NLP – Topic Modeling Supervisé avec BERTopic (Python)
NLP - Topic Modeling sous Python avec « BERTopic »
NLP – Analyse des sentiments sous Julia (VaderSentiment.jl, TextModels.jl)
NLP – Sentence transformers sous Julia (Transformers.jl / Hugging Face)
NLP – Catégorisation de documents sous Julia (TextAnalysis.jl, WordCloud.jl)
Auto-encodeur sous Julia avec le package « Flux »
NeuralNetworkClassifier Multiclasse sous Julia avec « MLJFlux.jl »
Réseaux de neurones sous Julia avec « Flux »
Régression linéaire multiple sous Julia avec « GLM.jl »
Graphiques dynamiques sous Julia avec Makie / GLMakie
Graphiques sympas sous Julia avec Makie / CairoMakie
Appel à des fonctions Julia dans un programme Python avec « JuliaCall »
Using Python from Julia – Accès aux packages spécialisés de Python (ex. scikit-learn)
Notebooks réactifs pour Julia avec « Pluto.jl »
Notebooks réactifs avec « marimo » (Python)
Ade4Shiny – Analyse en ligne avec « ade4 » (code R)
Connexion R et Julia via « RCall.jl » - Accès aux packages spécialisés de R
Classification Ascendante Hiérarchique [CAH] avec Julia (Clustering.jl)
Clustering – La méthode des K-Means avec Julia (Clustering.jl)
Analyse en composantes principales [ACP] avec Julia (MLJ / MultivariateStats)
Analyse discriminante sous Julia (MLJ.jl / MultivariateStats.jl)
Julia vs. programmes compilés (langages C [gcc] & Pascal [fpc]) - Performances
Profiler – Julia in VS Code (Profiling de code)
Julia (LinearAlgebra) vs. Python (Numpy) – Calcul matriciel
Arbres de décision sous Julia (MLJ.jl / DecisionTree.jl)
Ridge – Lasso – Pipeline – Courbe ROC sous Julia (MLJ.jl)
Comparaison de modèles supervisés sous Julia (MLJ.jl)
Extension Julia pour VS Code (Programmation Julia)
Machine learning in Julia – Introduction (MLJ.jl)
Requêtes LINQ sur DataFrame Julia (Query.jl)
Requêtes SQL sur DataFrame Julia (DuckDB)
Statistique descriptive avec Julia (StatsBase, StatsPlots)
Connexion VS Code – Google Colab (Notebook Jupyter)
Création d’un environnement Julia (Notebook Jupyter / VS Code)
Manipulation des DataFrames sous Julia
Julia vs. Python – Performances comparées
Optimisation des hyperparamètres en ML avec « optuna » (Scikit-learn / Python)
Reranking appliqué à la réponse aux QCM (Hugging Face / Transformers)
Processus data parallélisé avec « RAY / DATA » (Python)
Parallélisation des flux de traitements avec « ray » (Python)
Multiprocessing avec la librairie « Ray » pour Python
Analyse discriminante PLS « from scratch » avec ChatGPT (Python)
Analyse discriminante avec « discrimintools » (Python)
Règles d’association avec Knime – Données de transactions
Règles d’association avec KNIME
Détection des anomalies – Isolation Forest et Local Outlier Factor (Python)
Python Machine Learning sous Excel avec « xlwings lite »
Connexion entre Python (notebook) et Excel via « xlwings »
Extensions Weka et Scikit-Learn pour Knime
NLP – Sentence Transformers Multilingue – Hugging Face (Python)
NLP – Sentence Transformers (SBERT) – Hugging Face (Python)
Orange Data Mining – NLP – Sentence Transformers (SBERT)
Orange Data Mining - NLP - Catégorisation de documents
Weka DM – Le package « Python Weka Wrapper 3 »
Le debugger de VS Code – Python
Positron – L'EDI pour R « et » Python
Orange DM - Courbe ROC et Courbe de Gain
Orange DM - Clustering – CAH des variables
Orange DM - Clustering – CAH des individus
Orange DM - Cartes de Kohonen (SOM)
Orange DM - Clustering avec les K-Means
Orange DM - Comparaison de modèles
Orange DM - Arbres de décision
Règles d'association avec « arules » pour R
Sequential pattern mining - PySpark
Règles d'association avec PySpark
Stacking de classifieurs - mlxtend
Règles d'association - mlxtend/Python
Manipulation des DataFrames PySpark
Apply parallélisé pour DataFrame Pandas
Embarrassingly parallel problem sous R
Manip. des données "data.table" (pour R)
Manip. des données "datatable" (Python)
DuckDB + Pandas - Combinaison gagnante
Pandas vs. Polars - Performances comparées
Estimation et test statistiques
Parallélisation des traitements avec Joblib (Python)
Parallélisation Numba pour OneVsRestClassifier (Python)
Python rapide avec Taichi (vs. Numba)
Vectorisation des calculs – Numpy, Numba, Xarray (Python)
Intégration de code C dans Python avec Cython
Intégration de code C++ dans un projet R avec Rcpp
Combiner R et Python via Reticulate
Few-shot classification en NLP (spaCy / classy-classification)
Image to text et traduction (Hugging Face / Transformers)
Sentiment Analysis en NLP (Hugging Face / Transformers)
Zero-shot classification en NLP (Hugging Face / Transformers)
Deep Learning sous R avec le package torch
R et Python - Performances comparées
Knime Interactive R Statistics Integration
Auto-encodeur avec PyTorch (Python)
Transfer Learning avec PyTorch (torchvision / Python)
Modèles pré-entraînés pour le classement (PyTorch / Python)
ConvNet (CNN) avec tensorflow / keras (Python)
ConvNet (CNN) avec PyTorch (torchvision / Python)
Classement multiclasse avec PyTorch (Python)
Classement binaire avec PyTorch (Python)
Formulaire interactif dans un notebook (ipywigdets / Python)
Clustering – Déploiement Web App (streamlit / Python)
Pipeline – FunctionTransformer (scikit-learn / Python)
Pipeline – Paramétrage (scikit-learn / Python)
Microsoft Copilot... est mon ami
Pipeline - ColumnTransformer (scikit-learn / Python)
LibreOffice Calc - Filtres et Tableaux croisés
Macros Python pour LibreOffice Calc (2)
Fonctions personnalisées Python pour LibreOffice Calc
Macros Python pour LibreOffice Calc (1)
Requêtes SQL sur DataFrame Pandas (pandasql / Python)
Dockerisation (BD [SQLite] + Web App Python [gradio])
NLP - Catégorisation de doc. avec "fasttext" (Python)
NLP - Reconnaissance de la langue (fasttext / Python)
Déploiement des classifieurs avec R Shiny + Docker
Suivi avec MLFLOW TRACKING (PyCaret / Python)
Déploiement facile via GRADIO (PyCaret / Python)
Déploiement via STREAMLIT + DOCKER (Pycaret)
Déploiement via une API REST (PyCaret / Python)
Machine learning avec tidymodels pour R
Text Mining (NLP) - Le package spaCy pour Python
La méthode DISMIX (Python / scientisttools)
La méthode DISQUAL (Python / scientisttools)
PROC CANDISC avec "scientisttools" (Python)
Analyse discriminante - Projet Etudiant Python
PROC DISCRIMIN et STEPDISC (scientisttools / Python)
Analyse discriminante PLS (Python / scikit-learn)
Régression et classement - Equivalences (Python)
Clustering - Gap statistic - Nombre de groupes
ACP avec scientisttools - Nombre de composantes
Arbres de décision- Post-élagage avec R / rpart
Post-élagage des arbres - Python / Scikit-learn
Clustering tree avec Python / Scikit-Learn
Multidimensional Scaling avec Scientisttools
Analyses factorielles avec "scientisttools"
Clustering - Détection des communautés (igraph)
Segmentation d'image - K-Means (OpenCV vs. Scipy)
KMeans - Accélérer Scikit-learn / Python
Clustering de documents textuels avec PyCaret
Clustering des modalités de var. qualitatives (ACM)
ACP - Effet taille, indice KMO/MSA, corr. partielles
ACP + Rotation Quartimax et Clustering de variables
ACP sous Python avec statsmodels - Rotation Varimax
ACM sous Python avec fanalysis
AFC sous Python avec fanalysis
ACP sous Python avec fanalysis
Clustering flou - La méthode Fuzzy C-Means (Python)
K-Means - Pipeline et Déploiement (sklearn+fanalysis)
Tandem Clustering - Classif. sur données mixtes (R)
Clustering de modalités de variables quali (Python)
Clustering de Variables Quantitatives (Python)
Clustering Mixte - Carte de Kohonen + CAH (R)
Clustering Mixte - K-Means + CAH (R)
Clustering - Mesures éval. des partitions (sklearn)
Notebooks Jupyter (Python) avec VS Code
Environnement conda - Jupyter notebook et VSCode
Introduction au clustering - K-means sous Knime
Clustering - K-Means - Tanagra + Excel
Tanagra - AFDM #2 - Var. illustratives, indiv. supp.
Tanagra - AFDM #1 - Analyse fact. des données mixtes
Tanagra - ACM #2 - Var. illustratives, indiv. supp.
Tanagra - ACM #1 - Analyse fact. des corres. multiples
Tanagra - AFC #2 - Modalités lignes (colonnes) supp.
Tanagra - AFC #1 - Analyse factorielle des corresp.
Tanagra - ACP #6 - Tandem clustering : ACP + CAH
Tanagra - ACP #5 - VARCLUS, clustering de variables
Tanagra - ACP #4 - Rotation varimax, corr. partielles
Tanagra - ACP #3 - Var illus., indiv. supplémentaires
Tanagra - ACP #2 - Paramètres optionnels
Tanagra - ACP #1 - Calculs et post-traitements Excel
Explicabilité des modèles - Slides
Cours Delphi / Pascal - Travaux dirigés
(Vidéo) Représentation pré-entraînée GloVe avec Keras
(Vidéo) La couche Embedding de Keras en NLP
(Vidéo) Natural Language Processing avec Keras
(Vidéo) Modèle pré-entraîné Word2Vec avec Gensim
(Vidéo) Word2Vec / Doc2Vec avec Gensim - Python
(Vidéo) Topic Modeling avec Gensim / Python
(Vidéo) Word Embedding – L'algorithme Word2Vec
(Vidéo) StandardScaler et descente de gradient
(Vidéo) Topic Modeling avec Knime
(Vidéo) Text mining avec Knime
(Vidéo) Text mining avec quanteda sous R
(Vidéo) Text mining avec tidytext sous R
(Vidéo) Subdivision train-test avec scikit-learn
(Vidéo) Machine learning avec PyCaret
(Vidéo) Arbres de décision avec scikit-learn
(Vidéo) Ridge, Lasso – Optim. des hyperparamètres
Régression Logistique – Machine Learning
(Vidéo) Excel – Filtres, tableaux croisés
(Vidéo) Cross-validation, leave-one-out
(Vidéo) SAS sous Python avec SASPy
(Vidéo) Extension Intel(R) pour scikit-learn
(Vidéo) Perceptron avec TensorFlow / Keras (Python)
(Vidéo) Anaconda Python - Environnements
(Vidéo) Régression logistique avec Python / scikit-learn
(Vidéo) Régression logistique avec Knime
(Vidéo) La Proc Logistic de SAS
(Vidéo) Régression logistique pas-à-pas
(Vidéo) Régression avec la "proc reg" de SAS
(Vidéo) Régression linéaire avec Excel + Tanagra
(Vidéo) Programmation parallèle sous R
(Vidéo) Programmation MapReduce sous R
(Vidéo) Parallel Machine Learning avec Dask
(Vidéo) Gestion des DataFrame avec Dask (Python)
(Vidéo) Programmation parallèle avec Dask
(Vidéo) Cost-sensitive learning
Econométrie par Régis Bourbonnais
(Vidéo) Model Explainability par H2O
(Vidéo) Outils pour l'interprétation des modèles
(Vidéo) Python – AutoML de Scikit-Learn
(Vidéo) Python – AutoML de H2O
(Vidéo) Python - Le package Yellowbrick
(Vidéo) Stratégies pour classes déséquilibrées
(Vidéo) Extraction des règles d'association
(Vidéo) Subdivision apprentissage-test avec R
(Vidéo) Sélection forward en ADL
(Vidéo) Classification sur données pré-classées
(Vidéo) Arbres sur très grandes bases avec R
(Vidéo) Arbres de décision avec R
(Vidéo) La méthode des K-Means sous R et Python
(Vidéo) Déploiement de Pipeline Python
(Vidéo) Régression logistique multinomiale avec keras
(Vidéo) Régression logistique sous R avec Keras
(Vidéo) La régression logistique de scikit-learn
Titre : (Vidéo) Sélection rapide de variables
(Vidéo) Classifieurs linéaires
(Vidéo) Induction de règles prédictives
(Vidéo) Description des modèles avec PMML
(Vidéo) Manipulation des DataFrames "pandas"
(Vidéo) Analyse discriminante sous Python
(Vidéo) Analyse discriminante sous SAS
(Vidéo) ADL sous R avec "discriminR"
(Vidéo) Recodage des explicatives qualitatives en ADL
(Vidéo) Exportation des modèles prédictifs
(Vidéo) Conversion d'un Notebook Python avec Pandoc
(Vidéo) Modélisation, évaluation, déploiement
(Vidéo) Subdivision train-test pour les comparaisons
Réduction de dimension - La méthode GLRM
Pratique des Méthodes Factorielles avec Python
Pratique de l'Analyse Discriminante Linéaire
Dépendances des variables qualitatives - Version 2.1
Analyse Discriminante Linéaire sous R
Analyse Discriminante Linéaire sous Python
Régression Logistique sous Python
Régression Logistique -- TD 4.b
Régression Logistique -- TD 4.a
Régression Logistique -- TD 2.b
Régression Logistique -- TD 2.a
Détection des anomalies sous Python
Arbres de décision avec Scikit-Learn
Détection des anomalies - Diapos
Implémentation du Naive Bayes sous R
Deep learning : l'algorithme Word2Vec
Deep learning avec PyTorch sous Python
Auto-encodeur avec Keras sous Python
Deep learning : les auto-encodeurs
Discrétisation supervisée rapide
Ateliers Master SISE : logiciel SAS
Python Machine Learning avec Orange
Machine Learning - Outils pour l'enseignement
Performances des boucles sous R
Réseaux de neurones convolutifs sous Knime
Deep Learning avec Keras sous Knime
Économétrie - Projet Open Data
Régression ZIP sous R et Python
Régression de Poisson - Diapos
Économétrie - TD 6 - Évaluation
Économétrie - TD 5 - Régression sous Python
Économétrie - TD 4 - Régression sous R (II)
Économétrie - TD 3 - Régression sous R (I)
Économétrie - TD 2 - Régression multiple
Économétrie - TD 1.b - Régression simple
Économétrie - TD 1.a - Corrélation
Python - Détection de communautés avec MDS
Multidimensional scaling sous R
Positionnement multidimensionnel - Diapos
Programmer efficacement sous Python
Graphique de dépendance partielle - R et Python
Interpréter un classement en analyse prédictive
Python - Machine learning avec mlxtend
Programmer efficacement sous R
Importance des variables dans les modèles
Règles d'association sous Python
R et Python, performances comparées
Machine Learning avec H2O (Python)
Packages Python pour le Deep Learning
Packages R pour le Deep Learning
Deep learning : perceptrons simples et multicouches
Ateliers Master SISE : outils de la Dataviz
Master SISE - Remise à niveau - SQL
Pipeline sous Python - La méthode DISQUAL
Analyses factorielles sous Python avec fanalysis
Régressions ridge et elasticnet sous R
Descente de gradient stochastique sous Python
Deep Learning - Tensorflow et Keras sous R
Deep Learning avec Tensorflow et Keras (Python)
Requêtes avec jointures sous R
Régression linéaire sous Excel
Panne partielle du serveur Eric
Stratégies d'échantillonnage pour la modélisation
Master SISE - Remise à niveau - Python Statistique
R ou Python, il faut choisir ?
Ressources partagées - Apprentissage supervisé
Ateliers : Outils de la Data Science
Comprendre la taille d'effet (effect size)
De la statistique à la data science
Probabilités et quantiles sous Excel, R et Python
Détection de communautés sous Python
Détection de communautés - Diapos
Python : Manipulations des données avec Pandas
Filtrage collaboratif et recommandations - Diapos
Les expression régulières sous R
Fouille d'opinions et analyse des sentiments - Diapos
Text mining : catégorisation de SMS sous Python
Excel avancé - Cours et exercices corrigés
Text mining : topic model - Diapos
Text mining : la catégorisation de textes - Diapos
Text mining : la matrice documents termes - Diapos
Introduction au text mining - Diapos
Etude des logiciels de data science
Clustering : la méthode TwoStep Cluster
Clustering : algorithme des k-médoïdes - Diapos
Clustering : méthode des centres mobiles - Diapos
Clustering : caractérisation des classes - Diapos
Master SISE - Remise à niveau - Clustering
Master SISE - Remise à niveau - Analyse prédictive
Master SISE - Remise à niveau - Inférence statistique
Master SISE - Remise à niveau - Analyses factorielles
Les cartes auto-organisatrices de Kohonen - Diapos
Master SISE - Remise à niveau - Introduction à R
Classification ascendante hiérarchique - Diapos
ANOVA à un et deux facteurs - Diapos
Master SISE - Remise à niveau - Statistique Descriptive
Master SISE - Programme de remise à niveau - Excel
Les add-ins Tanagra et Sipina pour Excel 2016
Programmation Python sous Spark avec PySpark
Programmation R sous Spark avec SparkR
SVM : Support Vector Machine avec R et Python
SVM : Support Vector Machine - Diapos
Gradient boosting avec R et Python
Mining of Massive Datasets (2nd Edition)
Classification automatique sous Python
Building Machine Learning Systems
Data Science : fondamentaux et études de cas
Random Forest et Boosting avec R et Python
Bagging, Random Forest, Boosting - Diapos
Classification automatique sous R
Python - Econométrie avec StatsModels
Python - Machine learning avec scikit-learn
Python - Statistiques avec SciPy
Python - Les matrices avec NumPy
Python - Les vecteurs avec NumPy
Python - La distribution Anaconda
Les fichiers sous Python - Diapos
Les classes sous Python - Diapos
Collection d'objets sous Python - Diapos
Fonctions et modules sous Python - Diapos
Introduction à Python - Diapos
Programmation MapReduce sous R - Diapos
Big Data et Machine Learning...
Extraction des règles d'association - Diapos
Pratique de la régression - Version 2.1
Reconnaissance faciale et détection de l’âge
Prédicteurs catégoriels en Rég. Logistique
Analyse de corrélation - Version 1.1
Validation croisée, Bootstrap - Diapos
Arbres de classification - Théorie et pratique
Decision Trees for Analytics...
Méthodologie statistique pour l'analyse prédictive
Règles de décision prédictives - Diapos
Data Mining with Decision Trees
Introduction aux arbres de décision - Diapos
Clustering de variables qualitatives - Diapos
Induction par arbre avec WinIDAMS
La discrétisation des variables quantitatives (slides)
Nouveaux arbres interactifs dans SPAD 8
Nouveau site web pour Sipina (FR)
L'add-in Sipina pour Excel 2007 et 2010
SQL Server Data Mining Add-Ins
L'add-in Real Statistics pour Excel
Régression linéaire pour le classement
Analyse discriminante et régression linéaire
Text mining avec Knime et RapidMiner
Classification de variables qualitatives
Classification automatique sur données mixtes
Scilab et R - Performances comparées
Programmation à partir d'objets statistiques sous R
Manipulation des vecteurs sous R
Programmation modulaire sous R
Analyse Factorielle de Données Mixtes - Diapos
Analyse des correspondances multiples - Diapos
Analyse en composantes principales - Diapos
Analyse des correspondances discriminante - Diapos
Analyse factorielle des correspondances - Diapos
Programmation parallèle sous R
Multithreading équilibré pour la discriminante
Multithreading pour l'analyse discriminante
Associations dans la distribution SIPINA
Paramétrer le perceptron multicouche
Analyse des correspondances multiples - Outils
Analyse des correspondances discriminante
Analyse des correspondances - Comparaisons
Analyse en facteurs principaux
Analyse factorielle de données mixtes
Manipulation des données avec R
Analyse discriminante linéaire - Comparaisons
ACP sur corrélations partielles (suite)
ACP avec Tanagra - Nouveaux outils
ACP avec R - Détection du nombre d'axes
ACP sous R - Indice KMO et test de Bartlett
La librairie LIBCVM (Core Vector Machine)
Introduction à R - Arbre de décision
Introduction à R - Régression logistique
Tinn-R, un éditeur de code pour R
Vérification des données manquantes - Tanagra
Régression logistique sur les grandes bases
Arbres de décision sur les grandes bases (suite)
Arbres sur les " très" grandes bases (suite)
Connexion entre R et Excel via RExcel
L'add-in Tanagra pour Excel 2010 - 64 bits
Données manquantes en déploiement
Données manquantes - Régression logistique
Extraction des itemsets fréquents
Tanagra add-on pour OpenOffice Calc 3.3
Pratique de la Régression Linéaire (version 2)
Régression avec le logiciel LazStats (OpenStat)
REGRESS dans la distribution SIPINA
Régression linéaire simple et multiple
Classifieur Bayesien Naïf - Diaporama
Régression - Déploiement de modèles
Régression linéaire - Lecture des résultats
Régression Linéaire Multiple - Diaporama
Régression Linéaire Simple - Diaporama
Introduction à l'Econométrie - Diaporama
Analyse factorielle discriminante - Diaporama
ACP avec FactoMineR et dynGraph
Outils pour le développement d'applications
Régles d'association - Données transactionnelles
Arbres de décision sur les grands fichiers (mise à jour)
Multithreading pour les arbres de décision
Création de rapports avec Tanagra
Bayesien naïf pour prédicteurs continus
Nouvelle interface pour RapidMiner 5.0
Le format PMML pour le déploiement de modèles
Connexion Sipina/Excel via OLE [XL-SIPINA]
L'add-in Tanagra pour Excel 2007 et 2010
Filtrage des prédicteurs discrets
Data Mining sous R - Le package rattle
Déploiement des modèles prédictifs avec R
Traitement des très grands fichiers avec R
Tanagra dans La revue Modulad (2005)
Tanagra - Présentation à EGC'2005
Sipina - Présentation de l'ancienne version 2.5
Traitement des classes déséquilibrées
Tanagra et autres logiciels gratuits
Le classifieur Bayesien Naïf revisité
Discrétisation - Comparaison de logiciels
"Wrapper" pour la sélection de variables (suite)
Induction de règles floues avec Knime
Arbres de décision interactifs avec SPAD
Induction de Règles Prédictives
Sipina – Traitement des très grands fichiers
Sipina - Echantillonnage dans les arbres
Sipina - Traitement des données manquantes
Evaluation des classifieurs - Quelques courbes
Diagnostic de la régression logistique
Etude des dépendances - Variables qualitatives
Probabilités et Statistique - Note de cours
Tests de conformité à la loi normale
Pratique de la Régression Linéaire Multiple
Comparaison de populations - Tests paramétriques
Pratique de la régression logistique
Statistiques descriptives (suite)
Stratégie « wrapper » pour la sélection de variables
Analyse factorielle des correspondances avec R
Analyse des Corresponsances Multiples avec R
Installation des packages sous R
Diagnostic de la régression avec R
Analyse en Composantes Principales avec R
Connexion Open Office Calc sous Linux
Règles d'Association Prédictives
Utiliser et paramétrer A PRIORI MR
Mesures d'intérêt des règles dans A PRIORI MR
Comparaison des performances sous Linux
Coûts de mauvais classement en apprentissage supervisé
Règles d’association – Comparaison de logiciels
Validation croisée - Comparaison de logiciels (suite)
Classification automatique - Déploiement de modèles
K-Means – Comparaison de logiciels
Traitement de gros volumes – CAH Mixte
Régression logistique - Comparaison de logiciels
SVM - Comparaison de logiciels
Traitement de gros volumes – Comparaison de logiciels
Tanagra : Spécifications, Développement, Promotion
La méthode CART dans Tanagra et R (package rpart)
Comparaison des dispersions pour K échantillons indépendants
Tests de comparaison pour 2 échantillons appariés
Test de Kruskal-Wallis et comparaisons multiples
Tests non paramétriques de comparaison de 2 populations. Modèle de localisation.
Comparaison de populations – Tests non paramétriques
Comparaison de populations - Tests paramétriques multivariés
Comparaison de populations - Tests paramétriques univariés
Régression PLS – Comparaison de logiciels
Détection (univariée) des points aberrants
Analyse Discriminante PLS – Etude comparative
Programmer un composant dans TANAGRA
Interpréter la « valeur test »
Régression logistique ordinale
Analyse discriminante linéaire
Analyse de variance de Friedman
Tests d’adéquation à la loi normale
Analyse de variance et comparaison de variances
Mesures d’association – Variables ordinales
Mesures d’association – Variables nominales
Coefficient de corrélation linéaire
Régression PLS – Sélection du nombre d’axes
Tanagra : un logiciel open source
Règles d’association - Orange, Tanagra et Weka
Règles d’association avec Apriori PT
Règles d’association « supervisées »
A PRIORI sur les bases transactionnelles
Règles d’association – Algorithme A PRIORI
Réseaux de neurones avec SIPINA, TANAGRA et WEKA
Apprentissage-test avec ORANGE, TANAGRA et WEKA
Arbres de décision avec ORANGE, TANAGRA et WEKA
Courbe ROC avec ORANGE, TANAGRA et WEKA
Logiciels gratuits pour l’enseignement (déc.2005)
Points aberrants et influents dans la régression
Statistiques descriptives comparatives
Travailler sur les corrélations partielles
K-Means sur variables qualitatives
Régression logistique multinomiale
Stepdisc – Analyse discriminante
Listes de décision (vs. arbres de décision)
Support vector machine (SVM) multi-classes
Construction de variables avec NIPALS
Echantillonnage dans les arbres de décision
Analyse discriminante sur axes principaux
Validation croisée, bootstrap, leave one out
Comparaison de classifieurs – Validation croisée
Courbe ROC pour la comparaison de classifieurs
Statistiques descriptives avec SIPINA
Scoring avec la régression logistique
Ciblage marketing (scoring) – Coil challenge
Déploiement de modèles avec Tanagra
Sélection de variables – Bayesien naïf
Traitement des grands fichiers
Sauver et charger des parties du diagramme
Copier coller dans le diagramme
Importer un fichier Weka dans Tanagra
Discrétisation contextuelle – La méthode MDLPC
Importer un fichier Weka dans Sipina
Description de l’interface SIPINA
Déploiement d'un arbre de décision avec SIPINA
Classification automatique - Algorithme EM
Analyse discriminante descriptive - Vins de Bordeaux
Sélection forward - Crime dataset
Régression - Expliquer la consommation des véhicules
CAH Mixte - Le fichier Iris de Fisher
CART - Détermination de la taille de l'arbre
Arbres de décision - ID3 sur Breast Cancer
AFC - Association médias et professions
ACP - Description de véhicules
Arbres interactifs - Sipina et Orange
Apprentissage - test avec Sipina
Analyse interactive avec Sipina
Importation fichier XLS (Excel) [Mode natif]
Importation fichier XLS (Excel) [Macro complémentaire]
Ricco Rakotomalala
NLP – Topic Modeling Supervisé avec BERTopic (Python)
2026-06-28 (Tag:b4trU5uelus)
Machine learning. Data science. NLP (natural language processing). Text mining. Le « topic modeling » (modélisation de sujets) en NLP consiste à dégager des « topics » (thématiques) à partir d’un corpus de documents. Il s’agit d’un procédé nativement non-supervisé. Le package « BERTopic » introduit un concept peu usuel avec l’injection de la classe d’appartenance des documents - lorsqu’elle est disponible - dans le processus. Il peut produire directement une caractérisation des documents regroupés selon leur classe d’appartenance ; il peut également s’appuyer sur un algorithme supervisé (une régression logistique Ridge dans notre tutoriel) pour donner un éclairage sur le processus de désignation des classes. Nous observons dans notre expérimentation que les subtilités entre les résultats permettent d’enrichir l’exploration des corpus de documents étiquetés.
Lien vidéo: https://www.youtube.com/watch?v=b4trU5uelus
Notebook + Data : Programme - Notebook - Données
NLP - Topic Modeling sous Python avec « BERTopic »
2026-06-26 (Tag:PAUvOSpyp-0)
Machine learning. Data science. NLP (natural language processing). Text mining. Le « topic modeling » (modélisation de sujets) en NLP consiste à dégager des « topics » (thématiques) à partir d’un corpus de documents, que l’on caractérise par la suite à l’aide des mots-clés qui leur sont associés. L’approche BERTopic se distingue en utilisant des représentations sémantiques issues des modèles de langage pré-entraînés. Dans un premier temps, elle procède à un clustering de documents à partir de leurs « embedding » (vecteur numérique de description des documents) ; dans un second temps, elle associe les termes aux groupes de documents avec l’indicateur « c-TF-IDF », qui est une généralisation aux groupes de documents de la pondération « TF-IDF » bien connue en NLP. L’autre originalité est la possibilité d’affiner la description des « topics » à l’aide d’outils additionnels sans avoir à relancer le processus dans son intégralité. Non exploré dans ce tutoriel, mais décrit de manière très intéressante sur le site web, il est même possible d’utiliser les LLM et l’IA générative pour produire une description pertinente et circonstanciée des « topics ».
Lien vidéo: https://www.youtube.com/watch?v=PAUvOSpyp-0
Notebook + Data : Programme - Notebook - Données
NLP – Analyse des sentiments sous Julia (VaderSentiment.jl, TextModels.jl)
2026-06-24 (Tag:3J5VPpX2Jww)
Data science. Machine learning. NLP (natural language processing). Text Mining. Utilisation des solutions clés en main pour l’analyse des sentiments des documents textuels sous Julia, avec le package « VaderSentiment » qui utilise la polarité des termes et des règles lexicales, et « TextModels » qui repose sur un modèle préentraîné sur de grands corpus. Sur notre base test, les deux outils sont très faciles d’utilisation, mais avec des résultats contrastés. L’opportunité d’utiliser des modèles accessibles sur « Hugging Face » est également discuté, d’autant plus que nous pouvons mettre en miroir nos résultats avec ceux obtenus dans un précédent tutoriel sous Python où nous avions recours à une version spécialisée, dérivée de « DistilBERT », qui fait référence dans le domaine.
Lien vidéo: https://www.youtube.com/watch?v=3J5VPpX2Jww
Notebook + Data : Programme - Notebook - Données
NLP – Sentence transformers sous Julia (Transformers.jl / Hugging Face)
2026-06-22 (Tag:0EsKXRhOYxM)
Machine learning. Data science. NLP (natural language processing). Text Mining. Utilisation d’un modèle « sentence transformers » pré-entraîné accessible sur « Hugging Face » dans un processus de catégorisation de documents textuels sous Julia, via le package « Transformers.jl ». Nous l’utilisons pour obtenir une représentation vectorielle des documents (document embedding) propice à l’application des algorithmes de machine learning. Les étapes sont bien délimitées : chargement en ligne du modèle pré-entraîné (all-MiniLM-L6-v2), traduction du corpus en matrice numérique, catégorisation avec une régression logistique (Lasso). A noter que, à la différence du package « Sentence_transformers » de Python, « Transformers.jl » ne fournit pas une description vectorielle respectant la similarité sémantique. Il faut post-traiter ses résultats avant de pouvoir les exploiter dans un processus de machine learning. La fonction Julia qui s’en charge est décrite dans le notebook.
Lien vidéo: https://www.youtube.com/watch?v=0EsKXRhOYxM
Notebook + Data : Programme - Notebook - Données
NLP – Catégorisation de documents sous Julia (TextAnalysis.jl, WordCloud.jl)
2026-06-19 (Tag:hX_7UeqdHmE)
Machine Learning. Data Science. NLP (natural language processing). Text Mining. Catégorisation de documents (données « Reuters ») sous Julia avec les packages spécialisés « TextAnalysis » et (un peu) « WordCloud ». Preprocessing des documents, représentation bag of words (sac de mots), construction de la matrice documents-termes (pondération binaire). Analyse prédictive à l’aide d’un classifieur bayésien naïf multinomial (via MLJ, MultinomialNBClassifier du package « NaiveBayes »). Evaluation des performances avec le schéma train / test. Le dispositif répond parfaitement aux attentes du domaine.
Lien vidéo: https://www.youtube.com/watch?v=hX_7UeqdHmE
Notebook + Data : Programme - Notebook - Données
Auto-encodeur sous Julia avec le package « Flux »
2026-06-17 (Tag:zthiSmU0Pp4)
Deep learning - Machine learning - Data science. Définition, paramétrage, instanciation et entraînement des autoencodeurs (autoencoders) avec « Flux.jl » sous Julia. Nous reproduisons à l’identique une étude menée auparavant sous Python avec la librairie « PyTorch » (Torch), avec les principales étapes : définition de la structure du réseau, les parties « encoder » et « decoder » ; choix de la fonction de perte (loss, MSE ici) et de l’algorithme d’optimisation (Adam) ; écriture de la boucle d’entraînement ; inspection de la structure du réseau et accès aux poids synaptiques ; projection des individus dans l'espace intermédiaire (embeddings) ; reconstitution des données initiales afin de pouvoir identifier les données atypiques ; traitement des variables et des individus supplémentaires.
Lien vidéo: https://www.youtube.com/watch?v=zthiSmU0Pp4
Notebook + Data : Programme - Notebook - Données
NeuralNetworkClassifier Multiclasse sous Julia avec « MLJFlux.jl »
2026-06-15 (Tag:BLBvH7Tv4Fw)
Machine learning. Data science. Deep learning. Instanciation, paramétrage et entraînement d’un perceptron multicouche pour un problème de classification supervisée multiclasse sous Julia via le package « MLJFlux ». Il fait le pont entre les librairies « MLJ » et « Flux » : le premier encapsule l’utilisation des algorithmes de machine learning dans un framework standardisé ; le second est une bibliothèque de deep learning, au même titre que l’est PyTorch pour Python. MLJ nous facilite grandement la vie, notamment en nous épargnant l’écriture explicite de la boucle d’entraînement. Il reste néanmoins possible d’accéder aux objets « Flux » sous-jacents pour produire les résultats intermédiaires. Dans cet exercice, nous accédons à la projection des données dans un espace défini par les neurones de la couche cachée, nous pouvons ainsi apprécier visuellement la séparabilité des classes dans un graphique nuage de points.
Lien vidéo: https://www.youtube.com/watch?v=BLBvH7Tv4Fw
Notebook + Data : Programme - Notebook - Données
Réseaux de neurones sous Julia avec « Flux »
2026-06-12 (Tag:5nYx09mjm0s)
Machine learning. Data science. Deep learning. Classement ou classification supervisée binaire sous Julia via le package « Flux ». Instanciation et implémentation de perceptrons simples et multicouches : importation et préparation des données, définition du modèle, inspection des structures (couches, poids synaptiques, biais), entraînement sur un échantillon d’apprentissage, évaluation sur un échantillon test. Pour identifier les phases clés de l’étude, nous les mettons en parallèle avec ce qui se fait par ailleurs sous Python avec le package « PyTorch » (vidéo en référence, données et étapes identiques). Nous avons bien les mêmes repères avec des résultats du même ordre. Le tandem Julia + Flux (librairie de machine learning / deep learning) joue parfaitement son rôle. Faute de matériel adéquat, je ne l’ai pas testé, mais dixit la documentation « Flux » est compatible avec les GPU pour l’accélération des calculs.
Lien vidéo: https://www.youtube.com/watch?v=5nYx09mjm0s
Notebook + Data : Programme - Notebook - Données
Régression linéaire multiple sous Julia avec « GLM.jl »
2026-06-10 (Tag:1XlhlPCsT98)
Machine learning. Data science. Econométrie. Mise en œuvre de la régression multiple sous Julia via le package « GLM », dans une approche plutôt statistique. Utilisation de la fonction lm(). Avec les principales étapes : importation des données ; instanciation de la régression ; inspection des résultats ; obtention des résultats additionnels ; diagnostic de la régression avec l’étude des résidus, identification des points atypiques et influents (levier, résidus standardisés, résidus studentisés) ; prédiction ponctuelle et par intervalle sur un fichier d’observations supplémentaires. Le tutoriel a été calé sur une étude précédente – avec exactement les mêmes données - du package « statsmodels » pour Python. Nous retrouvons bien les mêmes fonctionnalités avec des résultats identiques.
Lien vidéo: https://www.youtube.com/watch?v=1XlhlPCsT98
Notebook + Data : Programme - Notebook - Données
Graphiques dynamiques sous Julia avec Makie / GLMakie
2026-06-08 (Tag:dsbOeNoeAok)
Machine learning. Data science. « GLMakie » est une librairie basée sur OpenGL appartenant à l’écosystème de plotting « Makie » pour le langage Julia. Elle permet d’afficher les graphiques dans une fenêtre dédiée (en dehors de notre notebook), et nous donne la possibilité de manipuler de manière interactive la représentation des données. Nous explorons deux applications dans notre tutoriel : une représentation 3D que l’on peut tourner et retourner à loisir ; un nuage de points que l’on peut filtrer sur la base d’une tierce variable associée à un « slider ». Le dispositif est très facile d’utilisation.
Lien vidéo: https://www.youtube.com/watch?v=dsbOeNoeAok
Notebook + Data : Programme - Notebook - Données
Graphiques sympas sous Julia avec Makie / CairoMakie
2026-06-08 (Tag:Xq0P08QHr-g)
Machine learning. Data science. La librairie « CairoMakie » fait partie de l’écosystème de visualisation « Makie » pour Julia. Elle permet de produire des graphiques statiques de qualité pour la création de rapports ou pour les publications scientifiques, avec une mise en page élaborée. Dans ce tutoriel, nous passons en revue quelques graphiques statistiques (histogrammes, courbes de densité, nuages de points, etc.), en essayant de mettre en avant les particularités de l’outil. Nous ne l’avons pas exploré ici, mais il est tout à fait possible d’exporter les résultats vers des format vectoriels (ex. SVG) ou sous la forme d’images (ex. PNG).
Lien vidéo: https://www.youtube.com/watch?v=Xq0P08QHr-g
Notebook + Data : Programme - Notebook - Données
Appel à des fonctions Julia dans un programme Python avec « JuliaCall »
2026-06-01 (Tag:Op_52Uqe6z0)
Machine learning. Data science. Le module « JuliaCall » permet de faire appel à des fonctions Julia, éventuellement stockées dans des modules, depuis un programme Python. L’idée est de tirer profit des performances de Julia (avec sa technologie JIT [Juste in time] qui compile à la volée en code machine optimisé) pour les portions de code coûteuses (parce que complexe ou répétitives), tout en conservant l’architecture générale en Python de notre application. Dans notre exemple, nous constatons que remplacer dans une section critique de notre application, une fonction Python par l’équivalent en Julia (via JuliaCall), permet de réduire dans des proportions considérables le temps d’exécution.
Lien vidéo: https://www.youtube.com/watch?v=Op_52Uqe6z0
Notebook + Data : Programme - Notebook - Données
Using Python from Julia – Accès aux packages spécialisés de Python (ex. scikit-learn)
2026-06-01 (Tag:kwNx7R1KQAI)
Machine learning. Data science. Accès aux packages spécialisés de Python à partir d’un programme (notebook) Julia via la librairie « PythonCall ». Outils à installer pour le bon fonctionnement du dispositif (Julia d’un côté ; Python de l’autre, avec les packages à utiliser, je m’appuie sur l’environnement « base » de la distribution Anaconda en ce qui me concerne). Connexion à Python dans un programme Julia, puis importation de classes de calcul de machine learning (en l’occurrence un LinearSVC dans notre tutoriel -- support vector machine avec un noyau linéaire, nous disposons d'un modèle explicite comparable à la régression logistique). Entraînement du modèle et post-traitement des résultats. Pour Julia, l’accès à l’immense écosystème des packages spécialisés de Python (machine learning, data science) décuple dans des proportions assez phénoménales ses possibilités de traitements.
Lien vidéo: https://www.youtube.com/watch?v=kwNx7R1KQAI
Notebook + Data : Programme - Notebook - Données
Notebooks réactifs pour Julia avec « Pluto.jl »
2026-05-29 (Tag:9kjag8WSS9c)
Machine learning. Data Science. « Pluto.jl » est un environnement de notebooks interactifs pour le langage Julia, un peu comparable à Jupyter Notebook, mais avec deux (au moins) fonctionnalités additionnelles : la réactivité, les modifications d’une variable dans une cellule sont répercutées dans les cellules dépendantes ; la possibilité d’introduire des composants visuels (les widgets, zone de saisie, slider, case à cocher, etc.) qui permettent d’améliorer l’interactivité de notre projet. Il se positionne, pour Julia, comme une solution similaire à la librairie « marimo » pour Python. Dans notre tutoriel de machine learning, nous modifions le nombre de clusters (méthode des K-Means) avec un slider et nous observons en temps réel les modifications des profils des groupes via un radarplot représentant les moyennes conditionnelles.
Lien vidéo: https://www.youtube.com/watch?v=9kjag8WSS9c
Notebook + Data : Programme - Notebook - Données
Notebooks réactifs avec « marimo » (Python)
2026-05-23 (Tag:nUOi5S8XBdI)
Machine learning. Data science. La librairie « marimo » pour Python permet de créer des notebooks qui, à la différence de Jupyter, sont réactives dans le sens où les modifications des variables induisent une mise à jour automatique des cellules dépendantes. La cohérence de l’ensemble du projet est assurée à chaque instant, il n’est plus nécessaire de réexécuter à intervalles réguliers l’ensemble du notebook. « Marimo » permet également de transformer simplement les notebooks en application web interactive (un peu – toutes proportions gardées – comme Streamlit). Nous disposons d’un jeu de composants d’interface graphique (widgets : champ text, case à cocher, slider, etc.) pour définir une interface dynamique, avec la possibilité d’interagir dynamiquement avec nos applications de machine learning (ex. dans notre tutoriel, modifier le nombre de clusters pour un K-Means et observer les positions relatives des groupes dans le premier plan factoriel d’une ACP [analyse en composantes principales]).
Lien vidéo: https://www.youtube.com/watch?v=nUOi5S8XBdI
Notebook + Data : Programme - Notebook - Données
Ade4Shiny – Analyse en ligne avec « ade4 » (code R)
2026-05-22 (Tag:08G6ukrtTY4)
Machine learing. Data science. Réalisation d’une ACP (analyse en composantes principales) à l’aide de l’application en ligne « ade4shiny », basé sur le fameux package « ade4 » pour R, développé et maintenu par le Laboratoire de Biométrie et Biologie Evolutive (LBBE) de l’Université Lyon 1. L’accès au logiciel est totalement libre (cf. l’URL ci-dessous), il nous permet de réaliser très simplement les étapes clés des analyses statistiques multivariées : importation des données, spécification des paramètres de l’étude, accès et récupération des résultats. L’ensemble des traitements spécifiés peut être exporté sous la forme d’un code programme pour R.
Lien vidéo: https://www.youtube.com/watch?v=08G6ukrtTY4
Notebook + Data : Programme - Notebook - Données
Connexion R et Julia via « RCall.jl » - Accès aux packages spécialisés de R
2026-05-20 (Tag:f4YVdosbAAA)
Machine learning. Data Science. Pilotage de R à partir de Julia. Démarrage d’une session, transfert des données, lancement des calculs, récupération des résultats. « RCall.jl » se charge des échanges entre les deux entités, la solution est très facile d’utilisation pourvu que R soit visible dans le PATH (sous Windows) et que les librairies de R sollicitées soient préalablement installées (il est néanmoins possible de les installer à la volée). Nous implémentons une AFC (analyse factorielle des correspondances) du package « ade4 » pour montrer l’excellente tenue du dispositif. Pour Julia, l’accès à l’immense écosystème des packages spécialisés de R (statistique, machine learning, data science) décuple dans des proportions assez phénoménales ses possibilités de traitements.
Lien vidéo: https://www.youtube.com/watch?v=f4YVdosbAAA
Notebook + Data : Programme - Notebook - Données
Classification Ascendante Hiérarchique [CAH] avec Julia (Clustering.jl)
2026-05-19 (Tag:HV9Ljnh8T_o)
Machine learning. Data science. Apprentissage non-supervisé. Mise en œuvre de la méthode de classification automatique CAH (classification ascendante hiérarchique) avec Julia via le package « Clustering.jl ». Avec les étapes usuelles : préparation des données, calcul de la matrice de distances, lancement de l’algorithme, identification du nombre de clusters à travers la lecture du dendrogramme, caractérisation des groupes avec [dans ce tutoriel] une représentation graphique des profils sous la forme d’un « radar plot » (« spider plot », « radar chart ») (package « PlotlyJS »). La structuration de l’information peut également s’exprimer à travers la CAH de variables, la matrice des distances étant dérivée des corrélations par paires de variables. L’approche met au jour une autre forme des « dimensions » (patterns) véhiculées par les données.
Lien vidéo: https://www.youtube.com/watch?v=HV9Ljnh8T_o
Notebook + Data : Programme - Notebook - Données
Clustering – La méthode des K-Means avec Julia (Clustering.jl)
2026-05-09 (Tag:5TVcnCoeI-k)
Machine learning. Data science. Apprentissage non-supervisé. Mise en œuvre de la méthode des K-Means sous Julia via la librairie « Clustering.jl ». Avec les étapes usuelles : préparation des données, lancement des calculs, inspection des résultats avec en particulier la caractérisation des clusters (des groupes obtenus par algorithme), traitement des variables et individus supplémentaires. Nous couplons la démarche avec une analyse en composantes principales (ACP) du package « MultivariateStats.jl » pour mieux situer les positions relatives des clusters et la nature des résultats.
Lien vidéo: https://www.youtube.com/watch?v=5TVcnCoeI-k
Notebook + Data : Programme - Notebook - Données
Analyse en composantes principales [ACP] avec Julia (MLJ / MultivariateStats)
2026-05-06 (Tag:73LkuDosr5o)
Machine learning. Data science. Mise en œuvre de l’analyse en composantes principales (ACP) sous Julia via le tandem de packages « MLJ » (Machine Learning in Julia) et « MultivariateStats ». Construction des axes factoriels à l’aide des données actives. Eboulis des valeurs propres (scree plot). Aides à l’interprétation à travers les variables (corrélations aux composantes, contributions [CTR], cosinus carré [COS2]), cercle des corrélations. Représentation des individus (coordonnées factorielles). Traitements des variables et individus supplémentaires (illustratifs). Enfin, rotation orthogonale (varimax) des axes pour améliorer la lisibilité des résultats. Bilan : Julia, avec ces packages spécialisés, répond parfaitement aux attentes dans le domaine.
Lien vidéo: https://www.youtube.com/watch?v=73LkuDosr5o
Notebook + Data : Programme - Notebook - Données
Analyse discriminante sous Julia (MLJ.jl / MultivariateStats.jl)
2026-04-30 (Tag:3216RgcneY0)
Machine learning. Data science. Mise en œuvre de l’analyse discriminante sous Julia via le tandem de packages « MLJ » (Machine Learning in Julia), qui sert d’interface, et « MultivariateStats » qui fournit l’algorithme de calcul. Nous montons une démarche d’expérimentation simple dans un premier temps, une modélisation-évaluation avec un schéma « holdout ». Dans un deuxième temps, nous explorons les différentes facettes de l’analyse discriminante en confrontant, pour les individus de l’échantillon test, les distances de Mahalanobis aux centres de classes (calculés sur l’échantillon d’apprentissage) avec les distances euclidiennes comptabilisées dans l’espace réduit issu de l’analyse factorielle discriminante. Bilan : nous constatons que l’outil (Julia – MLJ – MultivariateStats) répond parfaitement à ce que l’on est en droit d’attendre dans le domaine.
Lien vidéo: https://www.youtube.com/watch?v=3216RgcneY0
Notebook + Data : Programme - Notebook - Données
Julia vs. programmes compilés (langages C [gcc] & Pascal [fpc]) - Performances
2026-04-28 (Tag:8JICIi0I0J4)
Machine learning. Data science. Comparaison des performances entre Julia d’une part, les programmes compilés d’autre part, avec les langages C (compilé avec « gcc » [GNU Compiler Collection]) et Pascal (compilé avec « fpc » [Free Pascal Compiler]). Mesures des temps d’exécution dans l’implémentation d’un tri à bulles où sont mis à l’épreuve principalement : l’accès aux valeurs d’une liste (vecteur) (lecture, écriture), la réalisation de boucles for imbriquées, la gestion des branchements conditionnels. Assez extraordinairement, Julia, pourtant typé dynamiquement, tient parfaitement la route avec sa technologie JIT (just-in-time, compilation à la volée), au même niveau de performances que le C (gcc), et se compare avantageusement au Pascal (fpc).
Lien vidéo: https://www.youtube.com/watch?v=8JICIi0I0J4
Notebook + Data : Programme - Notebook - Données
Profiler – Julia in VS Code (Profiling de code)
2026-04-25 (Tag:rv4ajDIJ4bY)
Machine learning. Data Science. Utilisation de l’outil de profilage de VS Code pour l’optimisation du temps d’exécution d’un programme Julia. Il permet l’identification des goulots d’étranglement, ceux qui impactent négativement les performances de nos implémentations. A voir ensuite comment améliorer ces parties critiques pour obtenir une amélioration significative de la rapidité de traitements de nos solutions (je me suis contenté de les supprimer dans cette vidéo, il est évident qu’il ne s’agit pas vraiment d’une approche viable).
Lien vidéo: https://www.youtube.com/watch?v=rv4ajDIJ4bY
Notebook + Data : Programme - Notebook - Données
Julia (LinearAlgebra) vs. Python (Numpy) – Calcul matriciel
2026-04-25 (Tag:2tkICUjiyH4)
Machine learning. Data science. Comparaison des performances de Julia (package « LinearAlgebra ») et de Python (package « Numpy ») sur des calculs matriciels, entièrement vectorisés donc, qui reposent quasi entièrement sur les caractéristiques des librairies sollicitées. Dans notre contexte (centrage-réduction, décomposition en valeurs singulières, produit matrice, inversion, diagonalisation [valeurs et vecteurs propres]), le tandem Python / Numpy se démarque significativement à mesure que la volumétrie augmente. A contrario, les qualités intrinsèques des langages (de la technologie associée, JIT) pèsent très peu sur la rapidité d’exécution.
Lien vidéo: https://www.youtube.com/watch?v=2tkICUjiyH4
Notebook + Data : Programme - Notebook - Données
Arbres de décision sous Julia (MLJ.jl / DecisionTree.jl)
2026-04-24 (Tag:aNP8n0eGOiI)
Machine learning. Data science. Induction des arbres de décision sous Julia via le tandem de packages « MLJ » (qui harmonise l’accès aux méthodes) et « DecisionTree ». Les étapes sont bien identifiées dans un schéma holdout (apprentissage / test) : importation des données, encodage préalable (notamment OneHotEncoding des descripteurs qualitatifs), modélisation, inspection de l’arbre (affichage, importance des variables), évaluation. Encapsulation des étapes dans un pipeline. Bilan : Julia (via MLJ et DecisionTree) répond parfaitement au cahier des charges attendu dans le domaine.
Lien vidéo: https://www.youtube.com/watch?v=aNP8n0eGOiI
Notebook + Data : Programme - Notebook - Données
Ridge – Lasso – Pipeline – Courbe ROC sous Julia (MLJ.jl)
2026-04-23 (Tag:c771zfqxxDk)
Machine learning. Data science. Comparaison des performances prédictives des modèles via la courbe ROC sous Julia (package « MLJ »). Avec les étapes clés : inspection et préparation des variables (standardisation), implémentation de la régression logistique et de ses variantes pénalisées (ridge, lasso) via les spécifications des hyperparamètres, construction de la courbe ROC (receiver operating characteristic), calcul de l’AUC (area under curve, aire sous la courbe), et de l’intervalle de confiance de l’AUC puisque l’indicateur est soumis aux fluctuations d’échantillonnage. Dans notre exemple, nous utilisons le dataset « spambase » bien connu dans notre domaine. Enfin, mise en place d’un pipeline pour enchaîner de manière transparente le parcours de modélisation (à l’instar de ce qui se fait sous Python / Scikit-learn par exemple). Bilan : Julia dispose de tout l’arsenal nécessaire pour mener efficacement et simplement ce type d’étude, très typique des tâches du data scientist.
Lien vidéo: https://www.youtube.com/watch?v=c771zfqxxDk
Notebook + Data : Programme - Notebook - Données
Comparaison de modèles supervisés sous Julia (MLJ.jl)
2026-04-21 (Tag:a72iBJ8yw5E)
Machine learning. Data science. Comparaison des performances d’algorithmes supervisés sous Julia. Utilisation du package « MLJ » (Machine learning in Julia). Traitement du fichier « spambase » avec les modèles prédictifs : arbre de décision, random forest, régression logistique, gradient boosting. Nous avons utilisé le schéma holdout mais un traitement par une technique de rééchantillonnage aurait été possible (ex. validation croisée, avec les réserves d’usage). Bilan : à l’instar des autres outils, il est aisé de réaliser ce type de démarche avec Julia / MLJ.
Lien vidéo: https://www.youtube.com/watch?v=a72iBJ8yw5E
Notebook + Data : Programme - Notebook - Données
Extension Julia pour VS Code (Programmation Julia)
2026-04-20 (Tag:rEXNRyU_Fs4)
Programmation Julia, utilisation de l’éditeur Visual Studio Code (VS Code). Installation de l’extension « Julia Language Support ». Création et édition du code (fichier « .jl »). Lancement du programme. Attention, utiliser préférentiellement la solution consistant à : ouvrir un terminal, lancer manuellement l’interpréteur Julia, faire exécuter le code via l’instruction include(). En effet, l’utilisation directe du menu d’exécution peut entraîner des problèmes d’interaction entre la console Julia (REPL : read-eval-print loop) et VS Code.
Lien vidéo: https://www.youtube.com/watch?v=rEXNRyU_Fs4
Notebook + Data : Programme - Notebook - Données
Machine learning in Julia – Introduction (MLJ.jl)
2026-04-17 (Tag:2vXQgNTSD6g)
Machine learning. Data science. Julia. Première exploration des fonctionnalités du package « MLJ » de Julia dédié au machine learning. Nous nous plaçons dans un cas d’usage très simple (scolaire) de classification supervisée dans un premier temps : importation des données, préparation des structures, partition train/test, entraînement du modèle (régression logistique [package « MLJLinearModels »]), évaluation [accuracy, matrice de confusion], validation croisée. Bilan des opérations : MLJ de Julia présente bien les capacités attendues dans le domaine.
Lien vidéo: https://www.youtube.com/watch?v=2vXQgNTSD6g
Notebook + Data : Programme - Notebook - Données
Requêtes LINQ sur DataFrame Julia (Query.jl)
2026-04-16 (Tag:eEYTxCHGS1o)
Machine learning. Data science. Julia. Application de requêtes LINQ (Language-Integrated Query) sur des « dataframe » Julia (package DataFrames). LINQ permet de manipuler des collections de données avec une syntaxe uniforme. Il est plus générique que le SQL, mais peut néanmoins s’appliquer à des bases mono ou multi-tables. La fonctionnalité est portée sous Julia via le package « Query ». Nous constatons dans cette vidéo que l’outil permet la définition de requêtes évoluées (filtrage, projection, tri, jointure, regroupement, champs calculés, etc.).
Lien vidéo: https://www.youtube.com/watch?v=eEYTxCHGS1o
Notebook + Data : Programme - Notebook - Données
Requêtes SQL sur DataFrame Julia (DuckDB)
2026-04-15 (Tag:wtAFyxyGmAo)
Machine learning. Data Science. Julia. Utilisation de requêtes SQL pour accéder aux informations de tables sous la forme de dataframe Julia en mémoire via l’utilisation du driver du package « DuckDB » (DuckDB, rappelons-le, est un système de gestion de bases de données orientées colonnes, adapté pour le traitement analytique). Plusieurs exemples de requêtes simples et avec jointure. On notera que le package DataFrames de Julia propose aussi des solutions natives pour les jointures.
Lien vidéo: https://www.youtube.com/watch?v=wtAFyxyGmAo
Notebook + Data : Programme - Notebook - Données
Statistique descriptive avec Julia (StatsBase, StatsPlots)
2026-04-12 (Tag:RK-TR-clCQg)
Machine learning. Data science. Exploration des outils de statistique descriptive et de représentation graphique des packages « StatsBase » et « StatsPlots ». Importation et transformation des données, calcul des indicateurs univariés usuels (moyenne, écart-type, médiane, etc.), statistiques bivariés (corrélation, spearman,…), graphiques statistiques (histogrammes, densité estimée, boxplot, nuages de points, heatmap matrice des corrélations, pairplot, etc.). Les librairies répondent parfaitement à ce que l’on est en droit d’attendre dans le domaine.
Lien vidéo: https://www.youtube.com/watch?v=RK-TR-clCQg
Notebook + Data : Programme - Notebook - Données
Connexion VS Code – Google Colab (Notebook Jupyter)
2026-04-10 (Tag:pNDU6SL_x5o)
Machine learning. Data science. Création d’un notebook sous l’éditeur « VS Code » en utilisant comme moteur sous-jacent « Google Colab » via l’extension « Colab ». Nous avons utilisé l’interpréteur Python, mais nous aurions pu tout aussi bien nous appuyer sur R ou sur Julia. A la première utilisation, il faut bien sûr se connecter à Google en renseignant son login et son mot de passe. Par la suite, comme nous pouvons le constater dans ce tutoriel, le dispositif est totalement transparent et très facile à mettre en œuvre.
Lien vidéo: https://www.youtube.com/watch?v=pNDU6SL_x5o
Notebook + Data : Programme - Notebook - Données
Création d’un environnement Julia (Notebook Jupyter / VS Code)
2026-04-09 (Tag:jZBtDRHs4lg)
Machine learning. Data Science. Création d’un environnement Julia spécifique à un projet sur une machine locale. Installation des packages, avec en particulier « IJulia » qui permet d’associer le langage Julia à l’écosystème Jupyter Notebook. Création d’un notebook « .ipynb » sous VS Code, connexion avec l’environnement, édition comme on le ferait avec tout notebook (code, texte, markdown). La configuration est définie par des fichiers « .toml » (Project.toml ; Manifest.toml) que l’on peut par la suite diffuser, nous permettant ainsi de partager avec d’autres personnes notre environnement de travail.
Lien vidéo: https://www.youtube.com/watch?v=jZBtDRHs4lg
Notebook + Data : Programme - Notebook - Données
Manipulation des DataFrames sous Julia
2026-04-07 (Tag:W6abDTi7Mw8)
Machine learning. Data science. Manipulation des data frames dans un notebook Julia (sous Google Colab) Importation des données (fichier .xlsx via le module XLSX) ; inspection du dataset ; accès indicés ; projection ; restrictions à l’aide de conditions booléennes simples ou composées (et / ou) ; tris croissants ou décroissants à l’aide d’un ou plusieurs critères ; calculs sur regroupements. Bilan : l’outil est très simple d’utilisation, les aficionados de R ou de Python / Pandas ne sont pas dépaysés.
Lien vidéo: https://www.youtube.com/watch?v=W6abDTi7Mw8
Notebook + Data : Programme - Notebook - Données
Julia vs. Python – Performances comparées
2026-04-05 (Tag:Zl_NkLKIOls)
Comparaison des performances des technologies sous-jacentes aux langages de programmation Julia et Python. Mesures des temps d’exécution dans l’implémentation d’un tri à bulles où sont mis à l’épreuve principalement : l’accès aux valeurs d’une liste (vecteur) (lecture, écriture), la réalisation de boucles for imbriquées, la gestion des branchements conditionnels. Conclusion dans ce contexte précis : la technologie de Julia, avec une vraie compilation à la volée (code machine) et une optimisation avancée, surclasse celle de Python (qui passe par du byte code exécuté par un runtime).
Lien vidéo: https://www.youtube.com/watch?v=Zl_NkLKIOls
Notebook + Data : Programme - Notebook - Données
Optimisation des hyperparamètres en ML avec « optuna » (Scikit-learn / Python)
2026-04-04 (Tag:oOFMcUZDz0o)
Machine learning. Data science. Le package « optuna » est une librairie Python dédiée à l’optimisation des hyperparamètres des modèles de machine learning. Il s’appuie sur des mécanismes plus sophistiqués que la simple recherche au hasard ou en grille et, c’est ce qui nous intéresse dans cette vidéo, il est en mesure de produire un dashboard qui retrace les tenants et aboutissants de nos expérimentations. Il fournit ainsi une expertise très importante sur la teneur des résultats. Parce qu’en définitive, ce n’est pas tant la performance ponctuelle qui nous intéresse, mais plutôt l’étude du comportement de l’algorithme en fonction des plages de valeurs prises par les hyperparamètres étudiés.
Lien vidéo: https://www.youtube.com/watch?v=oOFMcUZDz0o
Notebook + Data : Programme - Notebook - Données
Reranking appliqué à la réponse aux QCM (Hugging Face / Transformers)
2026-04-03 (Tag:mGCM3v8K7FU)
Machine Learning. Data Science. NLP - natural language processing. Text Mining. Technologie « reranker » basé sur les « cross-encoder » pour affiner les réponses des requêtes. Détournement d’usage avec une utilisation dans le cadre de la réponse automatique aux QCM. Notre exemple s’appuie sur le modèle pré-entraîné multilingue « BAAI/bge-reranker-v2-m3 ». D’autres outils sont disponibles sur « Hugging Face ». Plutôt que l’utilisation du package « FlagEmbedding », nous avons préféré nous appuyer directement sur « transformers » qui est sous-jacent à la technologie.
Lien vidéo: https://www.youtube.com/watch?v=mGCM3v8K7FU
Notebook + Data : Programme - Notebook - Données
Processus data parallélisé avec « RAY / DATA » (Python)
2026-03-23 (Tag:Kow0xQIgybM)
Machine Learning. Data Science. « Ray Data » est un module de la librairie « Ray » qui fournit des outils pour le traitement des données à grande échelle de manière distribuée / parallélisée. Nous explorons la capacité de l’outil à tirer parti des processeurs multicœurs dans cette vidéo. Le travail de préparation et de découpage en blocs des données est délégué à la structure « ray data », qui sait gérer les exécutions en streaming (qui ne nécessite pas de charger les données en mémoire). Notre rôle revient simplement à définir la fonction « call back » qui doit traiter chaque instance, ou chaque bloc d’instances si nous souhaitons effectuer un traitement par batch. L’expérimentation montre que la parallélisation est effective. En effet, l’augmentation des ressources de calcul (nombre de cœurs en ce qui nous concerne) permet de réduire les temps d’exécution.
Lien vidéo: https://www.youtube.com/watch?v=Kow0xQIgybM
Notebook + Data : Programme - Notebook - Données
Parallélisation des flux de traitements avec « ray » (Python)
2026-03-01 (Tag:UdacCCmipRo)
Machine Learning. Data Science. Un exemple réaliste de parallélisation des flux de traitements avec « ray », en exploitant les capacités multicœurs de nos machines. Parsing de fichiers d’emails listés dans un dossier (The Enron Email Dataset), calcul à la volée de la polarité des sentiments en utilisant la librairie NLTK, transformation des résultats sous la forme d’un data frame Pandas. L’adaptation du programme séquentiel en une structure parallélisée requiert peu d’efforts, l’idée est d’utiliser la notion d’Actors de « ray », une classe de calcul qui représente un « worker » (un exécuteur de tâches). Nous dispatchons alors les données en blocs, et nous sollicitons autant de « workers » qu’il y a de sous-parties des données. Le gain de la version parallélisée par rapport au programme séquentiel est vraiment bluffant.
Lien vidéo: https://www.youtube.com/watch?v=UdacCCmipRo
Notebook + Data : Programme - Notebook - Données
Multiprocessing avec la librairie « Ray » pour Python
2026-02-20 (Tag:SZ14t6qSyxs)
Machine learning. Data Science. « Ray » est un framework open source conçu pour scaler des applications Python et ML (dixit COPILOT). Dans cette vidéo, nous nous intéressons sur la définition des applications multiprocessus en parallélisant une procédure de recherche de minimum dans un vecteur numérique numpy, via un algorithme de tri à bulles (volontairement défavorable). 3 approches sont comparées : un algorithme séquentiel ; une approche multiprocessus avec la librairie « multiprocessing » de Python ; une approche parallèle avec « Ray ». Sans surprise, les algorithmes parallélisés se révèlent d’autant plus efficaces que les volumétries augmentent. Et « Ray », initialement pénalisé par la lourdeur de son initialisation, rattrape « multiprocessing » lorsque les effectifs deviennent importants.
Lien vidéo: https://www.youtube.com/watch?v=SZ14t6qSyxs
Notebook + Fichier YAML : Programme - Notebook - Données
Analyse discriminante PLS « from scratch » avec ChatGPT (Python)
2026-02-17 (Tag:YLh5gsmOFkQ)
Machine learning. Data science. Classification supervisée. Analyse discriminante PLS, approche en deux étapes : régression PLS [partial least squares], analyse discriminante linéaire à partir des coordonnées factorielles des individus ; le nombre de composantes à utiliser est un paramètre de l’algorithme. Production d’un code Python d’implémentation de la méthode à partir de requêtes ChatGPT. Inspection de la solution proposée, évaluation sur un jeu de données exemple, comparaison des résultats avec ceux de TANAGRA. La puissance de l’IA générative est bluffante. Elle pose des questions sur la formation des étudiants [juniors], sur leur évaluation, mais aussi interpelle sur la place qu’ils peuvent occuper lorsqu’ils débutent dans les entreprises.
Lien vidéo: https://www.youtube.com/watch?v=YLh5gsmOFkQ
Notebook + Fichier YAML : Programme - Notebook - Données
Analyse discriminante avec « discrimintools » (Python)
2026-02-16 (Tag:NvdjH1fRRE0)
Machine learning. Data Science. Présentation de la librairie « discrimintools » pour Python. Elle implémente différentes variantes de l’analyse discriminante. Dans cette vidéo, nous explorons les fonctionnalités de DISCRIM, analyse discriminante linéaire prédictive, qui sait appréhender le cas des variables explicatives qualitatives ; la sélection de variables avec STEPDISC ; l’analyse factorielle discriminante avec CANDISC. La librairie « discrimintools » se distingue aussi par la qualité de sa documentation (présentation des approches, description des API).
Lien vidéo: https://www.youtube.com/watch?v=NvdjH1fRRE0
Notebook + Fichier YAML : Programme - Notebook - Données
Règles d’association avec Knime – Données de transactions
2026-01-24 (Tag:I-L2k_lzopQ)
Machine learning. Data Mining. Data Science. Extraction des règles d’association à partir de données de transactions avec le composant « Association Rule Learner » de KNIME. La particularité du format de données de transactions, leur préparation spécifique sous la forme de « TIDList » pour pouvoir le présenter à l’outil. Le paramétrage et la génération des règles. Comparaison des résultats avec ceux du package « arules » pour R.
Lien vidéo: https://www.youtube.com/watch?v=rQ7z-G7qoV0
Notebook + Fichier YAML : Programme - Notebook - Données
Règles d’association avec KNIME
2026-01-21 (Tag:I-L2k_lzopQ)
Machine learning. Data Mining. Data Science. Extraction des règles d’association à partir de données tabulaires avec le composant « Association Rule Learner » de KNIME. La préparation spécifique des données (BitVector) pour pouvoir les présenter à l’outil. Le paramétrage, la génération et la récupération des règles que l’on peut copier dans un tableur pour réaliser des post-traitements, notamment les calculs liés aux différentes mesures d’évaluation des règles.
Lien vidéo: https://www.youtube.com/watch?v=I-L2k_lzopQ
Notebook + Fichier YAML : Programme - Notebook - Données
Détection des anomalies – Isolation Forest et Local Outlier Factor (Python)
2026-01-15 (Tag:qCaA6vGDRUw)
Machine Learning. Data Science. La problématique de la détection des anomalies en machine learning, applicable par exemple à la sécurité informatique (détection des intrusions). Description du comportement des méthodes « Isolation Forest » et « Local Outlier Factor » sur un exemple synthétique. Les approches fonctionnent plutôt bien, elles attribuent des scores d’anomalie plus élevés aux points suspects. La difficulté vient de la définition du seuil qui permet de décider si un point est un « inlier » (observation licite) ou « outlier » (atypique). J’essaie de montrer comment palier cela en utilisant des outils graphiques pour ajuster judicieusement ce seuil.
Lien vidéo: https://www.youtube.com/watch?v=qCaA6vGDRUw
Notebook + Fichier YAML : Programme - Notebook - Données
Isolation Forest
2026-01-14 (Tag:6lmdp57sRsk)
Machine Learning. Data Science. Détection des outliers. Isolation forest une méthode de détection des anomalies, des points atypiques. Elle isole les observations en créant une multitude d'arbres aléatoirement. Les anomalies, étant rares et différentes, sont généralement isolées plus rapidement dans des feuilles survenant dans les parties hautes de l'arbre. Le fonctionnement de l'approche est décrit sur un jeu de données réaliste.
Document (pdf): Isolation Forest
Données et programme : Programme et Données
Connexion entre Python (notebook) et Excel via « xlwings »
2025-12-22 (Tag:feDNuaLVDLk)
Machine learning. Data Science. Analyse discriminante linéaire. Programmation de macros et de fonctions personnalisées en Python pour Excel via l’add-in « xlwings lite ». Ce dernier est une version simplifiée de « xlwings ». Il permet d’utiliser Python sous Excel sans avoir à installer nous même Python. De même, il n’est pas nécessaire d’installer explicitement les packages spécialisés [la liste des packages supportés est indiquée sur le site], il suffit de les spécifier dans un fichier « requirements.txt ». J’illustre l’efficacité de « xlwings lite » en programmant une fonction personnalisée qui prend en entrée (a) une plage de données représentant un data frame Pandas, (b) le nom de la variable cible. Elle renvoie en sortie les coefficients de l’analyse discriminante linéaire [je me suis restreint à une classification supervisée binaire] sous la forme d’un data frame Pandas. Il s’agit bien d’une fonction c.-à-d. la mise à jour des données entraîne une mise à jour instantanée des coefficients calculés. La facilité d’utilisation du dispositif « xlwings lite » est bluffante.
Lien vidéo: https://www.youtube.com/watch?v=feDNuaLVDLk
Notebook + Fichier YAML : Programme - Notebook - Données
Connexion entre Python (notebook) et Excel via « xlwings »
2025-12-21 (Tag:-ONGM2pg3tc)
Machine learning. Data science. Analyse discriminante linéaire. Connexion entre un Notebook Jupyter Python (j’utilise l’éditeur VS Code) et Excel via le package « xlwings ». Envoi des données du notebook vers le tableur ; puis, inversement, importation d’un dataset dans un classeur Excel ouvert dans un data frame Pandas exploitable dans le notebook courant. Un exemple de prédiction de l’occurrence de l’AVC chez des patients à partir de leurs caractéristiques biologiques et leur comportement permet de situer l’intérêt de faire coopérer les deux outils, en particulier dans un cadre pédagogique d’initiation à l’analyse prédictive.
Lien vidéo: https://www.youtube.com/watch?v=-ONGM2pg3tc
Notebook + Fichier YAML : Programme - Notebook - Données
Extensions Weka et Scikit-Learn pour Knime
2025-12-18 (Tag:mZTtocYu2SE)
Machine Learning. Data Science. Utilisation des extensions Weka Data Mining et Scikit-Learn (Sklearn) sous KNIME. Installation des extensions, localisation dans l’arborescence des composants. Expérimentation du dispositif dans une démarche d’analyse prédictive consistant à prédire la nature d’un courriel (spam ou ham) à partir de ses caractéristiques. Quel que soit l’outil utilisé (algorithme natif de Knime, Weka ou Sklearn), le processus est toujours le même : introduction d’un composant « learner » pour l’entraînement du modèle, utilisation d’un « predictor » pour son application en prédiction. Dans notre exemple, nous comparons les mérites de différents expressions de la régression logistique (ou apparentés), nous les évaluons à la fois en prédiction (matrice de confusion) et en « scoring » (courbe roc et critère auc).
Lien vidéo: https://www.youtube.com/watch?v=mZTtocYu2SE
Notebook + Fichier YAML : Programme - Notebook - Données
NLP – Sentence Transformers Multilingue – Hugging Face (Python)
2025-11-28 (Tag:buq9S0LFyuI)
Machine Learning. Data Science. NLP (natural language processing). Text Mining. Python. Utilisation des « Sentence Transformers » (SBERT), modèle pré-entraîné récupéré sur la plateforme « Hugging Face » (paraphrase-multilingual-MiniLM-L12-v2), pour produire une représentation vectorielle des documents (document embedding) rédigés dans des langues différentes. Ainsi, des documents à la sémantique proche se voient attribués des vecteurs de descriptions similaires, même s'ils sont exprimés dans les langues différentes. Pour évaluer la qualité du dispositif, nous le mettons à contribution dans une démarche de catégorisation de documents multilingues.
Lien vidéo: https://www.youtube.com/watch?v=buq9S0LFyuI
Notebook + Fichier YAML : Programme - Notebook - Données
NLP – Sentence Transformers (SBERT) – Hugging Face (Python)
2025-11-27 (Tag:a9uoSi1yf-U)
Machine Learning. Data Science. NLP (natural language processing). Text Mining. Python. Utilisation des « Sentence Transformers » (SBERT), modèle pré-entraîné récupéré sur la plateforme « Hugging Face », pour produire une représentation vectorielle des documents (document embedding) propice à l’application des algorithmes de machine learning. Création d’un environnement dédié (conda) ; choix, chargement et stockage du modèle pré-entraîné (all-MiniLM-L6-v2) ; traduction du corpus en matrice numérique ; catégorisation de documents à l’aide de la régression logistique. Le dispositif et les résultats sont à mettre en miroir avec la même étude menée à l’aide du logiciel Orange Data Mining
Lien vidéo: https://www.youtube.com/watch?v=a9uoSi1yf-U
Notebook + Fichier YAML : Programme - Notebook - Données
Orange Data Mining – NLP – Sentence Transformers (SBERT)
2025-11-26 (Tag:JVbzyU42ny4)
Machine learning. Data Science. NLP (natural language processing). Text Mining. Utilisation des « Sentence Transformers » (SBERT), modèle pré-entraîné, pour produire une représentation vectorielle des documents (document embedding) propice à l’application des algorithmes de machine learning. Dans cette vidéo, nous traitons de la catégorisation de documents (text categorization) via une régression logistique (données Reuters). Les « Sentence Transformers » sont censés capter le sens des documents. Nous vérifions si le modèle prédictif basé sur cette représentation, sur le même problème, est meilleur que celui s’appuyant sur les « bag-of-words » (décrite dans une vidéo récente : Orange Data Mining - NLP - Catégorisation). Nous utilisons le logiciel Orange Data Mining.
Lien vidéo: https://www.youtube.com/watch?v=JVbzyU42ny4
Notebook + Fichier YAML : Programme - Notebook - Données
Orange Data Mining - NLP - Catégorisation de documents
2025-11-24 (Tag:pbwPlvVolmQ)
Machine Learning. Data Science. NLP (natural language processing). Text Mining. Catégorisation de documents à l’aide du logiciel Orange Data Mining. Importation du package spécialisé « text » pour le traitement des données textuelles. Visualisation Word Cloud. Preprocessing des documents, représentation bag of words (sac de mots), construction de la matrice documents-termes (pondération binaire). Analyse prédictive à l’aide de la régression logistique, lecture des coefficients pour l’interprétation du modèle de classement. Evaluation des performances avec le schéma train / test.
Lien vidéo: https://www.youtube.com/watch?v=pbwPlvVolmQ
Notebook + Fichier YAML : Programme - Notebook - Données
Weka Data Mining – Le package « Python Weka Wrapper 3 »
2025-11-10 (Tag:45V2A_kc2vs)
Machine Learning. Data Science. Présentation du package « python-weka-wrapper3 », qui nous donne accès aux fonctionnalités de Weka, aux très nombreux algorithmes de machine learning notamment, dans un programme Python. Création d’un environnement dédié (conda). Puis description des tâches usuelles d’une démarche d’analyse prédictive : importation des données (fichier « arff », une sorte de fichier CSV qui intègre un dictionnaire des variables), partition en échantillons d’apprentissage et de test, entraînement du modèle (SVM avec un noyau linéaire), évaluation (accuracy, matrice de confusion) ; indentification du meilleur paramétrage avec l’outil « GridSearchCV » de Weka ; comparaison des performances de plusieurs algorithmes (SVM linéaire, arbre de décision, régression logistique, K-NN).
Lien vidéo: https://www.youtube.com/watch?v=45V2A_kc2vs
Notebook + Fichier YAML : Programme - Notebook - Données
Weka Data Mining – Analyse prédictive
2025-11-01 (Tag:nmXB1W83XuE)
Machine learning. Data Science. Présentation du logiciel Weka dans le cadre d’une analyse prédictive. Importation des données (CSV), partition en apprentissage-test, modélisation (régression logistique), évaluation en test (matrice de confusion, rappel, précision, accuracy, taux d’erreur), différentes courbes (précision-rappel, roc, lift cumulé), récupération des classes prédites.
Lien vidéo: https://www.youtube.com/watch?v=nmXB1W83XuE
Notebook + Fichier YAML : Programme - Notebook - Données
Le debugger de VS Code – Programmation Python
2025-10-31 (Tag:FqTiVdkRNS4)
Machine learning. Data Science. Présentation du debugger de VS Code pour le débogage des programmes en Python. L’outil permet de suivre à la trace le (bon) déroulement de notre code. Plusieurs aspects sont détaillés dans cette vidéo : le placement de points d’arrêts pour interrompre le programme à des endroits spécifiques, l’exécution pas à pas qui permet de suivre le cheminement des instructions, l’inspection de l’état des variables (création, valeurs prises) à chaque étape. Le débugger permet de remplacer avantageusement la pratique souvent répandue qui consiste à disséminer plus ou moins judicieusement des print() dans nos programmes.
Lien vidéo: https://www.youtube.com/watch?v=FqTiVdkRNS4
Notebook + Fichier YAML : Programme - Notebook - Données
Le debugger de RStudio – Programmation R
2025-10-30 (Tag:K-KSxHE1t6U)
Machine learning. Data Science. Présentation du debugger de RStudio. L’outil permet de suivre à la trace le (bon) déroulement d’un programme R que nous développons. Plusieurs aspects sont détaillés dans cette vidéo : le placement de points d’arrêts pour interrompre le programme à des endroits spécifiques, l’exécution pas à pas qui permet de suivre le cheminement des instructions, l’inspection de l’état des variables (création, valeurs prises) à chaque étape. Le débugger permet de remplacer avantageusement la pratique souvent répandue qui consiste à disséminer plus ou moins judicieusement des print() dans nos programmes.
Lien vidéo: https://www.youtube.com/watch?v=K-KSxHE1t6U
Notebook + Fichier YAML : Programme - Notebook - Données
Le profiler de RStudio – Programmation R
2025-10-30 (Tag:q8N13RyFslc)
Machine learning. Data Science. Utilisation de l’outil de profilage de RStudio (« profiler ») pour l’optimisation du temps d’exécution d’un programme en langage R. Identification des goulots d’étranglements, les différentes solutions pour améliorer la rapidité des traitements. Exemple illustratif avec l’implémentation d’un leave-one-out avec l’analyse discriminante (lda) du package MASS. Le profiler a permis de mettre en évidence les parties critiques du code. Nous obtenons des gains substantiels en les retravaillant. Ici il s’agissait simplement de modifier le prototype de la fonction appelée pour l’apprentissage, associer à un choix approprié des structures de données.
Lien vidéo: https://www.youtube.com/watch?v=q8N13RyFslc
Notebook + Fichier YAML : Programme - Notebook - Données
Positron – L'EDI Data Science pour R « et » Python
2025-10-19 (Tag:5keUBMSoWxU)
Positron est un EDI (environnement de développement intégré) pour la data science. Il est édité par les auteurs de RStudio (Posit PBC). Il permet de développer de manière indifférenciée [dans le même environnement de travail] des projets de data science / machine learning en langage R et langage Python, avec des fonctionnalités étendues (cf. « Features » du site web). Dans cette vidéo, nous explorons de manière très succincte la possibilité d’éditer des notebook (.ipynb) pour R et pour Python (environnement Conda). Pour avoir un peu plus de recul, j’ai demandé à ChatGPT de faire un petit comparatif avec des outils de référence tels que RStudio et VSCode.
Lien vidéo: https://www.youtube.com/watch?v=5keUBMSoWxU
Notebook + Fichier YAML : Programme - Notebook - Données
Orange Data Mining – Analyse des correspondances multiples (ACM)
2025-10-16 (Tag:62NJToD3O5k)
Machine learning. Analyse des données. Réalisation d’une ACM (ou AFCM – Analyse [factorielle] des correspondances multiples) sous Orange Data Mining. Obtention des coordonnées des modalités des variables dans l’espace factoriel. Déduction des coordonnées des individus (qui n’est pas fourni nativement) via un script Python. Le widget « Python Script » permet d’élargir considérablement les possibilités de l’outil. Les résultats sont mis en miroir avec ceux du package « FactoMineR » pour R. En effet, Orange Data Mining s’appuie sur une approche numérique différente de notre mode de calcul usuel.
Lien vidéo: https://www.youtube.com/watch?v=62NJToD3O5k
Notebook + Fichier YAML : Programme - Notebook - Données
Orange Data Mining – Analyse en composantes principales (ACP)
2025-10-13 (Tag:x6ySioivcaw)
Machine learning. Analyse des données. Réalisation d’une ACP (analyse en composantes principales) sous Orange Data Mining. Screeplot, choix du nombre de composantes. Projection des individus dans les plans factoriels. Mise en avant des options d’illustration pour mieux situer le positionnement relatif des points (couleurs, taille,…). Elaboration du cercle des corrélations (qui n’existe pas nativement). Encore une fois les fonctionnalités interactives du logiciel font merveille pour une exploration dynamique (ludique même) des données.
Lien vidéo: https://www.youtube.com/watch?v=x6ySioivcaw
Notebook + Fichier YAML : Programme - Notebook - Données
Orange Data Mining – Courbe ROC et Courbe de Gain
2025-10-11 (Tag:FUeOP9Tbj_0)
Machine learning. Sous Orange Data Mining, construction des courbes ROC (receiver operating characteristic) et de gain (lift cumulé) en analyse prédictive. Deux courbes d’aspects très similaires, mais qui ne sont pas construites de la même manière, qui n’ont pas la même finalité, et qui n’ont pas la même lecture. La première est plutôt un outil d’évaluation, associée notamment au critère AUC (aire sous la courbe) (bien qu’elle se prête à d’autres usages aussi), la seconde est un outil opérationnel utilisé dans le ciblage (souvent en marketing, mais dans tout domaine où il y a un arbitrage à réaliser dans une démarche de ciblage). La mise en œuvre sous Orange est très facile, y compris lorsque l’on souhaite comparer les performances de différents algorithmes.
Lien vidéo: https://www.youtube.com/watch?v=FUeOP9Tbj_0
Notebook + Fichier YAML : Programme - Notebook - Données
Orange Data Mining – Grille de score
2025-10-09 (Tag:4PVpYoKfNr0)
Machine learning. Construction d’un modèle prédictif sous la forme d’une grille de score avec le logiciel Orange Data Mining. Lien entre les coefficients d’une régression logistique (ou tout classifieur pouvant s’exprimer sous la forme d’une combinaison linéaire des descripteurs) et les « points » d’une grille d’affectation. Orange introduit de surcroît la sélection de variable, le recodage automatique, la possibilité de définir le nombre de critère à introduire dans grille et l’amplitude des valeurs. Le système de points est explicite et lisible, mais il s’agit bien d’un modèle prédictif dont on peut apprécier les performances sur un échantillon test.
Lien vidéo: https://www.youtube.com/watch?v=4PVpYoKfNr0
Notebook + Fichier YAML : Programme - Notebook - Données
Orange Data Mining – Clustering – CAH des variables
2025-10-06 (Tag:Z7Wwcwts6MI)
Machine learning. Clustering de variables quantitatives via la CAH (classification ascendante hiérarchique) avec le logiciel Orange Data Mining. Définition de la distance entre variables basée sur le coefficient de corrélation de Pearson. Construction de la partition. Visualisation de la solution dans un plan « factoriel » défini à partir du positionnement multidimensionnel (MDS – multidimensional scaling). Visualisation dynamique de la solution à partir des modifications interactives de la sélection dans le dendrogramme. Extension des fonctionnalités avec l'introduction du composant Python Script dans le workflow.
Lien vidéo: https://www.youtube.com/watch?v=Z7Wwcwts6MI
Notebook + Fichier YAML : Programme - Notebook - Données
Orange Data Mining – Clustering – CAH des individus
2025-10-05 (Tag:sMLoMc2VZ-c)
Machine learning. Clustering. CAH (classification ascendante hiérarchique) [des individus] avec Orange Data Mining. Calcul des distances par paires, construction du dendrogramme, visualisation des groupes dans le premier plan factoriel. * Exploration dynamique avec modification interactive de la solution [nombre de groupes] et conséquences sur les positions des clusters dans le plan*. Identification des variables importantes dans la définition de la partition. Caractérisation des groupes via une représentation graphie (boxplot). Ici aussi, possibilité d’étude temps réel via la manipulation interactive du dendrogramme.
Lien vidéo: https://www.youtube.com/watch?v=sMLoMc2VZ-c
Notebook + Fichier YAML : Programme - Notebook - Données
Orange Data Mining – Cartes de Kohonen (SOM)
2025-10-01 (Tag:kPOzoUDvWWc)
Machine learning. Apprentissage non-supervisé. Implémentation des Cartes de Kohonen (SOM – Self Organizing Maps) sous Orange Data Mining. Paramétrage. Lecture interprétation des résultats à travers les représentations graphiques associées à la carte (variables actives et illustratives). L’approche combine les avantages d’une technique de réduction de dimension et de clustering (pré-clustering) puisque chaque nœud représente un sous-ensemble d’observations. Il est possible de réaliser une CAH (classification ascendante hiérarchique) via la matrice des distances déduite de la carte.
Lien vidéo: https://www.youtube.com/watch?v=kPOzoUDvWWc
Notebook + Fichier YAML : Programme - Notebook - Données
Orange Data Mining – Clustering avec les K-Means
2025-10-01 (Tag:kyJGRZGKVPs)
Machine learning. Clustering avec la méthode des K-Means. Importation et inspection des données, préparation, spécification du nombre de clusters, identification des variables impactantes, interprétation des résultats, statistiques descriptives et graphiques conditionnellement aux groupes d’appartenance.
Lien vidéo: https://www.youtube.com/watch?v=kyJGRZGKVPs
Notebook + Fichier YAML : Programme - Notebook - Données
Orange Data Mining - Comparaison de modèles prédictifs
2025-09-29 (Tag:FxGIT5sYAyo)
Machine Learning. Workflow (simple) pour la comparaison de modèles prédictifs sur un dataset (arbres de décision, random forest, régression logistique, SVM [avec différents noyaux]). Validation croisée. Choix de la métrique à utiliser. Création d’un rapport à partir des résultats. Elaboration du classifieur définitif sur la totalité des données, la régression logistique. Expertise des coefficients du modèle.
Lien vidéo: https://www.youtube.com/watch?v=FxGIT5sYAyo
Notebook + Fichier YAML : Programme - Notebook - Données
Orange Data Mining - Arbres de décision
2025-09-25 (Tag:FMkPBGtA_mg)
Machine Learning. Construction des arbres de décision avec le logiciel « Orange Data Mining ». Création d’un workflow. Importation des données (fichier CSV). Description statistique. Spécification et entraînement d’un arbre de décision. Fonctionnalité très intéressante, possibilité d’explorer interactivement les sous-populations associés aux sommets de l’arbre. Evaluation des performances, schémas holdout et validation croisée. Exploration interactive encore une fois des sous-ensembles associés aux différentes situations de la matrice de confusion.
Lien vidéo: https://www.youtube.com/watch?v=FMkPBGtA_mg
Notebook + Fichier YAML : Programme - Notebook - Données
Règles d’association avec « arules » pour R
2025-03-25 (Tag:DduPerQqVeo)
Extraction des itemsets fréquents et des règles d’association, méthodes utilisées entres autres dans les systèmes de recommandations, à partir de données tabulaires avec la librairie « arules » pour R. Organisation initiale du fichier (tableau individus x variables), typage des variables (en type « factor » de R), extraction et post-traitement des itemsets et des règles, notamment via leur transformation en structure data frame de R (filtrage, tri, etc., tout type de traitement qui peut s’appliquer à un data frame). Le tutoriel a été réalisé sous Google Colab avec le moteur d’exécution R.
Lien vidéo: https://www.youtube.com/watch?v=DduPerQqVeo
Notebook + Fichier YAML : Programme - Notebook - Données
Utiliser R avec Google Colab
2025-03-10 (Tag:PEKfz66ujvg)
Configurer Google Colab pour l’utilisation de l’interpréteur de langage R (Exécution / Modifier le type d'exécution). Création d’un notebook : chargement des packages, importation des données, saisies des commandes et affichage des résultats. Installation à la volée de packages additionnels.
Lien vidéo: https://www.youtube.com/watch?v=PEKfz66ujvg
Notebook + Fichier YAML : Programme - Notebook - Données
Sequential Pattern Mining avec PySpark (Spark / Python)
2025-03-06 (Tag:vdUBP_iQHX4)
Extraction des motifs séquentiels à l’aide de la librairie PySpark pour Python. La notion de motifs séquentiels, des groupes d’évènements ordonnés chronologiquement (ex. les contenus des paniers d’achats d’une personne au cours des différentes visites dans une boutique), le lien avec la recherche des itemsets fréquents et les règles d’association, l’introduction d’une dimension temporelle (chronologique surtout), le changement d’individu statistique (on passe de la transaction à la personne qui effectue une succession de transactions). La préparation spécifique des données essentielle au bon fonctionnement de l’algorithme PrefixSpan de PySpark. L’analyse des sorties, en particulier leur filtrage pour mettre en évidence les résultats qui nous intéressent.
Lien vidéo: https://www.youtube.com/watch?v=vdUBP_iQHX4
Notebook + Fichier YAML : Programme - Notebook - Données
Règles d’association avec PySpark (Spark / Python)
2025-03-06 (Tag:K_b2FkYDjpk)
Extraction des itemsets fréquents et des règles d’association à partir d’un fichier de transactions avec la librairie « PySpark » pour Python, utilisés notamment dans le contexte des systèmes de recommandation. Organisation initiale du fichier de données (paniers d’achats), transformation pour pouvoir le présenter à une version parallélisée de FPGrowth. Rôle important des paramètres « support min » et « confiance min » dans la génération des solutions. Post-filtrage des itemsets et des règles à partir de leurs caractéristiques (présence des produits, cardinal des itemsets, critères numériques …). Le format des itemsets et des règles (DataFrame PySpark) nous permet de manipuler à loisir les résultats.
Lien vidéo: https://www.youtube.com/watch?v=K_b2FkYDjpk
Notebook + Fichier YAML : Programme - Notebook - Données
Stacking de classifieurs avec « mlxtend – Python »
2025-03-04 (Tag:o-KdfNqebWk)
Stacking de modèles à l’aide la librairie « mlxtend » pour Python. L’idée est de produire un meta-classifieur pour associer des modèles élaborés à partir d’un échantillon d’apprentissage. Dans notre cas, nous utilisons une régression logistique, ce qui revient à déterminer la pondération la plus efficace dans le mécanisme de combinaison. Utiliser les données d’apprentissage pour ce second entraînement reviendrait à favoriser les modèles qui font du sur-apprentissage. « mlxtend » propose une approche basée sur la validation croisée pour lever cet écueil. La vidéo aborde de plus les outils de « mlxtend » pour l’évaluation des performances (0.632 et 0.632+ bootstrap) et la comparaison de modèles (5x2cv paired t-test et f-test) via des procédures de rééchantillonnage.
Lien vidéo: https://www.youtube.com/watch?v=o-KdfNqebWk
Notebook + Fichier YAML : Programme - Notebook - Données
Règles d’association avec « mlxtend – Python »
2025-03-03 (Tag:QBjJwwPBBXk)
Extraction des itemsets fréquents et des règles d’association à partir d’un fichier de transactions avec la librairie « mlxtend » pour Python, utilisés notamment dans le contexte des systèmes de recommandation. Organisation du fichier de données (paniers d’achats), transformation nécessaire en tableau de booléens avant la présentation aux algorithmes. Rôle important des paramètres « support min » et « confiance min » dans la génération des solutions. Post-filtrage des itemsets et des règles à partir de leurs caractéristiques (présence des produits, cardinal des itemsets, critères numériques …). Le format des itemsets et des règles (DataFrame Pandas) nous permet de manipuler à loisir les résultats.
Lien vidéo: https://www.youtube.com/watch?v=QBjJwwPBBXk
Notebook + Fichier YAML : Programme - Notebook - Données
Machine learning avec PySpark – Spark / MLlib
2025-02-02 (Tag:dhdw_HOaLcg)
Mise en oeuvre d’une méthode de machine learning (une régression logistique) de la librairie MLlib via l’API Python PySpark (3.5.4) pour Spark. Les fichiers d’apprentissage et de test se présentent au format CSV usuel (avec en-tête, séparateur de colonne « ; », variable cible codée en chaînes de caractères). Nous mettons l’accent sur la préparation des données, assez spécifique, cruciale pour le bon fonctionnement du dispositif. La vidéo décrit dans ses aspects les plus schématiques les étapes d’entraînement sur l’échantillon d’apprentissage, de prédiction et d’évaluation sur l’échantillon test. L’idée est de disposer d’un exemple simple facile à reproduire.
Lien vidéo: https://www.youtube.com/watch?v=dhdw_HOaLcg
Notebook + Fichier YAML : Programme - Notebook - Données
Manipulation des DataFrames PySpark (Spark / Python)
2025-01-31 (Tag:xyoIgxZSD0E)
Introduction à Spark SQL, un module du framework Spark pour la manipulation des données structurées, en particulier les DataFrames. Nous nous appuyons sur l’API PySpark, il permet d’interagir avec Spark via le langage de programmation Python. La configuration du dispositif est extrêmement simple : il suffit de créer un environnement (j’utilise conda) et d’y installer la librairie. L’accès au moteur de calcul est transparent pour nous. Notre code est valable que notre structure sous-jacente soit une machine locale ou un cluster de machines. Plusieurs étapes sont décrites dans la vidéo : création d’une session, chargement d’un fichier CSV, quelques filtrages et calculs statistiques (moyennes, croisement). Enfin, PySpark nous offre la possibilité de réaliser des requêtes rédigées en langage SQL.
Lien vidéo: https://www.youtube.com/watch?v=xyoIgxZSD0E
Notebook + Fichier YAML : Programme - Notebook - Données
Apply parallélisé pour DataFrame Pandas Python
2025-01-30 (Tag:t7K5fcomn8k)
Solutions de parallélisation de la fonction « apply » de Pandas qui applique séquentiellement une fonction sur des colonnes d’un DataFrame Pandas. Le cadre spécifique où les calculs sont indépendants d’une colonne à l’autre. La décomposition des traitements et la consolidation des résultats sont très simplifiées. La parallélisation est alors d’une simplicité désarmante (traduit étrangement en « embarrasingly parallel problem » en anglais). Etude des fonctions « apply » parallélisées des librairies « Modin » (avec le moteur "dask") et « Pandarallel ». Comparaison des temps de traitement sur une base benchmark. Les gains en durée d’exécution sont substantiels avec une modification négligeable du code.
Lien vidéo: https://www.youtube.com/watch?v=t7K5fcomn8k
Notebook + Fichier YAML : Programme - Notebook - Données
Embarrassingly parallel problem sous R
2025-01-19 (Tag:Vwx3wZ3gl_M)
Etude du concept de « embarrassingly parallel problem » sous R. Contrairement à ce que laisse entendre la terminologie, l’idée est de montrer qu’il est possible d’implémenter la parallélisation des calculs avec une simplicité désarmante dans certaines situations. C’est le cas notamment lorsqu’il s’agit de traiter indépendamment les uns des autres les éléments d’une structure. L’effort d’adaptation du code du séquentiel au parallèle est quasi-nul, avec à la clé des réductions de temps de traitements significatifs. Dans la vidéo, nous détaillons les différentes solutions possibles pour appliquer une fonction de transformation aux colonnes d’un data frame sous R. Les packages utilisés sont « parallel », « doParallel » et « foreach ».
Lien vidéo: https://www.youtube.com/watch?v=Vwx3wZ3gl_M
Notebook + Fichier YAML : Programme - Notebook - Données
Manipulation des données avec "data.table" (pour R)
2025-01-17 (Tag:BG9uMlyE5Ko)
Présentation et exploration des fonctionnalités du package « data.table » pour R, particulièrement performant pour la manipulation et le traitement des data frame. Mesure des durées d’exécution dans différentes configurations où l’on doit manier une base avec 9.796.862 observations et 42 descripteurs. Comparaisons avec le package « datatable » pour Python, qui s’inspire fortement de celui de R dixit la documentation. En définitive, les deux packages sont globalement équivalents, avec des spécificités propres à chacun selon la nature de l’opération.
Lien vidéo: https://www.youtube.com/watch?v=BG9uMlyE5Ko
Notebook + Fichier YAML : Programme - Notebook - Données
Manipulation des données avec "datatable" (Python)
2025-01-14 (Tag:-XpRV3QyYt8)
Description des fonctionnalités du package « datatable » pour Python. Il est inspiré du package « data.table » pour R. Il a pour particularité d’être performant sur les très grandes bases de données, notamment en parallélisant les traitements, exploitant ainsi, au moins, les capacités multicœurs de nos ordinateurs. Petite difficulté quand-même, « datatable » adopte une syntaxe assez spécifique, un peu déroutante peut-être pour les habitués de la référence « pandas ». Mais la documentation en ligne est très bien faite, avec notamment un tableau faisant le parallèle entre les deux outils. Le passage de l'un à l'autre est facilité. Notre expérimentation sur une base de 9.796.862 observations et 42 descripteurs montre que « datatable » surpasse « pandas » en rapidité de traitements. Il se montre compétitif par rapport au package « polars » qui excelle également dans la manipulation des données tabulaires.
Lien vidéo: https://www.youtube.com/watch?v=-XpRV3QyYt8
Notebook + Fichier YAML : Programme - Notebook - Données
DuckDB + Pandas - Combinaison gagnante
2025-01-13 (Tag:PUTqWDxvJ6k)
Description de DuckDB, un système de gestion de bases de données orientées colonnes, adapté pour le traitement analytique. Nous mettons l’accent sur son interfaçage avec Python, avec la possibilité de définir et exécuter des requêtes SQL sur des data frame Pandas, monotables et multitables via des jointures. A noter la facilité d’utilisation de DuckDB qui ne nécessite pas d’installation d’un serveur. Un environnement Python avec l’intégration du package dédié suffit pour monter une application. Enfin, non traité dans cette vidéo, mais souligné par de nombreuses références, DuckDB se révèle très performant pour l’appréhension des très grandes bases de données.
Lien vidéo: https://www.youtube.com/watch?v=PUTqWDxvJ6k
Notebook + Fichier YAML : Programme - Notebook - Données
Pandas vs. Polars - Performances comparées (Python)
2025-01-12 (Tag:R8T58O97z-Y)
Description de la librairie « Polars » pour Python. Elle se présente comme une alternative plus intuitive et largement plus efficace que « Pandas » pour la manipulation des data frame (données tabulaires). Comparaison des durées de traitements pour un dataset comprenant 9.796.862 observations et 42 variables (la base du challenge KDD CUP 1999, qui a été dupliquée), avec différentes opérations : chargement du fichier, filtrage, moyennes, moyennes conditionnelles, tri, comptage des valeurs. Pour la majorité des tâches, notamment grâce à sa capacité à paralléliser les opérations, la différence entre CPU Time et Wall Time est édifiante, « Polars » s’est montrée nettement plus performante.
Lien vidéo: https://www.youtube.com/watch?v=R8T58O97z-Y
Notebook + Fichier YAML : Programme - Notebook
Dataset : KDDCUP-99
Estimation et test statistiques
2025-01-11 (Tag:JBz4vJYrEre)
Un support de cours très succinct sur l’estimation (ponctuelle et par intervalle) et les tests d’hypothèses statistiques. Utilisé pour une remise à niveau en statistique inférentielle. Le document sert avant tout de repère pour la réalisation d’exercices illustratifs sous Excel, R et SAS.
Slides : Estimation et test statistiquesParallélisation des traitements avec Joblib (Python)
2024-12-30 (Tag:gQYp_CYCGVM)
Exploration des fonctionnalités de la librairie « Joblib » en matière de parallélisation des traitements. Cas d’étude avec l’implémentation de la stratégie OneVsRestClassifier pour la régression logistique multiclasse, l’algorithme sous-jacent est une régression logistique binaire basée sur un « fisher scoring ». Comparaison des durées d’exécution, (1) sans et avec la parallélisation, (2) entre deux technologies de parallélisation (processus vs. threads). Pour (1), bien que l’introduction du traitement parallèle soit significative, elle ne permet pas de réduire la durée proportionnellement au nombre de ressources demandées ; pour (2), les approches concurrentes (processus vs. threads) sont équivalentes, tout du moins pour le problème étudié.
Lien vidéo: https://www.youtube.com/watch?v=gQYp_CYCGVM
Sources : Programme - Notebook
Parallélisation Numba pour OneVsRestClassifier (Python)
2024-12-29 (Tag:OtQFfZE8Qa0)
Exploration des fonctionnalités de la librairie « Numba » (Python) pour le traitement parallèle en machine learning. Cas d’étude avec l’implémentation de la stratégie OneVsRestClassifier pour le classement multiclasse. La méthode sous-jacente est une régression logistique binaire avec l’algorithme Fisher Scoring, lui-même développé « from scratch » et « compilé » avec Numba. Mesure de la réduction du temps de traitement lors du passage à la parallélisation des calculs. Comparaison avec la classe OneVsRestClassifier de « scikit-learn » qui implémente également la parallélisation des traitements (via le paramètre n_jobs) à l’aide d’une autre technologie.
Lien vidéo: https://www.youtube.com/watch?v=OtQFfZE8Qa0
Sources : Programme - Notebook
Python rapide avec Taichi (vs. Numba)
2024-12-27 (Tag:4Z8156o6ZJ4)
Présentation de « Taichi », un package dédié à la haute performance pour la programmation Python, avec plusieurs fonctionnalités, dont la compilation à la volée (JIT – Just in Time Compiler) du code en instructions machines, ainsi que la parallélisation des calculs, etc. Dixit la documentation, la rapidité d’exécution peut surpasser celle de langages tels que le C++. Dans notre expérimentation où nous implémentons une recherche d’un minimum d’un vecteur « Numpy » en temps quadratique, les gains sont réellement spectaculaires par rapport au CPython (l’implémentation de référence en byte-code, à ne pas confondre avec Cython). Ils ne se démarquent pas en revanche par rapport aux packages équivalents tels que « Numba ». Enfin, l’adaptation du code Python à « Taichi » nécessite des contorsions qui peuvent se révéler contraignantes.
Lien vidéo: https://www.youtube.com/watch?v=4Z8156o6ZJ4
Sources : Programme - Notebook
Vectorisation des calculs – Numpy, Numba, Xarray (Python)
2024-12-26 (Tag:gcsu2sPUriU)
Principe de la vectorisation des traitements sur des grandes structures de vecteurs et matrices « numpy ». Itérations sur les valeurs avec les boucles. Accélération des calculs à l’aide du mécanisme de vectorisation. Exploitation de la « compilation » Numba de la fonction appliquée aux scalaires, avec les directives @njit et @vectorize. Utilisation de la fonctions dédiée de « xarray », plus efficace que vectorize() de « numpy ».
Lien vidéo: https://www.youtube.com/watch?v=gcsu2sPUriU
Sources : Programme - Notebook
Intégration de code C dans Python avec Cython
2024-12-23 (Tag:D__sO3x0FzQ)
Description et mise en œuvre de Cython, une extension du langage Python qui permet d’intégrer et d’interagir avec du code C dans un projet Python. Deux modes sont proposés : Pure Python, où le code reste compatible avec Python natif ; Cython où nous nous rapprochons davantage du langage C. L’installation d’un compilateur C/C++ est nécessaire. Dans ce tutoriel, je montre l’utilisation du dispositif dans un notebook, sans qu’il soit nécessaire de créer des fichiers additionnels. Les gains en temps de traitement sont spectaculaires dans le tri d’un vecteur Numpy avec des modifications mineures du code Python originel (en introduisant les déclarations de types simplement). Il est également possible d’améliorer les performances en ajustant les directives de compilation.
Lien vidéo: https://www.youtube.com/watch?v=D__sO3x0FzQ
Sources : Programme - Notebook
Python rapide avec Numba
2024-12-23 (Tag:BkJoHz0NGlE)
Présentation de Numba, un package qui réalise la compilation à la volée (JIT – Just in Time Compiler) du code Python en instructions machines. Les performances se rapprochent des langages tels que C ou Fortran. Le dispositif est très facile à mettre en œuvre, avec à la clé des gains en temps d’exécution réellement spectaculaires. Je montre cela dans un exemple de tri à bulles d’un vecteur de valeurs flottantes Numpy. Je montre également qu’il est possible de gagner encore davantage en exploitant à bon escient les possibilités de l’outil en termes de parallélisation des calculs.
Lien vidéo: https://www.youtube.com/watch?v=BkJoHz0NGlE
Sources : Programme - Notebook
Intégration de code C++ dans un projet R avec Rcpp
2024-12-09 (Tag:GEYIGcv1_dY)
Détection des goulots d’étranglement (en temps d’exécution) dans un programme R avec un profiler. Différentes pistes pour dépasser les écueils, en particulier la possibilité de réécrire en C++ les portions de code concernées. Utilisation de la librairie « Rcpp ». Installation du compilateur C++ via « RTools ». Configuration et écriture du fichier « .cpp ». Compilation, importation et utilisation dans R de la fonction compilée. Comparaison du temps traitement entre du code en R (« compilé » à la volée en Byte Code depuis R 3.4) et du code compilé C++ dans une implémentation du tri à bulles.
Lien vidéo: https://www.youtube.com/watch?v=GEYIGcv1_dY
Sources : Prog. et données
Combiner R et Python via Reticulate
2024-12-09 (Tag:nHC_Jptv3PY)
Pouvoir faire appel à du code Python dans un notebook R (.rmd). Installation et configuration préalable des outils. Accès à des objets R dans du code R, et inversement. Exemple de projet d’analyse prédictive où (1) sous R, les individus, décrits par des variables mixtes, sont projetés dans un espace factoriel via l’analyse factorielle des données mixtes du package « FactoMineR » ; (2) sous Python, modélisation de la variable cible à partir de la description factorielle via le package « Scikit-Learn ». Nous constatons que les échanges entre les 2 environnements (R et Python) sont fluides. Leur association élargit significativement nos capacités d’analyse.
Lien vidéo: https://www.youtube.com/watch?v=nHC_Jptv3PY
Sources : Prog. et données
Few-shot classification en NLP (spaCy / classy-classification)
2024-12-03 (Tag:799IlpTsCBs)
Catégorisation de textes à partir d’un modèle pré-entraîné peaufiné à l’aide de quelques (très peu) documents étiquetés. Utilisation du package « classy-classification » qui permet de compléter un pipeline de départ « spaCy ». Quelques éléments sur l’installation (difficile) du package, solution de repli avec Google Colab. Evaluation des performances sur la base IMDB de commentaires de films. Alternative avec le package « spacy-setfit ».
Lien vidéo: https://www.youtube.com/watch?v=799IlpTsCBs
Sources : Prog. et données
Image to text et traduction (Hugging Face / Transformers)
2024-12-03 (Tag:r9evaTAiAj0)
Combinaisons de pipelines Transformers (PyTorch, deep learning) basés sur des modèles pré-entraînés disponibles sur Hugging Face : un parseur d’image qui produit une description textuelle en anglais ; un traducteur qui traduit du texte de l’anglais vers le français. Les modèles pré-entraînés sont respectivement « ydshieh/vit-gpt2-coco-en » et « google-t5/t5-base ». Un regard rapide sur la liste des tâches couvertes par les pipelines Transformers dans les différents domaines : audio, computer vision, natural language processing (NLP), multimodal.
Lien vidéo: https://www.youtube.com/watch?v=r9evaTAiAj0
Sources : Prog. et données
Sentiment Analysis en NLP (Hugging Face / Transformers)
2024-12-02 (Tag:OLIDORb2v0U)
Analyse de sentiments en traitement des données textuelles via les modèles pré-entraînés accessibles sur Hugging Face. Utilisation du package « transformers » pour Python. Configuration de l’environnement. Utilisation de « PyTorch » comme moteur « deep learning » sous-jacent à la librairie. Quelques exemples d’usage avec parfois des résultats qui interrogent. Evaluation plus étendue sur la base IMDB (polarité des commentaires).
Lien vidéo: https://www.youtube.com/watch?v=Seqxhwv7I6U
Sources : Prog. et données
Zero-shot classification en NLP (Hugging Face / Transformers)
2024-12-02 (Tag:OLIDORb2v0U)
Principe du "Zero-Shot classification" en NLP (natural language processing, traitement statistique des données textuelles). Utilisation des modèles pré-entraînés pour le classement de documents dans un domaine spécifique. Modèle récupéré sur Hugging Face, dans notre cas "roberta-large-mnli". Installation des outils, en particulier du package "Transformers" et du moteur sous-jacent "PyTorch" (Python). Quelques exemples d'utilisation, avec la possibilité de contextualisation du classement. Evaluation du dispositif pour la catégorisation des commentaires de films (base IMDB). Réflexion sur le choix crucial du nom des classes.
Lien vidéo: https://www.youtube.com/watch?v=OLIDORb2v0U
Sources : Prog. et données
Deep Learning sous R avec le package torch
2024-11-18 (Tag:lx9mtZBdXow)
Implémentation d'un algorithme de deep learning (un perceptron multicouche) sous R à l'aide de la libraire « torch », basé sur « PyTorch ». Préparation des données, définition de la structure du réseau via une classe, paramétrage de la fonction de perte et de l'algorithme d'optimisation, entraînement du modèle, évaluation sur un échantillon test. Particularité de la vidéo : mise en parallèle sur le même problème (dataset, modèle) du code pour Python (PyTorch) avec le code pour le langage R ; les similitudes sont très fortes, sans que cela ne soit une surprise si l'on considère que « torch » est en réalité une interface pour PyTorch.
Lien vidéo: https://www.youtube.com/watch?v=lx9mtZBdXow
Sources : Prog. et données
R et Python - Performances comparées
2024-11-09 (Tag:FZqsL13wzPM)
Comparaison des performances des technologies sous-jacentes à R et Python. Le principe du JIT (just-in-time, compilation à la volée) qui génère du byte-code dans les deux cas. Mesures de performances dans l’implémentation d’un tri à bulles, où sont mis à l’épreuve principalement : l’accès aux valeurs d’un vecteur (lecture, écriture), la réalisation de boucles for imbriquées, la gestion des branchements conditionnels. Conclusion : les deux technologies se valent, pour ce qui est des versions évaluées tout du moins (R 4.4.1 vs. Python 3.12.4).
Lien vidéo: https://www.youtube.com/watch?v=FZqsL13wzPM
Sources : Prog. et données
Knime Interactive R Statistics Integration
2024-10-30 (Tag:GfFWq36GJf8)
Possibilité d’exécuter du code R au sein d’un workflow Knime à l’aide des composants R Scripting. Installation de l’extension « Interactive R Statistics » dans Knime. Configuration de l’outil avec désignation de l’interpréteur (moteur) R à utiliser. La question des packages R spécifiques que l’on souhaite intégrer dans nos workflows. La circulation des informations d’un composant à l’autre avec le mécanisme des ports en entrée et en sortie des composants (tables de données, worskpace de R). Pour illustrer le propos, mise en œuvre d’un tandem clustering enchaînant une projection des individus dans un espace factoriel et une classification (clustering) sur facteurs. Une des originalités ici est de choisir à bon escient les packages R (psych, fdm2id) permettant de traiter simplement et de manière lisible les individus supplémentaires.
Lien vidéo: https://www.youtube.com/watch?v=GfFWq36GJf8
Sources : Notebook et données
Extension Python pour Knime
2024-10-17 (Tag:5mFnx-umn_c)
Possibilité d'exécuter du code Python au sein d'un workflow Knime avec le composant Python Script. Installation du package Python pour Knime. Identification et/ou choix – à travers les environnements conda – des versions de Python et des packages de data science. Configuration par défaut du composant Python Script. Circulation des informations via le mécanisme des ports en entrée et sortie, pour les données (table) ou pour les modèles de machine learning (objets picklés). Mise en œuvre d'un schéma classique d'apprentissage/test en classification supervisée avec la régression logistique de la librairie scikit-learn. Quelques éléments de réflexion sur les sophistications possibles à travers le mécanisme des pipeline ou, plus prosaïquement, en s'appuyant sur de la programmation ad hoc en Python.
Lien vidéo: https://www.youtube.com/watch?v=5mFnx-umn_c
Sources : Notebook et données
Auto-encodeur avec PyTorch (Python)
2024-10-09 (Tag:70HFz9ooiI0)
Deep Learning - Machine learning. Définition, paramétrage, instanciation et entraînement des auto-encodeurs (autoencoders) avec PyTorch (Python). Retour rapide sur les auto-encodeurs, le principe de l'embedding, une représentation intermédiaire et une réduction de dimension qui a pour objectif de capter l'essence des informations portées par les données. Projection des individus dans l'espace intermédiaire. Reconstitution des données initiales. Fonction de coût, algorithme d'optimisation. Quelques applications : traitement des variables et des individus supplémentaires ; utilisation d'un auto-encodeur pour identifier les atypismes dans les données.
Lien vidéo: https://www.youtube.com/watch?v=70HFz9ooiI0
Sources : Notebook et données
Transfer Learning avec PyTorch (torchvision / Python)
2024-05-31 (Tag:HnKn1hi7ImyeMSxoqfU)
Deep Learning, réseaux de neurones convolutifs. Principe du transfer learning en computer vision. Comment construire un modèle hybride en appariant un modèle pré-entraîné sur des grands corpus (VGG19 sur ImageNet) avec un classifieur ad hoc pour un classement binaire (les fameux chats et chiens). Gap des performances entre un modèle ad hoc et le modèle hybride. Parallèle avec les embeddings en NLP (natural language processing).
Lien vidéo: https://www.youtube.com/watch?v=moUkAJLvte8
Sources : Notebook et données
Modèles pré-entraînés pour le classement d’images (PyTorch / Python)
2024-05-29 (Tag:MRc4lZ8qpOMLXzvfnbJ)
Mise en oeuvre de modèles de deep learning pré-entraînés sur des grands corpus étiquetés (ImageNet en l’occurrence) pour le classement d’images supplémentaires. Utilisation des librairies PyTorch / Torchvision pour Python. Etude du fonctionnement en particulier des classifieurs ResNet-50 et VGG-19. Principales étapes du processus : inspection de l’image, instanciation du modèle (avec pour la première utilisation, le chargement en ligne de ses poids synaptiques, stockés dans un dossier cache de la machine locale), la transformation de l’image pour qu’elle soit compatible avec le modèle, la prédiction avec le score d’appartenance.
Lien vidéo: https://www.youtube.com/watch?v=iMAVUMpbBqM
Sources : Notebook et données
Réseau de neurones convolutifs avec tensorflow / keras (Python)
2024-05-28 (Tag:HHqyzgcBZ4OQk5u7baq)
Définition et mise en oeuvre d’un réseau de neurones convolutifs (cnn / convnet – convolutional neural network) pour le classement d’images via le tandem de librairies de deep learning tensorflow / keras. Mise en parallèle des – exactement – mêmes traitements effectués à l’aide de PyTorch. Base exemple des figures « Pokémon ». Importation et préparation de la base étiquetée d’apprentissage. Architecture du CNN (convolutional neural network) : les couches de traitements convolutifs vs. les couches de perceptron. Choix de la fonction de perte (crossentropy) et de l’algorithme d’optimisation (adam). Organisation et exécution de l’entraînement du modèle. Application du modèle sur une base de test. Mesure des performances.
Lien vidéo: https://www.youtube.com/watch?v=lvkBPIb4p_0
Sources : Notebook et données
Réseau de neurones convolutifs avec PyTorch (torchvision / Python)
2024-05-27 (Tag:jeZ63S1USKmqwhJjZf9)
Définition et mise en oeuvre d’un réseau de neurones convolutifs (cnn / convnet – convolutional neural network) pour le classement d’images via la librairie de deep learning PyTorch. Utilisation de l’extension « torchvision ». Base exemple des figures « Pokémon ». Importation et préparation de la base étiquetée d’apprentissage avec, notamment, le typage en « tenseur » (tensor) des images. Architecture du CNN : les couches de traitements convolutifs vs. les couches de perceptron. Choix de la fonction de perte (crossentropyloss) et de l’algorithme d’optimisation (adam). Organisation et exécution de l’entraînement du modèle. Application du modèle sur une base de test. Mesure des performances.
Lien vidéo: https://www.youtube.com/watch?v=iCc_sAbuPj0
Sources : Notebook et données
Classement multiclasse avec PyTorch (Python)
2024-05-22 (Tag:baqtEtXHe2TMwUvQLUW)
Suite de la vidéo consacrée à la classification supervisée à l’aide des perceptrons simples et multicouches (réseaux de neurones), utilisation de la librairie PyTorch dédiée au machine learning / deep learning. Par rapport à classification binaire (cf. lien de la vidéo ci-dessous), plusieurs spécificités pour pouvoir traiter un problème multiclasse (variable cible catégorielle à plus [strictement] de 2 modalités) : nécessité d’encoder la variable cible catégorielle en matrice 0/1 via un codage disjonctif complet (OneHotEncoder) pour pouvoir utiliser le critère MSE ; utilisation d’une fonction de transfert adaptée (softmax) ; en prédiction, conversion de la matrice des probabilités d’affectation en vecteur de modalités. Traitement des données "iris".
Lien vidéo: https://www.youtube.com/watch?v=BV37oO-uTaU
Sources : Notebook et données
Classement binaire avec PyTorch (Python)
2024-05-22 (Tag:A5g98NGUHOydweoPOSt)
Classement ou classification supervisée binaire avec la librairie PyTorch (Python). Particularités de l’outil dans le cadre de la définition et de la mise en œuvre des perceptrons simples et multicouches (réseaux de neurones) : mettre les données sous la forme de tenseurs (tensor, des matrices et vecteurs optimisés pour les calculs de machine learning) ; définir l’architecture et le comportement du réseau sous la forme d’une classe ; écrire explicitement les différentes étapes de « fit » pour l’entraînement du modèle. PyTorch fait partie des librairies phares de deep learning à ce jour.
Lien vidéo: https://www.youtube.com/watch?v=ipzemUBDAqU
Sources : Notebook et données
Formulaire interactif dans un notebook (ipywigdets / Python)
2024-05-17 (Tag:g5rxxgstMDnZFTB9Sck)
Création de formulaire interactif dans un notebook Jupyter à l'aide du package « Ipywidgets » pour Python. Initialisation, disposition et paramétrage des objets visuels ; programmation des gestionnaires d'évènements. Plusieurs exemples de programmes très simples, mise en parallèle avec le fonctionnement d'une application console que l'on chercherait à faire exécuter au sein d'un notebook. Utilisation de VS Code.
Lien vidéo: https://www.youtube.com/watch?v=vhFReA8jPUA
Sources : Notebook et données
Clustering – Déploiement Web App (streamlit / Python)
2024-03-31 (Tag:98DO0qpqE9Q2yik17lY)
Déploiement d'un modèle de clustering (classification automatique, non-supervisée) sous la forme d'une Web App développée à l'aide de la technologie « streamlit » pour Python. Le « modèle » correspond en réalité à un processus encapsulé dans une structure Pipeline de « scikit-learn ». Il comprend un mécanisme d'imputation des données manquantes (SimpleImputer), la standardisation des données (StandardScaler) et la méthode K-Means (KMeans). Il est utilisable en déploiement c.-à-d. il peut s'appliquer en généralisation sur des individus supplémentaires sans qu'il soit nécessaire d'avoir accès aux données d'entraînement. Elaboration enfin d'une application streamlit permettant de saisir les caractéristiques d'un individu, d'obtenir son groupe d'affectation, la distance aux barycentres des groupes, de disposer d'indications sur le mécanisme d'affectation à travers les valeurs prises par les variables.
Lien vidéo: https://www.youtube.com/watch?v=wYW47OnxdWA
Sources : Notebook et données
Pipeline – FunctionTransformer (scikit-learn / Python)
2024-03-31 (Tag:CjjKEbDRNnV8AKgk9sF)
Utilisation de l'outil FunctionTransformer dans une phase de préparation de données, incorporée dans un Pipeline scikit-learn. La fonction de transformation peut être définie à la volée (fonction lambda) ou implémentée à part. Le plus important est d'être en cohérence avec le format des variables passées en paramètres. Sérialisation du workflow complet (préparation des données + modèle de machine learning [régression logistique ici]) à l'aide du package "dill" (le package "pickle" ne sait pas manipuler les fonctions lambda).
Lien vidéo: https://www.youtube.com/watch?v=buIQuxM_uro
Sources : Notebook et données
Pipeline – Paramétrage (scikit-learn / Python)
2024-03-29 (Tag:NSwdHhRFRrtsL8kK8NJ)
Pipeline sous Python dans le cadre de l'analyse conjointe (tandem clustering) mixant analyse factorielle et classification automatique (clustering). Accès aux étapes intermédiaires du pipeline avec une double finalité : (1) lecture des résultats ; (2) manipulation des paramètres des algorithmes pour pouvoir relancer les calculs sans avoir à réinstancier à chaque fois le pipeline dans sa globalité. Exemple avec une ACP (analyse en composantes principales) associée à un K-Means où l'objectif est de déterminer le nombre de facteurs à retenir pour une solution efficace. Nous nous plaçons dans un cadre particulier où les vraies classes d'appartenance sont connues, une mesure externe d'évaluation des partitions est utilisée (v-measure).
Lien vidéo: https://www.youtube.com/watch?v=bUMky9EFVLM
Sources : Notebook et données
Microsoft COPILOT... est mon ami
2024-03-29 (Tag:5BMprVboQr4)
Quelques expériences amusantes (?) avec Microsoft Copilot. Inspection des résultats et surtout des sources utilisées lors de requêtes relatives au machine learning (analyse discriminante prédictive, catégorisation de documents [NLP], identification de communautés dans les réseaux sociaux, clustering mixte). Avec, en filigrane, des questions (ou des remises en question) sur nos pratiques pédagogiques et l'intégration de ces outils d'IA générative dans nos dispositifs d'enseignement.
Lien vidéo: https://www.youtube.com/watch?v=5BMprVboQr4
Pipeline avec ColumnTransformer (scikit-learn / Python)
2024-03-27 (Tag:XyIUp1qLjRKMig8bXLE)
Implémentation de l'AFDM (analyse factorielle des données mixtes) à l'aide d'un "Pipeline" scikit-learn. Utilisation de l'outil "ColumnTransformer" pour effectuer les transformations de variables conditionnellement à leurs types (quantitatives [StandardScaler] et qualitatives [OneHotEncoder, Réduction par la racine de la fréquence]), les données étant ensuite présentées à un algorithme d'ACP (analyse en composantes principales). Elaboration d'une classe héritière de StandardScaler pour implémenter la réduction des indicatrices par la racine de la fréquence. Sauvegarde du "modèle" dans un fichier binaire à l'aide du package "dill". Chargement et application du modèle sur un individu supplémentaire. Comparaison de nos résultats avec ceux du package "scientisttools" qui fait référence en analyse de données sous Python.
Lien vidéo: https://www.youtube.com/watch?v=qy5qn_06UZA
Sources : Notebook et données
LibreOffice Calc - Filtres et Tableaux croisés dynamiques
2024-01-26 (Tag:RyPUZzMDu9c)
Manipulation des données sous le tableur LibreOffice Calc : AutoFiltre (filtre automatique), filtre standard, filtre spécial (filtres avancés, avec les zones de données, de critères et d'extraction), tableaux croisés dynamiques (TCD, champs de filtres et champs calculés).
Lien vidéo: https://www.youtube.com/watch?v=RyPUZzMDu9c
Sources : Données
Macros Python pour LibreOffice Calc (2) - Sélections simples et multiples
2023-12-29 (Tag:gl6Ygm9ksUQ)
Programmation de macros Python pour LibreOffice Calc, le tableur de la suite bureautique LibreOffice. Traitement des plages de cellules sélectionnées par l'utilisateur. Identification du type de sélection : une seule plage de cellules ou plusieurs plages non-contigües. Parcours des zones, parcours des cellules à l'intérieur d'une zone. Lecture, écriture et mise en forme des cellules.
Lien vidéo: https://www.youtube.com/watch?v=gl6Ygm9ksUQ
Sources : Prog. et Données
Fonctions personnalisées Python pour LibreOffice Calc
2023-12-28 (Tag:k2e2ADQBOiU)
Implémentation de fonctions dans des modules Python que l'on peut exploiter sous la forme de fonctions personnalisées dans une feuille de calcul du tableur Calc de la suite bureautique LibreOffice. Création et localisation du module Python dans le dossier "user". Elaboration d'une unité d'import Basic dans un classeur. Programmation en Basic de la fonction d'appel des fonctions Python.
Lien vidéo: https://www.youtube.com/watch?v=k2e2ADQBOiU
Sources : Prog. et Données
Macros Python pour LibreOffice Calc
2023-12-28 (Tag:d5Mga1TibJc)
Programmation de macros Python pour LibreOffice Calc via la librairie ScriptForge. Installations préalables, configuration de la machine pour que l’interpréteur Python soit visible de la suite bureautique, emplacement spécifique de nos modules Python pour LibreOffice. Ensuite, programmation des macros avec l’accès aux services via ScriptForge, notamment instanciation du service tableur et l’accès en lecture et écriture aux éléments de la feuille de calcul. Quelques exemples de macros, dont une – recueil des résultats de simulations répétées de lancer de pièces de monnaie – s’appuyant sur les capacités de calcul du tableur.
Lien vidéo: https://www.youtube.com/watch?v=d5Mga1TibJc
Sources : Prog. et Données
Requêtes SQL sur DataFrame Pandas (pandasql / Python)
2023-12-24 (Tag:5wpXzrG0KNA)
Utilisation de requêtes SQL pour accéder aux informations d'une base de données sous la forme de tables « DataFrame – Pandas » chargées en mémoire. Utilisation du package « pandasql ». Requêtes simples, requêtes avec jointures. Parallèle avec les fonctions natives du package « Pandas ». Quelques éléments de réflexion quant à l'opportunité de cette solution pour la manipulation des bases de données (volumétrie, performances).
Lien vidéo: https://www.youtube.com/watch?v=5wpXzrG0KNA
Sources : Prog. et Données
Dockerisation (Base de données [SQLite] + Web App Python [gradio])
2023-12-23 (Tag:-GgG1Wb2F64)
Création d'une image docker contenant une base de données (multi-tables) et une web app Python (basée sur « gradio » pour cette dernière, mais ça aurait pu être Streamlit, Shiny, Dash, Bokeh, etc.). L'enjeu du choix technologique pour la base de données. La contrainte d'installation et de configuration si utilisation d'un serveur de SGBD traditionnel (ex. MySQL, PostgreSQL, etc.). L'intérêt de s'appuyer sur SQLite qui intègre dans un simple fichier l'ensemble des tables. L'accès à la base sous Python passe par l'installation d'un package (pysqlite3 dans cette vidéo). La manipulation de données se fait via des requêtes SQL. La simplicité du dispositif permet de créer très facilement une image docker encapsulant l'ensemble des éléments du programme.
Lien vidéo: https://www.youtube.com/watch?v=-GgG1Wb2F64
Sources : Prog. et Données
NLP - Catégorisation de documents avec "fasttext" (Python)
2023-12-21 (Tag:Vcmhjea8Hss)
NLP – Natural langage processing, Machine learning. Classification supervisée de documents textuels à l'aide du package "fasttext" pour Python, avec un étiquetage multi-classes non mutuellement exclusives c.-à-d. un document peut appartenir à 1 (au moins) ou plusieurs classes. Paramétrage de l'algorithme "fasttext" basé sur un réseau de neurones supervisé. Inspection des prédictions, avec possibilité de prédire une ou plusieurs classes d'appartenance. Adaptation des mesures de performances (précision et rappel) à la problématique traitée. D'autres particularités de "fasttext" sont explorées : la possibilité de combiner des termes (bigrams) ; ou encore l'exploitation des modèles pré-entraînés sur des grands corpus, étude notamment du comportement d'un modèle basé sur un corpus de polarités de commentaires sur Amazon.
Lien vidéo: https://www.youtube.com/watch?v=Vcmhjea8Hss
Sources : Prog. et Données
NLP - Reconnaissance automatique de la langue avec "fasttext" (Python)
2023-12-20 (Tag:jN-3oWEkGnQ)
NLP, Natural Language Processing, TAL, Traitement automatique des langues. Présentation des fonctionnalités de reconnaissance automatique de la langue de la librairie "fasttext" pour Python. Retour rapide sur le mécanisme interne basé sur un dispositif de machine learning supervisé, étude en particulier du corpus étiqueté utilisé pour élaborer le modèle prédictif. Chargement et exploitation du modèle binaire pré-entraîné, accessible sur le web, en prédiction. Reconnaissance de la langue pour des documents en français, en anglais et en malgache. Limites de l'outil.
Lien vidéo: https://www.youtube.com/watch?v=jN-3oWEkGnQ
Sources : Prog. et Données
Déploiement des classifieurs avec R Shiny + Docker
2023-12-11 (Tag:n7ztNyx68Lk)
Machine learning. Déploiement d'un modèle prédictif (analyse discriminante linéaire) développé sous R à l'aide d'une application web R Shiny. Création et organisation de l'interface. Intégration du modèle dans le gestionnaire d'évènements. Test de fonctionnement, calcul de la prédiction pour un individu supplémentaire décrit par les saisies de l'utilisateur. Encapsulation de l'application et de ses dépendances dans une image Docker. Lancement du conteneur docker.
Lien vidéo: https://www.youtube.com/watch?v=n7ztNyx68Lk
Sources : Prog. et Données
Suivi des expérimentations avec MLFLOW TRACKING (PyCaret / Python)
2023-12-04 (Tag:kUKLzRtfJco)
Utilisation de MLFLOW dans la gestion des cycles de vie des projets de machine learning. Focus sur l’outil de "tracking" qui permet de recenser les expérimentations et de suivre les performances associées lors de la recherche des algorithmes les plus efficaces sur un jeu de données. Utilisation à cet effet des fonctionnalités du package PyCaret pour Python. Mise en place des expérimentations : comparaison des algorithmes de machine learning (régression logistique, arbre de décision, naive bayes, analyse discriminante, svm linéaire), détermination des meilleurs paramètres pour une des techniques. Lancement du serveur web, consultation des résultats organisées en sessions d’expérimentation, lecture détaillée des informations relatives aux modèles testés (code de déploiement, fichier pickle, fichiers de configuration de l’environnement). Enfin, mise à jour des résultats lorsque les expérimentations sont relancées, sur une nouvelle version du jeu de données par exemple.
Lien vidéo: https://www.youtube.com/watch?v=kUKLzRtfJco
Sources : Prog. et Données
Déploiement facile via GRADIO (PyCaret / Python)
2023-11-27 (Tag:OQ8_U28HB94)
Déploiement d'un pipeline (préparation des données + modèle prédictif de machine learning) sous la forme d'une application GRADIO, une librairie Python permettant de monter très simplement et très efficacement une application web de machine learning (à l'instar de STREAMLIT). Modélisation, création, et sauvegarde du pipeline avec PyCaret. Création de l'application de déploiement Python basé sur gradio, elle permet à l'utilisateur de saisir la description d'un individu supplémentaire, de lui appliquer le modèle (le pipeline) prédictif, d'afficher alors la classe prédite et le score d'affectation.
Lien vidéo: https://www.youtube.com/watch?v=OQ8_U28HB94
Sources : Prog. et Données
Déploiement facile via STREAMLIT + DOCKER (Pycaret / PYTHON)
2023-11-26 (Tag:qCixiQgxSkI)
Déploiement d'un pipeline (préparation des données + modèle prédictif de machine learning) sous la forme d'une application STREAMLIT, qui est par la suite encapsulée dans une image DOCKER. Utilisation des fonctionnalités de déploiement de la librairie Pycaret pour Python. Test de l'application streamlit dans l'environnement de développement. La question essentielle des versions de Python et des packages dans la construction de l'image. Lancement du conteneur docker avec Docker Desktop. Test de l'application : saisie des valeurs des descripteurs pour un individu à classer, prédiction de la classe d'appartenance avec le score d'affectation. Approche pour la gestion des valeurs manquantes.
Lien vidéo: https://www.youtube.com/watch?v=qCixiQgxSkI
Sources : Prog. et Données
Déploiement facile via une API REST avec PyCaret / PYTHON
2023-11-23 (Tag:0HaRdXCsOH4)
Déploiement d'un pipeline (préparation de données + modèle de machine learning) sous la forme d'une API REST avec le package PyCaret pour Python. Processus de modélisation en classification supervisée dans le cadre de PyCaret : entraînement et évaluation des algorithmes (régression logistique pour nous), détermination des bonnes valeurs des hyperparamètres en validation croisée, construction du classifieur définitif. Déploiement ensuite avec l'exportation du pipeline incluant le preprocessing et le modèle dans un fichier pickle (.pkl), puis création automatique d'un programme Python (.py) qui permet de générer le service web. Utilisation du service web : saisie des valeurs des variables prédictives, obtention de la classe prédite, mode gestion des valeurs manquantes par le dispositif.
Lien vidéo: https://www.youtube.com/watch?v=0HaRdXCsOH4
Sources : Prog. et Données
Machine learning avec tidymodels pour R
2023-11-20 (Tag:YvA0LTCUIqk)
Présentation des fonctionnalités du package "tidymodels" pour R dans le cadre de la classification supervisée. Le principe des meta-packages, la normalisation des étapes d'analyse et d'appel des fonctions de préparation, de modélisation et d'évaluation ; le mécanisme des workflow pour empiler des opérations de préparation de données et création de modèles ; la galaxie tidymodels et les packages associés ; la possibilité d'exploiter différents moteurs de calcul fournis dans différents framework et librairies. Dans notre exemple précisément, utilisation du package "brulee" qui instancie des algorithmes de la fameuse librairie de deep learning "torch". Mesure des performances prédictives (accuracy, rappel, précision, f-measure) dans des schémas holdout et en validation croisée. Focus sur la synthèse des résultats en validation croisée.
Lien vidéo: https://www.youtube.com/watch?v=YvA0LTCUIqk
Sources : Prog. et Données
Text Mining (NLP) - Le package spaCy pour Python
2023-11-13 (Tag:WSLG4MfOhPo)
NLP - Natural Language Processing (traitement du langage naturel). Exploration de quelques fonctionnalités de la librairie spaCy pour Python, elles contribuent à l'analyse fine des documents textuels : part-of-speech tagging (étiquetage morpho-syntaxique), lemmatisation, mise en évidence des schémas de dépendance entre les termes (token), identification des entités nommées, représentation vectorielle des termes et des documents. Le package peut s'appuyer sur des versions plus ou moins élaborées de modèles (pipeline) pré-entraînés sur des corpus dans différentes langues. Traitement du premier paragraphe de la chanson "Vesoul" de Jacques Brel.
Lien vidéo: https://www.youtube.com/watch?v=WSLG4MfOhPo
Sources : Prog. et Données
La méthode DISMIX (Python / scientisttools)
2023-07-12 (Tag:S6wTBImDN7Q)
Présentation de la méthode DISMIX de la librairie "scientisttools" pour Python, une généralisation de DISQUAL aux descripteurs mixtes (mix de variables explicatives quantitatives et qualitatives). Elle combine l'AFDM (analyse factorielle des données mixtes, généralisation de l'ACP normée et de l'ACM) et l'analyse discriminante linéaire (ADL) prédictive. Lecture des coefficients des fonctions discriminantes linéaires exprimées sur les variables originelles. Estimation de la probabilité de bien classer en validation croisée. Décryptage de la méthode via l'accès aux champs internes (AFDM et ADL) de l'objet de calcul.
Lien vidéo: https://www.youtube.com/watch?v=S6wTBImDN7Q
Sources : Prog. et Données
La méthode DISQUAL (Python / scientisttools)
2023-07-04 (Tag:sAcXjeknHNE)
Présentation de la méthode DISQUAL (discrimination sur variables qualitatives ; Saporta, 1975) qui combine l'analyse des correspondances multiples (ACM) et l'analyse discriminante linéaire (ADL) pour réaliser une classification supervisée (un classement) à partir de descripteurs tous qualitatifs. L'intérêt est de disposer en définitive un modèle s'exprimant sous la forme d'une combinaison linéaire des indicatrices (des modalités des variables), qui se prête facilement aux interprétations, notamment en scoring. Le nombre de facteurs de l'ACM à présenter à l'analyse discriminante constitue un paramètre de régularisation. Traitements sous Python avec la librairie "scientisttools" qui implémente nativement l'approche et présente directement les coefficients des modèles sous leur forme interprétable.
Lien vidéo: https://www.youtube.com/watch?v=sAcXjeknHNE
Sources : Prog. et Données
Analyse factorielle discriminante (CANDISC) avec "scientisttools" (Python)
2023-06-26 (Tag:BTx4HrwLGWM)
Présentation de l'analyse discriminante descriptive (analyse factorielle discriminante, l'équivalent de la PROC CANDISC de SAS) de la librairie "scientisttools" pour Python. Le type de données traité, les différences et les accointances avec la classification supervisée (prédiction). La nature de l'espace factoriel généré. L'interprétation des facteurs, et dans le même temps la caractérisation des groupes, via les corrélations avec les variables descriptives. Le traitement des individus supplémentaires : projection dans l'espace factoriel et rattachement aux groupes.
Lien vidéo: https://www.youtube.com/watch?v=BTx4HrwLGWM
Sources : Prog. et Données
Analyse discriminante linéaire - Projet Etudiant Python
2023-06-24 (Tag:e5NYJYDA6-4)
Présentation d'une librairie Python d'analyse discriminante linéaire prédictive (proc discrim), incluant la sélection de variables pas-à-pas (forward, backward ; proc stepdisc), réalisée par trois étudiants de la L3 IDS (informatique décisionnelle et statistique) de l'Université Lyon 2, promotion 2021 : Aleksandra Kruchinina, Aymeric Delefosse, Mamadou Diallo. Référence de la page GitHub, accès au code source, importation et mise en œuvre des algorithmes dans les notebooks Python. Possibilité de produire des rapports HTML ou PDF à partir des résultats des calculs.
Lien vidéo: https://www.youtube.com/watch?v=e5NYJYDA6-4
Sources : Prog. et Données
Analyse discriminante linéaire avec "scientisttools" (Python)
2023-06-22 (Tag:220nYnr0gMs)
Présentation des fonctionnalités des méthodes LDA (analyse discriminante linéaire prédictive) et STEPDISC (stepwise discriminant analysis - sélection de variables) de la librairie "scientisttools" (version 0.0.6) pour Python. Parallèle avec les procédures de référence "proc discrim" et "proc stepwise" du logiciel SAS, comparaison également avec les outils proposés par la librairie "discriminR" pour R. La démo s'appuie sur le schéma usuel de la classification supervisée : modélisation sur un échantillon d'apprentissage, prédiction et évaluation sur un échantillon test. Les données ont été préparées de manière à ce qu'il soit possible de réitérer à l'identique l'expérimentation sur d'autres outils/librairies.
Lien vidéo: https://www.youtube.com/watch?v=220nYnr0gMs
Sources : Prog. et Données
Analyse discriminante PLS (Python / scikit-learn)
2023-06-19 (Tag:7Qj-Ork0Z6A)
Utilisation de la régression PLS (partial least squares regression - régression des moindres carrés partiels) pour le classement (classification supervisée) évaluée sous l'angle de l'AUC (aire sous la courbe) de la courbe ROC. La combinaison d'une analyse discriminante linéaire et la régression PLS. Les propriétés de régularisation (résistance à la sur-dimensionnalité) de cette dernière via le nombre de composantes à retenir, facile à identifier et à manipuler. Projection des individus dans l'espace factoriel déduit des descripteurs (réduction de dimension), au sein duquel il est possible d'appliquer un algorithme supervisé pour discriminer les classes (classifieur linéaire avec une analyse discriminante ici, mais d'autres algorithmes auraient été possibles). Non traité dans la vidéo mais intéressant à explorer, passer par un pipeline pour enchaîner les opérations et disposer d'un modèle composite prêt à déployer. Traitements sous Python avec la librairie "scikit-learn".
Lien vidéo: https://www.youtube.com/watch?v=7Qj-Ork0Z6A
Sources : Prog. et Données
Régression et classement - Equivalences (Python / scikit-learn)
2023-06-15 (Tag:bCxIxMxvSlU)
Utilisation de la régression linéaire multiple dans un problème de classification supervisée binaire. Equivalences avec les classifieurs linéaires, en particulier avec l'analyse discriminante linéaire, au regard des frontières induites dans l'espace de représentation (hyperplan séparateur). Performances en prédiction. Illustration sur les données "Breast Cancer Wisconsin", bien connues en machine learning. Traitements sous Python avec la librairie "scikit-learn".
Lien vidéo: https://www.youtube.com/watch?v=bCxIxMxvSlU
Sources : Prog. et Données
Clustering - Gap statistic - Détermination du nombre de groupes
2023-06-15 (Tag:9UX_olmhhJg)
Présentation et calcul de la statistique "gap" (gap-statistic) basée sur une méthode de Monte-Carlo. Son utilisation dans une stratégie d'identification du "bon" nombre de groupes dans une démarche de clustering (classification automatique). Définition des données de référence sous H0 où les relations entre les individus et les variables sont perturbées aléatoirement. Comparaison des critères de qualité de partitionnement (inertie intra-classe dans le cas des K-Means) entre les données observées et la situation de référence. Règle(s) de détermination de la meilleure solution à partir de la courbe des "gap statistic". Traitements sont Python avec la librairie "scikit-learn".
Lien vidéo: https://www.youtube.com/watch?v=9UX_olmhhJg
Sources : Prog. et Données
ACP avec scientisttools - Choix du nombre de composantes
2023-06-08 (Tag:NEOWHKsZQqc)
Techniques pour le choix du nombre de composantes en ACP (analyse en composantes principales). (1) Les seuils directement calculés : règle du coude, règle de Kaiser-Gutman, règle de Karlis-Saporta-Spinaki, test des bâtons brisés (Legendre). (2) Les procédures basées sur des méthodes de Monte-Carlo (simulation). Deux axes : analyse parallèle où l'on définit des données H0 par randomisation (les relations entre les individus et les variables sont perturbées aléatoirement), on en déduit des valeurs seuils à comparer avec les valeurs propres observées ; l'analyse bootstrap où, cette fois-ci, toujours par simulation, on cherche à obtenir les distributions des valeurs propres pour pouvoir en déduire leurs intervalles de confiance. Traitements sous Python avec la librairie "scientisttools".
Lien vidéo: https://www.youtube.com/watch?v=NEOWHKsZQqc
Sources : Prog. et Données
Arbres - Post-élagage avec R / rpart - Validation croisée, règle de l'écart-type
2023-05-30 (Tag:hz2szjYGcRg)
Mise en oeuvre du post-élagage de l'algorithme CART (Breiman et al., 1984) avec la librairie "rpart" pour le logiciel R (fonctionnant sous RStudio). Le dispositif s'appuie sur la validation croisée pour mesurer de manière plus précise les performances des scénarios d'arbre emboîtés. Le paramètre "cp" (complexity parameter) permet de choisir le meilleur arbre, lequel peut correspondre à la solution "optimale" (dixit la courbe en validation croisée), ou encore celui correspondant à la règle de l'écart-type (1-SE rule) (en vertu de la préférence à la simplicité). Solution moins usitée (sous rpart), il est également possible - moyennant un peu de programmation - d'utiliser spécifiquement un échantillon d'élagage avec rpart.
Lien vidéo: https://www.youtube.com/watch?v=hz2szjYGcRg
Sources : Prog. et Données
Post-élagage des arbres de décision - Python / Scikit-learn
2023-05-23 (Tag:if6QEtJP77E)
Mise en oeuvre du mécanisme de post-élagage (post-pruning) de l'algorithme CART (Breiman et al., 1984) avec la classe de calcul DecisionTreeClassifier de Scikit-learn pour Python. Utilisation d'un échantillon dédié (pruning set, également connu sous l'appellation validation set dans d'autres logiciels ; des références qui s'appuient sur la validation croisée sont indiquées). Obtention des valeurs de l'hyperparamètre 'ccp_alpha' à utiliser via le "chemin de coût complexité". Courbes d'évolution de l'erreur en fonction du nombre de feuilles des arbres. Identification de l'arbre optimal. Conséquences sur l'erreur en généralisation mesuré sur un échantillon test à part. Quelques commentaires sur la procédure analogue proposée par la librairie "rpart" de R.
Lien vidéo: https://www.youtube.com/watch?v=if6QEtJP77E
Sources : Prog. et Données
Clustering tree avec Python / Scikit-Learn
2023-05-22 (Tag:e99mO3LJz0w)
Présentation d'une méthode de classification automatique (clustering, apprentissage non-supervisé) basé sur un algorithme de construction d'un arbre de régression multi-cible (multi-output) de la librairie Scikit-Learn pour Python. Combinaison de la segmentation monothétique (segmentation pas-à-pas fondée sur une variable à chaque étape, choisie parmi les X), avec une qualité de partition mesurée sur l'ensemble des variables de Y. L'astuce repose sur la caractéristique Y = X (ou bien, si on souhaite sophistiquer l'approche, Y est une émanation de X). Représentation des frontières induites par l'arbre dans l'espace de représentation. Exploitation des règles d'affectation pour le traitement des individus supplémentaires.
Lien vidéo: https://www.youtube.com/watch?v=e99mO3LJz0w
Sources : Prog. et Données
Multidimensional Scaling (MDS) sous Python avec Scientisttools
2023-05-15 (Tag:VjVr0-dCJlA)
Utilisation de la librairie "scientisttools" sous Python pour la mise en oeuvre du positionnement multidimensionnel classique (classical multidimensional scaling) dans un problème de recherche des communautés dans un réseau d'amitiés (matrice d'adjacence). Application d'un algorithme de clustering (K-Means) à partir des coordonnées "factorielles" des individus pour la délimitation des groupes. Traitement d'un individu supplémentaire via une double approche : identification de ses connexions au sein des communautés ; projection de l'individu supplémentaire dans l'espace "factoriel" MDS. Cette dernière fonctionnalité est très rare dans les librairies de machine learning.
Lien vidéo: https://www.youtube.com/watch?v=VjVr0-dCJlA
Sources : Prog. et Données
Analyses factorielles avec "scientisttools" sous Python
2023-05-09 (Tag:EMkpDxerxsE)
Présentation de la librairie d'analyse des données "scientisttools" pour Python. Elle intègre les techniques basiques (ACP, AFC, ACM), mais aussi celles plus sophistiquées (AFDM, ACP sur corrélations partielles, MDS, etc.). Elle propose deux modes de fonctionnement, une première classique sous Python comme une étape de réduction de dimension ; une seconde, plus originale, où elle émule les fonctionnalités et le fonctionnement des packages telles que FactoMineR, bien connue des data scientists, qui fait référence sous R. Dans cette vidéo, je montre l'utilisation de l'outil dans le cadre d'une analyse factorielle des données mixtes (FADM). Je mets en parallèle les résultats avec ceux de FactoMineR.
Lien vidéo: https://www.youtube.com/watch?v=EMkpDxerxsE
Sources : Prog. et Données
Clustering de graphes - Détection des communautés (Python / igraph)
2023-04-26 (Tag:Vp5-d-lk9jA)
Recherche des communautés dans un graphe représentant un réseau social via les techniques de clustering. Matrice d'adjacence. Transformation en matrice de distances cosinus. Application de la CAH (classification ascendante hiérarchique). Identification des individus caractéristiques des clusters avec la notion de médoïde. Traitements sous Python avec les packages igraph, scipy, scikit-learn.
Lien vidéo: https://www.youtube.com/watch?v=Vp5-d-lk9jA
Sources : Prog. et Données
Segmentation d'image avec les K-Means (Python / OpenCV vs. Scipy)
2023-04-22 (Tag:y2tSO7OSxH0)
Application d'une méthode de clustering pour la segmentation d'image. Conversion d'une image (en tableau de pixels) en une matrice 2D individus (pixels) x variables (3 couleurs RGB). Mise en oeuvre de la méthode des K-Means. Labélisation des pixels à l'aide des groupes d'appartenance. Reconstitution de l'image avec les "codebooks" (vecteur des moyennes conditionnelles représentant chaque groupe) pour obtenir une représentation en bichromie, quadrichromie, ... , K-chromie. Traitements sous Python avec les librairies PIL, matplotlib et Scipy. Il n'a pas été nécessaire d'utiliser OpenCV.
Lien vidéo: https://www.youtube.com/watch?v=y2tSO7OSxH0
Sources : Prog. et Données
Clustering / KMeans - Accélérer les traitements sous Scikit-learn / Python
2023-04-21 (Tag:z8kFPF1H46s)
Comment réduire les temps de traitements d'un projet de machine learning / clustering développé avec Scikit-Learn sous Python avec une modification très mineure de votre code, via l'utilisation du package "Intel Extension for Scikit-learn". Le système des patches avec la substitution des classes de calcul optimisées d'Intel à celles de Scikit-learn. Gains en temps de traitements pour les K-Means en entraînement et en inférence sur une base de 500.000 observations et 21 variables. Outils : Python ; packages Scikit-learn, Scikit-learn-intelex.
Lien vidéo: https://www.youtube.com/watch?v=z8kFPF1H46s
Sources : Prog. et Données
Clustering de documents textuels (NLP) avec PyCaret (Python)
2023-04-17 (Tag:DanM3sJqkYo)
NLP (Natural Language Processing) / Text Mining. Création automatique et simplifiée d'un pipeline de clustering de documents textuels sous Python à l'aide du package 'PyCaret'. Traitements et résultats dans une première approche. Puis, dans un deuxième temps, analyse approfondie des étapes de calculs mis en place par PyCaret, qui utilise en interne la classe de calcul TfidfVectorizer du package 'scikit-learn' pour créer la matrice documents-termes présentée à la méthode des K-Means. Possibilité de combiner les traitements avec une réduction de dimension (ACP - analyse des correspondances multiples), soit dans une phase illustrative (pour simplement représenter les groupes), soit dans une phase active (ce sont les composantes de l'ACP qui sont présentées à l'algorithme des K-Means).
Lien vidéo: https://www.youtube.com/watch?v=DanM3sJqkYo
Sources : Prog. et Données
Clustering des modalités de variables qualitatives via leur représentation factorielle (Python)
2023-04-15 (Tag:m2_UJXQhhzE)
Structuration de l'information à l'aide du clustering de modalités, lorsque les observations sont décrites par exclusivement des variables qualitatives. Exploitation de la représentation factorielle des points-modalités issue d'une ACM (analyse des correspondances multiples). K-Means des points-modalités dans l'espace factoriel en tenant compte de leur pondération (une modalité correspond à un ensemble d'individus). Traitements sous Python avec les packages 'fanalysis' et 'scikit-learn'.
Lien vidéo: https://www.youtube.com/watch?v=m2_UJXQhhzE
Sources : Prog. et Données
Clustering des modalités de variables qualitatives via leur représentation factorielle (Python)
2023-04-02 (Tag:tUi8eJZtl4w)
ACP (analyse en composantes principales) sous PYTHON. Le problème de l'effet taille en ACP. La mesure du degré de redondance des variables, de la liaison des variables aux autres (critère KMO : Kaiser-Meyer-Olkin ; présenté aussi sous le nom MSA : measure of sampling adequacy). Le travail sur les corrélations partielles pour explorer différemment les patterns véhiculés par les données. L'adaptation de la lecture des résultats qui en découle. Rotation "varimax" pour améliorer la lisibilité des composantes. Enfin, la transposition du travail sur les matrices des corrélations brutes et partielles au calcul des coordonnées factorielles des individus. Traitements sous Python avec les packages fanalysis, statsmodels et pingouin.
Lien vidéo: https://www.youtube.com/watch?v=tUi8eJZtl4w
Sources : Prog. et Données
ACP + Rotation Quartimax et Clustering de variables (Python)
2023-03-26 (Tag:HEBd3FCqQfk)
ACP (analyse en composantes principales) avec la rotation de facteurs "quartimax" (rotation orthogonale). Son utilisation dans le cadre d'un regroupement des variables (clustering de variables) pour comprendre les structures sous-jacentes aux données. Présentation des résultats sous la forme d'un graphique "heatmap", permettant de disposer d'une lecture plus limpide à la fois des appartenances aux groupes, mais aussi des relations entre les variables à l'intérieur des groupes. Les résultats sont mis en relation avec ceux obtenus à l'aide d'une approche plus classique fondée sur une CAH (classification ascendante hiérarchique) et une distance déduite des carrés des corrélations entre les variables. Traitements sous Python avec les packages statsmodels et seaborn.
Lien vidéo: https://www.youtube.com/watch?v=HEBd3FCqQfk
Sources : Prog. et Données
ACP sous Python avec statsmodels - Rotation Varimax
2023-03-23 (Tag:WyZbW34UJN8)
Pratique de l'ACP - analyse en composantes principales - sous Python avec le package "statsmodels". Exploration des fonctionnalités basiques, mais surtout focus sur la rotation orthogonale des facteurs (varimax, quartimax). Elle améliore l'interprétation en rendant plus tranchées (contributions, cosinus carré) les associations entre les variables et les composantes. Lecture des résultats, représentations graphiques avec des heatmap plutôt que des cercles des corrélations. Remarque sur la matrice de transition qui permet de positionner les variables "et" les individus dans le nouveau repère factoriel. Traitements sous Python avec le package "statsmodels".
Lien vidéo: https://www.youtube.com/watch?v=WyZbW34UJN8
Sources : Prog. et Données
ACM - Analyse des correspondances multiples sous Python avec fanalysis
2023-03-22 (Tag:oY0mtzcvRYk)
Présentation des fonctionnalités du package "fanalysis" pour la réalisation d'une analyse (factorielle) des correspondances multiples (ACM) sous Python. Focus sur la mauvaise perception de l'information restituée par les premiers facteurs : introduction de la correction de Benzécri pour les valeurs propres, de Greenacre pour les parts de variance restituées. Calcul des coordonnées factorielles des points individus et modalités, des contributions, des cosinus carrés. Quelques éléments sur les représentations graphiques. Traitements sous Python avec le package fanalysis. Un petit commentaire enfin sur le package "ca" pour R, particulièrement intéressant pour les analyses des correspondances.
Lien vidéo: https://www.youtube.com/watch?v=oY0mtzcvRYk
Sources : Prog. et Données
AFC - Analyse factorielle des correspondances sous Python avec fanalysis
2023-03-19 (Tag:1vlGxiXNCRA)
Présentation des fonctionnalités du package "fanalysis" pour la réalisation d'une analyse factorielle des correspondances sous Python. Traitement d'un tableau croisés de valeurs positive (souvent tableau de contingence). Coordonnées factorielles des modalités lignes et colonnes, aides à l'interprétation (cosinus carrés, contributions). Représentation simultanée des points lignes et colonnes, analyse des attractions et répulsions, utilisation d'un graphique heatmap pour approfondir les voisinages dans le repère factoriel. Traitements sous Python avec le package fanalysis.
Lien vidéo: https://www.youtube.com/watch?v=1vlGxiXNCRA
Sources : Prog. et Données
ACP - Analyse en composantes principales sous Python avec fanalysis
2023-03-18 (Tag:LeAq3iS-bpY)
Présentation des fonctionnalités du package fanalysis pour la réalisation d'une ACP (analyse en composantes principales) sous Python. Traitement des individus et variables actives, coordonnées factorielles, obtention des aides à l'interprétation sans calculs additionnels (contributions et cosinus carrés), outils graphiques directement accessibles (cercle des corrélations, carte des individus). Traitement des variables illustratives quantitatives et qualitatives. Projection simplifiée (une seule instruction) des individus supplémentaires (Python, package fanalysis).
Lien vidéo: https://www.youtube.com/watch?v=LeAq3iS-bpY
Sources : Prog. et Données
Clustering flou - La méthode Fuzzy C-Means (Python)
2023-03-16 (Tag:Bk_8PzhJPy4)
Principe et intérêt de la partition floue dans une démarche de classification automatique. Différences par rapport au K-Means usuel. La notion de degré d'appartenance aux classes. Rôle du paramètre "fuzzifier" dans l'algorithme de la méthode de machine learning. Illustration de la plan. Relativiser l'affectation à un cluster pour les observations situées à la limite de différents clusters. Lecture des résultats dans un jeu de données plus réaliste. Notebook sous Python avec les packages scikit-learn et scikit-fda.
Lien vidéo: https://www.youtube.com/watch?v=Bk_8PzhJPy4
Sources : Prog. et Données
Clustering - Pipeline Python et Déploiement (scikit-learn + fanalysis)
2023-03-13 (Tag:H_A8-Dr8bIw)
Clustering (k-means) sur données décrites par des variables catégorielles. Tandem clustering : projection des individus dans un espace factoriel à l'aide de l'analyse des correspondances multiples (ACM avec le package fanalysis) ; puis classification à partir de la représentation factorielle. Choix de nombre de facteurs, réduction de dimension. Identification du nombre de classes via la librairie Yellowbrick. Encapsulation des traitements dans une structure "pipeline" de scikit-learn. Sauvegarde du "modèle" (pipeline) d'affectation dans un fichier à l'aide de la librairie "pickle". Ecriture d'un programme permettant de déployer le "modèle" sur un ficher d'individus supplémentaires.
Lien vidéo: https://www.youtube.com/watch?v=H_A8-Dr8bIw
Sources : Prog. et Données
Tandem Clustering - Classification sur données mixtes (R)
2023-03-04 (Tag:Vhg0MKZ4t2E)
Solution pour le clustering d'individus sur données hétérogènes composées de variables quantitatives et qualitatives en machine learning : (1) plonger les individus dans un espace factoriel à l'aide d'un algorithme qui permet de traiter le mix de variables (l'analyse factorielle des données mixtes - AFDM - en l'occurrence) ; (2) puis appliquer un algorithme de classification (classification ascendante hiérarchique CAH ici) à partir de la représentation factorielle des individus. Au passage, nous opérons une réduction de dimension en n'exploitant qu'une partie des composantes principales, une forme de nettoyage des données. Utilisation du langage et logiciel R, avec les fonctions FAMD (package FactoMineR) et hclust (stats).
Lien vidéo: https://www.youtube.com/watch?v=Vhg0MKZ4t2E
Sources : Prog. et Données
Clustering Variables Qualitatives - Classification des modalités (Python)
2023-02-25 (Tag:QVK3i44oGx8)
Principe du clustering des variables qualitatives. Structuration / regroupement des modalités après un codage disjonctif complet. Indice de Dice entre les indicatrices. Matrice de distance. CAH, classification ascendante hiérarchique, algorithme non-supervisé de machine learning. Identification des groupes. Lecture des résultats. Utilisation des variables (modalités) illustratives pour renforcer les interprétations. Traitements sous Python avec les packages Pandas, Numpy et Scipy.
Lien vidéo: https://www.youtube.com/watch?v=QVK3i44oGx8
Sources : Prog. et Données
Clustering de Variables Quantitatives (Python)
2023-02-25 (Tag:Wwq20qxS2E8)
Regroupement / structuration de variables à l'aide d'un algorithme de clustering (cah - classification ascendante hiérarchique). Mesure de similarité entre les variables, coefficient de corrélation vs. carré du coefficient de corrélation. Dérivation d'une mesure de dissimilarité / distance entre les variables. Mise en oeuvre de la méthode de machine learning. Identification des groupes. Lecture des résultats. Enfin, exploitation des variables supplémentaires pour renforcer l'interprétation. Traitements sous Python avec les librairies Pandas, Numpy et Scipy.
Lien vidéo: https://www.youtube.com/watch?v=Wwq20qxS2E8
Sources : Prog. et Données
Clustering Mixte - Combinaison Carte de Kohonen et CAH (R)
2023-02-16 (Tag:HIV1WJ6dg6A)
Combiner les avantages des Cartes de Kohonen (SOM - Self Organizing Maps) et de la CAH (classification ascendante hiérarchique) dans le traitement des grandes bases en classification automatique (clustering, apprentissage non-supervisé). SOM permet de construire des pré-clusters qui sont regroupés par la CAH ensuite. L'avantage ici est que SOM est aussi un algorithme de réduction de dimension et de visualisation des données. Dans notre processus, ses outils d'interprétation visuelle permettent d'identifier relativement aisément les caractéristiques des groupes finaux. Utilisation du logiciel R, avec les procédures som (package "kohonen") et hclust (stats).
Lien vidéo: https://www.youtube.com/watch?v=HIV1WJ6dg6A
Sources : Prog. et Données
Clustering Mixte - Combinaison K-Means et CAH (R)
2023-02-14 (Tag:nik6O1DGykc)
Combiner les avantages de la méthode des K-Means et de la CAH (classification ascendante hiérarchique) pour le traitement des grosses volumétries en clustering. Construction de pré-clusters dans une première étape avec les K-Means ; agrégation des pré-clusters avec la CAH pour aboutir à la partition finale. Focus sur le processus d'association des individus aux groupes finaux. Utilisation du logiciel R, avec les procédures kmeans (package "historique" stats) et hclust (stats).
Lien vidéo: https://www.youtube.com/watch?v=nik6O1DGykc
Sources : Prog. et Données
Clustering - Mesures d'évaluation des partitions (Scikit-learn Python)
2023-02-05 (Tag:I6__VDxBH_M)
Présentation de quelques mesures - principalement celles proposées par la librairie Scikit-Learn pour Python - utilisées pour évaluer la qualité d'une partition issu d'un algorithme de classification automatique (clustering dans la terminologie machine learning). Mesures externes, basées sur la confrontation entre les vraies classes d'appartenance et les clusters issus du calcul. Mesures internes, fondées sur les notions de compacité et de séparabilité. Traitement des données "Iris de Fisher". Notebook Python sous VS Code (Visual Studio Code). Voir aussi la documentation de Scikit-Learn "Clustering Performance Evaluation".
Lien vidéo: https://www.youtube.com/watch?v=I6__VDxBH_M
Sources : Prog. et Données
Notebooks Jupyter (Python) avec Visual Studio Code (VS Code)
2023-02-04 (Tag:OKVmfEqa1jQ)
Création de notebook ".ipynb" avec VS Code pour les projets de machine learning sous Python. Installation automatique des extensions. Choix du noyau (kernel). Possibilité d'utilisation des environnements Anaconda (conda). Exportation d'un notebook sous la forme d'un rapport HTML consultable avec un navigateur. Alternance de codes, résultats, commentaires Markdown pour l'élaboration d'un rapport.
Lien vidéo: https://www.youtube.com/watch?v=OKVmfEqa1jQ
Fichier environnement conda - Jupyter notebook et VSCode (Python)
2023-01-14 (Tag:WO3DXfZEqwA)
Installation d'un groupe de packages pour un projet Python. Principe des fichiers d'environnement conda (gestionnaire d'environnements). Contenu d'un fichier yaml (yml), importation à partir d'Anaconda Navigator, activation de l'environnement et création d'un notebook Jupyter, vérification des versions des packages. Alternative avec l'utilisation de VSCode (Visual Studio Code), création d'un notebook, activation de l'environnement. Un mot sur la possibilité d'installer conda, et de bénéficier du même mécanisme, dans Google Colab.
Lien vidéo: https://www.youtube.com/watch?v=WO3DXfZEqwA
Introduction au clustering - K-means sous Knime - Fichier Iris
2023-01-08 (Tag:_33k9fDcOa0)
Importation et description des données. Standardisation des variables. K-means, interprétation des résultats, prototypes des classes. Variable illustrative qualitative. Classement d'un individu supplémentaire avec prise en compte de la transformation de variables. Lecture, interprétation et positionnement dans le premier plan factoriel de l'ACP (analyse en composantes principales).
Lien vidéo: https://www.youtube.com/watch?v=_33k9fDcOa0
Sources : Prog. et Données
Introduction au clustering - K-Means - Tanagra + Excel
2023-01-06 (Tag:rYaxYKmhag4)
Réalisation d'une analyse typologique en mixant les logiciels Tanagra et Excel. Description des données, la question de la standardisation, réalisation d'un K-Means dans Tanagra, récupération des groupes d'appartenance dans le tableur Excel. Post-traitement, interprétation des résultats : rapport de corrélation et valeurs-test pour les variables qualitatives, v de Cramer et valeurs-test pour les qualitatives. Déploiement, affectation d'un individu supplémentaire à l'un des groupes.
Lien vidéo: https://www.youtube.com/watch?v=rYaxYKmhag4
Sources : Prog. et Données
Tanagra - AFDM #2 - Variables illustratives, individus supplémentaires
2022-05-10 (Tag:Yughk88fSdE)
Analyse factorielle des données mixtes (AFDM) avec Tanagra. Traitement des variables illustratives, basé sur les corrélations pour les quantitatives, sur les moyennes conditionnelles pour les qualitatives. Traitement des individus supplémentaires, directement dans Tanagra, et à partir du tableau "Factor Scores Coefficients" dans un tableur. Représentation graphique incluant l'individu supplémentaire.
Lien vidéo: https://www.youtube.com/watch?v=Yughk88fSdE
Sources : Prog. et Données
Tanagra - AFDM #1 - Analyse factorielle des données mixtes
2022-05-09 (Tag:XOz4JZaflmE)
Analyse factorielle des données mixtes (AFDM). Analyse factorielle pour un mix de variables actives quantitatives et qualitatives. Type de données traité. Principe des calculs. Equivalences avec l'ACP (analyse en composantes principales) et l'ACM (analyse des correspondances multiples). Tableaux d'interprétation des résultats : contributions et qualités de représentation des variables via le carré des corrélations et des rapports de corrélations ; tableau des corrélations pour les quantitatives ; moyennes conditionnelles et valeurs test pour les modalités des qualitatives. Représentation (carte) des individus dans l'espace factoriel.
Lien vidéo: https://www.youtube.com/watch?v=XOz4JZaflmE
Sources : Prog. et Données
Tanagra - ACM #2 - Variables illustratives, individus supplémentaires
2022-04-01 (Tag:NC-C6217cZQ)
Analyse factorielle des correspondances multiples avec Tanagra : traitement des variables illustratives quantitatives (calculs basés sur les corrélations) et qualitatives (sur les moyennes conditionnelles) et des individus supplémentaires (à partir des coefficients du tableau "Factor Score Coefficients" de Tanagra et un codage disjonctif complet de la description de l'individu). Graphique sous Excel, positionnement relatif de l'individu supplémentaire par rapport aux individus actifs.
Lien vidéo: https://www.youtube.com/watch?v=NC-C6217cZQ
Sources : Prog. et Données
Tanagra - ACM (AFCM) #1 - Analyse (factorielle) des correspondances multiples
2022-04-01 (Tag:tQjf0nl11OE)
Analyse factorielle des correspondances multiples (AFCM). Type de tableau de données traité. Principe des calculs. Tableau des valeurs propres, correction de Benzécri, correction de Greenacre. Coordonnées des modalités, contributions, cosinus carrés, valeurs-test. Carte des modalités. Coordonnées des individus. Représentation dans le premier plan factoriel. Possibilité de représentation simultanée.
Lien vidéo: https://www.youtube.com/watch?v=tQjf0nl11OE
Sources : Prog. et Données
Tanagra - AFC #2 - Modalités lignes (colonnes) supplémentaires
2022-03-31 (Tag:jtZkWbKOwUg)
Analyse factorielle des correspondances (AFC). Calcul des coordonnées factorielles des modalités lignes (colonnes) supplémentaires à partir de leurs profils. Principe des calculs. Utilisation des tableaux "Factor scores coefficients for supplementary points" fournis par Tanagra. Insertion de la modalité supplémentaire dans la représentation factorielle (carte des modalités). L'exemple traite une modalité ligne, la transposition des calculs aux modalités colonnes ne présente aucune difficulté.
Lien vidéo: https://www.youtube.com/watch?v=jtZkWbKOwUg
Sources : Prog. et Données
Tanagra - AFC #1 - Analyse factorielle des correspondances
2022-03-31 (Tag:1eJrszLeBeI)
Analyse factorielle des correspondances (AFC). Tableau de contingence. Tableaux de profils lignes et colonnes : distance du KHI-2 entre profils, distance à l'origine (par rapport au profil moyen). Tableau sous indépendance, résidu standardisé et contributions au KHI-2. Notions d'attractions et de répulsions entre modalités lignes et colonnes. Représentation factorielle. Positionnement des modalités de même nature (les profils lignes entre eux, idem pour les profils colonnes). Représentation simultanée : analyse des proximités entre les modalités lignes et colonnes, relation avec la contribution au KHI-2.
Lien vidéo: https://www.youtube.com/watch?v=1eJrszLeBeI
Sources : Prog. et Données
Tanagra - ACP #6 - Tandem clustering : ACP + CAH
2022-03-30 (Tag:shIHQkWotEQ)
Approche combinée du clustering : associer algorithme de réduction de dimension (ACP - analyse en composantes principales) et méthode de classification automatique (CAH - classification ascendante hiérarchique). Intérêt de l'approche, son positionnement par rapport à un clustering sur les variables initiales utilisant la distance euclidienne, confrontation des résultats, positionnement des observations dans le repère factoriel. Le choix du nombre de facteurs à utiliser dans le processus de clustering reste une question ouverte.
Lien vidéo: https://www.youtube.com/watch?v=shIHQkWotEQ
Sources : Prog. et Données
Tanagra - ACP #5 - VARCLUS, clustering de variables
2022-03-29 (Tag:OCQDHYaIF0k)
Structuration des données avec la classification automatique des variables : l'algorithme VARCLUS, une approche descendante basé sur des calculs d'ACP (analyse en composantes principales) et de rotation d'axes. Notion de similarité entre variables, de distance, de variable synthétique représentative d'un groupe (cluster) de variables. Interprétation des résultats, appartenance aux groupes, détection du nombre de groupes. Les autres approches de classification de variables : algorithme ascendant hiérarchique, méthode de réallocation.
Lien vidéo: https://www.youtube.com/watch?v=OCQDHYaIF0k
Sources : Prog. et Données
Tanagra - ACP #4 - Rotation des facteurs (varimax), corrélations partielles
2022-03-26 (Tag:8uzu_Ay-SMk)
Analyse en composantes principales (ACP) sous Tanagra. Solutions pour le problème de l'effet taille. La rotation des facteurs (varimax - contributions, quartimax - cos2) avec le composant "Factor Rotation", intérêt, teneur des résultats, interprétation des résultats avec une meilleure association variables-composantes, préservation de la qualité de la représentation factorielle à nombre de composantes fixé. Le travail avec les corrélations partielles, introduction d'une (ou plusieurs) variables de contrôle dans l'ACP, intérêt de l'approche pour l'appréhension de l'effet taille, mais aussi plus globalement pour une lecture différente des informations portées par les données, construction des variables déflatées avec le composant "Residual Scores".
Lien vidéo: https://www.youtube.com/watch?v=8uzu_Ay-SMk
Sources : Prog. et Données
Tanagra - ACP #3 - Variables illustratives, individus supplémentaires
2022-03-25 (Tag:0QDCttXdq0Y)
Analyse en composantes principales (ACP) sous Tanagra : traitement des variables illustratives (quantitatives et qualitatives), corrélations avec les composantes , positionnement des modalités dans le premier plan factoriel à l'aide des moyennes conditionnelles (graphique sous Excel) ; projection des individus supplémentaires, automatiquement sous Tanagra, en post-traitement sous Excel via les moyennes et écarts-types calculés et les coefficients fournis par le composant "Principal Component Analysis".
Lien vidéo: https://www.youtube.com/watch?v=0QDCttXdq0Y
Sources : Prog. et Données
Tanagra - ACP #2 - Paramètres optionnels
2022-03-25 (Tag:MXKtw6YBT2E)
Analyse en composantes principales sous Tanagra, présentation des paramètres optionnels du composant "Principal Component Analysis" et lecture des résultats associés : test de sphéricité de Bartlett et indice MSA / KMO ( Kaiser, Mayer, Olkin) ; comparaison corrélations brutes et partielles ; comparaison corrélation brutes et corrélations reconstituées dans l'espace de représentation factoriel ; calcul des contributions et des cosinus carrés des individus, élaboration d'une représentation factorielle sous le tableur Excel en ne faisant apparaître que les individus à forte contribution.
Lien vidéo: https://www.youtube.com/watch?v=MXKtw6YBT2E
Sources : Prog. et Données
Tanagra - ACP #1 - Calculs, résultats, post-traitements sous Excel
2022-03-24 (Tag:FS89TcjqIHc)
Analyse en composantes principales (ACP), traitements sous Tanagra : importation des données via la macro-complémentaires (tanagra.xla), définition des rôles des variables, utilisation du composant "Principal Component Analysis", lecture des principaux tableaux de résultats (valeurs propres, détermination du nombre de composantes, tableau des corrélations avec les contributions et les cosinus carrés). Graphiques avec la représentation factorielle des individus et le cercle des corrélations. Possibilité de récupération des tableaux et des coordonnées factorielles dans Excel. Réalisation de traitements supplémentaires.
Lien vidéo: https://www.youtube.com/watch?v=FS89TcjqIHc
Sources : Prog. et Données
Explicabilité des modèles - Slides
2022-02-28 (Tag:8273652517454023817)
Dans certains domaines (ex. santé), il est primordial de comprendre la nature des relations entre les explicatives et la variable cible dans un modèle prédictif, parce qu'il faut justifier l'affectation réalisée en prédiction, parce que le modèle doit être validé par l'expert métier, parce que nous souhaitons tout simplement disposer d'une visibilité sur la pertinence des variables utilisées, etc. Les classifieurs linéaires ou encore les méthodes à base de règles se positionnent plutôt avantageusement dans cette optique. C'est moins le cas en ce qui concernent les réseaux de neurones ou encore les méthodes ensemblistes qui, pour aussi performantes qu'elles soient, se comportent comme des boîtes noires et produisent des résultats dont nous avons du mal à cerner la teneur.
Dans ce support de cours, nous nous intéressons aux outils agnostiques pour l'interprétation des modèles. "Agnostique" dans le sens où ils peuvent s'appliquer à tout type d'algorithme prédictif sans avoir à se pencher sur leurs mécanismes internes d'affectation. Il vient synthétiser et compléter plusieurs tutoriels qui abordaient le sujet sous plusieurs angles à l'aide de différents logiciels et/ou librairies.
Mots-clés : python, scikit-learn, shap, h2o, permutation feature importance, partial dependence plot, pdp, individual conditional expectation, ice, shapley values, shapley additive explanations
Support de cours : Interprétation des modèles
Références :
C. Molnar, "Interpretable Machine Learning", version 21/02/2022.
"(Vidéo) Outils pour l'interprétation des modèles", avril 2021.
"(Vidéo) Model Explainability par H2O", avril 2021.
"Importance des variables dans les modèles", février 2019.
"Graphique de dépendance partielle – R et Python", avril 2019.
Cours Delphi / Pascal - Travaux dirigés
2022-01-25 (Tag:5289145663913804781)
J'ai mis en ligne les séances de travaux dirigés de mon cours de Delhi / Pascal Objet : fiches de TD + corrections (10 séances, calibrées sur approximativement - parfois plus, parfois moins - 1h30 chacune). Avec deux innovations : j'ai passé les corrigés sur LAZARUS pour que tout un chacun puisse reproduire les exercices avec un environnement de développement intégré (EDI) totalement libre d'accès et multiplateforme ; des tutoriels vidéo facilitent la prise en main de l'outil pour la mise en oeuvre des thèmes clés.
Site du cours : Cours Delphi
Bonne Année 2022 – Bilan 2021
2022-01-01 (Tag:6227094332441139879)
L'année 2021 s'achève, 2022 commence. Je vous souhaite à tous une belle et heureuse année 2022.
Comme tous les ans à cette époque, je me lance dans un petit bilan chiffré permettant de situer mes contributions pédagogiques sur l'année écoulée. J'ai mis l'accent sur les vidéos en 2021. Je m'y suis fait finalement à ce mode de réalisation des tutoriels, en les accompagnant toujours des données et codes source des programmes utilisés (Python et R, sous forme de notebooks essentiellement). L'ensemble de mes sites enregistre 622 visites par jour sur 2021, on est dans les normes des années précédentes, et, grande nouveauté en termes de comptabilisation des accès, 209 vues par jour pour les vidéos sur la chaîne YouTube M2 SISE.
Autre innovation en ce début d'année 2022, le bilan est effectué sous forme de vidéo. Ce qui me permet de montre en temps réel les chiffres produits par les outils d'analyse Google et YouTube Analytics.
En cette nouvelle année, je souhaite le meilleur à tous les passionnés de Data Science, de Statistique et d'Informatique.
Ricco.
Vidéo : Bilan 2021 – Google & YouTube Analytics
Diaporama : Slides Bilan 2021
(Vidéo) Représentation pré-entraînée GloVe avec Keras
2021-12-26 (Tag:8163992277147501323)
Je montre dans cette vidéo comment, avec la librairie bien connue de deep learning Keras, exploiter une représentation pré-entraînée GloVe dans une démarche d'analyse de sentiments, plus généralement dans la catégorisation de textes. L'analyse des grands corpus de documents (ex. Wikipedia + GigaWord) permet de projeter les termes dans un espace de représentation dont la dimensionnalité est contrôlée (hyperparamètre de l'algorithme). Cette représentation constitue ainsi la première couche "embedding" du réseau de neurones prédictif sous Keras. Sur notre corpus d'apprentissage (analyse des sentiments sur des tweets), l'entraînement du réseau pour le calcul des poids synaptiques reliant cette couche d'entrée avec la sortie se fait alors classiquement à l'aide d'une descente de gradient.
Mots-clés : text mining, catégorisation de textes, word embedding, keras, deep learning, python, glove, perceptron, nlp, natural language processing
Vidéo : Glove Keras
Notebook Python : Twitter Sentiment Analysis
Références :
"(Vidéo) La couche Embedding de Keras en NLP", décembre 2021.
"(Vidéo) Modèle pré-entraîné Word2Vec avec Gensim", décembre 2021.
"Glove : Global Vectors for Word Representation", J. Pennington, R. Socher, C. Manning.
(Vidéo) La couche Embedding de Keras en NLP
2021-12-24 (Tag:8387136119984020830)
Nous nous intéressons à la couche Embedding de Keras dans cette vidéo. Il s'agit d'une couche de réseaux de neurones qui permet de représenter les termes dans un espace intermédiaire. Elle fait partie en cela des techniques de "word embedding". Mais, contrairement aux approches basées sur le voisinage telles que "Word2Vec", elle est intégrée dans un processus de modélisation prédictive. Elle ouvre également la porte à des opérateurs que nous trouvons habituellement dans les réseaux de convolutions utilisés en classement d'images. Nous illustrons notre propos par l'analyse de sentiments sur un corpus de tweets (Twitter). Après un premier modèle très basique, nous intégrons la régularisation via des mécanismes telles que le "max pooling" ou encore le "dropout" pour améliorer les performances prédictives.
Mots-clés : text mining, catégorisation de textes, tensorflow, keras, tweet, twitter, python, deep learning, nlp, natural language processing
Vidéo : Keras Embedding
Notebook Python : Twitter Dataset
Références :
"(Vidéo) Perceptron avec Tensorflow / Keras (Python)", juillet 2021.
"(Vidéo) Natural Language Processing avec Keras", décembre 2021.
"(Vidéo) Word2Vec / Doc2Vec avec Gensim – Python", décembre 2021.
(Vidéo) Natural Language Processing avec Keras
2021-12-22 (Tag:2729040876256946384)
Dans cette vidéo, nous traitons un problème d'analyse des sentiments à partir d'un corpus de tweets étiquetés. Nous exploitons le tandem de librairies Tensorflow et Keras sous Python. Nous nous plaçons dans le cadre usuel de la catégorisation de documents en nous basant sur une représentation bag-of-words (sac de mots). Le modèle prédictif est un réseau de neurones, plus précisément un perceptron multicouche. Nous nous intéressons alors à la représentation intermédiaire des données induite par la couche cachée. Les résultats nous amènent plusieurs éléments de réflexion concernant le surapprentissage et les pistes pour y remédier dans notre contexte.
Mots-clés : text mining, catégorisation de textes, tensorflow, keras, tweet, twitter, python
Vidéo : Keras Sentiment Analysis
Notebook Python + Données : Twitter Dataset
Références :
"(Vidéo) Perceptron avec Tensorflow / Keras (Python)", juillet 2021.
"Deep Learning avec Tensorflow et Keras (Python)", avril 2018.
"Text mining : la catégorisation de textes – Diapos", novembre 2016.
"Sentiment 140 - For Academics"
(Vidéo) Modèle pré-entraîné Word2Vec avec Gensim
2021-12-20 (Tag:8094008667171453909)
Je montre dans cette vidéo comment exploiter un modèle pré-entraîné dans une démarche d'analyse de sentiments, plus généralement dans la catégorisation de textes. L'idée est d'utiliser une vectorisation de termes Word2Vec issue de l'analyse de grands corpus (ex. Wikipedia avec Wikipedia2Vec) pour projeter les documents dans un nouvel espace de représentation. Disposant ainsi d'un tableau individus (documents) -variables (features) de dimensionnalité réduite (paramétrable), nous pouvons mettre en œuvre de manière tout à fait classique les algorithmes supervisés de machine learning. Nous avons fait le choix d'un support vector machine (svm) avec un noyau RBF pour notre exemple, nous aurions pu utiliser toute autre solution prédictive.
Mots-clés : text mining, catégorisation de textes, word embedding, word2vec, doc2vec, gensim, python
Vidéo : Wikipedia2Vec
Notebook Python + Données : Imdb Reviews
Références :
"Deep Learning : l'algorithme Word2Vec", décembre 2019.
"Word2Vec avec H20 sous Python", décembre 2019.
"(Vidéo) Word2Vec / Doc2Vec avec Gensim – Python", décembre 2021.
(Vidéo) Word2Vec / Doc2Vec avec Gensim - Python
2021-12-17 (Tag:4038996997275221699)
Cette vidéo est consacrée à la mise en œuvre du prolongement lexical, en particulier l'algorithme Word2Vec, à l'aide de la librairie Gensim pour Python. L'idée repose sur une forme de contextualisation des termes. Concrètement, on cherche à les représenter à l'aide de vecteurs numériques, de manière à ce que des termes voisins dans les documents présentent une forte similarité (au sens d'un indice telle que la similarité cosinus par exemple) dans le nouvel espace de représentation. La démarche peut être étendue aux documents (l'algorithme Word2Vec). Ainsi, nous disposons d'une représentation des corpus dans un espace de représentation de dimension réduite, paramétrable, rendant possible la mise en œuvre subséquente des techniques de machine learning (ex. catégorisation de documents).
Mots-clés : text mining, tokenisation, dictionnaire, word embedding, word2vec, doc2vec, gensim
Vidéo : Gensim Word2Vec
Notebook Python + Données : Imdb Reviews
Références :
"Deep Learning : l'algorithme Word2Vec", décembre 2019.
"Word2Vec avec H20 sous Python", décembre 2019.
(Vidéo) Topic Modeling avec Gensim / Python
2021-12-08 (Tag:6856840283633005947)
Cette vidéo est consacrée à la mise en oeuvre du "topic modeling" avec le package "Gensim" pour Python. J'avais déjà consacré une vidéo sur ce sujet sous Knime. La trame reste la même. L'objectif est d'extraire des thématiques caractérisées par des termes à partir d'un corpus de documents. La spécificité ici est bien sûr est l'utilisation des packages spécialisés sur Python. Outre Gensim, nous mettons également à contribution NLTK (Natural Language Toolkit) pour la partie pré-traitement.
Mots-clés : text mining, tokenisation, dictionnaire, représentation bow, bag of words, topic model, topic modeling, latent dirichlet allocation, LDA, gensim, nltk, python
Vidéo : Gensim Topic Model
Notebook Python + Données : Imdb Reviews
Références :
"Text mining : Topic Model", décembre 2016.
"(Vidéo) Topic Modeling avec Knime", novembre 2021.
(Vidéo) Word Embedding – L'algorithme Word2Vec
2021-11-30 (Tag:720199725254963036)
Cette vidéo montre la mise en oeuvre de l'algorithme Word2Vec en NLP (natural language processing) avec le logiciel Knime. Nous poursuivons un double objectif : représenter les termes par un vecteur de dimension "p" (hyperparamètre de l'algorithme) restituant leurs voisinages ; caractériser les documents en s'appuyant sur cette représentation.
Mots-clés : word embedding, word2vec, knime, nlp, natural language processing, réduction de dimensionnalité, deep learning, doc2vec
Vidéo : Word2Vec
Workflow Knime + Données : Imdb Reviews
Références :
"Deep Learning : l'algorithme Word2Vec", décembre 2019.
"Word2Vec avec H2O sous Python", décembre 2019.
(Vidéo) StandardScaler et descente de gradient
2021-11-24 (Tag:4574301366155857253)
Cette vidéo montre l'influence de la standardisation (centrage-réduction) des variables prédictives quantitatives sur l'algorithme de descente de gradient stochastique lors de la minimisation de la fonction de coût pour l'estimation des coefficients de la régression logistique binaire. La transformation joue sur la vitesse de convergence de l'algorithme, elle pèse en conséquence sur les qualités prédictives du classifieur. Nous travaillons avec les outils de la librairie "scikit-learn" pour Python.
Mots-clés : régression logistique binaire, scikit-learn, standardisation, transformation de variables
Vidéo : StandardScaler
Notebook + Données : Pima Indians Diabetes
Références :
"Régression logistique – Machine Learning", septembre 2021.
Page de cours "Régression Logistique".
(Vidéo) Topic Modeling avec Knime
2021-11-18 (Tag:3026982922186313508)
Cette vidéo est consacrée à la mise en oeuvre du "topic modeling" avec le logiciel Knime (package Text processing). La méthode consiste à extraire des corpus des "thèmes" (topics), en faible nombre, que l'on caractérise à partir des termes (tokens) qui composent les documents. On peut aussi la voir sous l'angle de la réduction de la dimensionnalité dans la mesure où nous disposons d'une description des documents dans l'espace des topics. Procéder à des analyses subséquentes est ainsi possible. Nous l'illustrons par le regroupement des documents en groupes (clusters) à l'aide d'un algorithme de classification automatique (k-means).
Mots-clés : knime, text mining, tokenisation, dictionnaire, matrice documents-termes, pondération, catégorisation de documents, topic model, topic modeling, latent dirichlet allocation, LDA, clustering,
Vidéo : Knime Topic Model
Workflow + Données : Imdb Reviews
Références :
"Text mining : Topic Model", décembre 2016.
"(Vidéo) Text mining avec Knime", novembre 2021.
(Vidéo) Text mining avec Knime
2021-11-08 (Tag:8760315959571337879)
Je montre dans cette vidéo quelques fonctionnalités de la librairie « Text processing » du logiciel Knime. Je mets l’accent en particulier sur la catégorisation de documents avec la comparaison des performances de deux algorithmes de machine learning dans un espace à très forte dimensionnalité. Sont tour à tour abordés les thèmes suivants : la conversion de textes en corpus, le pré-traitement (suppression des ponctuations, des mots-vides, de chiffres, l’harmonisation de la casse), la tokenisation, la représentation des documents en sac de mots, la matrice documents termes avec la pondération booléenne, l’analyse prédictive avec les arbres de décision et la régression logistique régularisée (Ridge).
Mots-clés : knime, tokenisation, dictionnaire, matrice documents-termes, pondération, catégorisation de documents
Vidéo : Knime Text Mining
Workflow + Données : Imdb Reviews
Références :
« Text mining avec Knime et RapidMiner », avril 2014.
(Vidéo) Text mining avec quanteda sous R
2021-11-05 (Tag:6585408001920926626)
Je montre dans cette vidéo les principales fonctionnalités du package de text mining "quanteda" pour R. Nous abordons tour à tour : le pré-traitement du corpus (suppression des ponctuations, des mots-vides, de chiffres, l'harmonisation de la casse), la tokenisation, la représentation des documents en sac de mots, les pondérations "term frequency" et binaires, la constitution du dictionnaire, l'analyse du voisinage des termes, le calcul des associations entre termes et variables supplémentaires. Nous donnons une tournure opérationnelle à la présentation en décrivant de manière approfondie un processus de catégorisation automatique de documents à l'aide d'un algorithme de machine learning – un SVM, support vector machine – de la librairie "e1071".
Mots-clés : logiciel R, package quanteda, tokenisation, dictionnaire, matrice documents-termes, pondération, catégorisation de documents, svm linéaire
Vidéo : Quanteda
Notebook R + Données : Imdb Reviews
Références :
"quanteda : Quantitative Analysis of Textual Data".
(Vidéo) Text mining avec tidytext sous R
2021-11-04 (Tag:7669680381654689698)
Je montre dans cette vidéo les principales fonctionnalités du package de text mining "tidytext" pour R. Nous abordons tour à tour : le pré-traitement du corpus (suppression des ponctuations, des mots-vides, de chiffres, l'harmonisation de la casse), la tokenisation, la représentation des documents en sac de mots, la pondération "term frequency", la constitution du dictionnaire, l'analyse des sentiments associés aux documents à partir de la polarité des termes recensés dans un lexique dédié.
Mots-clés : logiciel R, package tidytext, tidyverse, tokenisation, dictionnaire, matrice documents-termes, pondération, analyse des sentiments
Vidéo : Tidytext
Notebook R + Données : Imdb Reviews
Références :
"Text mining with R", J. Silge & D. Robinson.
(Vidéo) Subdivision train-test avec scikit-learn
2021-11-01 (Tag:10381121809666916)
Cette vidéo montre comment subdiviser aléatoirement un jeu de données en échantillons d'apprentissage et de test à l'aide de la fonction train_test_split(.) de la librairie "scikit-learn". J'essaie de mettre l'accent sur plusieurs aspects qui me paraissent important : l'organisation des données à présenter au module, le rôle des paramètres (train_size, random_state, stratify), les structures de données obtenues en sortie. Quelques statistiques descriptives simples permettent de s'assurer de la régularité du partitionnement.
Mots-clés : python, scikit-learn, train_test_split
Vidéo : Train test split
Code Python + Données : Breast Dataset
Références :
"Python - Machine learning avec scikit-learn", septembre 2015.
(Vidéo) Machine learning avec PyCaret
2021-10-30 (Tag:1992364301537007540)
"PyCaret" est la version Python du fameux package "caret" pour R. Il s'agit toujours d'un meta-package dans le sens où il ne programme pas directement les algorithmes de machine learning. Il s'appuie sur d'autres librairies pour cela, en particulier sur "scikit-learn". Il ajoute plutôt une surcouche destinée à nous faciliter la vie en prenant en charge une grande partie des tâches répétitives et fastidieuses de la pratique de la data science (élaboration d'un pipeline, préparation des données, détermination des meilleurs algorithmes, optimisation des hyperparamètres, déploiement, etc.).
Cette vidéo montre comment mettre à profit "PyCaret" dans un schéma d'analyse prédictive, s'inspirant assez fortement du travail que je demande à mes étudiants lorsque j'évalue leur capacité à mener à bien un projet complet de machine learning dans un temps réduit.
Mots-clés : python, pycaret, extra trees, gradient boosting, random forest
Vidéo : Machine learning PyCaret
Notebook + Données : Spam Dataset
Références :
"Machine learning avec caret – Package R", avril 2018.
(Vidéo) Arbres de décision avec scikit-learn
2021-10-30 (Tag:8934711520078593122)
Cette vidéo montre comment construire un arbre de décision avec la librairie "scikit-learn" pour Python. Nous utilisons la fameuse base iris. Les principales étapes abordées sont : l'entraînement de l'arbre sur l'échantillon d'apprentissage, les différents modes d'affichage de l'arbre, la prédiction et l'évaluation sur l'échantillon test, la modification des hyperparamètres et ses conséquences sur les performances du classifieur.
Mots-clés : python, scikit-learn, arbres de décision, decision tree
Vidéo : Arbres scikit-learn
Notebook + Données : Iris Dataset
Références :
"Python - Machine Learning avec scikit-learn", septembre 2015.
"Arbres de décision avec Scikit-Learn", février 2020.
(Vidéo) Scoring – Courbe Lift
2021-10-14 (Tag:5433361630545617219)
Deux vidéos pour le prix d'une cette fois-ci. Nous retraçons la construction de la courbe de gain (courbe lift cumulé) à l'aide du tandem Tanagra + Excel. L'idée est de reproduire pas-à-pas les étapes décrites dans le cours : construction du modèle prédictif à partir de l'échantillon d'apprentissage, mise en lumière de la fonction score, son application sur l'échantillon test pour obtenir les scores des individus (probabilités d'appartenance à la classe cible, ou une grandeur équivalente), conception des deux colonnes permettant l'élaboration de la courbe (taille de cible et taux de vrais positifs [rappel, sensibilité]). Deux vidéos parce que nous utilisons l'analyse discriminante linéaire d'une part, la régression logistique d'autre part.
Mots-clés : tableur excel, courbe lift cumulé, courbe de gain, gain chart
Vidéo 1 : Scoring – Analyse Discriminante
Vidéo 2 : Scoring – Régression logistique
Données : Heart Dataset
Références :
"Scoring – Ciblage Marketing".
(Vidéo) Ridge, Lasso – Optim. des hyperparamètres
2021-10-07 (Tag:9055970794191919428)
La question de l'optimisation des hyperparamètres des algorithmes de machine learning est posée dans cette vidéo. Nous nous appuyons sur l'exploration des performances mesurées en validation croisée sur l'échantillon d'apprentissage. Nous prenons pour exemple la régression logistique binaire, avec les régression pénalisées "Ridge" et "Lasso", pour lesquels nous faisons varier le paramètre de régularisation. L'outil GridSearchCV de la librairie Scikit-Learn pour Python est mise à contribution.
Mots-clés : python, scikit-learn, régression logistique binaire, gridsearchcv
Vidéo : Hyperparamètres Ridge Lasso
Notebook + Données : Spam Dataset
Références :
"Python - Machine Learning avec scikit-learn", septembre 2015.
"Régression logistique sur les grandes bases avec scikit-learn", décembre 2020.
"Pipeline Python pour le déploiement", janvier 2021.
Régression Logistique – Machine Learning
2021-09-28 (Tag:5471861669094523241)
Ce document est une version simplifiée et "modernisée" de mon support de cours pour la régression logistique, un peu plus "machine learning", un peu moins "statistique". Elle fait la part belle aux algorithmes d'optimisation, et essaie de clarifier autant que faire se peut le rôle des hyperparamètres. Sont tour à tour présentés : le mode d'estimation des coefficients de la régression, l'explicitation de l'importance des variables, les différentes approches pour la sélection de variables, les mécanismes de régularisation pour la régression en grandes dimensions (ridge, lasso, elasticnet), la régression multiclasse (approche multinomiale et combinaison de régressions binaires). L'interprétation approfondie des coefficients (odds-ratio), l'analyse des interactions, et l'inférence statistique qui s'y rapportent (tests, intervalles de confiance) ont été mis de côté.
Signe des temps, les exemples illustratifs sont réalisés sous Python avec la fameuse librairie "Scikit-Learn".
Mots-clés : régression logistique binaire, algorithmes d'optimisation, newton-raphson, descente de gradient, descente de gradient stochastique, importance des variables, sélection de variables, rfe, recursive feature elimination, rfecv, cross-validation, validation croisée, régression multiclasse, modèle multinomial, régressions one vs. rest, ovr, ridge, lasso, elasticnet
Support : ML – Régression logistique
Notebooks Python et fichiers : Breast - Iris
Références :
Page de cours "Régression logistique".
"Python - Machine learning avec scikit-learn", septembre 2015.
"Vidéo – Régression logistique avec Python / Scikit-Learn", juillet 2021.
"Régression logistique sous Python (Scikit-Learn, Statsmodels)", mars 2020.
(Vidéo) Excel – Filtres, tableaux croisés
2021-09-25 (Tag:866472562039380317)
Cette vidéo présente rapidement quelques outils pour la manipulation des tables de données dans le tableur Excel. Nous voyons tour à tour : les filtres automatiques et avancés, puis les tableaux croisés dynamiques. Une illustration de l'utilisation de la fonction SI(…) d'Excel est également proposée.
Mots-clés : tableur, excel, listes de données, filtres, TCD, tableaux croisés dynamiques
Vidéo : Filtres & TCD Excel
Fichier : Produits
Références :
Filtres automatiques, avancés, tableaux croisés dynamiques.
(Vidéo) Cross-validation, leave-one-out
2021-09-16 (Tag:2522547247436124460)
Cette vidéo s'attache à montrer l'intérêt et le mode opératoire de deux techniques de rééchantillonnage dans l'évaluation des performances des classifieurs : la validation croisée (cross-validation) et le leave-one-out. Je les positionne en particulier par rapport aux techniques usuelles d'évaluation en resubstitution et en schéma holdout (apprentissage-test). Une démonstration sous Tanagra montre les écarts que l'on peut observer entre les taux d'erreurs estimés selon les approches adoptées avec une base (200 observations vs. 60 variables prédictives candidates) et un algorithme (arbres de décision avec C4.5) propices au sur-apprentissage. Ils sont très révélateurs de leurs comportements respectifs.
Mots-clés : cross-validation, leave-one-out, holdout, resubstitution, taux d'erreur, arbres de décision, c4.5
Vidéo : Cross-validation
Slides : Schéma validation croisée
Données : Sonar
Références :
"Validation croisée, Boostrap (Diapos)", février 2015.
(Vidéo) SAS sous Python avec SASPy
2021-08-03 (Tag:8920120723011894772)
Dans cette vidéo, nous explorons les fonctionnalités du package SASPy. Il fournit des API qui permettent d'exploiter les fonctionnalités de la solution SAS Cloud pour l'enseignement académique. Plusieurs aspects retiennent particulièrement notre attention ici : la configuration de l'outil, qui n'est pas des plus simples ; la gestion en ligne des données, notamment l'accès aux banques SAS ; la mise en œuvre des algorithmes de machine learning et l'affichage des résultats. Nous privilégions un seul mode d'interaction avec le serveur distant dans notre tutoriel. En fin de vidéo, je précise les autres modalités possibles.
Mots-clés : sas, saspy, cloud, régression logistique, haute performance, random forest, sas ondemand for academics
Vidéo : SASPy
Données, fichier de configuration, notebook : Breast Cancer
Références :
"SASPy".
"SAS onDemand for Academics".
(Vidéo) Extension Intel(R) pour scikit-learn
2021-07-24 (Tag:971292834789316607)
L'extension Intel pour Scikit-learn est un package de machine learning pour Python. Il reproduit les signatures de fonctions et les fonctionnalités de Scikit-learn, mais s'appuie en sous-main sur la librairie oneAPI Data Analytics Library (oneDAL) d'Intel. Il se présente comme un patch que l'on peut appliquer à des projets de machine learning développés (ou que nous sommes en train de développer) à l'aide de scikit-learn, sans voir à introduire d'autres modifications dans le code source. L'intérêt est de bénéficier des capacités de calcul accrues de la librairie d'Intel, en particulier en termes de temps de traitement.
Dans cette vidéo, nous appliquons les SVM (SVC de Scikit-learn) sur la base "segmentation" dupliquée 8 fois (18480 observations, 19 descripteurs). Par rapport à Scikit-learn, le temps d'exécution a été réduit d'un facteur de 1.43 dans la phase d'apprentissage, et de 100 fois (!) durant la prédiction en resubstitution.
Les tutoriels accessibles sur la page web du package montrent qu'il est possible d'obtenir des gains plus spectaculaires encore lorsque l'on exploite des machines autrement mieux charpentées que la mienne.
Mots-clés : svm, support vector machine, scikit-learn, oneDAL
Vidéo : Extension Scikit-learn - Python
Données et notebook : SVM Segmentation
Références :
"Intel(R) extension for Scikit-learn".
"oneAPI Data Analytics Library".
(Vidéo) Perceptron avec TensorFlow / Keras (Python)
2021-07-18 (Tag:5820454955533319655)
Dans cette vidéo, nous implémentons des perceptrons simples et multicouches sous Python. Ce type de réseau de neurones est bien connu aujourd'hui. L'intérêt ici est d'étudier leur mise en œuvre et l'inspection des résultats avec l'utilisation du tandem de librairies TensorFlow et Keras qui font référence dans la pratique du deep learning.
Un précédent document rédigé (avril 2018) étudiait le même sujet, en traitant d'autres bases de données. Mis à part une commande spécifique pour la prédiction, nous constatons que les fonctionnalités spécifiques à notre étude (analyse prédictive) sont restées stables. Cet aspect est toujours rassurant pour la maintenance évolutive de nos projets de machine learning.
Mots-clés : réseau de neurones, perceptron simple, perceptron multicouches, deep learning, tensorflow, keras
Vidéo : TensorFlow / Keras - Python
Données et notebook : Segmentation dataset
Références :
"Deep Learning avec TensorFlow et Keras (Python)", avril 2018.
(Vidéo) Anaconda Python - Environnements
2021-07-16 (Tag:1456101798023141896)
La gestion des packages peut se révéler délicate sous Anaconda Python. Certains projets nécessitent un pool de librairies avec des versions spécifiques, parfois même avec une version dédiée de l'interpréteur Python. Modifier en conséquence la configuration de base de la distribution n'est pas adaptée. Des problèmes d'incompatibilités peuvent apparaître. On risque même de compromettre le bon fonctionnement d'autres projets existants.
Le mécanisme des environnements permet de dépasser ces potentiels problèmes. L'idée est de créer un espace dédié pour chaque projet, au sein duquel nous installons la version de Python et les packages idoines. Ainsi, au fil du temps, nous avons l'assurance de retrouver à chaque démarrage de notre projet la configuration adéquate. Pour illustrer notre propos, nous montrons dans cette vidéo la création d'un environnement à l'aide du gestionnaire "conda". Nous installons alors les dernières versions (à ce jour) des librairies fameuses de deep learning, tensorflow et keras. Nous démarrons enfin le notebook Jupyter (qu'il faut également installer dans l'environnement) pour vérifier leur disponibilité.
Mots-clés : anaconda python, conda, environnements, tensorflow, keras
Vidéo : Conda Environnement
Références :
Conda, Managing Environments.
(Vidéo) Régression logistique avec Python / scikit-learn
2021-07-13 (Tag:363912607528236056)
Dans cette vidéo, nous étudions les fonctionnalités de la régression logistique proposée par la librairie scikit-learn de Python. Nous inspectons les résultats, en particulier la lecture des coefficients et leur exploitation en tant qu'indicateurs de pertinence des variables. Nous embrayons alors sur la sélection de variables en détaillant le mode opératoire de l'outil RFE (recursive feature elimination), qui combine la stratégie backward avec la méthodologie wrapper basée sur la mesure des performances en validation croisée (RFECV). L'étude de cas confirme encore une fois la nature exploratoire de la démarche machine learning.
Mots-clés : régression logistique binaire, sélection de variables backward, wrapper, accuracy, taux de reconnaissance, recursive feature elimination, rfe, refcv, validation croisée, scikit-learn
Vidéo : Logistic Python
Données et notebook : Vote au Congrès
Références :
Page de cours "Régression logistique".
"Régression logistique sous Python", mars 2020.
"Python – Machine learning avec sckit-learn", septembre 2015.
"(Vidéo) Python – La package Yellowbrick", mars 2021.
(Vidéo) Régression logistique avec Knime
2021-07-08 (Tag:3674351393170738954)
Dans cette vidéo, nous étudions les fonctionnalités de la régression logistique proposée dans Knime Analytics Platform. Nous appliquons le schéma usuel "holdout" dans un premier temps, un modèle prédictif est élaboré à partir d'une base d'apprentissage, il est par la suite évalué sur une base de test. Nous comparons les résultats obtenus par ailleurs avec d'autres outils. Dans un second temps, nous implémentons une approche de sélection de variables "wrapper" où l'objectif est de chercher le sous-ensemble de variables explicatives le plus performant au sens d'un critère de performance.
Mots-clés : régression logistique binaire, sélection de variables forward, wrapper, accuracy, taux de reconnaissance, knime
Vidéo : Logistic Regression Knime
Données et workflow : Vote au Congrès
Références :
Page de cours "Régression logistique".
"Analyse prédictive sous Knime", février 2016.
(Vidéo) La Proc Logistic de SAS
2021-07-08 (Tag:6351590081695738262)
Dans cette vidéo, nous réalisons une régression logistique sous SAS Studio, version accessible via le programme SAS OnDemand for Academics. Après avoir importé le fichier de données (classeur Excel) dans le cloud, nous le chargeons dans la banque WORK, nous lançons ensuite les traitements : une régression logistique binaire basique dans un premier temps, nous introduisons la sélection de variables ensuite, à laquelle nous associons la construction de la courbe ROC pour l'évaluation des performances des modèles.
Mots-clés : régression logistique binaire, sélection de variables forward, courbe ROC, critère AUC, SAS Studio, SAS OnDemand for Academic
Vidéo : Proc Logistic
Données, programmes et sorties : Vote au Congrès
Références :
Page de cours "Régression logistique".
"La proc logistic de SAS 9.3", avril 2012.
(Vidéo) Régression logistique pas-à-pas
2021-07-06 (Tag:6435386581520359792)
Dans cette vidéo, nous détaillons une démarche d'analyse prédictive en utilisant le tandem Tanagra et tableur (Excel). La modélisation, via la régression logistique binaire, sur l'échantillon d'apprentissage est réalisée à l'aide de Tanagra. Le déploiement du modèle sur l'échantillon test est réalisée "manuellement" sous le tableur Excel. Il comprend : le calcul du logit, la dérivation de la probabilité d'appartenance à la classe cible, la déduction de la classe d'appartenance prédite. La matrice confusion est ensuite calculée, ainsi que les indicateurs de performances usuels. Nous comparons enfin les performances prédictives des modèles sans et avec sélection de variables.
Mots-clés : régression logistique binaire, sélection de variables forward, matrice de confusion, taux d'erreur, rappel / sensibilité, précision
Vidéo : Régression logistique avec Tanagra / Excel
Classeur Excel et schéma : Vote au Congrès
Références :
Page de cours "Régression logistique".
(Vidéo) Régression avec la "proc reg" de SAS
2021-06-04 (Tag:3551836713667207076)
Dans cette vidéo, nous présentons l'utilisation de la PROC REG de SAS dans un exercice de régression linéaire multiple. Nous avons accès à SAS Studio en ligne via le programme SAS OnDemand for Academics. Nous effectuons un tour rapide des fonctionnalités de l'outil : la régression, l'inspection des résultats, les graphiques des résidus, la détection des points atypiques, la sélection de variables.
Mots-clés : économétrie, modèle linéaire, régression linéaire multiple
Vidéo : Régression multiple avec SAS
Données et code SAS : Consommation voitures
Références :
Documentation "PROC REG" de SAS.
(Vidéo) Régression linéaire avec Excel + Tanagra
2021-06-04 (Tag:9017295353363007493)
Dans cette vidéo, nous présentons l'utilisation du tandem Excel (Tableur) – Tanagra dans un exercice de régression linéaire multiple. L'idée est d'exploiter les particularités des outils : le tableur pour la préparation des données et le post-traitement des résultats ; le logiciel spécialisé (Tanagra) pour la mise en œuvre des algorithmes de machine learning. Les thèmes abordés dans ce tutoriel sont : la régression, l'inspection des résultats, les graphiques des résidus, la détection des points atypiques, la sélection de variables et l'étude des colinéarités entre les exogènes.
Mots-clés : économétrie, modèle linéaire, régression linéaire multiple
Vidéo : Régression multiple avec Tanagra
Données : Consommation véhicules
Références :
Page de cours "Économétrie".
(Vidéo) Programmation parallèle sous R
2021-05-15 (Tag:8204255950946767287)
Cette vidéo présente la programmation parallèle sous R via l'utilisation des packages "parallel" et "foreach / doparallel". Nous reprenons l'idée du calcul du minimum d'un vecteur (déjà vu dans les vidéos précédentes : Dask / Python, Mapreduce sous R), mais avec un algorithme dégradé, en temps quadratique, pour mieux percevoir l'intérêt de la parallélisation des tâches lorsque les calculs deviennent complexes. Dès que la volumétrie est un tant soit peu conséquente, une meilleure utilisation des ressources des processeurs multicœurs s'avère décisive. Nous observerons aussi que les solutions proposées ("parallel" vs. "foreach / doparallel") ne présentent pas le même niveau de performances.
Mots-clés : logiciel r, programmation parallèle, parallel, foreach, doparallel
Vidéo : Parallel Programming with R
Programme : Calcul du minimum
Références :
"Programmation parallèle sous R", juin 2013.
(Vidéo) Programmation MapReduce sous R
2021-05-12 (Tag:3051982411578279723)
Cette vidéo présente la programmation MapReduce sous R via l'utilisation des packages de RHadoop. Elle s'attache en particulier à détailler les installations nécessaires au bon fonctionnement de la librairie "rmr2". Cette dernière n'est plus opérante avec les versions récentes de R (depuis les versions 3.5 et plus récentes en réalité). La solution préconisée passe par un downgrade (rétrogradage) de la version de R sous-jacente à RStudio, puis l'installation des librairies contemporaines. Un exemple de calcul du minimum d'un vecteur permet de vérifier la viabilité du dispositif.
Mots-clés : logiciel r, programmation parallèle, mapreduce, rmr, rhadoop
Vidéo : MapReduce R
Guide et programme : Calcul du minimum
Références :
"RHadoop".
"Programmation MapReduce sous R - Diapos", juillet 2015.
"MapReduce avec R", février 2015.
"Programmation R sous Hadoop", avril 2015.
(Vidéo) Parallel Machine Learning avec Dask
2021-05-10 (Tag:5289432391183625931)
Nous explorons les fonctionnalités machine learning de la librairie "dask" dans cette vidéo. Nous mettons en place un schéma classique d'analyse prédictive avec une régression logistique, similaire à ce que l'on réaliserait avec "scikit-learn", sauf que nous tirons parti de ce qui fait l'intérêt de "dask" : calculs différés permettant de définir et tester les opérations sans être bloqué par la manipulation de la totalité des données ; lecture en blocs du fichier de données, permettant de traiter des très grandes bases, y compris lorsque celles-ci ne tiennent pas en mémoire centrale ; parallélisation des traitements, tirant parti efficacement des spécificités de l'environnement numérique de travail.
Mots-clés : python, dask, dataframe, dask-ml, régression logistique
Vidéo : dask-ml
Données et programme : Dask Logistic Regression
Références :
"Dask: a flexible library for parallel computing in Python".
"Python – Machine Learning avec scikit-learn", septembre 2015.
(Vidéo) Gestion des DataFrame avec Dask (Python)
2021-05-07 (Tag:6386750148677868314)
Nous continuons l'exploration de la librairie "dask" pour Python dans cette vidéo. Nous traitons de la gestion des données. "dask" met à notre disposition un équivalent du DataFrame de Pandas, mais avec des capacités spécifiques pour le traitement des données massives : un chargement en blocs (chunks) des gros fichiers, l'accès à des systèmes de fichiers distribuées (HDFS de Hadoop par ex.), le traitement différé, la parallélisation des calculs. Avantage incommensurable par rapport à Pandas, le dispositif est fonctionnel même lorsque les données ne tiennent pas en mémoire centrale.
Mots-clés : python dask, dataframe, pandas
Vidéo : DataFrame avec Dask
Données et programme : CovType
Références :
"Dask: a flexible library for parallel computing in Python".
"R et Python, performances comparées", février 2019.
(Vidéo) Programmation parallèle avec Dask
2021-05-04 (Tag:8456461259513929098)
Nous discutons de la programmation parallèle sous Python dans cette vidéo. Nous utilisons la librairie "dask". L'objectif est d'exploiter au mieux les capacités multicœurs du processeur de ma machine de test. Les exemples montrent que la parallélisation des tâches ne devient décisive que lorsque nous traitons un certain volume de données. En deçà, les gains issus de la parallélisation ne compensent pas le temps consommé par les opérations supplémentaires que nécessitent la préparation des données et l'organisation des structures de calculs.
Mots-clés : python, dask
Vidéo : Parallel programming with Dask
Programme : Min et Mean sous Python
Références :
"Dask: a flexible library for parallel computing in Python".
"Programmation MapReduce sous R", juillet 2015.
"Programmation parallèle sous R", juin 2013.
(Vidéo) Cost-sensitive learning
2021-04-30 (Tag:6914226178815562128)
Dans cette vidéo, il est question de la prise en compte des coûts de mauvais classement en analyse prédictive. Les erreurs de prédiction ne sont pas toutes équivalentes. Classer en bonne santé une personne malade n'induit pas les mêmes conséquences que l'inverse par exemple. Cette information additionnelle est portée par une matrice dite de "coûts de mauvais classement". Elle traduit en valeurs numériques les répercussions des erreurs. Notre rôle consiste à utiliser à bon escient cette matrice pour guider la modélisation, mais aussi pour évaluer et comparer les performances des classifieurs.
Mots-clés : logiciel R, package rpart, MASS, lda, matrice de coûts de mauvais classement
Vidéo : Cost-sensitive learning
Données, slides, notebook : Breast cancer
Références :
Documentation MLR, "Cost-Sensitive Classification".
"Pratique de la régression logistique", version 2.0, septembre 2009.
"Coûts de mauvais classement en apprentissage supervisé", janvier 2009.
Econométrie par Régis Bourbonnais
2021-04-14 (Tag:6696099206471873245)
Cette fiche de lecture concerne la 10ème édition de l'ouvrage "Économétrie" de Régis Bourbonnais, une véritable institution qui a marqué et continue à marquer plusieurs générations de férus de régression et de traitement des séries temporelles. Le livre s'adresse aux étudiants de niveau licence et master en filière économétrie. En réalité, il est susceptible d'intéresser tous les étudiants des composantes à fort contenu mathématique et statistique (MIASHS, BUT STID, etc.).
En son temps, la 2nde édition du même ouvrage, celle de 1998, m'avait inspiré lorsque j'ai eu à élaborer mon cours d'économétrie pour notre licence il y a une quinzaine d'années (corrélation, régression simple et multiple, aspects pratiques de la régression).
Fiche de lecture : "Econométrie" - 10ème édition - Dunod - 2018
Site web de l'auteur : https://regisbourbonnais.dauphine.fr/
(Vidéo) Model Explainability par H2O
2021-04-09 (Tag:6698803776089870978)
Dans cette vidéo, je reprends l'idée de l'interprétation des modèles exposée précédemment (voir "Outils pour l'interprétation des modèles", avril 2021). Nous explorons les fonctionnalités de la librairie "H2O" cette fois-ci. Elle propose les instruments usuels dans un cadre simplifié (importance des variables, partial dependence plot, shapley values). Je mets surtout un focus particulier sur le graphique "individual conditional expectation plot (ICE)" qui permet de caractériser l'effet marginal d'une variable explicative sur la variable cible lors du classement d'un individu supplémentaire. En d'autres termes, il enrichit la lecture d'une prédiction en mettant en exergue l'évolution de la conclusion (la probabilité d'appartenance à la modalité cible) en fonction de la variation de la variable explicative.
Mots-clés : python, h2o, partial dependence plot, shapley additive explanations, individual conditional expectation
Vidéo : Model Explainability
Données et Notebook Python : Pima H2O Interpretation
Références :
Documentation H2O, "Model Explainability", version 3.32.1.1.
"Machine Learning avec H2O (Python)", Janvier 2019.
"(Vidéo) Outils pour l'interprétation des modèles", avril 2021.
(Vidéo) Outils pour l'interprétation des modèles
2021-04-08 (Tag:7704040457515250344)
Dans cette vidéo, nous explorons les outils d'interprétation agnostiques des classifieurs c.-à-d. applicables à tous types de modèles, y compris et en particulier aux modèles "boîtes noires" pour lesquels il est difficile d'identifier de prime abord la pertinence des variables explicatives et la nature de leurs liaisons avec l'attribut cible. Pour comprendre le fonctionnement et la teneur des résultats qu'ils fournissent, nous les appliquons dans un premier temps sur un classifieur linéaire (régression logistique) dont nous savons interpréter les coefficients estimés. L'idée est de vérifier la cohérence entre la lecture usuelle des paramètres du modèle (valeur et signe des coefficients) et les résultats proposés par les outils étudiés ([PFI] permutation feature importance et [PDP] graphique de dépendance partielle). Rassurés par leur comportement, nous les utilisons dans un deuxième temps sur un gradient boosting machine. Ils permettent de décrypter les caractéristiques du classifieur, notamment sa capacité à mettre en évidence des relations non-linéaires, impossibles à identifier avec la régression logistique.
Dans la seconde partie du tutoriel, nous étudions le concept de SHAP. Il permet de décortiquer le processus d'affectation des classes pour un individu à classer c.-à-d. à comprendre les caractéristiques (les valeurs prises par les variables pour l'individu à classer) qui ont conduit le modèle à produire l'estimation de la probabilité d'appartenance aux classes. Appliqué à un ensemble d'observations, l'outil SHAP rejoint les informations fournies par les outils d'interprétation des modèles évalués précédemment (PFI et PDF).
Mots-clés : python, scikit-learn, partial dependence plot, pdp, permutation feature importance, shap package, shapley additive explanations, interpretation
Vidéo : Interpretable machine learning
Données et Notebook Python : Pima ML Interpretation
Références :
Documentation Scikit-Learn, "Inspection", Chapitre 4, version 0.24.1.
C. Molnar, "Interpretable Machine Learning – A Guide for Making Black Box Models Explainable", version 08/04/2021.
"Importance des variables dans les modèles", février 2019.
"Graphique de dépendance partielle – R et Python", avril 2019.
"Interpréter un classement en analyse prédictive", avril 2019.
"Python – Machine Learning avec scikit-learn", septembre 2015.
(Vidéo) Python – AutoML de Scikit-Learn
2021-04-02 (Tag:5734244252776003750)
Nous explorons la solution AutoML basée sur la librairie "scikit-learn" dans cette vidéo. Le package "auto-sklearn" explore l'espace des solutions en croisant les algorithmes d'apprentissage automatique, les hyperparamètres associés, et les techniques de préparation des données. Il s'appuie sur un mécanisme de recherche sophistiqué plutôt qu'un simple brute force. Particularité très intéressante, il utilise également l'expérience acquise durant le traitement d'autres bases benchmark. Un rapprochement à partir des méta-informations extraites des jeux de données permet de situer le problème en cours de traitement.
Nous reprenons dans ce tutoriel le même schéma d'évaluation mis en place durant l'étude de la solution AutoML de la librairie H2O.
Mots-clés : python, automl, scikit-learn, auto-sklearn
Vidéo : Auto-Sklearn
Données : Spam auto-sklearn
Références :
Auto-sklearn – Efficient and Robust Automated Machine Learning (2015, 2020).
"Python – Machine Learning avec scikit-learn", septembre 2015.
(Vidéo) Python – AutoML de H2O
2021-03-28 (Tag:2264375618595827085)
Il est question de la fonction AutoML de la librairie H2O dans cette vidéo. Pour un temps de calcul défini à l'avance, elle se charge d'expérimenter des scénarios de modélisation prédictive en testant différents algorithmes, et en jouant sur les valeurs de leurs paramètres. Au-delà de l'identification de la configuration la plus performante, elle propose également une solution additionnelle composée par la combinaison de tous les modèles essayés ou des meilleurs modèles pour chaque famille d'algorithmes (linéaires, deep learning, gradient boosting machine, random forest, etc.). Le principal intérêt d'AutoML est de nous fournir une approche clé en main qui permet de se donner une idée sur les performances atteignables sur un jeu de données quelconque, avec un temps d'exécution maîtrisé. Charge à nous par la suite de développer une solution circonstanciée en rapport avec les données étudiées et de nous comparer à la référence que représenterait AutoML.
Mots-clés : python, h2o, automl, scikit-learn
Vidéo : AutoML
Données : Spam H2O
Références :
H2O AutoML – Automatic Machine Learning
"Machine learning avec H2O (Python)", janvier 2019.
"Python – Machine Learning avec scikit-learn", septembre 2015.
(Vidéo) Python - Le package Yellowbrick
2021-03-21 (Tag:8779037367130532570)
Il est question de la librairie "Yellowbrick" dans cette vidéo. Elle propose des outils pour visualiser graphiquement les process ou les résultats des algorithmes de machine learning. Elle est adossée à "scikit-learn", incontournable dans la pratique de la data science sous Python. Nous explorons tour à tour les fonctionnalités graphiques de Yellowbrick dans le cadre de l'analyse prédictive : l'étude de la redondance et de la pertinence des variables prédictives, leur importance dans la modélisation, la sélection de variables par l'élimination récursive (RFE, recursive feature elimination), les représentations des performances des modèles (matrice de confusion, rapport de performance, courbe ROC), la modulation du seuil d'affectation, le choix des valeurs des paramètres des algorithmes de machine learning, l'identification de la taille nécessaire des données (en nombre d'observations) pour modéliser les "pattern" qu'elles recèlent.
Mots-clés : python, yellowbrick, scikit-learn
Vidéo : Yellowbrick
Données et Notebook Python : Spam Yellowbrick
Références :
Yellowbrick : Machine Learning Visualization
"Python – Machine Learning avec scikit-learn", septembre 2015.
(Vidéo) Stratégies pour classes déséquilibrées
2021-03-08 (Tag:4363532520833914504)
Dans cette vidéo, j'aborde le problème des classes déséquilibrées en classement binaire. J'ai essayé de mettre en évidence plusieurs résultats importants.
Modéliser à partir d'un échantillon d'apprentissage fortement déséquilibré n'est pas vain. C'est ce que nous montrent la courbe ROC et le critère AUC calculés sur un échantillon test représentatif. Le mécanisme d'affectation est en revanche défectueux. C'est ce que nous dit la matrice de confusion et les indicateurs associées (taux de reconnaissance, rappel, précision, F-Score).
La solution populaire qui consiste à rééquilibrer artificiellement les données d'apprentissage par sous ou sur échantillonnage revient en réalité à recalibrer les probabilités d'affectation fournies par le modèle. Elle ne modifie pas les propriétés intrinsèques de ce dernier. Elle pèse en revanche sur le mécanisme d'affectation des classes.
Une solution alternative préconisée dans ce tutoriel serait de manipuler directement le seuil d'affectation dans le classement binaire. Je montre une procédure d'optimisation basée sur l'échantillon d'apprentissage pour obtenir de meilleures performances en classement, mesurée à l'aide du F1-Score sur l'échantillon test. Cette stratégie permet de dépasser le problème délicat de la détermination de la proportion des classes des approches basées sur l'échantillonnage.
Mots-clés : logiciel R, régression logistique, glm, courbe roc, auc, F1-Score, F-Measure
Vidéo : Classes déséquilibrées
Données et programme R : Imbalanced dataset
Références :
"Imbalanced Classification Problems", mlr documentation.
"F-Score", Wikipédia.
"Traitement des classes déséquilibrées", mai 2010.
"Coûts de mauvais classement en apprentissage supervisé", janvier 2009.
(Vidéo) Google Colab
2021-03-06 (Tag:1985192317038621516)
Dans cette vidéo, je présente Google Colab (Google Colaboratory). Il s'agit d'un outil que met à notre disposition Google pour développer des applications de machine learning (ipynb). Google Colab permet d'écrire et exécuter du code Python dans un navigateur, à la manière de Jupyter Notebook, sauf que nous travaillons directement dans le cloud. Il présente plusieurs avantages : il nous affranchit d'une installation locale ; les librairies de machine learning le plus populaires sont déjà installées et constamment mises à jour ; nous avons la possibilité d'installer facilement les packages spécifiques (!pip install …) ; nous bénéficions de la puissance de calcul de Google, avec des accès aux GPU et TPU, les gains en temps de traitement sont parfois faramineux par rapport au fonctionnement sur des machines locales aussi puissantes soient-elles ; nous disposons d'un espace de stockage pour nos données et nos projets ; nous avons la garantie de toujours disposer du même environnement de travail quelle que soit la machine que nous utilisons pour nous connecter ; enfin, une adresse Gmail suffit pour disposer de l'outil.
Je profite de cette présentation pour décrire la construction de la courbe ROC (receiving operating characteristics) dans un problème de classement binaire. J'explique pourquoi ce dispositif d'évaluation des classifieurs est plus générique que la matrice de confusion et ses indicateurs associés. Je parle aussi du critère AUC (area under curve) qui lui est associé. Nous utilisons les données "mushroom", où l'objectif est de déterminer la comestibilité des champignons à partir de leurs caractéristiques, pour illustrer notre propos.
Mots-clés : google colab, courbe roc, roc curve, auc, aire sous la courbe, régression logistique, scikit-learn
Vidéo : Google Colab
Données et programme : Mushroom
Références :
"Courbe ROC", Support de cours.
"Evaluation des classifieurs – Quelques courbes", octobre 2009.
"TD de Régression Logistique – TD 4.b", mars 2020.
"Courbe ROC pur la comparaison de classifieurs", mars 2008.
(Vidéo) Extraction des règles d'association
2021-02-26 (Tag:7774385566449535875)
Dans cette vidéo, je montre comment extraire les règles d'association à partir d'un jeu de données en utilisant le module ARS inclus dans la distribution SIPINA. La mise en œuvre de l'outil est relativement simple. L'enjeu est la profusion de règles. Pour mieux les manipuler, je propose de les reprendre dans Excel afin de bénéficier des fonctionnalités de filtrage, de recherche et de tri du tableur.
Mots-clés : ars, association rule software, sipina
Vidéo : Règles d'association
Données : Habitudes alimentaires
Références :
"Associations dans la distribution SIPINA", avril 2013.
"Extraction des règles d'association - Cours", juin 2015.
"Règles d'association – Comparaison de logiciels", novembre 2008.
(Vidéo) AMADO-online
2021-02-17 (Tag:8522477950171042130)
"AMADO-online est une application pour représenter et analyse les matrices de données selon les principes de Jacques Bertin". L'outil propose des fonctionnalités interactives pour mieux présenter les données, les réorganiser, pour rendre plus lisible les informations qu'elles véhiculent. Il permet également de structurer les tableaux par le calcul en s'appuyant sur les techniques d'analyse factorielle ou de classification automatique. L'application est directement accessible en ligne via un navigateur web. Importer ses propres données peut être réalisé via un simple copier-coller.
Mots-clés : amado, acp, afc, cah
Vidéo : AMADO-online
Données : Médias-professions, véhicules
Site de AMADO-online : https://paris-timemachine.huma-num.fr/amado/
(Vidéo) One hot encoding
2021-02-14 (Tag:6536424772407293706)
Dans cette vidéo, je montre comment procéder au recodage des variables explicatives catégorielles dans la régression logistique. Elles sont transformées en variables indicatrices 0/1. Deux problèmes se posent alors : durant l'apprentissage, comment procéder pour éviter le problème de la colinéarité (la somme des indicatrices de la variable qualitative originelle est égale à une constante) ; durant le test ou le déploiement, comment gérer le cas des modalités supplémentaires (les catégories présentes dans l'échantillon test mais pas dans le train set) ou absentes (l'inverse).
Mots-clés : python, pandas, get_dummies, régression logistique, dummy variable
Vidéo : One hot encoding
Données et programme : Heart avec Python
Références :
"Prédicteurs catégoriels en Régression Logistique", avril 2015.
"Codage disjonctif complet", mars 2008.
"(Vidéo) Recodage des explicatives qualitatives en ADL", novembre 2020.
(Vidéo) Subdivision apprentissage-test avec R
2021-02-09 (Tag:2545658297891289406)
Dans cette vidéo, je montre comment subdiviser aléatoirement un dataset en échantillons d'apprentissage et de test. Le dispositif repose sur la génération aléatoire d'un index sans aucun rapport avec le problème à traiter. Il sert à désigner les observations appartenant à l'apprentissage. L'échantillon test est obtenu par opposition à cet index, en exploitant le mécanisme des indices négatifs sous R. Les données sont ensuite utilisées dans un processus de modélisation par arbres de décision à l'aide du package "rpart".
Mots-clés : logiciel R, train set, training set, learning set, test set
Vidéo : Subdivision train-test avec R
Données et programme : Partition apprentissage-test
Références :
"Apprentissage-test avec Orange, Tanagra et Weka", avril 2008.
"(Vidéo) Subdivision train-test pour les comparaisons", novembre 2020.
(Vidéo) Sélection forward en ADL
2021-01-25 (Tag:2342437521142706018)
Dans cette vidéo, je détaille une implémentation possible de la sélection pas-à-pas "forward" de sélection de variables en analyse discriminante linéaire. Le mécanisme repose sur l'ajout graduel des variables les plus contributives. Dans la méthode proposée, les matrices de variance covariances intra-classes et totales sont calculées une fois pour toutes sur la totalité des variables au démarrage des calculs, puis nous y piochons au fur et à mesure les sous-matrices adéquates pour évaluer la pertinence des variables, sans qu'il ne soit nécessaire de revenir sur les données initiales. Cette approche assure la rapidité des calculs sur les grandes bases de données en nombre d'observations avec un nombre de variables candidates relativement modéré (de l'ordre de plusieurs centaines). Elle devient problématique lorsque le nombre de variables est très élevé (de l'ordre de plusieurs milliers, situation courante en text mining par exemple) du fait de l'occupation mémoire des matrices initiales de covariances. Une implémentation sous R montre la viabilité de la solution.
Mots-clés : analyse discriminante prédictive, stepdisc, forward, sélection de variables
Vidéo : Stepdisc Forward
Données et programme : Forward Selection dataset
Références :
"Pratique de l'analyse discriminante linéaire", mai 2020.
"Stepdisc – Analyse discriminante", mars 2008.
(Vidéo) Classification sur données pré-classées
2021-01-24 (Tag:6268089232865374488)
Dans cette vidéo, je montre la mise en œuvre d'un algorithme de classification automatique, la CAH – Classification Ascendante Hiérarchique, sur des données où préexiste un premier niveau de regroupement. On peut voir l'approche comme une variante de la CAH Mixte où l'on empile deux algorithmes de clustering (voir les références ci-dessous), mais à la différence que le premier niveau n'est pas obtenu par le calcul mais est endémique est données. Il est caractérisé par une variable catégorielle qui fait partie intégrante de la base.
Mots-clés : cah, classification automatique, clustering
Vidéo : CAH on preclassified data
Données et programme : Segmentation dataset
Références :
"Classification ascendante hiérarchique – Diapos", juillet 2016.
"Traitement de gros volumes – CAH Mixte", octobre 2008.
(Vidéo) Arbres sur très grandes bases avec R
2021-01-21 (Tag:342126636261044296)
Dans cette vidéo, je montre l'induction des arbres de décision sur une grande base de données sous R (494 021 obs., 200 variables). Elle cumule les caractéristiques qui mettent à mal l'algorithme "rpart" (du package "rpart") qui fait pourtant référence en la matière : la variable cible comporte 23 classes, certaines des variables explicatives sont catégorielles avec de nombreuses modalités (jusqu'à 66 pour l'une d'entre elles). Nous nous tournons alors vers l'algorithme J48, ersatz de la méthode C4.5 de Quinlan (1993), de la librairie "RWeka" basé sur le logiciel "Weka". Nous constatons que ses performances sont tout à fait satisfaisantes dans notre contexte. Conclusion : il est tout à fait possible de construire des arbres de décision à partir de très grandes bases sous R, il nous appartient de choisir judicieusement l'algorithme (le package) à utiliser en fonction des caractéristiques des données.
Mots-clés : logiciel R, decision trees, rweka, j48
Vidéo : J48 (RWeka) sous R
Données et programme : Arbres Large Dataset
Références :
"(Vidéo) Arbres de décision avec R", janvier 2021.
"Arbres de décision sur les grandes bases", janvier 2012.
"Traitement de gros volumes – Comparaison de logiciels", septembre 2008.
(Vidéo) Arbres de décision avec R
2021-01-20 (Tag:516103297052935328)
Dans cette vidéo, je montre l'induction des arbres de décision avec R via les fonctions "rpart" du package éponyme et "J48" de "Rweka". La première est basée sur l'approche CART de Breiman et al. (1984), la seconde sur l'algorithme C4.5 de Quinlan (1993).
L'objectif est de montrer qu'il existe une alternative à "rpart" pour la construction des arbres, avec des caractéristiques dont nous pourrons tirer avantage lors du traitement des très grandes bases de données. Ce thème fera l'objet d'une seconde vidéo.
Mots-clés : logiciel R, decision trees, rpart, rweka, j48, rpart.plot, partykit
Vidéo : Rpart (rpart) + J48 (RWeka) sous R
Données et programme : Arbres Iris
Références :
"Introduction aux arbres de décision", décembre 2014.
"Arbres de décision", Revue Modulad, Numéro 33, 2005.
"Introduction à R – Arbre de décision", mars 2012.
"Arbres de décision avec Scikit-Learn – Python", février 2020.
(Vidéo) La méthode des K-Means sous R et Python
2021-01-14 (Tag:1795733347765284676)
Dans ces deux vidéos, je montre succinctement la mise en œuvre de la méthode des K-Means sous R et sous Python (package scikit-learn). Faire le parallèle entre les deux outils est très intéressant pédagogiquement. L'accent est mis sur : la préparation des données ; la lecture des résultats ; une piste possible pour identifier le "bon" nombre de classes, problème récurrent de la classification automatique. Sous R, le projet est élaboré sous la forme d'un Notebook sous RStudio. L'output sous forme de page HTML est disponible en temps (quasi) réel, nous donnant une visibilité directe sur la teneur de nos traitements et des sorties y afférentes. Sous Python, j'utilise un Notebook Jupyter. Les résultats sont directement exportables en PDF.
Mots-clés : logiciel R, python, scikit-learn, k-means, méthode des centres mobiles, clustering
Vidéo 1 : K-Means sous R
Vidéo 2 : K-Means sous Python
Données et programme : Avec R , avec Python
Références :
"Classification automatique sous R – CAH et K-Means", octobre 2015.
"Classification automatique sous Python", mars 2016.
"Clustering : méthode des centres mobiles", octobre 2016.
"Clustering : caractérisation des classes", septembre 2016.
(Vidéo) Déploiement de Pipeline Python
2021-01-04 (Tag:2660856384720597666)
Dans cette vidéo, je reprends l'idée de la sauvegarde de modèles prédictifs en vue du déploiement. Sauf que nous nous plaçons dans une situation autrement plus complexe dans la mesure où le "modèle" intègre non seulement le classifieur mais aussi une série d'étapes intermédiaires relatives à la préparation et la sélection des variables explicatives. Je m'appuie sur le concept de "Pipeline" de la librairie "scikit-learn" pour Python. Il cumule les avantages dans notre contexte : il permet de définir un enchaînement de traitements ; il se prête à l'optimisation des hyperparamètres sélectivement sur certaines étapes via des techniques de rééchantillonnage ; la structure peut être sauvegardée d'un bloc dans un fichier en vue du déploiement, nous déchargeant des tâches de coordination.
Mots-clés : python, scikit-learn, sklearn, pipeline, perceptron, validation croisée
Vidéo : Pipeline Scikit-Learn
Données et programme : Segmentation dataset
Références :
"Exportation des modèles prédictifs", novembre 2020.
"Pipeline sous Python – La méthode DISQUAL", juin 2018.
Bonne Année 2021 - Bilan 2020
2021-01-02 (Tag:3407485661555569856)
L'année 2020 s'achève, 2021 commence. Je vous souhaite à tous une belle et heureuse année 2021.
2020 aura été très particulière : d'une part avec le double confinement que nous avons vécu, d'autre part avec le passage en distanciel des établissements d'enseignement supérieur en France (plus marqué encore à l'automne 2020, alors que nous sommes au cœur du premier semestre). Ça n'a pas été facile, c'est peu de le dire.
Il y a quand même des points positifs.
J'ai pu profiter de l'état de stase prolongée du printemps pour rédiger deux ouvrages qui me tenaient à cœur depuis un moment déjà, le premier sur l'analyse discriminante (Pratique de l'Analyse Discriminante Linéaire, mai 2020), le second sur l'analyse factorielle (Pratique des Méthodes Factorielles avec Python, juillet 2020).
Inquiet pour mes étudiants en distanciel, je me suis résolu à réaliser des tutoriels vidéo pour mieux les accompagner. Nécessité est mère de l'invention, dit-on, pour moi c'était vraiment une première. Je me rends compte surtout avec la nouvelle chaîne YouTube mise en en ligne fin octobre 2020 qu'il y a là matière à réflexion sur ma pratique pédagogique. Même lorsque nous reviendrons en présentiel une fois cette crise passée, le plus tôt possible j'espère, l'idée de communiquer par vidéo interposée avec les étudiants me paraît intéressante pour certains aspects de mes enseignements. Je pourrais ainsi prendre plus le temps de mettre l'accent sur d'autres thèmes lorsque nous sommes ensemble en salle de cours. J'avoue que tout cela reste un peu confus encore dans ma tête, Je ne mesure pas totalement la portée de cette nouvelle perspective. Mais cette période est peut-être une occasion unique de faire évoluer mon mode fonctionnement avec les étudiants dans les années à venir. A voir…
En cette nouvelle année, je souhaite le meilleur à tous les passionnés de Data Science, de Statistique et d'Informatique.
Ricco.
Diaporama : Tanagra – Bilan 2020
(Vidéo) Régression logistique multinomiale avec keras
2020-12-24 (Tag:2758698594223475778)
Dans cette vidéo, nous généralisons la régression logistique avec keras sous R au traitement des problèmes multi-classes c.-à-d. la prédiction d'une variable cible catégorielle comportant plus de 2 modalités. L'opération nécessite une préparation des données où nous exprimons la variable cible à l'aide d'une matrice d'indicatrices 0/1 via un recodage "one-hot-encoding" (un codage disjonctif tout simplement).
Mots-clés : logiciel R, keras, tensorflow, régression logistique,
Vidéo : Régression logistique multinomiale
Données et programme : iris dataset
Références :
"Deep Learning : perceptrons simples et multicouches", novembre 2018.
"(Vidéo) Régression logistique sous R avec keras", décembre 2020.
(Vidéo) Régression logistique sous R avec Keras
2020-12-23 (Tag:7919297147194060584)
Dans cette vidéo, je montre l'instanciation de la régression logistique sous R avec la librairie "keras". Cette dernière est connue pour proposer essentiellement des algorithmes de deep learning. Il est néanmoins facile d'observer qu'il y a une relation directe entre la régression logistique et le perceptron simple, un des réseaux de neurones les plus simples.
Pour l'exemple traité, nous constatons que la "régression logistique" de keras se comporte très favorablement par rapport à la fonction glm(.) (du package "stats") qui fait pourtant référence sous R.
Mots-clés : logiciel R, keras, tensorflow, régression logistique, glm
Vidéo : LogisticRegression Keras R
Données et programme : MIT Face Image
Références :
"Deep Learning : perceptrons simples et multicouches", novembre 2018.
"Deep Learning – Tensorflow et Keras sous R", avril 2018.
"Packages R pour le Deep Learning", décembre 2018.
(Vidéo) La régression logistique de scikit-learn
2020-12-21 (Tag:2080004724402447916)
Dans cette vidéo sont explorés les paramètres de la régression logistique implémentée dans la librairie "scikit-learn" pour Python, en particulier : "multi_class" pour le mode d'appréhension des problèmes multi-classes (variable cible à plus de 2 modalités) ; "solver" qui correspond à l'algorithme d'optimisation de la vraisemblance sous-jacente à l'estimation des coefficients de la régression. Nous constaterons qu'ils influent directement sur la qualité de la modélisation et la vitesse de convergence.
Mots-clés : python, scikit-learn, régression logistique binaire et multinomiale
Vidéo : LogisticRegression Scikit-Learn
Données et programme : Covertype data
Références :
"Régression Logistique", page de cours.
"Régression Logistique sous Python", mars 2020.
Titre : (Vidéo) Sélection rapide de variables
2020-12-17 (Tag:2441898170118415229)
Il est question de la sélection rapide de variables en analyse prédictive dans cette vidéo. Nous nous penchons en particulier sur les méthodes de ranking permettant de filtrer en amont les descripteurs avant la mise en œuvre des algorithmes de machine learning. Elles présentent l'avantage d'être très rapides sur des grandes bases de données, tant en nombre de variables que de variables prédictives candidates.
Ces techniques ne prennent en compte que la pertinence des descripteurs cependant c.-à-d. au sens de leur liaison statistique avec la variable cible, sans égard pour d'éventuelles redondances entre eux. Elles introduisent également un présupposé fort – très audacieux même – reposant sur l'idée que les descripteurs ainsi mis en évidence seront efficaces quel que soit l'algorithme d'apprentissage utilisé pour modéliser le concept les associant à la variable cible. Malgré tout, elles constituent une alternative très intéressantes aux autres méthodes de sélection. Elles permettent de défricher rapidement les grandes bases de données en réduisant drastiquement la dimensionnalité avec un effort de calcul minime.
Nous utilisons le module "feature_selection" de la libraire "scikit-learn" pour Python dans ce tutoriel. Le jeu de données correspond au fameux "waveform", bien connu en machine learning, auquel nous avons adjoint des descripteurs a priori non-pertinents que la méthode devrait pouvoir évacuer relativement facilement.
Mots-clés : python, scikit-learn, filter, ranking, feature selection, filtrage, analyse discriminante
Vidéo : Fast Feature Selection
Données et programme : Waveform data
Références :
"Filtrage des prédicteurs".
"Filtrage des prédicteurs discrets", juin 2010.
(Vidéo) Classifieurs linéaires
2020-12-13 (Tag:7489412885512491090)
Dans cette vidéo, je reprend un ancien tutoriel dans lequel j'évaluais le comportement des différents algorithmes d'apprentissage de classifieurs linéaires sur des données artificielles. L'idée est de montrer qu'à système de représentation égal, les modèles s'expriment sous la forme de combinaisons linéaires des variables initiales, nous pouvons obtenir des résultats différents, et par conséquent des performances différentes, parce que les approches se distinguent par le mode d'estimation des coefficients.
Plutôt que R (dans la précédente expérimentation), nous utilisons Python et la fameuse librairie "scikit-learn" dans cette vidéo. Nous comparons l'analyse discriminante, la régression logistique et les SVM (support vector machine) à noyau linéaire. Pour ce dernier cas, nous observons que le paramétrage adopté pèse également sur la teneur des résultats, au-delà du choix de l'algorithme.
Les représentations graphiques dans le plan des frontières de séparation des classes induites par les algorithmes permettent d'illustrer leur comportement sur notre jeu de données.
Mots-clés : python, scikit-learn, analyse discriminante, régression logistique, svm
Vidéo : Classifieurs linéaires
Données et programme : Artificial data
Références :
"Classifieurs linéaires", mai 2013.
(Vidéo) Induction de règles prédictives
2020-12-11 (Tag:2729076208483902013)
Dans cette vidéo, je parle des approches alternatives aux arbres de décision pour construire des modèles prédictifs à base de règles. Je fais en particulier un focus sur les algorithmes "separate-and-conquer" aboutissant à des systèmes de règles sous forme de liste de décisions ou de système de règles non-imbriquées. Les autres approches (bottom-up, algorithmes génétiques, règles floues) sont rapidement évoquées.
Je reprends alors un ancien tutoriel pour montrer la mise en oeuvre de ces algorithmes : (1) sous le logiciel R avec la procédure JRip du package "RWeka" ; (2) sous Tanagra avec les composants "Decision List" et "Rule Induction".
Mots-clés : induction de règles, liste de décision, logiciel R
Vidéo : Induction de règles prédictives
Données et programme : Life Insurance
Références :
"Règles de décision prédictives – Diapos", décembre 2014.
"Induction de règles prédictives", novembre 2009.
"Listes de décision (vs. arbres de décision)", avril 2005.
(Vidéo) Description des modèles avec PMML
2020-12-07 (Tag:3886143618958111075)
Dans cette vidéo, je montre comment utiliser le format PMML pour déployer dans Knime un arbre de décision élaboré dans SIPINA. L'idée est de mettre en avant l'interopérabilité des outils à travers la norme description PMML (Predictive Model Markup Language) des modèles, format standardisé dérivé du XML. Ainsi, il est possible de faire coopérer les logiciels de machine learning et décupler les possibilités de traitements en associant les qualités des uns et des autres.
Une version rédigée de ce tutoriel (cf. références) montre que les possibilités d'interaction peuvent s'étende aux outils ETL (Extract, Transform, Load) tels que Pentaho Data Integration, introduisant de plain-pied les modèles issus d'algorithmes de machine learning au sein des systèmes d'information.
Mots-clés : déploiement, pmml, predictive model markup language
Vidéo : Le format PMML pour le déploiement
Données et programme : Heart - PMML
Références :
"Le format PMML pour le déploiement de modèles", septembre 2010.
(Vidéo) Manipulation des DataFrames "pandas"
2020-12-05 (Tag:2683502523034990894)
Dans cette vidéo, je montre comment manipuler la structure DataFrame de la librairie "pandas" pour Python. Nous explorons plusieurs étapes : l'importation d'un ensemble de données (fichier Excel ici, mais facilement transposable à d'autres types de fichiers comme les CSV), l'inspection de la structure, l'affichage des valeurs. Différents types d'accès sont détaillés : la projection sur quelques colonnes, les restrictions à partir de conditions, les accès indicés. Je montre également la réalisation de calculs statistiques simples (calcul de fréquences) sur les variables. Enfin, nous effectuons la jonction avec les structures de "numpy" pour effectuer facilement, rapidement, des calculs matriciels.
Une version détaillée et rédigée de la manipulation des DataFrames pandas est disponible sur ce site (voir les références).
Mots-clés : python, pandas, numpy
Vidéo : La librairie pandas pour Python
Données et programme : Iris - Pandas
Références :
"Python : Manipulation des données avec Pandas", février 2017.
(Vidéo) Analyse discriminante sous Python
2020-12-04 (Tag:6383538739197361128)
Analyse discriminante linéaire sous Python avec le package "scikit-learn". Utilisation de la classe de calcul LinearDiscriminantAnalysis. Modélisation, entraînement du modèle sur les données d'apprentissage ; prédiction sur un échantillon non-étiqueté. Lecture des résultats, en particulier des coefficients des fonctions de classement. Références vers des tutoriels plus détaillés (lambda de Wilks, F de Rao, évaluation de la pertinence des variables) ou complémentaires (autres logiciels).
Mots-clés : analyse discriminante prédictive, python, scikit-learn
Vidéo : ADL sous Python
Données et programme : Kirsch – Mirabelle – Poire sous Python
Références :
"Pratique de l'Analyse Discriminante Linéaire", mai 2020.
"Analyse discriminante linéaire sous Python", avril 2020.
"Python - Machine Learning avec scikit-learn", septembre 2015.
(Vidéo) Analyse discriminante sous SAS
2020-12-03 (Tag:6053091999657167811)
Analyse discriminante linéaire sous SAS. Modélisation (entraînement du modèle sur les données d'apprentissage) avec la PROC DISCRIM. Sélection de variables avec la PROC STEPDISC, les méthodes pas-à-pas et en particulier l'approche "forward". Détail du mode opératoire et lecture des résultats.
Mots-clés : analyse discriminante prédictive, logiciel SAS, proc discrim, proc stepdisc
Vidéo : ADL avec SAS
Données et programme : Kirsch – Mirabelle – Poire sous SAS
Références :
"Pratique de l'Analyse Discriminante Linéaire", mai 2020.
"SAS OnDemand for Academics".
(Vidéo) ADL sous R avec "discriminR"
2020-12-02 (Tag:4116912367130335835)
Analyse discriminante linéaire sous R avec le package "discriminR". Modélisation (entraînement du modèle sur les données d'apprentissage), prédiction, sélection de variables avec les méthodes pas-à-pas, en particulier l'approche "forward". Lecture des résultats, focus sur les fonctions de classement directement fournies par la librairie, comparaison avec le mode opératoire et les sorties du package "klaR" pour la sélection.
Mots-clés : analyse discriminante prédictive, logiciel R, package discriminR, package klaR
Vidéo : ADL avec discriminR
Sortie des traitements : Sortie Markdown
Données et programme : Kirsch – Mirabelle - Poire
Références :
"Pratique de l'Analyse Discriminante Linéaire", mai 2020.
"Analyse discriminante linéaire sous R", avril 2020.
(Vidéo) Recodage des explicatives qualitatives en ADL
2020-11-29 (Tag:8283088892783551210)
Cette vidéo montre une solution possible pour l'intégration de variables explicatives qualitatives dans un modèle d'analyse discriminante linéaire. Elle passage par l'utilisation des "dummy variables" c.-à-d. des indicatrices 0/1. Deux questions importantes apparaissent alors : combien d'indicatrices créer pour recoder convenablement une variable catégorielle à K modalités ; et comment lire les résultats par la suite.
Mots-clés : analyse discriminante prédictive, dummy variables, indicatrices, codage disjonctif
Didacticiel vidéo : Recodage dummy variables en ADL
Classeur Excel : heart disease
Références :
"Pratique de l'Analyse Discriminante Linéaire", mai 2020, chapitre 3.
(Vidéo) Exportation des modèles prédictifs
2020-11-28 (Tag:611184425637061512)
Dans cette vidéo, je vais plus loin dans le déploiement de modèles prédictifs en abordant 2 points clés du processus : le stockage du modèle élaboré sur les données d'apprentissage dans un fichier de manière à pouvoir l'exploiter par la suite sans avoir à le réentraîner ; l'élaboration d'une application de déploiement qui prend en entrée le modèle sauvegardé et les données à traiter, dans le but d'automatiser le processus de prédiction.
Après avoir détaillé la démarche, je détaille les deux programmes pour R (glm), Python (Scikit-Learn, LogisticRegression) et Knime (Logistic Regression Learner) : (1) celui qui permet d'entraîner le modèle sur les données d'apprentissage et de le sauvegarder ; (2) celui qui prend en entrée le fichier représentant le modèle et les données de déploiement, effectue la prédiction, et exporte cette dernière dans un fichier Excel (un CSV aurait pu faire l'affaire aussi).
Les codes sources et les données utilisées sont bien sûr disponibles.
Mots-clés : modélisation, exportation des modèles, déploiement, logiciel r, glm, python, scikit-learn, knime
Didacticiel vidéo : Exportation de modèles et déploiement
Slides de présentation : Modélisation - Déploiement
Données et programmes : Codes R et Python, Archive Knime
Références :
"Introduction à R – Régression Logistique", mars 2012.
"Python – Machine Learning avec scikit-learn", septembre 2015.
"Analyse prédictive avec Knime", février 2016.
(Vidéo) Conversion d'un Notebook Python avec Pandoc
2020-11-22 (Tag:1458574147236313547)
Dans cette vidéo, je montre comment générer un fichier Word (docx) à partir d'un projet Jupyter Notebook (ipynb). On peut y voir plusieurs avantages pour le post-traitement du document : disposer d'un correcteur orthographique et grammatical plus performant, bénéficier des fonctionnalités d'édition plus avenants des traitements de texte, etc.
Je m'appuie sur un projet très succinct de construction d'un arbre de décision sur le jeu de données ultra-connu des Iris de Fisher. Nous remarquerons que les commentaires, le code, les sorties y compris graphiques du notebook sont parfaitement intégrés dans le fichier Word.
Mots-clés : pandoc, jupyter notebook, scikit-learn, arbre de décisionDidacticiel vidéo : Pandoc pour fichiers ipynb
Données et programme : Notebook et output
Références :
Pandoc - A universal document converter.
(Vidéo) Modélisation, évaluation, déploiement
2020-11-19 (Tag:2018567543501915940)
Dans cette vidéo, je parle d'une des modalités d'évaluation pratique que j'utilise dans mon cours d'introduction à la data science, dans la partie concernant l'analyse prédictive tout du moins.
L'idée est simple : les étudiants doivent produire une modèle prédictif pour le classement, en mesurer les performances, puis le déployer sur une base non-étiquetée c.-à-d. sans la variable cible.
Ils doivent rendre plusieurs éléments dont les projections réalisées sur cette dernière base. Parmi les critères d'évaluation du travail des étudiants figure en bonne place la confrontation entre les classes prédites et les classes observées que j'avais en réalité conservé à part pour la correction. Deux aspects m'importent alors : la performance prédictive pure (la capacité à faire le moins d'erreurs possibles), qui me permet de comparer les projets ; la concordance entre les erreurs annoncées et celles que je mesure moi-même après coup.
Mots-clés : analyse prédictive, arbre de décision, knime, déploiementDidacticiel vidéo : Modélisation, évaluation, déploiement
Support : Schéma CRISP-DM
Données et programme : Spam et archive Knime
Références :
R. Rakotomalala, "Support de cours Data Science".
(Vidéo) Subdivision train-test pour les comparaisons
2020-11-15 (Tag:7500964103652622879)
La période de confinement est un véritable challenge pour l'enseignement. Autant je suis à l'aise en cours avec les étudiants en présentiel dans la salle informatique durant les travaux dirigés sur machine ; autant j'ai du mal à me situer en distanciel, sans véritable retours, sans repères sur l'avancement des uns et des autres.
Pour mieux accompagner les étudiants, j'ai décidé de créer une chaîne vidéo sur YouTube pour qu'ils puissent avoir sous la main (sous les yeux) les explications ou démonstrations que j'effectue au début de chacune de mes séances.
En effet, je me permets d'aller vite en présentiel (je suis incapable de faire autrement de toute manière) parce que je suis avec eux par la suite. Je passe mon temps à roder derrière les étudiants, traquant les bugs, expliquer ce que je constate mal compris, refaire avec eux les étapes des traitements, ou tout simplement discuter de tel ou tel aspect de la data science. Ces échanges sont on ne peut plus enrichissants, à la fois pour les étudiants et pour les enseignants.
Rien de tout cela en distanciel, et surtout reproduire les démos à plusieurs reprises n'est pas envisageable, même si l'idée de discussion privée existe avec les outils d'échange à distance que nous utilisons.
Finalement, cette idée de vidéos n'est pas si mauvaise. Je m'étais toujours refusé à le faire jusqu'à présent. D'une part parce que montrer ma bobine sur le web ne m'intéresse pas spécialement ; d'autre part parce que je crois en la force de l'écrit où nous disposons de l'opportunité de prendre le temps d'expliquer les choses, parfois même de faire des digressions, choses moins évidente dans une vidéo où l'on doit être le plus schématique possible sous peine de perdre le spectateur. Mais bon, nécessité fait loi. Au moins pour les démonstrations, cette idée des tutoriels-vidéos me paraît viable.
Dans cette vidéo, je montre comment subdiviser un ensemble de données en échantillons d'apprentissage et de test, et comment s'organiser pour que la même partition soit exploitée pour comparer différents algorithmes de machine learning implémentés dans différents logiciels de data science. Nous utilisons : Knime, Tanagra, Sipina, Python / Scikit-Learn, R / Rpart. Le matériel pédagogique (données, programmes) associé aux traitements est disponible ci-dessous.
Allez savoir. Peut-être sommes-nous à un tournant de notre pratique de l'enseignement dans les universités….
Mots-clés : analyse discriminante, régression logistique, arbre de décision, python, logiciel r, scikit-learn, rpart, tanagra, sipina, knimeDidacticiel vidéo : Comparaisons des algorithmes
Support : Schéma train-test en analyse prédictive
Données et programmes : Spam, archives et code R/Python
Références :
"Analyse prédictive avec Knime", février 2016.
"Apprentissage-test avec Orange, Tanagra et Weka", avril 2008.
"Apprentissage-test avec Sipina", mars 2008.
"Python - Machine Learning avec Scikit-Learn", septembre 2015.
"Introduction à R – Arbre de décision", mars 2012.
Réduction de dimension - La méthode GLRM
2020-10-31 (Tag:914546469399812906)
La réduction de dimensionnalité est une tâche essentielle de l'analyse exploratoire. L'objectif est de concentrer la représentation des données sur un faible nombre de facteurs, exprimés à l'aide des variables initiales, qui traduisent les "formes" (pattern) pertinentes qui les régissent. En résumant l'essentiel de l'information sur un jeu de caractères réduits : nous pouvons représenter graphiquement les observations quand leur nombre est faible (souvent dans le plan) pour mieux apprécier les proximités ; les algorithmes de machine learning subséquents (supervisé ou non) sont plus efficaces lorsqu'ils sont appliqués sur un espace de représentation plus consistant.
Mon attention a été attirée récemment par l'algorithme GLRM (generalized low rank model). Plusieurs qualités sont mises en avant pour justifier son utilisation : à l'instar de l'AFDM, elle sait traiter nativement les descripteurs mixtes ; en s'affranchissant de la définition des facteurs sous la forme de combinaisons linéaires des variables initiales, elle dépasse les limitations de l'ACP notamment et est capable de capturer des formes non-linéaires. Une solution performante qui nous sortirait donc du sempiternel cadre de la décomposition en valeurs singulières d'une variante de la matrice des données initiales. L'idée est d'autant plus séduisante que l'appréhension des problèmes à très forte dimensionalité est devenu un standard dans le contexte du traitement des données non-structurées, en particulier le text mining.
Dans ce tutoriel, nous décrivons succinctement la méthode, puis nous étudions son comportement en l'opposant à l'ACP lorsque les descripteurs sont tous quantitatifs, à l'AFDM lorsqu'ils sont mixtes. Nous utilisons les jeux de données décrits dans l'ouvrage consacré à l'analyse factorielle qui a été mise en ligne récemment (Rakotomalala, 2020). Nous exploitons l'implémentation disponible dans la librairie H2O que nous avons explorée déjà à plusieurs reprises (Tutoriels Tanagra – H2O).
Mots-clés : réduction de dimensionnalité, analyse factorielle, acp, analyse en composantes principales, afdm, analyse factorielle des données mixtesDidacticiel : La méthode GLRM
Code R et données : Autos et Tennis
Références :
H2O Tutorials, "Generalized Low Rank Models".
Pratique des Méthodes Factorielles avec Python
2020-07-19 (Tag:4762320916683265099)
Ca faisait un moment que j'avais envie de le faire mais des multiples contraintes m'en avaient toujours empêché. Enfin j'ai pu travailler activement à la rédaction livre d'un consacré à l'analyse factorielle. J'ai fait la synthèse dans un ensemble que j'espère cohérent ce que j'ai pu écrire sur les méthodes factorielles ces quinze dernières années. Le plan est relativement classique. Nous présentons tour à tour les différentes techniques qui font référence dans le domaine (ACP, MDS, AFC, ACM, AFDM).Par rapport à la très abondante littérature qui existe (tant en ouvrages qu'en supports accessibles en ligne), fidèle à mon habitude, j'ai essayé de me démarquer en évitant déjà d'abreuver le lecteur de succession de formules matricielles arides, en simplifiant la présentation des techniques (ce n'est pas le plus facile), en retraçant dans le détail les aspects calculatoires à l'aide d'exemples illustratifs, en utilisant le langage Python et ses librairies scientifiques standards (numpy, scipy, scikit-learn).
Nous utilisons en particulier la librairie "fanalysis" d'Olivier Garcia (ancien du Master SISE, promotion 2000), accessible sur GitHub, qui fait référence aujourd'hui pour l'analyse factorielle avec Python. Elle est en adéquation avec les pratiques décrites dans les ouvrages phares de l'analyse de données (cf. la bibliographie). Quelques requêtes Google semblent montrer (juin 2020) qu'il y a peu d'outils et de documentation sur ce créneau, qui correspond pourtant à une véritable attente si j'en juge aux accès sur mon site des tutoriels où les documents relatifs aux méthodes factorielles d'une part, à la pratique de la data science sous Python d'autre part, font partie de ceux qui sont le plus téléchargés. A chaque étape, nous calibrerons les résultats en les comparant à ceux de SAS (proc princomp, proc factor, proc corresp), R (factominer, ade4, ca, pcamixdata, psych) et TANAGRA (avec les composants de l'onglet "Factorial Analysis").
Bien sûr, les programmes (notebooks Jupyter) et les données accompagnent la diffusion de l'ouvrage.
Mots-clés : analyse factorielle, méthodes factorielles, analyse en composantes principales, ACP, positionnement multidimensionnel, mds, multidimensional scaling, analyse factorielle des correspondances, AFC, analyse des correspondances multiples, ACM, AFCM, analyse factorielle des données mixtes, python, jupyter notebook
Ouvrage : Pratique de l'analyse factorielle
Notebooks Jupyter : Notebooks Analyse Factorielle
Données exemples : Data Méthodes Factorielles
Site de référence : Cours Analyse Factorielle
Pratique de l'Analyse Discriminante Linéaire
2020-05-10 (Tag:1335297904669898906)
Bon, les circonstances font qu'il m'a été possible de consacrer suffisamment de temps à l'écriture d'un livre. J'ai choisi de travailler sur l'analyse discriminante linéaire, une méthode prédictive que je trouve très intéressante, tant par sa mécanique interne que par l'usage que l'on peut en faire.Curieusement, alors qu'elle est souvent abordée dans les ouvrages de statistique exploratoire (data science dirait-on aujourd'hui), je ne connais pas de référence qui lui est entièrement consacrée en français. Je la trouve pourtant très riche. Il y a vraiment beaucoup de choses à dire sur son compte. J'ai décidé de m'y coller en choisissant délibérément l'axe prédictif, et en essayant de mettre en avant les différents aspects qui en font le sel. Ceux justement que j'essaie de souligner dans les séances que je lui consacre dans mes enseignements. En effet, sa présentation se résume très rapidement à un empilement de formules matricielles si l'on n'y prend garde. Il fallait absolument éviter cet écueil en se focalisant sur sa pratique, en étant toujours autant que possible concret et pragmatique.
Un package pour R, discriminR, réalisé par un groupe d'étudiants du Master SISE (promotion 2017-2018), Tom Alran, Benoît Courbon et Samuel Rasser-Chinta, accompagne cet ouvrage. Il permet de mettre facilement en application les principales idées qui ont mises en avant, avec des sorties aux standards de SAS Proc Discrim et Proc Stepdisc. Un tutoriel décrit son mode opératoire et la lecture des résultats dans le chapitre consacré aux logiciels. Merci à eux d'avoir bien voulu nous faire profiter de leur travail.
Ça fait plus de 20 ans que j'enseigne l'analyse discriminante prédictive, je ne m'en lasse pas, je lui trouve toujours de beaux atours et j'adore en parler.
Mots-clés : analyse discriminante linéaire, ADL, linear discriminant analysis, LDA, fonctions de classement, évaluation, sélection de variables, stepdisc, variables explicatives qualitatives, disqual, bayésien naïf, régularisation, analyse factorielle discriminante, analyse des correspondances discriminante, proc discrim, proc stepdisc, logiciel R, package discriminR, scikit-learn, python
Ouvrage : Analyse discriminante linéaire
Package R : discriminR 0.1.0
Données exemples : Data ADL
Références :
Page de cours, "Analyse discriminante".
Dépendances des variables qualitatives - Version 2.1
2020-04-14 (Tag:7605550378121595590)
Voilà un item de ma TODO LIST qui vient de resurgir de nulle part. Après 9 ans, j'ai mis à jour mon livre intitulé "Etude de dépendances – Variables qualitatives". Les deux premières versions dataient de 2007 (version 1.0 puis 2.0). Le document a été recompilé en 2011 semble-t-il, mais sans que je n'aie conservé une trace du pourquoi. Il était resté en stand-by depuis.La période étant propice à l'introspection, j'ai essayé de faire le tour de mes supports en suspens. Et je me suis rendu compte que j'avais noté une série de modifications à faire sur ce document. Je l'ai donc mis à jour en corrigeant déjà les coquilles qui pouvaient l'émailler ici ou là, en modifiant les options de compilation pour qu'une table de matière apparaisse dans les lecteurs de PDF, en rajoutant des références ou en retirant les liens URL devenus obsolètes, et en rajoutant quelques sections qui me paraissaient intéressantes.
Le fichier Excel des exemples illustratifs a été complété en conséquence.
Mots-clés : tableau de contingence, khi-2, mesures PRE (proportional reduction in error), odds et odds-ratio, coefficient de concordance, mesures d'association, associations ordinales
Techniques décrites : statistique du khi-2, test d'indépendance du khi-2, contributions au khi-2, t de Tschuprow, v de Cramer, lambda de Goodman et Kruskal, tau de Goodman et Kruskal, U de Theil, coefficient phi, correction de continuité, Q de Yule, kappa de Cohen, kappa de Fleiss, gamma de Goodman et Kruskal, tau-b de Kendall, tau-c de Kendall, d de Sommers, test de Mc Nemar, coefficient d'incertitude symétrique
Ouvrage : Etude des dépendances - Variables qualitatives - Tableau de contingence et mesures d'association
Exemples illustratifs : Credit.xlsx
Analyse Discriminante Linéaire sous R
2020-04-09 (Tag:49288561274060351)
En rédigeant mon précédent tutoriel consacré à l'analyse discriminante sous Python, je me suis rendu compte que je n'avais jamais écrit d'équivalent pour R, où l'on passerait en revue les fonctionnalités de la fonction lda() du package MASS qui fait référence sous cet environnement. C'est étonnant, surtout que je la pratique depuis un bon moment déjà. C'est même une des premières méthodes de R que j'ai explorées avec glm() et rpart(). Nous allons essayer d'y remédier dans ce document.Nous reprenons la trame de la présentation pour Python, en prenant appui toujours sur notre support de cours dédié, mais en l'adaptant bien sûr aux spécificités de lda(). Notre référence reste SAS, avec les procédures proc discrim et proc candisc. Un des enjeux fort sera de faire le lien entre les parties descriptives et prédictives en dérivant les fonctions de classement à partir des fonctions canoniques discriminantes.
Tutoriel Tanagra, "Analyse discriminante linéaire sous Python", avril 2020.
Analyse Discriminante Linéaire sous Python
2020-04-06 (Tag:9031696600998765270)
L'analyse discriminante linéaire est une méthode prédictive où le modèle s'exprime sous la forme d'un système d'équations linéaires des variables explicatives. Je l'affectionne particulièrement. Le temps que je lui consacre dans mes enseignements fait partie de mes séances favorites notamment parce qu'elle se prête à des multiples lectures. Je tiendrai très facilement des heures avec un nombre pourtant réduit de slides.Dans ce tutoriel, nous étudierons le comportement de la classe de calcul LinearDiscriminantAnalysis du package "scikit-learn" pour Python. En faisant le tour de ses propriétés et méthodes, nous passerons en revue les différents aspects de la technique. Pour mieux situer la teneur des résultats, nous mettrons en parallèle les sorties de la procédure PROC DISCRIM du logiciel SAS qui fait figure de référence dans le domaine.
Régression Logistique sous Python
2020-03-31 (Tag:3930917178413501818)
Ce tutoriel fait suite à la série d'exercices corrigés de régression logistique sous R (TD 1 à TD 8). Il aurait pu constituer la 9ème séance des travaux dirigés où l'on ferait travailler les étudiants sous Python. J'aime bien alterner les logiciels dans ma pratique de l'enseignement. J'ai quand-même préféré le format tutoriel parce qu'il y a de nombreux commentaires à faire sur le mode opératoire et les résultats des outils que nous utiliserons. Les librairies "statsmodels" et "scikit-learn" adoptent des points de vue très différents sur les mêmes traitements. Il est important de mettre en relation directe les thèmes et les commandes avec le cours rédigé disponible en ligne (voir références).Enfin, ce document peut être vu comme le pendant pour la régression logistique de celui consacré à la régression linéaire disponible sur notre site ("Python - Econométrie avec StatsModels", septembre 2015).
Mots-clés : python, package statsmodels, package scikit-learn, log-vraisemblance, régression logistique, inférence statistique, évaluation du modèle en resubstitution et en test, courbe roc, critère auc
Didacticiel : Régression logistique avec statsmodels et scikit-learn
Données et code source Python : Infidélité
Références :
R. Rakotomalala, "Cours de régression logistique".
Régression Logistique -- TD 8
2020-03-27 (Tag:5303396490299300628)
Huitième et dernier TD de mon cours de régression logistique, nous traitons de la régression logistique multinomiale où la variable cible est qualitative nominale à plus de 2 modalités.Nous explorons deux packages spécialisés, "nnet" et "vgam". Les modes opératoires sont similaires mais il faut faire attention aux spécificités, notamment lors de la prédiction. Ces librairies, de par leur mode de fonctionnement, requièrent la standardisation ou la normalisation des données. L'occasion est belle pour montrer comment réaliser l'opération sur l'échantillon d'apprentissage (facile), puis la transposer sur l'échantillon test (la procédure n'est pas toujours très bien comprise par les étudiants).
Enfin, pour élargir nos perspectives d'analyse, une comparaison avec les résultats d'un arbre de décision – autre méthode qui permet d'appréhender simplement les variables cibles nominales – est réalisée.
Données : waveform
Correction du TD (code R) : waveform – Correction
Correction du TD (Notebook) : Notebook TD 8
Vidéo de correction : Vidéo TD 8
Référence : Site du cours de régression logistique
Régression Logistique -- TD 7
2020-03-26 (Tag:1919461650029722114)
Dans cette septième séance, nous abordons le traitement des données groupées en régression logistique. La ligne du tableau de données correspond à une combinaison des variables explicatives, on parle de pattern ou de profil. Elle représente un ensemble d'observations dont tout ou partie (ou aucun) sont rattachées à la modalité cible de la variable dépendante.Ce prisme permet de mieux souligner l'influence des caractéristiques des individus dans la régression. Avec l'étude des profils, nous pouvons identifier les aspects mal restitués, ceux qui pèsent fortement – voire indûment – dans le modèle. Elle permet également de suggérer des combinaisons des variables qui approfondissent notre analyse.
Données : titanic
Correction du TD (code R) : titanic – Correction
Correction du TD (Notebook) : Notebook TD 7
Vidéo de correction : Vidéo TD 7
Référence : Site du cours de régression logistique
Régression Logistique -- TD 6
2020-03-25 (Tag:6120011292401830437)
Nous approfondissons la sélection de variables durant cette sixième séance. Nous revenons tout d'abord sur les approches classiques pas-à-pas, ascendantes et descendantes. Elles fournissent des sous-ensembles de variables parfois différentes qui sont autant de scénarios de solutions. Nous confrontons les résultats et nous nous en remettons aux performances prédictives pour identifier la plus intéressante.Puis nous explorons les approches alternatives, en particulier les techniques de ranking, qui agissent en amont et indépendamment des méthodes de machine learning pour effectuer la sélection, et l'approche wrapper, qui s'appuie sur des critères de performances estimés explicitement à partir des méthodes de machine learning.
Données : kr-vs-kp
Correction du TD (code R) : kr-vs-kp – Correction
Correction du TD (Notebook) : Notebook TD 6
Vidéo de correction : Vidéo TD 6
Référence : Site du cours de régression logistique
Régression Logistique -- TD 5
2020-03-24 (Tag:8700188331915381292)
Il est question de détection et traitement des non-linéarités dans cette cinquième séance. Nous commençons par un test omnibus, simple à mettre en œuvre mais peu puissant, pour identifier les variables qui agissent non-linéairement sur le LOGIT. Nous enchaînons ensuite avec une procédure graphique, les résidus partiels, pour la même tâche, mais elle présente l'avantage de suggérer la transformation de variables à opérer. Enfin, dans une dernière étape, nous étudions l'intérêt du passage systématique par la discrétisation des variables explicatives en régression logistique, stratégie souvent évoquée pour traiter simplement et automatiquement les non-linéarités.Données (Excel) : Pima diabete - Non-linéarité
Correction du TD (code R) : Non-linéarité – Correction
Correction du TD (Notebook) : Notebook TD 5
Vidéo de correction : Vidéo TD 5
Référence : Site du cours de régression logistique
Régression Logistique -- TD 4.b
2020-03-23 (Tag:2052361325543126258)
Deuxième partie de la quatrième séance, nous nous intéressons à la courbe ROC pour l'évaluation de la régression, dans un schéma de resubstitution (on utilise les mêmes données pour la construction et l‘évaluation du modèle) dans un premier temps pour comprendre les mécanismes sous-jacents à la construction de la courbe et au calcul du critère AUC (aire sous la courbe).Nous passons à un schéma de rééchantillonnage, le leave-one-out, dans un deuxième temps pour obtenir une courbe et une valeur de l'AUC plus représentatives de la qualité réelle du modèle dans la population. L'écart des résultats est substantiel, montrant, si besoin était, l'inanité de l'approche par substitution pour apprécier les performances des classifieurs.
Données (Excel) : Faible poids des bébés - Courbe ROC, AUC
Correction du TD (code R) : Courbe ROC, AUC – Correction
Correction du TD (Notebook) : Notebook TD 4.b
Vidéo de correction : Vidéo TD 4.b
Référence : Site du cours de régression logistique
Régression Logistique -- TD 4.a
2020-03-15 (Tag:5739688319539362947)
Nous enchaînons avec l'évaluation des modèles dans cette quatrième séance.Elle est subdivisée en deux parties. La première, celle-ci, est consacrée aux procédures visant à confronter les probabilités d'affectation aux classes fournies par le modèle avec les proportions observées dans les données disponibles : à l'aide d'une procédé graphique, le diagramme de fiabilité ; et d'un test statistique, le test de Hosmer et Lemeshow. Les calculs sont simples mais il faut bien décomposer les étapes pour ne pas se perdre dans les commandes R. Nous confrontons par la suite nos résultats avec ceux fournis par les packages spécialisés.
Mots-clés : logiciel R, package generalhoslem, package resourceselection, diagramme de fiabilité, reliability diagram, test de hosmer-lemeshow, probabilités d'affectation, scores
Données (Excel) : Faible poids des bébés
Correction du TD (code R) : Faible poids – Correction
Correction du TD (Notebook) : Notebook TD 4.a
Vidéo de correction : Vidéo TD 4.a
Référence : Site du cours de régression logistique
Régression Logistique -- TD 3
2020-03-14 (Tag:83692815650428337)
Cette troisième séance est consacrée aux interprétations sous la forme d'odds-ratio des coefficients de la régression logistique. Nous traitons des différentes configurations de la ou des variables indépendantes : binaires, qualitatives nominales, qualitatives ordinales, quantitatives.Pour vérifier nos calculs, nous mettons en parallèle les résultats avec ceux fournis par un package spécialisé en épidémiologie 'epitools'.
Mots-clés : logiciel R, package xlsx, package epitools, riskratio, chisq.test, oddsratio, glm, risque relatif, odds-ratio, inférence statistique, intervalle de confiance, interprétation des coefficients, recodage des variables indépendantes
Sujet du TD : Risque relatif, odds-ratio
Données (Excel) : Coeur
Correction du TD (code R) : Coeur – Correction
Correction du TD (Notebook) : Notebook TD 3
Vidéo de correction : Vidéo TD 3
Référence : Site du cours de régression logistique
Régression Logistique -- TD 2.b
2020-03-12 (Tag:8690127468918268650)
Seconde partie de la seconde séance, nous étudions toujours l'estimation des coefficients et les tests de significativité associés. Nous analysons cette fois-ci les facteurs de risque des infidélités dans les ménages. Sans surprise, l'usure du temps joue un rôle important. Mais nous verrons que d'autres variables pèsent également. A noter que la variable cible nécessite un recodage avant de pouvoir initier une régression logistique.Mots-clés : logiciel R, package xlsx, glm, tests du rapport de vraisemblance, tests de wald, interprétation des coefficients, recodage de la variable dépendante, colinéarité
Sujet du TD : Estimation, test et interprétations
Données (Excel) : Infidélités
Correction du TD (code R) : Infidélités – Correction
Correction du TD (Notebook) : Notebook TD 2.b
Vidéo de correction : Vidéo TD 2.b
Référence : Site du cours de régression logistique
Régression Logistique -- TD 2.a
2020-03-10 (Tag:6673922805029565369)
Seconde séance des TD (travaux dirigés sur machine) de régression logistique. Il s'agit d'aborder les tests de significativité et les interprétations des coefficients, pour les variables explicatives quantitatives et qualitatives. La question du recodage des variables et l'interprétation des coefficients qui en découle sont étudiés.La séance est en deux parties. Dans cette première partie, nous étudions l'impact des caractéristiques physiologiques et comportementales des personnes sur le ronflement. Les conclusions confortent à peu près ce que l'on sait de ce phénomène bien connu.
Mots-clés : logiciel R, package xlsx, glm, tests du rapport de vraisemblance, tests de wald, interprétation des coefficients, termes d'interaction, recodage des explicatives
Sujet du TD : Estimation, test et interprétations
Données (Excel) : Ronflement
Correction du TD (code R) : Ronflement – Correction
Correction du TD (Notebook) : Notebook TD 2.a
Vidéo de correction : Vidéo TD 2.a
Référence : Site du cours de régression logistique
Régression Logistique -- TD 1
2020-03-09 (Tag:3399307316414176807)
J'ai la fièvre du rangement de temps en temps. Je me mets en tête de mettre de l'ordre dans mes innombrables fichiers de préparations, supports de cours, tutoriels, etc., etc. Et comme il m'arrive parfois d'oublier ce que j'ai moi-même écrit, je tombe sur des sacrées surprises.Ces dernières années, je me tourne de plus en plus vers les cours de machine learning et leurs applications. Mais je n'oublie pas que j'ai en réserve de nombreux cours de statistique, avec notamment un module de régression logistique que j'ai assuré pendant de nombreuses années et dont la préparation m'avait amené à rédiger de nombreux supports comprenant un livre (accessible sur ma page de cours dédiée). Je ne fais plus le cours depuis 2016, mais j'avais gardé bien au chaud toutes mes séances de TD (travaux dirigés sur machine) découpées en tranches d'1h45 où je faisais travailler mes étudiants sur les différentes thématiques de la régression logistique sous le logiciel R.
Vite, vite, avant que je n'oublie tout et que ce travail tombe dans l'oubli, j'ai décidé de mettre un coup de propre sur mes énoncés, et de les diffuser avec les données et les corrigés. Tout le monde peut en profiter comme il l'entend, je ne revendique absolument aucun droit là-dessus.
Première (TD 1) publication d'une longue série (TD 2.a, TD 2.b, TD 3, TD 4a, TD 4.b, TD 5, TD 6, TD 7, TD 8) donc : la création d'un modèle à l'aide de la régression logistique sur un échantillon d'apprentissage, son évaluation statistique, l'évaluation de ses performances prédictives sur un échantillon test, l'identification et la sélection des variables explicatives pertinentes.
Il faut avoir un bon niveau sous R pour pouvoir profiter pleinement des exercices, de cette séance et des suivantes.
Mots-clés : logiciel R, package xlsx, glm, package MASS, stepAIC, critère AIC, akaike, BIC, schwartz, tests de significativité, sélection de variables, estimation des coefficients, modélisation, efficiacité prédictive, échantillon d'apprentissage, échantillon test, matrice de confusion, taux d'erreur
Sujet du TD : Estimation, prédiction, sélection de variables
Données (Excel) : Diabete
Correction du TD (code R) : Diabete - Correction
Correction du TD (Notebook) : Notebook TD 1
Vidéo de correction : Vidéo TD 1
Référence : Site du cours de régression logistique
Détection des anomalies sous Python
2020-03-04 (Tag:1866914272457207413)
Ce tutoriel vient en complément du support de cours consacré à la détection des anomalies ("Détection des anomalies", décembre 2019). Nous nous intéressons à deux aspects du domaine : la détection des observations atypiques ou déviantes dans une base, on parle de "outlier" ; par rapport à un jeu de données de référence non-pollué (qui joue le rôle d'ensemble d'apprentissage), l'identification des nouveautés parmi des individus supplémentaires, au sens où leurs caractéristiques s'en écartent significativement, on parle de "novelty".Nous utiliserons la librairie "Scikit-Learn" (Novelty and Outler Detection) pour mener notre étude, avec en particulier les classes de calcul EllipticEnvelope et LocalOutlierFactor.
Mots-clés : anomalies, points atypiques, points aberrants, nouveautés, outlier, novelty, package scikit-learn
Didacticiel : Détection des outliers et novelties
Code source + données : Cars
Références :
Tutoriel Tanagra, "Détection des anomalies - Diapos", décembre 2019.
Tanagra sous Mac OS X
2020-02-12 (Tag:4197593881658910861)
"On peut faire fonctionner Tanagra sous Mac Monsieur ?" est une question que me posent souvent mes étudiants possesseurs de portables Mac durant les travaux dirigés. Je leur répondais invariablement que ça devait être possible avec une machine virtuelle mais, un peu taquin que je suis, j'ajoutais que le plus simple était plutôt d'utiliser nos machines de la salle informatique qui sont sous Windows. Notre université se saigne aux quatre veines pour offrir du matériel de qualité à ses étudiants, ce serait ballot de ne pas en profiter.Le fait est que je savais la chose possible en théorie, mais je ne l'avais jamais moi-même testé ni vu faire... jusqu'à aujourd'hui. Valentin Amorim, en L3 AES de l'Université Paris 2, m'a transmis le document ci-dessous. Il l'a mis au point sous l'égide d'Antoine Auberger, pour le compte de son cours "Sondages et Techniques quantitatives". Valentin détaille de manière schématique et reproductible les étapes de l'opération : récupérer et installer le logiciel de virtualisation VirtualBox, récupérer et installer l'image de Windows (différentes versions sont possibles), installer enfin Tanagra sur la machine virtuelle. Le tout fonctionne très bien. Il est possible également d'utiliser une machine virtuelle Linux et de passer par Wine comme j'ai pu le tester moi-même par le passé (cf. références).
Un grand Merci Valentin pour ce travail qui profitera à tout le monde !
Mots-clés : macos, mac os x, os x, windows, linux, ubuntu
Didacticiel : Tanagra, installation sur Mac OS X
Références :
Tutoriel Tanagra, "Tanagra sous Linux", janvier 2009.
Tutoriel Tanagra, "Connexion Open Office Calc sous Linux", avril 2009.
Arbres de décision avec Scikit-Learn
2020-02-05 (Tag:2125873889988820609)
Tous les ans, préalablement à chacune de mes séances sur machine avec les étudiants, je fais un travail de mise à jour des instructions et indications de résultats retranscrits dans ma fiche de TD (travaux dirigés). Il faut dire que les packages sous R et Python ne se soucient pas toujours de compatibilités descendantes ou ascendantes. Une instruction valable hier peut ne pas fonctionner aujourd'hui ou, pire, fournir un résultat différent parce que les paramètres par défaut ont été modifiés ou les algorithmes sous-jacents améliorés. La situation est moins critique lorsque des fonctionnalités additionnelles sont proposées. Encore faut-il les connaître. La veille technologique est indissociable de notre activité, et j'y passe vraiment beaucoup de temps.Concernant ma séance consacrée aux arbres de décision sous Python justement, où nous utilisons la libraire Scikit-Learn (Decision Trees), j'avais pour habitude d'annoncer à mes étudiants qu'il n'était pas possible de disposer – simplement – d'une représentation graphique de l'arbre, à l'instar de ce que nous fournirait le package "rpart.plot" pour les arbres "rpart" sous R par exemple. La nécessité d'installer un outil externe (voir "Random Forest et Boosting avec R et Python", novembre 2015 ; section 4.3.3) rendait la manipulation rédhibitoire dans une séance où nous travaillons en temps (très) restreint avec des machines (très) protégées. Je me suis rendu compte récemment au détour d'une requête Google, assez heureuse je dois l'avouer, que la situation a évolué avec la version 0.21.0 de Scikit-Learn (Mai 2019). Nous allons vérifier cela dans ce tutoriel. Nous en profiterons pour étudier les manipulations à réaliser pour pouvoir appliquer les dits-arbres sur des variables prédictives (explicatives) catégorielles. L'outil ne sait pas les appréhender de manière native... pour l'instant (version 0.22.1, février 2020).
Bonne année 2020 - Bilan 2019
2020-01-01 (Tag:4491502479717919021)
L'année 2019 s'achève, 2020 commence. Je vous souhaite à tous une belle et heureuse année 2020.Un petit bilan chiffré concernant l'activité organisée autour du projet Tanagra pour l'année écoulée. 48 documents supplémentaires (supports de cours, tutoriels) ont été postés, tous en français.
L'ensemble des sites (logiciels, support de cours, ouvrages, tutoriels) a été visité 214.816 fois en 2019, soit 588 visites par jour. Les visiteurs viennent en majorité de la France (51%), du Maghreb (17%) et de l'Afrique francophone. Les pages de supports de cours ont toujours autant de succès, en particuliers ceux dédiés à la Data Science et à la programmation (R et Python).
Depuis la mise en place du compteur Google Analytics (01 février 2008), le groupe de sites a été visité 2.746.385 fois, soit 631 visites par jour en presque 12 ans.
En cette nouvelle année, je souhaite le meilleur à tous les passionnés de Data Science, de Statistique et d'Informatique.
Ricco.
Détection des anomalies - Diapos
2019-12-27 (Tag:2901024991763215702)
La détection des anomalies consiste à repérer dans les données les observations qui s'écartent significativement des autres, soit par les valeurs de certaines variables prises individuellement (une personne faisant 2m20), soit par des combinaisons de valeurs incongrues (1m90 pour 50 kg). Ces observations sont par nature rares et éparses, elles peuvent être consécutives à l'intégration par inadvertance d'individus d'autres populations dans un échantillon de données (un basketteur intégré dans un fichier recensant des sumotoris).Les valeurs atypiques faussent souvent les résultats fournis par les algorithmes de machine learning. Leur identification et leur traitement sont des aspects importants de la pratique de la data science. Mais leur détection peut être également une finalité en soi, lorsqu'on pense par exemple qu'elles sont le fruit d'un comportement déviant générant des observations inhabituelles (tentative de fraude d'un opérateur lors d'un accès sur un serveur, etc.).
Dans ce support, je présente la méthode LOF (local outlier factor). Elle cherche à identifier les observations atypiques en comparant les densités locales des points dans un voisinage dont le périmètre (le nombre de voisins) est un paramètre de l'algorithme. Je détaille les calculs et je montre le comportement de l'approche sur un jeu de données en faisant appel à la librairie Rlof pour R. Un tutoriel sous Python suivra.
Mots-clés : anomalies, points atypiques, points aberrants, nouveautés, anomaly detection, outlier detection, novelty detection, local outlier factor, logiciel R, package rlof, reachability distance
Support de cours : Local Outlier Factor
Références :
Breunig, M. M.; Kriegel, H.-P.; Ng, R. T.; Sander, J. (2000). LOF: Identifying Density-based Local Outliers. Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data. SIGMOD. pp. 93–104.
Tutoriel Tanagra, "Détection univariée des points aberrants", mai 2008.
Rakotomalala R., "Pratique de la régression", chapitre 2 "Points aberrants et influents", mai 2015.
Implémentation du Naive Bayes sous R
2019-12-24 (Tag:418273537341878714)
J'ai fait travailler mes étudiants sur la programmation sous R du classifieur bayésien naïf récemment. Schématiquement, la méthode est relativement simple à implémenter, surtout lorsque toutes les variables explicatives sont qualitatives. Il en est de même lorsqu'elles sont toutes quantitatives. Il y a en revanche des choix stratégiques à mettre en place lorsqu'elles sont mixtes. Je pensais que la principale difficulté viendrait de cette partie. Non en réalité. Je me suis rendu compte après coup que le principal écueil était de développer une implémentation performante du déploiement, lorsque nous appliquons le modèle sur des individus supplémentaires. Parce que R possède des caractéristiques qui lui sont propres, les temps d'exécution peuvent varier dans des proportions très importantes selon notre habilité à en tirer profit.Dans ce tutoriel, nous nous penchons sur la programmation des fonctions fit() - construction du modèle sur un jeu de données - et predict() - application du modèle en prédiction sur un jeu de données - du Naive Bayes. La variable cible est forcément qualitative. Nous nous en tiendrons au cas des variables explicatives qualitatives. L'objectif n'est pas de proposer une resucée du naive bayes. Plusieurs packages disponibles sur le CRAN s'en chargent très bien. Il s'agit surtout pour nous d'étudier l'impact des choix d'implémentation sur les temps d'exécution sous R.
Word2Vec avec H2O sous Python
2019-12-08 (Tag:7920553032770397791)
Ce tutoriel fait suite au support de cours consacré au prolongement lexical (word embedding) où nous avions étudié l'algorithme "Word2Vec" dans le cadre de la fouille de textes (text mining ; on parle aussi de NLP, natural language processing). Nous mettons en œuvre la technique sur un jeu de données jouet tiré de l'ouvrage de Coelho et Richert (2015). Le premier objectif est de représenter les termes du corpus dans un espace de dimension réduite en les contextualisant c.-à-d. en tenant compte de leur voisinage. Le second consiste à calculer les coordonnées des documents pour apprécier leurs proximités dans ce nouvel espace de représentation ainsi défini.Nous nous appuyons sur la librairie H2O pour Python. Nous l'avions déjà exploré à plusieurs reprises précédemment (par ex. "Machine Learning avec H2O", janvier 2019). L'enjeu dans notre contexte est de savoir préparer correctement le corpus pour que l'on puisse faire appel aux fonctions dédiées. Cette tâche est quand-même assez particulière sous H20. Nous y porterons toute notre attention – de la manière la plus didactique possible, voire scolaire – pour ne pas perdre le lecteur en route.
Deep learning : l'algorithme Word2Vec
2019-12-07 (Tag:5150226833739146663)
Le prolongement lexical ou word embedding est une technique de text mining qui permet de décrire les termes d'un corpus à l'aide d'un vecteur de valeurs numériques (de taille paramétrable), de manière à ce que les termes qui apparaissent dans des contextes similaires soient proches (au sens d'une distance quelconque, la distance cosinus par exemple).Dans ce support, je présente la méthode word2vec basée sur un algorithme de deep learning (réseau de neurones multicouche). Elle traduit la notion de contexte par le voisinage des mots dont on peut moduler l'amplitude. De la description des termes, nous pouvons dériver une description matricielle des documents, tableau de données à partir de laquelle nous pouvons appliquer les techniques usuelles de machine learning (catégorisation, clustering, etc.).
Mots-clés : word embedding, prolongement de mots, prolongement lexical, word2vec, text mining, réduction de la dimensionnalité, deep learning
Support de cours : Word2Vec – Deep Learning
Références :
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. "Efficient Estimation of Word Representations in Vector Space." In Proc. of Workshop at ICLR. (Sep 2013).
Deep learning avec PyTorch sous Python
2019-12-01 (Tag:3853205690432945921)
Dans ce document, nous nous attelons à l'instanciation, l'apprentissage et l'évaluation de perceptrons simples et multicouches avec PyTorch. Nous travaillons à partir d'un fichier de données que nous devons importer et préparer au préalable. Toutes les étapes seront détaillées. J'insisterai sur la manipulation des "tensor", le format de vecteurs et matrices qu'utilise la librairie pour ses manipulations internes. Je m'attarderai également sur la construction un peu particulière des réseaux qui nécessite une connaissance (très basique, n'exagérons rien) des mécanismes de classes (l'héritage et la surcharge des méthodes) sous Python.Mots-clés : deep learning, perceptron simple et multicouche, réseau de neurones, pytorch, python
Didacticiel : PyTorch for deep learning
Code source + données : Breast PyTorch
Références :
PyTorch, https://pytorch.org/
Tutoriel Tanagra, "Deep learning : perceptrons simples et multicouches", novembre 2018.
Auto-encodeur avec Keras sous Python
2019-11-30 (Tag:1565059002108579932)
Ce tutoriel fait suite au support de cours consacré aux auto-encodeurs (cf. référence ci-dessous). Nous mettons en oeuvre la technique sur un jeu de données jouet (des automobiles pour ne pas changer) à l'aide des librairies tensorflow et keras pour Python.Il y a différentes manières de considérer les auto-encodeurs. Dans notre cas, nous adoptons le point de vue de la description des données dans un espace de dimension réduite. Comme une alternative à l'ACP (analyse en composantes principales) en somme. L'objectif est de cerner au mieux les attentes que l'on pourrait avoir par rapport aux résultats qu'elle fournit dans ce contexte, notamment en matière de qualité de reconstitution des données.
Deep learning : les auto-encodeurs
2019-11-27 (Tag:7859718413770063729)
Un auto-encodeur est un réseau de neurones non-supervisé utilisé pour la réduction de dimension et la data visualisation. Il se présente comme un perceptron multicouches où les neurones des couches d'entrée et de sortie sont identiques, ils sont formés par les descripteurs. Le réseau peut comporter plusieurs couches intermédiaires, la couche centrale, de taille fortement réduite par rapport à la dimensionnalité initiale, constitue le "code" permettant de compresser l'information disponible aussi fidèlement que possible au sens d'un critère à optimiser.Ce support de cours présente les principes sous-jacents à cette technique de deep learning. Le parallèle est fait avec l'ACP (analyse en composantes principales), l'intérêt des auto-encodeurs est de pouvoir proposer différents niveaux d'abstraction et de savoir appréhender les "pattern" non-linéaires.
Mots-clés : deep learning, réseaux de neurones, réduction de la dimensionnalité, visualisation des données, pattern non-linéaire, couches cachées, perceptron, filtrage du bruit
Support de cours : Auto-encodeur
Références :
Wikipedia, "Autoencoder".
Rakotomalala R., "Deep learning : perceptrons simples et multicouches", nov. 2018.
Discrétisation supervisée rapide
2019-11-20 (Tag:3671041851082879031)
Nous nous intéressons à la discrétisation supervisée dans ce tutoriel, plus particulièrement à la méthode descendante MDLP de Fayyad et Irani (1993). Nous évaluons les solutions qu'elle propose sur deux bases de données et nous comparons les temps d'exécution sous R, à travers les packages "discretization" et "RWeka".Une étude rapide de l'algorithme permet de faire le parallèle avec l'induction par arbre de décision. Fort de cette idée, nous proposons un algorithme de discrétisation basée sur rpart(). On peut toujours argumenter sur la qualité des solutions proposées, ce n'est pas notre propos. En revanche, il apparaît clairement que cette nouvelle approche s'avère autrement plus rapide sur les très grandes bases de données.
Mots-clés : discrétisation, apprentissage supervisé, logiciel R, package discretization, package rweka, mdlp, rpart, arbres de décision
Didacticiel : Discrétisation supervisée rapide
Code source + données : Discrétisation rpart
Références :
Tutoriel Tanagra, "La discrétisation des variables quantitatives", octobre 2014.
Tutoriel Tanagra, "Discrétisation – Comparaison de logiciels", février 2010.
JIT compilation sous Python
2019-11-14 (Tag:388981598548349157)
La compilation à la volée (JIT, just-in-time compilation) est un procédé qui permet de compiler dynamiquement, durant l'exécution, tout ou partie d'un code programme. Dans ce tutoriel, nous étudions le package Numba pour Python. Il permet de rendre plus performantes des portions de nos programmes (des fonctions essentiellement) en introduisant simplement des "directives de compilation", sans autres modifications du code. Nous verrons que l'outil est diablement intéressant et permet d'obtenir des gains spectaculaires. Il l'est d'autant plus que nous pouvons profiter de la parallélisation automatique des calculs dans certaines configurations.Mots-clés : just-in-time compilation, JIT, python, package numba, régression linéaire, descente du gradient, package numpy, parallélisation
Didacticiel : JIT sous Python
Code source : Python - Numba
Références :
Numba, "A high Performance Python Compiler", http://numba.pydata.org/
Tutoriel Tanagra, "Programmer efficacement sous Python", avril 2019.
Ateliers Master SISE : logiciel SAS
2019-11-12 (Tag:4388723053918717792)
Comme de tradition (2016, 2017, 2018), nous commençons l’année (universitaire) par des ateliers consacrés aux outils de la data science en Master SISE. Nous nous intéressons au logiciel SAS cette fois-ci. Même si par ailleurs, notre priorité est la maîtrise des outils R et Python, il n’en reste pas moins que SAS représente un acteur important en France, au sein d’une certaine catégorie d’entreprises en tous les cas. Dans notre département (qui commence en L3), une UE (unité d’enseignement) lui est consacrée en Master 1 puis, en Master 2, il est utilisé dans quelques cours de statistique, mais guère plus. Il m’a semblé intéressant de faire travailler les étudiants sur ce thème pour consolider leurs connaissances et préparer au mieux l’année.Les 6 séances ont été réparties en 3 thèmes : Manipulation des Données, Statistique Descriptive, Statistique Inférentielle. Pour chaque séance, nous disposons : d’un support de présentation, d’un sujet de travaux pratiques sur machine, d’un ou plusieurs jeux de données (fichier Excel ou CSV), d’un corrigé sous la forme de fichiers SAS, d’un tutoriel vidéo montrant les différentes étapes de la réalisation des tâches.
Je me répète tous les ans, mais je ne m’en lasse pas, merci aux étudiants du Master SISE pour cet excellent travail qui profitera à tout le monde.
| Thèmes | Présentations | Exercices | Dataset | Corrigés | Tutoriels |
| Manip. Data 1 |  |  |  |  |  |
| Manip. Data 2 | | | | | |
| Stat. Desc. 1 | | | | | |
| Stat. Desc. 2 | | | | | |
| Stat. Inf. 1 | | | | | |
| Stat. Inf. 2 | | | | | |
Python Machine Learning avec Orange
2019-11-11 (Tag:6975358987029925070)
Orange est un logiciel bien connu des passionnés de data mining. On trouve de nombreux tutoriels en ligne, j’en ai écrit moi-même plusieurs. Moins connue en revanche est la possibilité d’utiliser les fonctions de la librairie Orange dans des programmes rédigés en Python. Pourtant, la fonctionnalité est disponible depuis longtemps, bien largement avant la vague Python dans la pratique du machine learning de ces dernières années.Dans ce tutoriel, je montre son mode opératoire dans un problème simple d’apprentissage supervisé. Nous constaterons que le package Orange pour Python est assez simple d’utilisation et, dans ce cadre, se pose comme une alternative tout à fait valable aux libraires très populaires telles que "scikit-learn" ou le tandem "tensorflow / keras".
Machine Learning - Outils pour l'enseignement
2019-10-16 (Tag:4690675362440379384)
Je dois intervenir ce vendredi 18 octobre 2019 au séminaire de la SFDS consacré au "Machine Learning appliqué à l'Agro-Industrie". Je parlerai surtout des outils que je préconise et que j'utilise moi-même pour mes enseignements en lien avec la data science dans nos formations. Au préalable, j'essaie de cerner le phénomène "machine learning". Il constitue un terreau de nouvelles applications qui nécessitent des nouvelles fonctionnalités des outils. Lesquels doivent dépasser les attendus des "simples" logiciels de stats que nous connaissons depuis bien longtemps déjà.Ma démonstration aboutit un peu à une ode à R et Python quand-même. Mais bon, reconstruire les évidences est parfois instructif m'a-t-on dit. Prendre du recul permet de remettre en perspective nos choix et nos décisions. Dans le cas de ces deux logiciels, au-delà des aspects pédagogiques et de leurs aptitudes, leur forte pénétration dans les entreprises et, de ce fait, leur présence explicite dans les offres d'emplois qui ciblent nos étudiants, sont des éléments d'appréciation primordiaux qui n'étaient pas évidents il y a quelques années encore, lorsqu'on parlait de logiciels libres dans le domaine du machine learning et de la data science. De même, l'ouverture vers la programmation qu'offre ces outils se révèle décisive dans la formation de nos étudiants. Nous pouvons ainsi doubler la compétence en traitements avec la capacité à produire du code performant.
Pour illustrer mon propos, je décrirai quelques projets réalisés par mes étudiants dans le cadre académique du Master SISE. Leur savoir-faire allié à l'efficacité opérationnelle de R et Python leur permettent de réaliser des véritables prouesses en temps réduit.
Support de l'intervention : Slides Machine Learning - Outils
Mots-clés : logiciel R, Python, machine learning, formation, master data science, science des données, big data analytics, logiciels libres
Performances des boucles sous R
2019-10-06 (Tag:6771774350182687911)
J'assure mon cours de "Programmation R" en Master à cette époque de l'année. Lorsque j'aborde la question des boucles, je dis traditionnellement que ce n'est pas une bonne idée, le temps d'exécution étant souvent prohibitif. Je conseille aux étudiants de modifier leur code de manière à exploiter les aptitudes des fonctions de la famille des apply. Nous réalisons ensuite une série d'exercices pour voir comment ce type d'adaptation pourrait se mettre en place.J'ai dû relativiser cette affirmation dans la période récente, parce que l'interpréteur R a énormément progressé avec les versions 3.4.0 puis 3.5.0. Depuis la 3.4.0 notamment, les boucles sont maintenant compilées à la volée (just-in-time), améliorant considérablement les temps de traitement sans que l'on ait à modifier en quoique ce soit notre code.
J'avais par le passé étudié les outils et astuces pour programmer efficacement sous R. Dans ce tutoriel, nous nous pencherons plus en détail sur la question des boucles en comparant les performances de la structure for() avec une solution passant par un sapply(). Je prendrai comme prétexte la programmation de l'algorithme de tri par sélection pour illustrer mon propos.
Réseaux de neurones convolutifs sous Knime
2019-08-01 (Tag:2597616075010359867)
Ecrire un tutoriel sur l'utilisation des réseaux de neurones convolutifs (CNN - Convolutional Neural Networks) - un des représentants les plus fameux du deep learning - pour le classement d'images me titillait depuis un moment déjà. Mais il y a tellement de choses à lire et à écrire que je repoussais sans cesse. La lecture récente du dernier ouvrage de Stéphane Tufféry (Tufféry, 2019) et la découverte des composants de deep learning sous KNIME (Keras, Tensorflow) m'ont poussé à me lancer.Il existe de nombreux didacticiels en ligne, notamment sur l'utilisation des CNN en Python sur des bases qui font référence telles que MNIST ou "Cats and Dogs". Stéphane dans son ouvrage effectue les mêmes analyses, mais sous R. Ça ne sert à rien de les réitérer. Mon idée était de me démarquer en proposant une étude simplifiée sur une base moins usitée, en schématisant les étapes autant que possible, et en réalisant l'ensemble des traitements sans écrire une seule ligne de code. Je suis R et Python addict, entendons-nous bien, mais varier les plaisirs ne peut pas faire de mal. KNIME convient parfaitement dans ce cadre.
Deep Learning avec Keras sous Knime
2019-07-28 (Tag:3224712620841138697)
"En dehors de R et Python, point de salut alors pour le deep learning ?" me demande, un brin inquiet, un internaute. J'ai compris quand j'ai voulu le rediriger vers d'autres langages (Java, C++) qu'il était surtout réfractaire à la programmation. Sa vraie question était plutôt de savoir s'il était possible d'exploiter les librairies de deep learning, comme le fameux tandem tensorflow / keras par exemple, sans passer par le codage informatique.La réponse est oui. Dans ce tutoriel, nous verrons comment installer et rendre exploitables ces librairies dans le logiciel Knime, un de mes outils libres favoris pour la data science. Les opérations usuelles de manipulation de données, de modélisation et d'évaluation sont représentées par un "workflow" où les traitements sont symbolisés par des composants (nodes), et l'enchaînement des traitements par les liens entre ces nœuds. On parle alors de "programmation visuelle", moins traumatisante que l'écriture de ligne de code. Pour ce qui est de Knime, plus qu'une simple succession d'opérations, il s'agit bien de programmation puisqu'il est possible de définir des structures algorithmiques telles que les actions conditionnelles, des boucles, et même des fonctions sous forme de meta-nodes regroupant des actions.
Mots-clés : Knime, deep learning, tensorflow, keras, perceptron simple et multicouche, analyse prédictive
Didacticiel : Keras sous Knime
Données et workflow Knime : Keras workflow
Références :
Knime - Keras Integration -- https://www.knime.com/deeplearning/keras
Tutoriel Tanagra, "Deep Learning - Tensorflow et Keras sous R", avril 2018.
Tutoriel Tanagra, "Deep Learning avec Tensorflow et Keras (Python)", avril 2018.
Big Data, Machine Learning...
2019-07-17 (Tag:4861973238176610529)
Cette fiche de lecture est consacrée au dernier ouvrage de Stéphane Tufféry, "Big Data, Machine Learning et Apprentissage profond", Technip, 2019.Mots clés : machine learning, big data, apprentissage profond, deep learning, programmation R, logiciel R, packages spécialisés, image mining, reconnaissance d'images, text mining, analyse des réseaux sociaux, traitement des gros volumes de données, data science
Fiche de lecture : Big Data, Machine Learning et Apprentissage Profond
Économétrie - Classe inversée
2019-06-25 (Tag:6211159319376943229)
Lorsque j'avais commencé mon cours d'économétrie ("théorie et pratique de la régression linéaire simple et multiple" serait plus approprié) il y a une quinzaine d'années, je disposais de 24h pour les CM (cours magistraux) et 12h pour les TD (travaux dirigés, sur machine en ce qui me concerne). C'était Byzance. Puis, au fil du temps sont arrivées les restrictions, de plus en plus oppressantes, au point que ces dernières années on m'accordait (on accordait aux étudiants) 8.75h CM et 10.5h TD. Je me suis toujours battu pour préserver les exercices sur machine, primordiales à mon sens, parce que les étudiants sont dans l'action, parce que je peux être au plus près d'eux pour échanger et parler des aspects opérationnels que l'on ne traite jamais dans les manuels d'économétrie. Il m'a bien fallu lâcher du lest d'un autre côté. C'est tombé sur les CM. Aussi peu d'heures (5 séances d'1h45) pour traiter de la corrélation, la régression simple, la régression multiple et l'appréhension des problèmes pratiques (expertise des résidus, colinéarité, sélection de variables, identification des points atypiques ; des thèmes de niveau L3, ni plus ni moins), on en rigolerait si ce n'était pas au détriment des étudiants.Pour le coup, je me suis dit qu'il fallait absolument trouver une autre manière de réaliser mon cours d'économétrie, sinon on allait droit dans le mur. Ça tombe sous le sens finalement. Quel intérêt aujourd'hui de faire des CM lénifiants où les étudiants grattent avec un profond ennui, alors qu'ils ont à disposition de très nombreux supports sur le web, y compris d'excellents (pour certains) cours filmés réalisés par d'éminents collègues, en français (faites une recherche avec les mots-clés "régression linéaire" sur YouTube, juste pour voir), en anglais, dans d'autres langues. Je me suis dit que c'était là une occasion d'appliquer les principes de la pédagogie inversée (ou classe inversée), séduisante en théorie, mais dont la mise en œuvre n'est pas toujours évidente parce que nous devons forcément composer avec des contraintes de tout ordre, y compris matérielles. Pour ma part, j'avais une soixantaine d'étudiants, dans des salles où il est impossible de modifier la configuration du mobilier pour les organiser en groupes (notre service du patrimoine a certainement beaucoup de qualités, mais l'humour n'en fait pas partie).
Après réflexion, j'ai opté pour la version suivante de la classe inversée. Les étudiants sont organisés en groupes. Une semaine avant la séance, je leur transmets une liste de supports à lire, accompagnée d'une série d'exercices à réaliser. Le jour dit, je fais un rappel de cours très succinct (une quinzaine de minutes) en mettant l'accent sur les points importants. Puis, les étudiants, au titre de leur groupe, passent au tableau pour la correction des exercices sur la base du volontariat. Chaque passage avec succès correspond à un bonus sur la note finale de la matière.
Je n'étais pas vraiment convaincu de l'intérêt du rappel de cours, mais les étudiants ont insisté pour que je resitue les thèmes de la séance. Dans l'idéal, l'étudiant qui passe au tableau devrait effectuer une correction commentée. Dans les faits, il a tendance à écrire silencieusement à toute vitesse les équations et les résultats. Souvent les étudiants s'attachent au "comment faire" au détriment du "pourquoi le faire ainsi". Pendant qu'ils écrivent donc, je m'applique à les aider en les poussant à expliquer leur démarche ou en commentant moi-même, afin de positionner la question traitée par rapport au chapitre de cours concerné.
Ça a plutôt bien marché finalement, surtout parce que les étudiants ont adhéré au mode de fonctionnement. C'est heureux parce qu'un enseignement n'a aucun sens si on n'a pas leur assentiment. J'avais aussi la crainte que les séances se transforment en activité de recopie des corrections, mais la plupart ont joué le jeu et se sont beaucoup investis. Il m'a même fallu instaurer des règles de passage au tableau pour que les bonus soient équitablement répartis.
Je mets en ligne aujourd'hui la liste des exercices pour les 4 séances "CM" du cours d'économétrie (je consacrais la séance 5 des "CM" à la correction conjointe d'annales d'examen). L'objectif pédagogique est d'aiguiller les étudiants sur les différents thèmes du programme de L3. J'y joins les corrigés (sous Excel, tout le monde connaît mon attachement aux vertus pédagogiques du tableur pour l'initiation à la statistique) que je diffusais après coup afin que les étudiants disposent d'un repère commun. J'avoue que j'ai un peu du mal à m'y retrouver moi-même après tant d'années. Il se peut que certains exercices aient été glanés sur d'autres sites web ou encore dans des ouvrages de référence, je suis désolé de ne pas pouvoir créditer leurs auteurs faute de pouvoir les retrouver, mais je les remercie quoiqu'il en soit.
| Thème | Sujet | Corrigé |
|---|---|---|
| Séance n°1. Corrélation de Pearson. Estimation, intervalle de confiance, tests, corrélation partielle, corrélation de Spearman. | | |
| Séance n°2. Régression linéaire simple. Estimation des coefficients, intervalle de confiance, tests de significativité, prédiction ponctuelle et par intervalle. | | |
| Séance n°3. Régression linéaire multiple. Estimation des coefficients, intervalle de confiance, tests de significativité, tests généralisés sur les coefficients, prédiction ponctuelle et par intervalle, rupture de structure, test de Chow. | | |
| Séance n°4. Pratique de la régression. Etude des résidus, colinéarité et sélection de variables, points atypiques et influents, traitement des exogènes qualitatives. | | |
Économétrie - Projet Open Data
2019-06-17 (Tag:692830240682040604)
Suite à des circonstances particulières, il m'a fallu improviser une évaluation de mon cours d'économétrie une année. J'avais décidé de faire travailler mes étudiants sur la modélisation à partir des "Open Data". J'avais en-tête un double objectif : (1) les faire travailler sur la pratique de la régression linéaire multiple, qui était un peu le coeur du cours il faut dire ; (2) les amener à s'intéresser aux "Open Data", le potentiel d'études qu'elles (données ouvertes) recèlent, mais aussi la difficulté à les exploiter puisqu'elles ne sont pas explicitement collectées à des fins d'analyse.Les étudiants ont si bien travaillé que j'ai reconduit le dispositif l'année suivante en rajoutant une soutenance pour que les étudiants puissent présenter et de défendre leur travail. Ils ont beaucoup d'imagination pour dégoter des sujets originaux voire épiques qui ont le mérite de titiller ma curiosité.
Je mets en ligne le cahier des charges que je diffusais auprès des étudiants (souvent des personnes me contactent pour avoir des idées de mémoire, je me dis que le thème universel des "open data" peut inspirer). Dans notre timing, suite à ma présentation du format de l'évaluation, ils avaient deux semaines pour me proposer un sujet qui tient la route, que je devais valider, puis deux semaines supplémentaires pour finaliser l'étude et me rendre un rapport. Les soutenances avaient lieu la semaine suivante. Sachant qu'en parallèle, ne l'oublions pas, ils suivent les autres enseignements et subissent d'autres évaluations sous des formes diverses et variées.
Enfin, très important, je proscrivais l'utilisation des bases déjà préparées que l'on retrouve sur les sites dépôts dédiés aux challenges ou à l'étude des algorithmes de machine learning. Elles sont très bien dans le cadre restreint des compétitions et des comparaisons, mais elles ne reflètent en rien la démarche la modélisation dans une étude réelle, contexte où la préparation des données tient une place primordiale et conditionne la qualité des résultats.
Les étudiants peuvent utiliser les outils qu'ils souhaitent. Ils s'appuient sur R ou Python souvent, mais plusieurs ont fait le choix de Gretl. La seule règle imposée était que je puisse reproduire les calculs à l'identique.
Cahier des charges : Projet Open Data - Modélisation
Outils d'optimisation sous R
2019-06-13 (Tag:7110347761140076643)
J'utilise quasiment toujours le tableur Excel pour disséquer les algorithmes de machine learning. Il n'y a rien de mieux je trouve pour décortiquer les formules. On ne peut pas rentrer des commandes au petit bonheur la chance, nous sommes obligés de tout comprendre pour pouvoir tout décomposer. Comme une grande partie des méthodes revient à optimiser une fonction de perte (ou de gain), je m'appuie alors sur le solveur. J'obtiens souvent des résultats satisfaisants, comme par exemple dans mon ouvrage – qui servira de référence – consacré à la “Pratique de la régression logistique” où l'on maximise la log-vraisemblance.Je me suis demandé s'il existait un équivalent du solveur sous R. En cherchant un peu, je me suis rendu compte que oui, il s'agit de la fonction optim() du package “stats”, installé et chargé par défaut sous R. Tout comme son homologue sous Excel, il peut fonctionner avec seulement une fonction objectif et un vecteur de paramètres. Mais il peut aller plus loin, nous pouvons lui fournir d'autres informations pour qu'il soit plus efficace. Il sait produire également des résultats additionnels nécessaires à l'inférence statistique lorsque nous travaillons sur les algorithmes de régression par exemple.
Dans ce tutoriel, nous montrons l'utilisation des fonctions optim() et optimHess() pour la programmation de la régression logistique. Nous comparerons les résultats d'une part avec les sorties de la fonction glm() de R, d'autre part avec les fruits d'une petite implémentation maison de l'algorithme de Newton-Raphson.
Régression ZIP sous R et Python
2019-06-10 (Tag:3766795863149981969)
Ce tutoriel fait suite au support de cours consacré à la Zero-Inflated Poisson Regression, une technique adaptée à la modélisation d'une variable de comptage lorsque la valeur "0" est surreprésentée.Nous travaillerons sous R dans un premier temps. Nous détaillons les différentes manières de modéliser une variable cible représentant un dénombrement. Nous appliquerons tour à tour la régression logistique, la régression de Poisson et la régression ZIP avec le package "pscl" (Political Science Computational Library). Nous analyserons les résultats pour essayer de comprendre l'intérêt des différentes approches. Dans un deuxième temps, nous reprenons dans les grandes lignes la même étude en travaillant sous Python cette fois-ci. Nous ferons appel au package "statsmodels". Nous constaterons – sans surprise – la convergence des résultats avec ceux de R.
Régression ZIP - Diapos
2019-06-06 (Tag:833605898807813422)
En grattant un peu pour rédiger mon précédent support pour la Régression de Poisson, je me suis rendu compte qu’il y avait une abondante littérature dans le domaine. Dans ce document, je m’intéresse à la " Zero-inflated Poisson Regression " c.-à-d. à la construction d’un modèle de comptage dans le cas où la valeur 0 est surreprésentée.Je réutilise l’exemple des infidélités maritales (tout un programme) où l’on essaie d’expliquer (Y) le nombre de tromperies dans les ménages sur une période étudiée. Le schéma de modélisation repose sur l’idée qu’elle (la valeur zéro) est régie par deux phénomènes : (Y = 0) parce que la personne est intrinsèquement fidèle, elle ne risque pas d’aller voir ailleurs ; (Y = 0) parce que la personne n’a pas eu l’occasion ou l’opportunité de folâtrer sur la période étudiée.
Ce support décrit les mécanismes sous-jacents à la Régression ZIP : l’estimation des paramètres, les tests statistiques associés, notamment celui qui permet de cerner la contribution effective du modèle par rapport à la régression de Poisson usuelle.
Régression de Poisson avec R
2019-05-27 (Tag:9216018909888012926)
Ce tutoriel fait suite au support de cours dédié à la Régression de Poisson. Je reprends la trame et les données d'un traitement décrit dans l'ouvrage "Approaching Multivariate Analysis - A Practical Introduction" (2010, chapitre 13). Les auteurs effectuent les traitements sous SPSS. J'ai trouvé intéressant de pouvoir reproduire (ou pas) leurs résultats en effectuant l'analyse sous R avec l'outil glm() du package "stats" de R.Mots-clés : régression de poisson, modèle de comptage, glm, logiciel R, codage disjonctif, codage imbriqué, tests de significativité, résidus déviance, résidus standardisé, levier
Didacticiel : Régression de Poisson avec R
Données et programme : Poisson Regression
Références :
P. Dugard, J. Todman, H. Staines, "Approcahing Multivariate Analysis - A Practical Introduction", Second Edition, Routeledge, 2010.
R. Rakotomalala, "Régression de Poisson - Diapos", Mai 2019.
Régression de Poisson - Diapos
2019-05-24 (Tag:5707551669267615514)
J'essaie de mettre de l'ordre dans mes documents concernant mon cours d'économétrie en ce moment. Je suis tombé sur une très ancienne TODO LIST où j'avais noté une série de choses à faire en relation avec cet enseignement, entres autres la régression de Poisson. J'avais acheté un livre à cet effet (Hilbe, 2011), et il prenait malheureusement la poussière dans ma petite bibliothèque personnelle depuis plusieurs années.Il n'est jamais trop tard pour bien faire. J'ai lu l'ouvrage, excellent au demeurant (à mi-chemin entre le texte didactique et la monographie), et j'ai décidé rédiger un support de cours pour cette technique explicative où la variable réponse représente un comptage. Sont détaillés dans le diaporama : les principes qui sous-tendent la méthode, l'estimation des paramètres par la méthode du maximum de la vraisemblance, les outils nécessaires à sa pratique (tests et intervalles de confiance, sélection de variables, identification des points atypiques et influents).
L'écriture de ce support aura été pour moi l'occasion de continuer à explorer une autre manière de présenter une méthode statistique en faisant la part belle à du code R. Il ne faut pas que la présentation soit dépendante du langage, certainement pas. Mais illustrer par des instructions et des sorties de logiciel peuvent aider à comprendre les concepts. Je l'espère tout du moins.
Un tutoriel détaillant la mise en oeuvre de la régression de Poisson sur un ensemble de données arrive incessamment sous peu.
Mots-clés : régression de poisson, modèle de comptage, estimation du maximum de vraisemblance, déviance, sélection de variable, critères aic / akaike et bic / schwarz, étude des résidus, détection des points atypiques et influents, surdispersion, overdispersion
Support de cours : Poisson Regression
Données pour illustration du cours : Affairs
Références :
J.M. Hilbe, ''Negative Binomial Regression'', Second Edition, Cambridge University Press, 2011.
Économétrie avec gretl
2019-05-15 (Tag:5317788705515972129)
En faisant faire un travail d'analyse économétrique sur les "Open Data" à mes étudiants, où ils étaient libres d'utiliser l'outil de leur choix, j'ai constaté que plusieurs d'entre eux ont opté pour "gretl" (Gnu Regression, Econometrics and Time-series Library). Je connaissais, je l'avais testé vite fait par le passé, mais sans creuser davantage. Ces étudiants avaient parfaitement répondu au cahier des charges de l'étude, là où la majorité de leurs collègues avaient travaillé sous R. Visiblement, "gretl" semble proposer des fonctionnalités assez complètes, qui répondent aux attendus de mon enseignement d'économétrie de Licence en tous les cas. Nous allons examiner cela dans ce tutoriel.Nous prenons comme repère la quatrième séance de TD (travaux dirigés sur machine) de mon cours. L'objectif est d'expliquer la nocivité des cigarettes (teneur en CO – monoxyde de carbone) à partir de leurs caractéristiques (teneur en nicotine, en goudron, poids). Les thèmes abordés sont : l'importation et la description des données, la pratique de la régression linéaire multiple avec l'estimation des paramètres du modèle et l'inspection des résultats. Mettre en parallèle les sorties de "gretl" et la correction du TD (traité sous R) accessible en ligne nous permettra de calibrer notre démarche et vérifier les résultats.
Économétrie - TD 6 - Évaluation
2019-05-12 (Tag:2409078654584225264)
Je passe au contrôle pour la sixième session sur machine (après les TD 1.A, TD 1.B, TD 2, TD 3, TD 4, TD 5) de mon cours d'économétrie. Contrairement aux autres séances, je fournis uniquement les données et les objectifs. Charge aux étudiants (en groupes de 2 souvent) de mettre au point une stratégie pour élaborer le modèle le plus performant.Nous sommes un peu beaucoup dans une vision "machine learning" où seule compte l'efficacité prédictive (un chercheur célèbre disait qu'en machine learning, on recherche avant tout à identifier ce qui marche le mieux, alors qu'en statistique, on chercherait plutôt à expliquer pourquoi ça marche). Au regard de la durée de la séance (1h45) où les étudiants doivent effectuer les traitements, mettre en forme les résultats, et rédiger un compte rendu, il est difficile de se lancer dans des considérations métaphysiques de toute manière.
Les étudiants reçoivent deux ensembles de données dispatchées dans deux feuilles d'un classeur Excel. Le premier est classique (données étiquetées), il comporte la variable endogène à prédire et un certain nombre d'exogènes candidates. Ils doivent l'exploiter pour créer le meilleur modèle possible. Le second contient uniquement les explicatives, les observations étant numérotées (données non-étiquetées). J'ai conservé pour la correction les valeurs de la colonne cible. Les étudiants doivent produire les prédictions ponctuelles et les intervalles de prédiction. Une partie de l'évaluation repose sur la confrontation entre les prédictions des étudiants et les valeurs observées (que j'ai réservées à part). Deux critères m'importent dans l'histoire : (1) l'erreur quadratique moyenne (écarts entre prédiction ponctuelle et valeur observée) ; (2) la qualité des fourchettes de prédiction (leur – faible - amplitude et la proportion des valeurs observées effectivement couvertes par les fourchettes, ces deux caractéristiques étant antinomiques).
Dans le fichier mis en ligne ici, l'objectif est de prédire le prix des véhicules à partir de leurs caractéristiques (encore les voitures Monsieur…). Il y a deux (tout petits) pièges : la distribution de l'endogène est fortement asymétrique, une transformation serait souhaitable ; une des exogènes présente une valeur unique, on devrait s'en apercevoir avec les statistiques descriptives (si on pense à les calculer), il ne sert à rien de l'introduire dans le modèle.
Travailler en temps contraint oblige les étudiants à avoir une bonne maîtrise, d'une part des concepts et méthodes de la régression linéaire multiple, d'autre part des outils (Excel, R ou Python, ils ont le choix), pour espérer pouvoir s'en sortir.
Données : Car prices - Data
Données pour correction : Car prices - Étiquettes
Économétrie - TD 5 - Régression sous Python
2019-05-11 (Tag:8635336782239298338)
Ne dit-on pas que "L'ennui naquit un jour de l'uniformité" ? Pour varier encore une fois les plaisirs, je fais travailler les étudiants sous Python dans ce cinquième TD (après TD 1.A, TD 1.B, TD 2, TD 3, TD 4) de mon cours d'économétrie. L'objectif est de pousser les étudiants à s'abstraire de l'outil, la forme, pour se concentrer sur le fond, la pratique de la régression linéaire multiple. Tout comme pour R, certains connaissent déjà, d'autres non. Pour préparer la séance, je les enjoins à réaliser des exercices de remise à niveau pour Python.Durant le TD, nous revenons sur les principaux thèmes étudiés cette année : la régression linéaire multiple, l'inspection des résidus, la détection de la colinéarité, la sélection de variables, les tests généralisés, la détection et le traitement des points atypiques et influents, la prédiction ponctuelle et par intervalle. Temps imparti : 1h45. Bien s'exercer sous Python en amont est fondamental pour le succès de la séance.
Sujet du TD : Régression multiple - Python
Données : Mortality - Data
Correction du TD : Mortality - Correction
Économétrie - TD 4 - Régression sous R (II)
2019-05-10 (Tag:2083621542038982533)
"Ah bon ? On ne traite pas un fichier de voitures aujourd'hui ?". Les étudiants sont caustiques parfois. Oui, oui, pour ce quatrième TD (après TD 1.A, TD 1.B, TD 2 et TD 3) de mon cours d'économétrie, le propos de la régression est l'explication de la nocivité des cigarettes à partir de leur teneur en divers composants. Nettement moins poétique que les automobiles je trouve. Mais il faut bien varier les plaisirs. Nous travaillons sous le logiciel R pour la seconde fois. Les thèmes méthodologiques abordés sont la régression linéaire multiple, l'analyse des résidus dont les tests de normalité, la détection et le traitement des points atypiques, la sélection de variables, la prédiction sur les individus supplémentaires regroupés dans un fichier à part, l'exportation des résultats.Petite coquetterie, je demande aux étudiants de produire à la fin du TD un rapport (word ou pdf) récapitulant les questions, le code R et leurs éventuels commentaires. Pour ce faire, je les aiguille sur la création de projets Markdown sous Rstudio. J'effectue une petite démonstration en début de séance. On trouve facilement des tutoriels à ce sujet sur le web.
Comme d'habitude, les étudiants ont 1h45 pour réaliser les exercices.
Sujet du TD : Régression multiple - R - Markdown
Données : Cigarettes - Data
Correction du TD : Cigarettes - Correction
Économétrie - TD 3 - Régression sous R (I)
2019-05-09 (Tag:4525940663921323371)
(1) "Qu'importe le flacon pourvu qu'on ait l'ivresse" et (2) "cent fois sur le métier il faut remettre son ouvrage" sont deux adages qui me conviennent parfaitement (surtout le premier, on se demande pourquoi). Dans ce troisième TD de mon cours d'économétrie (après TD 1.A, TD 1.B et TD.2), nous revenons (précepte 2) sur la corrélation et la régression simple, mais avec un autre outil (précepte 1), le logiciel R, tant prisé par les statisticiens. Certains de nos étudiants sont assez familiarisés avec R, d'autres non. Pour que tout le monde soit d'emblée opérationnel, je leur conseille de réaliser préalablement (avant la séance !) des exercices de remise à niveau pour R.Les thèmes abordés durant ce TD sont : la corrélation, intervalle de confiance de la corrélation, la corrélation sur les rangs, la régression simple, l'estimation de la pente et de la constante, les tests de significativités, les graphiques usuels en régression simple, la prédiction ponctuelle et par intervalle.
Temps imparti : 1h45. Les meilleurs y arrivent, pourvu qu'ils aient une bonne connaissance de R en amont.
Sujet du TD : Corrélation et régression simple - R
Données : Autos completed - Data
Correction du TD : Autos completed - Correction
Économétrie - TD 2 - Régression multiple
2019-05-08 (Tag:5282443502724937251)
Deuxième séance de TD (la première est scindée en 1.a et 1.b) pour mon cours d'économétrie. Le thème est la régression multiple, avec la dernière session sous Excel. Nous explorons : l'estimation des coefficients par le calcul matriciel et à l'aide de la fonction droitereg(), la construction du tableau d'analyse de variance, le calcul du coefficient de détermination, le test de significativité globale de la régression, le calcul des critères AIC (Akaike) et BIC (Schwarz), les tests de significativité individuelle des coefficients, la sélection de variables, la prédiction ponctuelle et par intervalle, l'évaluation de l'impact des variables à travers les coefficients standardisés, les tests généralisés sur les coefficients.Le temps imparti est de 1h45. C'est court mais faisable… si on maîtrise les formules du cours et que l'on sait manipuler les fonctions matricielles d'Excel.
Enfin, afin que les étudiants puissent retravailler sereinement dessus après la séance, outre le corrigé, je décris les opérations dans un tutoriel ("Régression linéaire sous Excel", mars 2018) où l'on réalise des tâches similaires sur un autre fichier de données.
Sujet du TD : Régression multiple - Excel
Données : Cars Acceleration (2) - Data
Correction du TD : Cars Acceleration (2) - Correction
Économétrie - TD 1.b - Régression simple
2019-05-07 (Tag:4623921530188152985)
Voici la seconde partie de la première séance des TD d'économétrie, consacrée à la régression simple sous Excel. Les thèmes abordés sont : estimation des paramètres, tableau d'analyse de variance, coefficient de détermination, test de significativité globale de la régression, test de significativité de la pente, graphiques des résidus, prédiction ponctuelle et par intervalle. Temps de travail escompté pour ces exercices : 45 minutes.Sujet du TD : Régression simple - Excel
Données : Cars Acceleration (1) - Data
Correction du TD : Cars Acceleration (1) - Correction
Économétrie - TD 1.a - Corrélation
2019-05-06 (Tag:1440950785621854715)
J'arrête mon cours d'économétrie (Modèle Linéaire -- Niveau Licence 3) cette année. Comme pour mon enseignement d'Excel – Programmation VBA, j'ai décidé de mettre en ligne mes travaux dirigés sur machine (TD) avant qu'ils ne tombent dans l'oubli.Je publie aujourd'hui le premier de la série (qui comprendra TD 1.A, TD 1.B, TD 2, TD 3, TD 4, TD 5 et TD 6). Il est consacré à l'analyse des corrélations, nous utilisons le logiciel Excel. J'ai deux commentaires. (1) Elaborer une fiche de TD est toujours très compliqué. Il faut arbitrer entre deux extrêmes : donner trop peu d'indications avec le risque de subir la fameuse phrase qui fuse du fond de la salle "qu'est-ce qu'il faut faire là ?" ; trop diriger le travail, le commentaire "on recopie le code sans rien comprendre Monsieur" est tout aussi dévastateur. Il faut donc titiller l'esprit des étudiants en leur donnant suffisamment d'indications, mais pas trop. Tout est dans la subtilité. (2) Je sais bien qu'un tableur n'est pas un logiciel d'économétrie. Mais je trouve personnellement que c'est un formidable outil pédagogique pour l'enseignement des statistiques, au moins dans un premier temps. On ne peut pas rentrer des commandes sans comprendre dans Excel. La nécessité de décrypter les formules pour réaliser les calculs aide les étudiants à assimiler les éléments du cours.
Dans cette première séance (première partie de ma première séance en réalité dans ma pratique), nous travaillons sur l'analyse des corrélations disais-je, avec les thèmes suivants : calcul du coefficient de corrélation de Pearson, test de significativité, intervalle de confiance, corrélation partielle, non-linéarité et corrélation des rangs (Spearman). Un étudiant d'un bon niveau devrait réaliser ces exercices en 1h à peu près.
Sujet du TD : Analyse des corrélations - Excel
Données : Autos - Data
Correction du TD : Autos - Correction
Python - Détection de communautés avec MDS
2019-05-04 (Tag:8706412600219873031)
La détection de communautés est une des applications phares de l'analyse des réseaux sociaux. Outre un support de cours, je l'avais déjà abordé dans un ancien tutoriel. Sous Python, l'objectif était de se familiariser d'une part avec les notions essentielles de l'analyse des communautés (voisinage, centralité, individus relais, …), d'autre part de découvrir les fonctionnalités du package "igraph". Nous avions traité le fameux problème du "Club de karaté de Zachary" où les données se présentent sous la forme d'une matrice d'adjacence binaire (absence ou présence de lien entre les sociétaires du club).Nous cherchons à aller plus loin aujourd'hui avec une configuration où les connexions entre les individus sont valorisées par une valeur numérique positive ou nulle. Le tableau de départ de l'étude correspond à une matrice de dissimilarités. Nous verrons que le positionnement multidimensionnel (Muldimensional Scaling en anglais, MDS) constitue une voie intéressante pour répondre à la problématique de la détection de communautés dans ce contexte. En effet, en positionnant les points dans espace euclidien, il permet l'exploitation des algorithmes de machine learning adaptés à ce système de représentation "individus x variables" c.-à-d. la très grande majorité d'entre eux.
Multidimensional scaling sous R
2019-04-28 (Tag:6069282013302507774)
Ce tutoriel vient illustrer mon support de cours consacré au positionnement multidimensionnel (Multidimensional Scaling en anglais, MDS). L'objectif est de représenter dans le plan les positions relatives des villes en prenant en entrée les distances kilométriques des routes qui les relient. C'est une application très parlante et/mais ressassée du MDS (exemple pour les villes de France). J'essaie d'être original ici en traitant les villes de Madagascar.Mon idée initiale était de récupérer les informations directement sous R via les API des services de cartographie en ligne (Google Maps, Bing Maps, OpenStreetMap, etc.). Mais la tâche ne s'est pas avérée aussi triviale que je ne le pensais. J'en parle justement dans ce document où je montre comment accéder aux données dans une application R à l'aide des packages spécialisés, en ce qui concerne OpenStreetMap tout du moins. Souhaitant traiter les villes principales des provinces de Madagascar, et leur nombre étant relativement retreint (6 provinces), j'ai finalement décidé de recueillir manuellement les distances sur Google Maps.
OpenStreetMap sous R
2019-04-27 (Tag:6999203046543961454)
Pour illustrer mon support de cours consacré au "multidimensional scaling" (MDS), je souhaitais reproduire le sempiternel exemple du positionnement des villes dans le plan à partir de leurs distances routières réciproques. Le choix d'un pays original me permettrait de me démarquer, à savoir Madagascar que je connais très bien.Obtenir ces données en ligne sur Google Maps via un navigateur est très facile. Mais bon, tant qu'à faire, ce serait plus fun de les capter dans notre application R en faisant appel aux API dédiées, via les packages qui savent les manipuler (ex. mapsapi). Et patatras, j'apprends qu'il faut s'enregistrer pour obtenir une clé. L'accès reste gratuit certes tant qu'on reste en deçà d'une certaine limite, mais il faut – quoiqu'il en soit – fournir des informations bancaires lorsqu'on active son compte. Eh bien non ! Moi, je ne veux pas.
Je me suis tourné vers les alternatives gratuites, libres, sans enquiquinements. OpenStreetMap me semblait être une solution tout à fait valable. J'ai galéré ! Il y a certes de très nombreux tutoriels sur le net. Mais la majorité travaillent à partir de données préparées dans des formats spécifiques encapsulées dans des packages. Je n'ai pas trouvé un exemple clair et simple qui travaille exclusivement avec des données récupérées en ligne. J'ai cherché pourtant. J'ai donc remis à plus tard mon tutoriel sur les applications du MDS pour m'orienter vers la manipulation des données obtenues via l'API OpenStreetMap. La mission est simple : afficher la carte de Madagascar, obtenir la distance entre Antananarivo et Fianarantsoa, afficher le trajet en ces deux villes.
Positionnement multidimensionnel - Diapos
2019-04-25 (Tag:1081907255313051922)
Le positionnement multidimensionnel (multidimensional scaling en anglais, MDS) est une technique de visualisation qui permet de visualiser dans un repère euclidien (à p = 2 ou p = 3 dimensions le plus souvent) les positions relatives d'objets décrits par une matrice de distances, de dissimilarités ou de similarités.Ce support décrit les arcanes de la méthode. Il met l'accent sur le MDS classique dans un premier temps, avant de généraliser la présentation aux approches métriques et non-métriques. Les aspects pratiques sont détaillés avec force exemples : l'évaluation de la qualité de la représentation, le rapprochement avec l'ACP (analyse en composantes principales), le problème des valeurs propres négatives, le positionnement des individus supplémentaires, le traitement d'une matrice de corrélations,…
Mots-clés : positionnement multidimensionnel, multidimensional scaling, MDS, matrice de distance, stress, distance euclidienne, dissimilarité, similarité, principal coordinates analysis, PCoA, ACP, analyse en composantes principales, matrice de corrélations, MDS métrique, MDS non-métrique, produit scalaire
Support : MDS
Données : autos_mds
Références :
Debois D., "Une introduction au positionnement multidimensionnel", Revue MODULAD, n°32, p.1-28, 2005.
Programmer efficacement sous Python
2019-04-17 (Tag:8536628751878715)
J'avais écrit récemment un document à propos de l'optimisation des programmes sous R ("Programmer efficacement sous R", février 2019). Dans ce tutoriel, nous étudierons cette fois-ci comment déboguer, analyse et optimiser du code en Python, via l'EDI (Environnement de Développement Intégré) SPYDER livré avec la distribution ANACONDA.D'autres environnements de développements existent pour Python ("Here are the most popular Python IDEs / Editors", KDnuggets, Décembre 2018) mais, pour ma part, SPYDER me convient très bien au jour le jour. Je le conseille souvent à mes étudiants, en partie à cause de sa similitude avec RStudio. L'interface leur étant familière, le passage d'un langage à l'autre est moins abrupt.
Tout comme pour R, nous prétexterons de l'implémentation du leave-one-out (LOOCV – Leave-One-Out Cross-Validation) en modélisation prédictive (analyse discriminante linéaire) pour explorer les fonctionnalités proposées par SPYDER.
Mots-clés : débogueur, profileur, analyse de code, leave-one-out, python, scikit-learn
Didacticiel : Programmation efficace sous Python
Programme python et données : waveform
Références :
SPYDER: The Scientific Python Development Environment -- https://docs.spyder-ide.org/
Graphique de dépendance partielle - R et Python
2019-04-13 (Tag:4557775497817090303)
Récemment, j'avais étudié les outils agnostiques (applicables à tous types de classifieurs) pour mesurer l'importance des variables dans les modèles prédictifs (Février 2019). Toujours inspiré par l'excellent ouvrage de Christopher Molnar, "Interpretable Machine Learning", je m'essaie à l'étude de l'influence des variables cette fois-ci. L'objectif est de répondre à la question : de quelle manière la variable pèse sur la prédiction du modèle ? Pour schématiser, je dirais que l'importance traduit l'intensité de l'impact global de la variable. L'influence, elle, s'intéresse au sens et à la forme de la relation avec la cible, mais toujours à travers le modèle.Dans ce tutoriel nous étudierons le graphique de dépendance partielle ("partial dependence plot" en anglais, PDP) qui permet de caractériser, d'une certaine manière qu'on essaiera de délimiter, l'influence d'une variable dans un modèle. Nous travaillerons sous R dans un premier temps, je proposerai un programme pour le calculer, puis nous verrons si nos résultats concordent avec ceux du package "iml" pour R. Dans un deuxième temps, nous travaillerons sous Python, et nous explorerons cette fois-ci la procédure dédiée proposée par le package "scikit-learn".
R - Machine learning avec mlr
2019-04-06 (Tag:1037391168355515428)
La profusion des packages est à la fois une force et une faiblesse de R. Une force parce que nous disposons d'une richesse telle qu'il est possible de trouver un package qui réponde à nos besoins de traitements, quels qu'ils soient (presque). Une faiblesse parce que, en l'absence d'une coordination forte, ils adoptent souvent des modes opératoires disparates qui déroutent les utilisateurs. C'est en ces termes que j'introduisais le package "caret" qui se propose d'unifier la pratique du machine learning sous R dans un moule unique.Je pourrais tenir exactement le même discours en ce qui concerne la librairie "mlr" que je présente dans ce tutoriel. Nous traiterons d'un exemple (assez amusant) de "football mining" tiré de l'excellent ouvrage de Zhao et Cen (2014) pour en détailler les fonctionnalités.
Mots-clés : analyse prédictive, régression logistique, arbre de décision, svm, support vector machine, k-plus proches voisins, gradient boosting, courbe ROC, AUC, filtrage des variables, importance des variables, football mining, série A italienne, holdout, validation croisée, benchmarking, tuning
Didacticiel : Machine learning sous R avec mlr
Données et programme : Package mlr - Football
Références :
Bischl et al., "Machine learning in R".
Interpréter un classement en analyse prédictive
2019-04-01 (Tag:2833343391602171150)
Mon attention a été attirée récemment sur un post (mars 2019) du blog "Lovely Analytics" concernant l'interprétation du processus de classement à l'aide du package "lime" pour Python. Très peu souvent abordé dans les articles scientifiques, l'affaire est pourtant d'importance en pratique. En effet, quoi de plus naturel que d'essayer d'identifier les caractéristiques qui ont prédominé lors de l'attribution d'une classe à un individu en prédiction. Dans de nombreux domaines, cette justification est primordiale pour asseoir la crédibilité de la décision. On sait que le modèle refuse l'attribution d'un crédit à une personne parce qu'elle est au chômage, ou parce qu'elle a bouton sur le nez, ou, pire, parce qu'elle a un revers à deux mains, ou que sais-je encore… en tous les cas, on ne peut certainement pas se retrancher derrière la décision de l'ordinateur en invoquant l'infaillibilité de la data science et des fameux algorithmes.Dans ce tutoriel, nous essayons d'expertiser les solutions avancées par "lime" en vérifiant leur adéquation avec l'interprétation usuelle que l'on peut faire du classement dans les situations où on sait le faire, à savoir lorsqu'on utilise les arbres de décision et les classifieurs linéaires.
Mots-clés : python, package scikit-learn, package lime, classement, prédiction, arbre de décision, régression logistique
Didacticiel : Décortiquer lime
Données et programmes : Lime avec Python
Références :
M.T. Ribeiro, S. Singh, C. Guestrin, "Local Interpretable Model-Agnostic Explanations (LIME) : An Introduction", https://www.oreilly.com/learning/introduction-to-local-interpretable-model-agnostic-explanations-lime
Python - Machine learning avec mlxtend
2019-03-26 (Tag:490680842635512390)
Dans ce tutoriel, via une trame d’analyse prédictive assez standard, nous explorons le package "mlxtend" (machine learning extensions) de Sebastian Raschka. Je l'avais découvert initialement en cherchant des outils pour l'extraction des règles d'association sous Python. J'avais noté en lisant la documentation qu'il proposait des fonctionnalités assez intéressantes pour l'évaluation des modèles, que l'on retrouve peu dans les autres bibliothèques. De fil en aiguille, j'ai identifié d'autres procédures que je trouve assez judicieuses.Plutôt que de s'opposer aux packages déjà bien en place, "mlxtend" propose des outils qui s'interfacent avec ceux de scikit-learn par exemple, tirant parti de la puissance de ce dernier.
Mots-clés : python, machine learning, analyse prédictive, scikit-learn, évaluation des modèles, bootstrap, importance des variables, test de mcnemar, test de cochran, sélection des variables, wrapper, svm, rbf, régression logistique, stacking, combinaison de modèles
Didacticiel : Présentation de mlxtend
Données et programme : Mlxtend avec Python
Références :
Sebastian Raschka, "MLxtend: Providing machine learning and data science utilities and extensions to Python's scientific computing stack", in The Journal of Open Source Software, 3(24), april 2018.
Programmer efficacement sous R
2019-02-26 (Tag:6343290411698740284)
Mon attention a été attirée récemment par l'excellent ouvrage "Efficient R Programming" de Gillepsie et Lovelace (2017), accessible en ligne. Les auteurs exposent les tenants et aboutissants de la programmation efficace sous R. Au-delà des trucs et astuces, ils discutent des principes de l'écriture de programmes performants (en occupation mémoire et en temps d'exécution) et présentent – entres autres – les outils de benchmarking et de profiling (profilage en français) de code. Je me suis dit que ce serait une bonne chose d'illustrer leur utilisation dans le cadre de la programmation d'une procédure type de machine learning.Mon choix s'est porté sur la programmation du leave-one-out, une procédure de rééchantillonnage pour l'évaluation des modèles prédictifs. L'optimisation du code reposera sur une analyse fine des étapes grâce à l'outil de profiling. Nous pourrons gratter du temps d'exécution en jouant sur les spécificités des primitives de calcul utilisées, le choix des structures de données, la parallélisation des calculs. Tout cela en préservant la lisibilité du code source, gage indispensable de pérennité des applications sur le long terme.
Importance des variables dans les modèles
2019-02-23 (Tag:2678356772626605067)
En flânant sur le web, j'ai découvert l'excellent ouvrage libre de Christoph Molnar : “Interpretable Machine Learning” (13 fév. 2019). Son propos est de mettre l'accent sur l'interprétation des modèles. J'ai pris beaucoup de plaisir à le lire et surtout j'ai (re)découvert des approches intéressantes notamment dans le chapitre 5 intitulé “Model-Agnostic Methods” où il présente des méthodes génériques qui peuvent s'appliquer à tous types de classifieurs.Je me suis intéressé en particulier à la “permutation feature importance”, une technique destinée à mesurer l'importance des variables. Dans ce tutoriel, nous l'étudierons en la programmant nous-même sous R sur un jeu de données bien connu (Breast Cancer Wisconsin) pour lequel nous avons rajouté des variables générées aléatoirement pour corser l'affaire. Nous utilisons une régression logistique parce qu'elle propose intrinsèquement un procédé permettant d'évaluer l'influence des variables. Ce sera l'occasion d'étalonner la technique agnostique et étudier sa capacité à identifier la solution adéquate. Dans un deuxième temps, nous utiliserons le package “iml” développé par l'auteur de l'ouvrage et qui fournit des outils clés en main. Nous pourrons ainsi comparer nos résultats.
Règles d'association sous Python
2019-02-13 (Tag:7596337565513783851)
Ça fait un moment que je n'ai plus écrit de didacticiels sur les règles d'association. Comme je m'investis de plus en plus dans Python dans mes enseignements, je me suis dit qu'il était temps d'en écrire un pour ce langage, en complément d'un ancien document consacré à différents logiciels, notamment R avec le package "arules" (‘'Règles d'association – Comparaison de logiciels'', novembre 2008). J'utilise la librairie ‘'mlxtend'' (machine learning extensions) qui propose une série d'outils pour le machine learning : clustering, classification supervisée, régression, etc., et donc l'extraction des itemsets fréquents et des règles d'association que nous étudierons dans ce didacticiel.L'organisation de ce document est on ne peut plus classique dans notre contexte : chargement et préparation des données, extraction des itemsets fréquents, recherche des sous-ensembles d'itemsets comportant des items particuliers, déduction des règles d'association à partir des itemsets fréquents, recherche de sous-ensembles de règles au regard de la présence de certains items ou répondant à des critères numériques.
Mots-clés : python, package mlxtend, itemsets fréquents, règles d'association, support, confiance, lift, apriori
Didacticiel : Règles d'association sous Python
Programmes et données : python_market_basket.zip
Références :
Tutoriel Tanagra, "Extraction des règles d'association - Diapos", Juin 2015.
R et Python, performances comparées
2019-02-04 (Tag:4508710512778190102)
Lancer un débat sur les mérites des différents langages de programmation est une bonne manière de plomber un repas entre informaticiens. J'en avais fait les frais naguère lorsque j'avais voulu comparer les performances de plusieurs d'entre eux (Java, C++, C#, Delphi - alors que j'en étais arrivé à la conclusion finalement que le meilleur outil était celui dont on maîtrisait le mieux les contours, et que la structuration des données jouait un rôle fondamental).J'imagine qu'on se heurterait à la même fronde de la part de certains (une moitié vs. l'autre ?) data scientists si l'on se mettait à opposer R et Python. L'année dernière, à la même époque, j'avais essayé de montrer qu'on pouvait enseigner les deux dans les formations en data science, et que le passage d'un outil à l'autre engendrait un surcoût pédagogique négligeable au regard des avantages, notamment en termes de positionnement de nos étudiants sur le marché du travail. Je m'attache à appliquer ce principe dans mes enseignements à l'Université.
Malgré tout, je me risque à un petit comparatif dans ce tutoriel. Parce que j'entends beaucoup d'affirmations ici et là qui ne sont pas vraiment argumentées. J'ai décidé de vérifier par moi-même en observant les performances des outils dans un cadre précis, bien délimité : chargement d'un fichier CSV volumineux (9.796.862 observations et 42 variables – il s'agit de la base KDD CUP 99 dont chaque ligne a été dupliquée), réalisation de calculs de statistique descriptives simples (moyennes, croisements, tris).
Tous les outils testés ont mené à bien les opérations, c'est une information primordiale. Après, nous avons des résultats – spécifiques à l'expérience menée, je souligne encore une fois – qui titillent quand même pas mal notre intellect. Je vous laisse les découvrir.
Bien sûr, les temps de traitement annoncés dans ce tutoriel sont propres à ma machine fixe (Core i7 - 3.1 Ghz). J'ai refait les tests sur mon ordinateur portable (Core i5 - 2.7 Ghz), les valeurs sont différentes dans l'absolu (le contraire eût été étonnant), mais les positions et écarts relatifs restent identiques. J'imagine qu'il en sera de même sur votre ordinateur.
Enfin, à l'attention des ronchons pro-ci ou pro-ça dont j'entends déjà les grognements, je leur dis de monter leurs propres expérimentations, et surtout de bien veiller à mettre en ligne leurs codes et leurs données pour que tout un chacun puisse retracer ce qui est annoncé. S'assurer de la reproductibilité des résultats est la base même de la démarche scientifique.
Mots-clés : logiciel R, fichier CSV, kdd cup 99, package data.table, packager readr, package dplyr, python, package pandas, statistique descriptive
Didacticiel : R et Python, performances
Programmes : Chargement et statistiques (R et Python)
Données : kddcup99twice.7z
Références :
Tutoriel Tanagra, "R ou Python, il faut choisir ?", Janvier 2018.
Stacking avec R
2019-01-13 (Tag:6525351355041936245)
Ce tutoriel fait suite au support de cours consacré au stacking. L'idée, rappelons-le, est de faire coopérer des modèles en prédiction en espérant que les erreurs se compenseront. L'ensemble serait alors plus performant que les modèles sous-jacents qui le composent, pris individuellement. A la différence du boosting ou du bagging, nous créons les classifieurs à partir de la même version des données d'entraînement (sans pondération ou autres modifications), la diversité nécessaire à la complémentarité provient de l'utilisation d'algorithmes de familles différentes. Dans les exemples que nous explorerons, le pool comprendra un arbre de décision, une analyse discriminante linéaire, et un SVM avec un noyau RBF. On peut penser que ces approches possèdent des caractéristiques suffisamment dissemblables pour qu'en classement, elles ne soient pas constamment unanimes (si les modèles sont unanimes, les faire coopérer ne sert à rien).Nous étudierons le stacking de deux manières dans ce document. Dans un premier temps, nous programmerons à partir de zéro les différentes manières de combiner les modèles (vote ‘'hard'', vote ‘'soft'', métamodèle). Au-delà du plaisir à le faire, l'objectif est de décortiquer les étapes pour s'assurer la bonne compréhension des approches. Ensuite seulement, dans un deuxième temps, nous utiliserons les outils spécialisés (caretEnsemble, H2O). Le fait de détailler les opérations précédemment permettra de mieux appréhender les paramètres et les opérations préalables que nécessitent l'appel des fonctions dédiées au stacking dans ces packages.
Stacking
2019-01-08 (Tag:3026145711335986413)
Combiner des modèles prédictifs pour les rendre collectivement plus performants est une idée qui a largement fait son chemin auprès des data scientists. Les approches bagging, boosting, sont souvent mises en avant. Elles reposent sur le principe de l'application du même algorithme d'apprentissage sur différentes variantes des données (ex. par pondération des observations) de manière à obtenir un pool de classifieurs présentant une hétérogénéité satisfaisante.Une autre piste existe. On peut s'appuyer sur la diversité des algorithmes eux-mêmes pour produire l'ensemble de classifieurs. On pourrait par exemple utiliser, un arbre de décision, une analyse discriminante linéaire et un support vector machine avec un noyau RBF. L'efficacité globale dépend alors de l'efficacité individuelle des modèles et de leur hétérogénéité (décorrélation si l'on se réfère à la terminologie de random forest).
Dans ce support, nous traçons les grandes lignes de l'approche. L'agrégation des modèles tient alors une place centrale. Elle peut reposer sur un vote simple ou pondéré. Elle peut aussi, et c'est le principe du stacking, être modélisé à partir des prédictions des classifieurs qui constituent le pool. On aurait alors un modèle de modèles, un métamodèle prédictif.
Mots-clés : ensemble de modèles, métamodèle, stacking, stacked ensemble, vote simple, vote pondéré, python, scikit-learn, h2o
Support de cours : Stacking - Diapos
Références :
H2O Documentation, "Stacked Ensembles".
Machine Learning avec H2O (Python)
2019-01-04 (Tag:1604048897239609656)
H2O est une plate-forme JAVA de machine learning. Elle propose des outils pour la manipulation et la préparation de données, des algorithmes de modélisation, supervisées, non-supervisées ou de réduction de dimensionnalité. Nous pouvons accéder à ses fonctionnalités en mode client-serveur via différents langages de programmation avec le mécanisme des API (application programming interface). Nous nous appuierons sur Python dans ce tutoriel, mais nous aurions pu réaliser entièrement la même trame sous R.Ce tutoriel comporte trois grandes parties : nous évaluerons son aptitude à paralléliser ses algorithmes d’analyse prédictive ; nous étudierons ensuite dans le détail ces approches supervisées, en regardant de près les (une partie des) paramètres et les sorties ; enfin, nous jetterons un oeil sur quelques outils additionnels de H2O, toujours pour le supervisé.
Mots-clés : h2o, python, régression logistique binaire, random forest, gradient boosting, perceptron simple et multicouche, deep learning, naive bayes, grid search, automl, stacking, stacked ensembles, validation croisée, échantillon de validation, multithreading, parallélisation, processeur multicœur
Didacticiel : Machine Learning avec H2O
Données et programme Python : H2O - Programme Python
Références :
H2O.ai -- http://docs.h2o.ai/h2o/latest-stable/h2o-docs/index.html
Bonne année 2019 - Bilan 2018
2019-01-03 (Tag:9145344553042169014)
L'année 2018 s'achève, 2019 commence. Je vous souhaite à tous une belle et heureuse année 2019.Un petit bilan chiffré concernant l'activité organisée autour du projet Tanagra pour l'année écoulée. L'ensemble des sites (logiciels, support de cours, ouvrages, tutoriels) a été visité 198.198 fois en 2018, soit 543 visites par jour.
Il y a une forte diminution de la fréquentation par rapport à l'année dernière (609 visites en 2017), dû en partie aux pannes répétées de notre serveur, avec en prime un blackout total de notre établissement pendant plus de 15 jours en août (je n'ai même pas pu lire mes e-mails). Je m'en excuse auprès des internautes qui, pendant plusieurs périodes, n'ont pas pu accéder aux documents. Peut-être qu'il est temps de migrer tout cela sur un support plus fiable comme GitHub par exemple mais, pour l'instant, vu le volume à déplacer, je ne me sens pas trop de le faire. Transférer plus de 15 ans de travail avec près de 500 documents représenterait une activité à plein temps qui pourrait durer des semaines, voire des mois. A voir.
Depuis la mise en place du compteur Google Analytics (01 février 2008), le groupe de sites a été visité 2.531.569 fois, soit 630 visites par jour en plus de 10 ans.
Les visiteurs viennent en majorité de la France (52%), du Maghreb (16%) et de l'Afrique francophone. Les pages de supports de cours ont toujours autant de succès, en particuliers ceux dédiés à la Data Science et à la programmation (R et Python).
29 documents supplémentaires (supports de cours, tutoriels) ont été postés cette année, tous en français.
En cette nouvelle année, je souhaite le meilleur à tous les passionnés de Data Science, de Statistique et d'Informatique.
Ricco.
Packages Python pour le Deep Learning
2018-12-24 (Tag:5670420984144360163)
Ce document fait suite au support de cours consacré aux "Perceptrons simples et multicouches" et au tutoriel sur les "Packages R pour le Deep Learning - Perceptrons". L'objectif est de montrer un processus complet d'analyse prédictive à l'aide de successions de commandes simples sous Python : importer les données, les préparer ; construire et configurer le réseau ; estimer ses coefficients (poids synaptiques) à partir d'un ensemble de données étiquetées ; prédire sur un second échantillon, soit aux fins de déploiement, soit aux fins d'évaluation des performances.La tâche est en théorie relativement aisée. Le véritable enjeu pour nous est d'identifier sans ambiguïtés, d'une part les bonnes commandes, d'autre part les paramètres idoines pour construire précisément le réseau que nous souhaitons appliquer sur les données. En pratique, ce n'est pas si évident que cela parce qu'identifier de la documentation pertinente sur le web n'est pas toujours facile. On retrouve souvent le même tutoriel avec la sempiternelle base MNIST, qui est littéralement accommodée à toutes les sauces. Pouvoir généraliser la démarche à d'autres bases devient une vraie gageure. J'espère y arriver en schématisant au mieux les étapes, et surtout en donnant au lecteur la possibilité de faire le parallèle avec la même mission réalisée sous R.
Nous étudierons les packages "scikit-learn", "keras / tensorflow" et "h2o". Nous dirons un mot également des librairies "MXNET", "PyTorch" et "caffe".
Mots-clés : packages python, deep learnin, perceptron simple, perceptron multicouche, scikit-learn, keras, tensorflow, h2o, mxnet, pytorch, caffe, réseaux de neurones
Didacticiel : Perceptrons - Packages Python
Données et programme Python : spam dataset python
Références :
Tutoriel Tanagra, "Deep Learning : perceptrons simples et multicouches", novembre 2018.
Packages R pour le Deep Learning
2018-12-16 (Tag:8755838121585641278)
Ce tutoriel fait suite au support de cours consacré aux perceptrons simples et multicouches. L'objectif est d'explorer le mode opératoire et l'efficacité des différents packages qui proposent la méthode.Notre schéma de travail sera relativement classique s'agissant d'un contexte d'analyse prédictive. Nous importons une base de données, nous la subdivisons en échantillons d'apprentissage et de test. Nous standardisons les variables avec une subtilité importante que l'on précisera. Puis, pour chaque package, nous implémenterons un perceptron multicouche avec 1 seule couche cachée à 2 neurones (ce n'est pas de l'humour...) dont nous évaluerons les performances prédictives. Certains packages proposent des fonctionnalités additionnelles. Nous essayerons de les cerner.
Mots-clés : package R, logiciel R, nnet, neuralnet, h2o, rsnns, deepnet, keras, mxnet, perceptron simple, perceptron multicouche, réseaux de neurones, deep learning
Didacticiel : Perceptrons - Packages R
Données et programme R : spam dataset
Références :
Tutoriel Tanagra, "Deep learning : perceptrons simples et multicouches", novembre 2018.
Deep learning : perceptrons simples et multicouches
2018-11-18 (Tag:1554990848699206059)
La vie est faite de bizarreries qui m’étonnent toujours. A mes débuts dans l’enseignement, les étudiants étaient très curieux de savoir ce qu’étaient ces fameux réseaux de neurones qui leur paraissaient tant mystérieux. Faute de disposer d’outils simples à utiliser (au milieu des années 90), je l’avais programmé dans SIPINA et j’avais monté un cours dessus, en me focalisant sur l’analyse prédictive avec le perceptron, simple et multicouche. Au fil des années, d’autres approches sont devenues plus "populaires" (oui, même dans le domaine scientifique, ça existe), les SVM (suppport vector machine) ou encore les technologies bagging, random forest, boosting. L’intérêt des étudiants s’étant délité, j’ai rangé au placard ma séance consacrée au perceptron dans mon cours de machine learning (qui s’appelait data mining à l’époque, conséquence d’un autre phénomène de mode aussi).Puis est venue la vague du deep learning. Les étudiants sont revenus à la charge. J’ai cru à une blague tout d’abord quand j’ai lu les premiers articles qui en parlaient. Ils s’agiraient de réseaux avec plusieurs couches pour faire de l’apprentissage profond. Ah bon ? Ce n’est pas ce que l’on avait avec les perceptrons ? Et ce depuis bien longtemps déjà ! Passé ce premier instant de scepticisme, je me suis dit que cet engouement devait reposer sur des bases quand même un peu plus solides, et j’ai un peu creusé l’affaire. Je me suis rendu compte qu’il y avait matière à proposer des choses intéressantes dans mes enseignements. Je suis donc parti dans l’idée de réaliser une série de supports sur le sujet, à commencer par dépoussiérer mon cours sur les perceptrons, que j’ai fait évoluer à la lumière des « nouveautés » proposées dans les bibliothèques de calcul qui font foi, en particulier sous R et sous Python.
Ateliers Master SISE : outils de la Dataviz
2018-11-06 (Tag:28004813672522698)
Comme tous les ans, à la rentrée universitaire, je demande aux étudiants du Master SISE d’assurer des ateliers techniques destinés à former leurs propres collègues. Cette année, mon choix s’est porté sur les outils de la Dataviz (de Reporting) : Power BI (version gratuite), Google Data Studio et D3.js.Bien sûr, avec 3 heures pour chaque outil (1h30 initiation [1], 1h30 perfectionnement [2]), on peut difficilement les étudier en profondeur. Mais par expérience, je sais que franchir la barrière à l’entrée est très souvent le principal enjeu de l’autoformation. Lorsque l’apprenant ne sait pas par quel bout commencer, il se décourage vite souvent. Pouvoir passer cet écueil est donc primordial, et c’est justement l’objectif des ateliers qu’ont préparé les étudiants, avec des étapes clés basiques : comment importer et manipuler ses données, comment créer un premier dashboard, quelles sont les principales fonctionnalités (représentations graphiques, tableaux, etc.), qu’est-ce que l’on peut attendre de l’outil globalement… Ces ateliers jouent parfaitement leur rôle dans cette optique. Par la suite, une fois que nous avons mis le pied à l’étrier, il nous appartient d’aller plus loin par nous-même.
Les fichiers ci-dessous comprennent : les supports de présentation, les sujets des exercices, les données et/ou corrigés (PDF), le corrigé sous forme de tutoriel vidéo.
Merci aux étudiants pour cet excellent travail qui profitera à tout le monde. La Dataviz est une compétence connue et reconnue dans le monde de la data. Il suffit de consulter les offres d’emploi que l’on trouve sur le site de l’APEC par exemple pour s'en convaincre (Dataviz).
| Thèmes | Présentations | Exercices | Dataset / Corrigés | Tutoriels |
|---|---|---|---|---|
| Power BI 1 | | | | |
| Power BI 2 | | | | |
| Data Studio 1 | | | | |
| Data Studio 2 | | | | |
| D3.js 1 | | |  | |
| D3.js 2 | | | | |
LibreOffice Base
2018-09-14 (Tag:6214131336308290574)
J’ai mis en ligne récemment un module de remise à niveau pour les candidats au Master SISE dédié au langage SQL (structured query language). Les exercices ont été préparés par les étudiants de la promotion 2017-2018. Ils ont choisi de privilégier le SGDB (système de gestion de bases de données) Microsoft Access parce qu’il est installé par défaut dans les salles machines de notre Université.En réalité, les exercices sont génériques (parce que le langage SQL l’est ! même s’il peut y avoir des spécificités parfois selon les outils), ils sont réalisables sous tout autre SGBD. Et c’est une bonne chose parce que tout le monde n’a pas accès à Access, qui est payant rappelons-le. Nous pouvons notamment utiliser l’outil Base de la suite bureautique LibreOffice. Dans ce tutoriel, je montre comment créer une base via l’importation de données contenues dans des fichiers Excel, comment établir les liens entre les tables générées, puis initier des requêtes mono ou multi-tables.
Master SISE - Remise à niveau - SQL
2018-09-12 (Tag:3347484969455707011)
Les données sont la principale matière première de la data science, lesquelles sont souvent stockées dans des bases de données relationnelles. Savoir les manipuler correctement est par conséquent une compétence fondamentale pour nous.Il y a deux phases dans l’appréhension des bases de données. La première est leur conception à partir des informations existantes. Il s’agit de les collecter, de les recenser et de proposer une organisation sous forme d’une collection de tables, reliées entre elles. La méthode MERISE est certainement une des approches les plus populaires pour les élaborer rationnellement (ex. Idriss NEUMANN, "Initiation à la conception de bases de données relationnelles avec MERISE").
Le seconde phase consiste à les exploiter en insérant des données dans les tables, effectuer des mises à jour et, très souvent, réaliser de requêtes d’extraction pour récupérer les données disponibles correspondant à certaines conditions. Le langage SQL (structured query language) est l’outil privilégié pour cette tâche. On peut vouloir obtenir par exemple la liste des clients et les montants d’achats des personnes qui sont venus dans tels magasins d’une grande chaîne de distribution durant telle période. Une instruction SQL simple permet de le faire rapidement et ainsi d’initier par la suite les analyses qui conviennent. De fait, SQL apparaît systématiquement dans le top des outils couramment utilisés par les data scientists (Sondage KdNuggets, Mai 2018).
Ce thème de remise à niveau est plutôt consacré à la seconde phase. La base est considérée comme conçue, les tables sont pourvues de données (il faudra quand même importer les données à partir de fichiers Excel au préalable). L’objectif des exercices est de familiariser l’apprenant aux principales commandes SQL.
Particularité importante de ce thème, les supports de cours et les exercices ont été conçus par les étudiants même du Master SISE, promotion 2017-2018. Je les en remercie.
Document principal : SQL - Trame
Outil : Microsoft ACCESS ou LibreOffice BASE
Exercice 1 : SQL Niveau 1, cours, exercices, données
Exercice 2 : SQL Niveau 2, cours, exercices
Pipeline sous Python - La méthode DISQUAL
2018-06-26 (Tag:7209392120303181496)
En inventoriant le package « fanalysis » d’Olivier Garcia dédié à l’analyse factorielle (ACP, AFC et ACM) sous Python, mon attention a été attirée par l’outil Pipeline du package « scikit-learn » mis en avant lors de la présentation de l’ACM (analyse des correspondances multiples). Un Pipeline est un méta-opérateur qui permet d’enchaîner plusieurs calculs, pourvu que les classes mises à contribution implémentent les fonctions fit() (apprentissage) et transform() (projection). Les mécanismes de classes de Python et la forte cohérence des objets de « scikit-learn » font merveille ici. Cette notion d’opérateur encapsulant plusieurs autres qui s’exécutent séquentiellement n’est pas sans rappeler les metanodes dans des logiciels de data mining tels que Knime. J’avais pu en explorer le fonctionnement lors de la programmation de la validation croisée par exemple.Nous nous appuierons sur l’étude de la méthode DISQUAL de Gilbert Saporta pour montrer l’intérêt de la classe Pipeline de « scikit-learn ». DISQUAL (discrimination sur variables qualitatives) permet de réaliser une analyse discriminante prédictive sur des variables explicatives qualitatives en faisant succéder deux techniques statistiques : dans un premier temps, une ACM est opérée sur les descripteurs, nous obtenons une description des données dans un espace factoriel ; dans un second temps, on lance une analyse discriminante linéaire (ADL), expliquant la variable cible à partir des facteurs de l’ACM. DISQUAL cumule un double avantage : elle rend réalisable l’analyse discriminante linéaire dans une configuration qu’elle ne sait pas appréhender nativement (explicatives qualitatives) ; on peut en moduler les propriétés de régularisation, et donc la robustesse au surapprentissage, en jouant sur le nombre de facteurs de l’ACM à retenir pour l’analyse discriminante.
On note surtout dans le contexte de ce tutoriel que DISQUAL est constituée deux techniques statistiques qui se succèdent (ACM + ADL). Elle se prête à merveille à l’utilisation de l'outil Pipeline.
Mots-clés : pipeline, scikit-learn, package fanalysis, disqual, acm, analyse des correspondances multiples, discrimination sur variables qualitatives, analyse discriminante
Composants Tanagra : MULTIPLE CORRESPONDANCE ANALYSIS, LINEAR DISCRIMINANT ANALYSIS
Didacticiel : Pipeline et DISQUAL
Données et programme : Pipeline et disqual - Python
Références :
Scikit-learn, "sklearn.pipeline.Pipeline".
LeMakiStatheux, "La méthode DISQUAL".
Analyses factorielles sous Python avec fanalysis
2018-06-11 (Tag:3652888718556703645)
Je concluais mon précédent tutoriel sur l’ACP sous Python en espérant voir un jour des packages Python permettant de réaliser plus simplement (que sous ''scikit-learn''), plus efficacement, les analyses factorielles : ACP [analyse en composantes principales], mais pourquoi pas aussi l’AFC [analyse factorielle des correspondances] et l’ACM [analyse des correspondances multiples].Mes voeux ont été devancés. Un de mes anciens étudiants du Master SISE, Olivier Garcia (SISE 1999-2000, ça remonte à quelques années …), m’indique qu’il a mis en ligne récemment un package qui permettent de réaliser ces analyses, avec toutes les fonctionnalités attendues de l’analyse de données à la française décrite dans les publications francophones qui font référence. Un grand Merci à lui !
Le package intitulé "fanalysis" est sous licence BSD-3 et peut se télécharger simplement en tapant en ligne de commande :
pip install fanalysis
Voici le lien vers le repo GitHub : https://github.com/OlivierGarciaDev/fanalysis
Ce package fanalysis poursuit un double objectif :
1) Permettre de réaliser des analyses factorielles dans un but descriptif. Il permet de produire simplement les statistiques principales : valeurs propres, coordonnées, contributions, cos2. Ces statistiques peuvent être exportées vers un DataFrame Pandas. En outre, divers outils graphiques sont proposés : valeurs propres, mapping factoriels, graphiques permettant de voir quelles lignes/colonnes présentent les plus fortes contributions/cos2 pour un axe donné...
2) Permettre d'utiliser les analyses factorielles en tant que méthodes de pre-processing dans des pipelines scikit-learn. On peut ainsi, par exemple, enchaîner une AFC multiple puis une régression logistique, et optimiser le nombre de facteurs pris en compte par validation croisée.
La docstring est en écrite globish, mais 3 tutos sont disponibles en français sur le repo GitHub, sous forme de notebooks :
Le package met à disposition des tests unitaires dont la philosophie générale est de comparer les sorties de ses méthodes avec celles du package R FactoMineR. Ouf, les tests s'avèrent concluant !
Le package fanalysis fonctionne avec des matrices denses en entrée.
Sur le plan technique, c'est la fonction svd() (décomposition en valeurs singulières) de numpy qui est au coeur des calculs.
Mots-clés : package fanalysis, python, acp, analyse en composantes principales, afc, analyse factorielle des correspondances, acm, analyse des correspondances multiples
Ouvrage de référence : "Pratique des Méthodes Factorielles avec Python", juillet 2020.
Site de référence : Cours Analyse Factorielle
ACP avec Python
2018-06-08 (Tag:997100130568640469)
J’ai déjà beaucoup donné pour l’analyse en composantes principales, sous forme de support de cours (ACP), de tutoriels pour Tanagra, pour Excel, pour R, ... mais jamais pour Python.Il est temps d’y remédier. D’autant plus que l’affaire n’est pas si évidente finalement. J’ai choisi d’utiliser le package "scikit-learn" maintes fois cité sur le web. Je me suis rendu compte que la classe PCA effectuait les calculs essentiels effectivement, mais il nous appartenait ensuite de programmer tout le post-traitement, notamment les aides à l’interprétation. Je me suis retrouvé un peu dans la même situation qu’il y a presque 10 ans où je m’essayais à l’ACP sous R en utilisant la fonction basique princomp() du package "stats" (Mai 2009). Le tutoriel associé ainsi que notre support de cours nous serviront de repères tout au long de ce document.
Mots-clés : analyse en composantes principales, ACP, package scikit-learn, PCA
Didacticiel : ACP sous Python
Données et programme : Autos Python
Références :
Tutoriel Tanagra, "ACP avec Tanagra - Nouveaux outils", Juin 2012.
Tutoriel Tanagra, "Analyse en Composantes Principales avec R", Mai 2009.
Tutoriel Tanagra, "ACP avec R - Détection du nombre d'axes", Juin 2012.
Site de référence :
Cours Analyse Factorielle
Régressions ridge et elasticnet sous R
2018-05-24 (Tag:1166994971848417330)
Ce tutoriel fait suite au support de cours consacré à la régression régularisée (RAK, 2018). Il vient en contrepoint au document récent consacré à la Régression Lasso sous Python. Nous travaillons sous R cette fois-ci et nous étudions les régressions ridge et elasticnet.Nous nous situons dans le cadre de la régression logistique avec une variable cible qualitative binaire. Le contexte n’est pas favorable avec un échantillon d’apprentissage constitué de n_train = 200 observations et p = 123 descripteurs, dont certains sont en réalité des constantes. Les propriétés de régularisation de ridge et elasticnet devraient se révéler décisives. Encore faut-il savoir / pouvoir déterminer les valeurs adéquates des paramètres de ces algorithmes. Ils pèsent fortement sur la qualité des résultats.
Nous verrons comment faire avec les outils à notre disposition. Nous utiliserons les packages ‘’glmnet’’ et ‘’tensorflow / keras’’. Ce dernier tandem a été présenté plus en détail dans un précédent document (Avril 2018). Il faut s’y référer notamment pour la partie installation qui n’est pas triviale.
Mots-clés : régression ridge, régression elasticnet, package glmnet, package tensorflow, package keras, ridge path, elasticnet path, coefficient de pénalité, validation croisée
Didacticiel : Ridge et elasticnet sous R
Données et programme : Adult dataset
Références :
Rakotomalala R., "Régression régularisée - Ridge, Lasso, Elasticnet", Mai 2018.
Régression Lasso sous Python
2018-05-18 (Tag:7505630401583875404)
Ce tutoriel fait suite au support de cours consacré à la régression régularisée. Nous travaillons sous Python avec le package « scikit-learn ».Au-delà de la simple mise en oeuvre de la Régression Lasso, nous effectuons une comparaison avec la régression linéaire multiple usuelle telle qu’elle est proposée dans la librairie « StatsModels » pour montrer son intérêt. Nous verrons entres autres ses apports en termes de sélection de variables et d’optimisation des performances prédictives.
L’exemple est à vocation pédagogique, il s’agit avant tout de décortiquer les mécanismes de l’approche. J’ai par conséquent fait le choix d’utiliser une base de taille réduite (p = 16 variables explicatives) pour que les graphiques soient lisibles (le « Lasso path » par exemple). Dans ce contexte, les propriétés de régularisation de la Régression Lasso ne se démarquent pas vraiment.
Mots-clés : régression lasso, package scikit-learn, package statsmodels, lasso path, coefficient de pénalité, validation croisée
Didacticiel : Lasso Python
Données et programme : Baseball dataset
Références :
Rakotomalala R., "Régression régularisée - Ridge, Lasso, Elasticnet", Mai 2018.
Ridge - Lasso - Elasticnet
2018-05-11 (Tag:6105162149691382991)
La régression est la méthode la plus populaire auprès des data scientists (KDnuggets Polls, « Top 10 Data Science, Machine Learning Methods Used in 2017 », Décembre 2017). Elle existe depuis la nuit des temps (j’exagère un peu) et fait référence. Elle est de ces approches que l’on doit systématiquement essayer lorsqu’il s’agit de mettre en concurrence plusieurs algorithmes dans un problème d’analyse prédictive.La régression doit faire face à de nouveaux enjeux ces dernières années, avec notamment la profusion des données à très forte dimensionnalité lors du traitement des données non-structurées. Un grand nombre de descripteurs sont automatiquement générés avec pour caractéristiques le bruit et la colinéarité. Les approches et implémentations classiques de la régression souffrent de ces situations. La régularisation devient une nécessité vitale pour éviter les phénomènes de surapprentissage.
Dans ce support de cours, nous présentons les approches Ridge, Lasso et Elasticnet dans le cadre de la régression linéaire multiple. Nous les étendons par la suite à la régression logistique. Les exemples utilisant les packages spécialisés pour R et Python permet de comprendre concrètement le comportement de ces algorithmes de machine learning.
Descente de gradient stochastique sous Python
2018-05-01 (Tag:391175574347799302)
Ce tutoriel fait suite au support de cours consacré à l’application de la méthode du gradient en apprentissage supervisé. Nous travaillons sous Python. Un document similaire a été écrit pour le logiciel R dans le cadre de la régression linéaire multiple.Nous travaillons sur un problème de classement cette-fois. Nous souhaitons estimer les paramètres de la régression logistique à partir d’un ensemble de données étiquetées. Nous utilisons le package « scikit-learn » particulièrement populaire auprès des aficionados de Python . Nous étudierons l’influence du paramétrage sur la rapidité de la convergence de l’algorithme d’apprentissage et, de manière plus générale, sur la qualité du modèle obtenu. Nous en profiterons pour détailler une petite curiosité, parce que peu mise en avant dans les supports, que constitue la construction de la courbe ROC (Receiver Operating Characteristic) en validation croisée.
Mots-clés : descente de gradient stochastique, package scikit-learn, sklearn, régression logistique, python
Didacticiel : Descente de gradient stochastique
Données et programmes : sonar dataset
Références :
Rakotomalala R., "Descente de gradient - Diapos", avril 2018.
Tutoriel Tanagra, "Descente de gradient sous R", avril 2018.
Descente de gradient sous R
2018-04-26 (Tag:2693078904526530712)
Ce tutoriel fait suite au support de cours consacré à l’application de la méthode du gradient en apprentissage supervisé. Nous travaillons sous R. Un document consacré à Python viendra par la suite.Nous nous plaçons dans le cadre de la régression linéaire multiple. Dans un premier temps, nous traiterons un jeu de données réduit qui nous permettra d’étudier en détail le comportement des algorithmes de descente de gradient, stochastique ou non. L’idée est de comparer les coefficients estimés et les valeurs de la fonction de perte obtenues à l’issue du processus d’apprentissage. Dans un second temps, nous traiterons un fichier réaliste de classement de protéines où le nombre de variables est élevé, son ratio par rapport au nombre d’observations est largement supérieur à 1. Dans ce cas, l’implémentation usuelle de la régression sous R, lm() du package « stats », même si elle est solide, n’est pas opérationnelle. Seules les approches basées sur la descente de gradient permettent de produire un résultat exploitable.
Nous utiliserons les packages ‘gradDescent’ et ‘tensorflow / keras’. Ce dernier tandem a été présenté plus en détail dans un précédent document (Avril 2018). Il faut s’y référer notamment pour la partie installation qui n’est pas triviale.
Mots-clés : descente de gradient, algorithme du gradient, gradient stochastique, logiciel R, package gradDescent, packages tensorflow, keras, régression, régression linéaire multiple, classement de protéines
Didacticiel : Descente de gradient sous R
Données et programmes : artificial + protein
Références :
R. Rakotomalala, "Descente de gradient - Diapos", avril 2018.
Tutoriel Tanagra, "Deep learning - Tensorflow et Keras sous R", avril 2018.
Tutoriel Tanagra, "Descente de gradient stochastique sous Python", mai 2018.
Descente de gradient - Diapos
2018-04-20 (Tag:1237537260603801153)
Application du principe de la descente de gradient à l’apprentissage supervisé. Exemples avec la régression linéaire multiple et la régression logistique.La volumétrie est un problème récurrent du machine learning. La majorité des algorithmes reposent sur la formulation d’une optimisation. Il devient très difficile de les mettre en œuvre sur les bases actuelles qui sont parfois aussi larges (si ce n’est plus) que longues. L’algorithme du gradient connaît un regain d’intérêt certain dans ce contexte. En effet, d’une part, il permet de revisiter les méthodes statistiques existantes comme la régression, d’autre part, il devient incontournable dans les méthodes très populaires aujourd’hui telles que le deep learning.
Ce support de cours présente le principe descente de gradient. Il montre concrètement son implémentation dans le cadre de la régression linéaire multiple et la régression logistique binaire et multinomiale. Quelques packages pour Python (scikit-learn, tensorflow / keras) et R (gradDescent) sont mis en avant.
Mots-clés : gradient descent, stochastic gradient descent, descente de gradient stochastique, régression linéaire multiple, régression logistique, python, logiciel R, tensorflow, keras, scikit-learn, gradDescent, perceptron
Support de cours : Descente de gradient
Références :
Wikipedia, "Gradient descent".
Wikipedia, "Stochastic gradient descent".
Deep Learning - Tensorflow et Keras sous R
2018-04-13 (Tag:3101126383574939377)
Python et R sont les deux mamelles généreuses de la fertilité intellectuelle du data scientist. Parfois elles sont interchangeables, parfois elles se complètent. En tous les cas, elles nourrissent la pratique de la data science. Et, finalement, le choix entre ces fontaines de jouvence est avant tout affaire de goûts personnels, de circonstances, d’environnements de travail, de disponibilité des packages…Ce tutoriel fait suite à un document récent consacré au deep learning via les librairies Tensorflow et Keras sous Python. Nous en reprenons les étapes point par point, mais sous R cette fois-ci. Nous verrons que la transposition est particulièrement simple.
Mots-clés : deep learning, tensorflow, keras, perceptron simple, perceptron multicouche, logiciel R
Didacticiel : Tensorflow et Keras sous R
Données et programmes : 2D
Références :
Tutoriel Tanagra, "Deep Learning avec Tensorflow et Keras (Python)", avril 2018.
Deep Learning avec Tensorflow et Keras (Python)
2018-04-11 (Tag:5769114397937148134)
Tensorflow est une bibliothèque open-source développée par l’équipe Google Brain qui l’utilisait initialement en interne. Elle implémente des méthodes d’apprentissage automatique basées sur le principe des réseaux de neurones profonds (deep learning). Une API Python est disponible. Nous pouvons l’exploiter directement dans un programme rédigé en Python. C’est faisable, il existe des tutoriels et des ouvrages à ce sujet. Pourtant, j’ai préféré passer par Keras parce que le formalisme imposé par Tensorflow est déroutant au possible pour un néophyte. Découvrir de nouveaux algorithmes devient vite rédhibitoire si on a du mal à se dépatouiller avec un outil que nous sommes censés utiliser pour les mettre en application.Keras est une librairie Python qui encapsule l’accès aux fonctions proposées par plusieurs librairies de machine learning, en particulier Tensorflow. De fait, Keras n’implémente pas nativement les méthodes. Elle sert d’interface avec Tensorflow simplement. Mais pourquoi alors s’enquiquiner avec une surcouche supplémentaire direz-vous ? Parce qu’elle nous facilite grandement la vie en proposant des fonctions et procédures relativement simples à mettre en œuvre. Un apprenant qui a déjà assimilé les démarches types du machine learning, qui a pu par ailleurs utiliser des librairies qui font référence telles que scikit-learn, ne sera pas dépaysé lorsqu’il aura à travailler avec Keras. L’accès aux fonctionnalités de Tensorflow devenant transparentes, il pourra se focaliser sur la compréhension des méthodes.
Ce tutoriel a pour objectif la prise en main des outils. Pour aller à l’essentiel, nous implémenterons des perceptrons simples et multicouches dans des problèmes d’analyse prédictive. Ayant déjà nos repères concernant ces méthodes, nous pourrons nous consacrer pleinement à l’assimilation du mode de fonctionnement du tandem Tensorflow - Keras. Les supports de cours consacrés aux méthodes de Deep Learning suivront.
Mots-clés : deep learning, package keras, package tensorflow, python, anaconda, perceptron simple, perceptron multicouche
Didacticiel : Tensorflow Keras sous Python
Données et programmes : 2D et wine
Références :
Tutoriel Tanagra, "Paramétrer le perceptron multicouche", avril 2013.
Tutoriel Tanagra, "Deep Learning - Tensorflow et Keras sous R", avril 2018.
Machine learning avec caret
2018-04-05 (Tag:6467176549556023893)
La profusion des packages est à la fois une force et une faiblesse de R. Une force parce que cette richesse permet de couvrir une très large fraction de la pratique des statistiques et du machine learning. Aujourd’hui, face à tout type de problème, la première question que l’on se pose est : “est-ce qu’il n’y a pas déjà un package qui permet de le faire simplement ?”. Mais c’est aussi une faiblesse parce qu’il y a une très forte hétérogénéité des pratiques et modes opératoires des packages. Et la documentation n’est pas toujours explicite malheureusement. Il m’arrive d’aller voir dans le code même pour comprendre réellement ce qui est implémenté. L’affaire se corse d’autant plus que nous devons souvent combiner (jongler entre) plusieurs packages pour mettre en place une analyse complète.Le package “caret” (Classification And REgression Training) est une librairie pour R. Il couvre une large fraction de la pratique de l’analyse prédictive (classement et régression). Un peu à la manière de “scikit-learn” pour Python, il intègre dans un ensemble cohérent les étapes clés de la modélisation : préparation des données, sélection, apprentissage, évaluation. La standardisation des prototypes des fonctions d’apprentissage et de prédiction notamment permet de simplifier notre code, facilitant les tâches d’optimisation et de comparaison des modèles.
Dans ce tutoriel, à partir d’un exemple d’identification de “spams”, nous montrons quelques facettes du package “caret”.
Mots-clés : analyse prédictive, classement, régression, régression logistique, svm, support vector machine, optimisation des paramètres, techniques de rééchantillonnage, validation croisée, courbe lift, courbe roc
Didacticiel : Machine learning avec "caret"
Données : spam_caret.txt
Référénces :
Max Kuhn, "The caret Package", 2017.
ACP sous Excel avec Xnumbers
2018-03-29 (Tag:2366102702097894395)
Tout le monde l’a bien compris, le tableur est pour moi avant tout un outil pédagogique pour l’enseignement de la statistique et du data mining. Les étudiants ne peuvent pas entrer des commandes ou cliquer frénétiquement au petit bonheur la chance. Ils doivent regarder de près les formules pour pouvoir les comprendre et les reproduire. Il n’y a pas mieux pour les amener à décortiquer les différentes étapes du calcul quelle que soit la méthode étudiée.Nous avions analysé la Régression Linéaire Multiple sous Excel récemment (Mars 2018). Dans ce tutoriel, nous explorons la mécanique d’une autre méthode phare de la data science (voir Top Data Science and Machine Learning Used in 2017) : l’analyse en composantes principales (ACP). J’en profiterai pour présenter Xnumbers, une librairie particulièrement performante pour le calcul scientifique sous Excel. Elle nous sera utile en particulier pour la factorisation des matrices à l’aide de la décomposition en valeurs singulières.
Autoformation avec swirl
2018-03-27 (Tag:2347299627991239136)
L’autoformation est un des leviers essentiels de notre progression. J'essaie de contribuer moi-même à mon échelle à travers les supports de cours et les tutoriels. Une voie alternative est le tutoriel où on guide explicitement l'apprenant avec des systèmes de questions-réponses et des exercices contrôlés.Le package swirl pour R fait partie de cette seconde catégorie. Une ancienne du Master SISE qui assure des formations sous R me l'a indiqué. Je la remercie pour cela. Malgré le temps que je passe sur le web à scruter ce qui se fait, beaucoup de choses m'échappent. Elle m'indiquait qu’elle l’utilisait avec succès pour ses séances de cours. Bien évidemment que je me suis rué dessus pour voir un peu ce qu'il en était, et le parti que je pourrais en tirer pour mes propres enseignements.
Dans ce tutoriel, nous essaierons de faire le tour de l'outil pédagogique en montrant son mode de fonctionnement sur un exemple de séance consacrée à la régression linéaire multiple. Nous en profiterons pour regarder un peu sous le capot et voir les éléments constitutifs des cours.
Mots-clés : autoapprentissage, autoformation, package R, logiciel R, régression linéaire multiple
Didacticiel : Apprendre R, sous R
Références :
Swirl : Learn R, in R -- http://swirlstats.com/
Requêtes avec jointures sous R
2018-03-23 (Tag:7441045152336310267)
Dans ma pratique usuelle, lorsque je dois traiter des bases multi-tables dans un processus de modélisation, j’effectue une partie du pre-processing avec des SGBD (système de gestion de base de données). Avec le langage SQL (structured query language), on y est à l’aise pour effectuer des requêtes mettant en œuvre des jointures complexes entre plusieurs sources. Au final, une table unique propice à l’analyse est produite, que j’importe ensuite dans le logiciel d’analyse statistique, que ce soit R ou Python.Cette approche n’est pas toujours adaptée lorsque les sources initiales sont susceptibles de mises à jour fréquentes. Une modification des données nécessiterait la ré-exécution des requêtes en amont avant de pouvoir relancer le processus de modélisation. Dans ce cas, il est plus judicieux d’intégrer le code de la phase de requêtage dans le programme réalisant le traitement statistique.
Dans ce tutoriel, nous étudions les différentes solutions à notre disposition sous R pour effectuer des requêtes avec jointures. Elles ont toutes permis de répondre au cahier des charges, avec plus ou moins de facilité. Finalement, il nous appartient de choisir celle qui est la plus adaptée par rapport à notre cahier des charges.
Mots-clés : requêtes, jointures, SQL, package dplyr, fusion, tables, package sqldf
Didacticiel : Requêtes avec jointures
Données : Movies Dataset
Références :
Package "sqldf" ; package "dplyr".
Régression linéaire sous Excel
2018-03-16 (Tag:7645419652095348638)
Dans ce tutoriel, nous reprenons à partir d’un exemple traité sous Excel les principaux concepts présentés dans les documents accessibles sur ma page de cours d’Econométrie. Deux ouvrages en particulier seront mis à contribution (voir Références du document). Les principales formules seront explicitées pour chaque calcul. Elles seront mises en relation avec les opérations sous Excel. Puisque nous traitons de la régression linéaire multiple, nous ferons un usage intensif des fonctions matricielles du tableur.Mots-clés : régression linéaire simple et multiple, excel, droitereg, fonctions matricielles
Didacticiel : Régression sous Excel
Classeur Excel : Données "cigarettes"
Références :
Cours Économétrie - Modèles linéaires
Tutoriel Tanagra, "Classeur Économétrie", avril 2015.
Panne partielle du serveur Eric
2018-03-14 (Tag:7919121866711822619)
Depuis le 12 mars 2018 à 15h11, le serveur eric.univ-lyon2.fr utilise un certificat de sécurité invalide. Les accès en https nécessitent l'ajout d'une exception de sécurité. Il n'y a aucune crainte à avoir.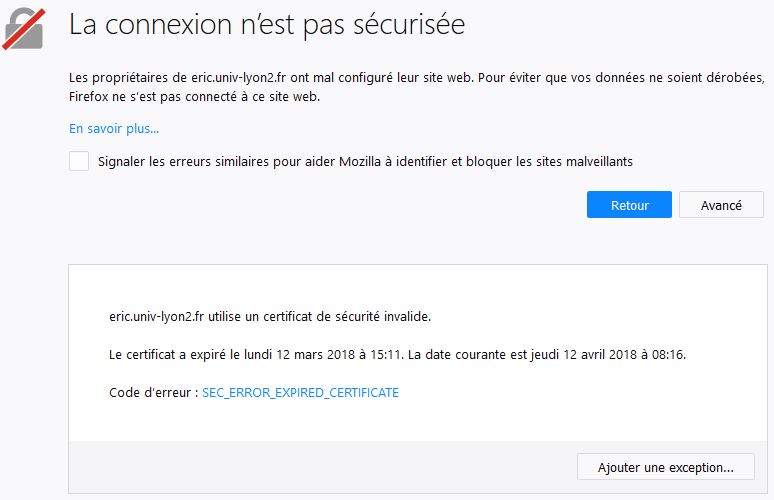
Je ne sais pas quand ce problème sera résolu.
Pour l'heure, la solution la plus simple consiste à modifier manuellement les adresses https en http.
Je suis désolé de ce désagrément.
Ricco.
Stratégies d'échantillonnage pour la modélisation
2018-02-21 (Tag:1946325645275759775)
Ce tutoriel fait suite au support de cours consacré aux algorithmes d'échantillonnage. Nous nous y intéressions en particulier aux stratégies d'échantillonnage pour la modélisation prédictive.Dans ce document, nous étudions expérimentalement le comportement des deux stratégies décrites dans le support. L'approche "random sampling" consiste à démarrer à partir d'une taille d'échantillon définie a priori, puis de l'augmenter graduellement tout en surveillant les performances en test (taux d'erreur). La méthode "windowing" procède du même principe mais cherche à sélectionner judicieusement les observations additionnelles à chaque étape pour améliorer la convergence.
Nos algorithmes et bases de référence seront respectivement l'analyse discriminante linéaire et les données WAVEFORM bien connus des data scientists. L'étude a été menée sous R. Mais le portage du code dans d'autres langages comme Python ne pose aucun problème conceptuel.
Mots-clés : échantillonnage, random sampling, windowing, apprentissage supervisé
Document : Stratégies d'échantillonnage pour la modélisation
Données : waveform dataset
Références :
Tutoriel Tanagra, "Algorithmes d'échantillonnage", février 2018.
Algorithmes d'échantillonnage
2018-02-14 (Tag:4422736075243049219)
La volumétrie est un des enjeux clés du big data analytics. Des technologies spécifiques sont développées à cet effet. Mais d’autres stratégies existent. L’échantillonnage en est une. Dans le cadre de l’apprentissage supervisé par exemple, l’idée serait de modéliser à partir d’une fraction des données, choisies plus ou moins judicieusement, tout en s’assurant un niveau de performances équivalent au modèle qui aurait été élaboré à partir de la totalité des observations.Mais avant d’en arriver à ce stade, il faut déjà pouvoir extraire l’échantillon à partir des données initiales. Ce support présente différents algorithmes permettant de traiter un fichier texte CSV (comma-separated value) de grande taille en accès séquentiel qu’il n’est pas possible de charger entièrement en mémoire vive. Deux grandes variantes sont explicitées : la première, plus simple, suppose connue la taille de la base initiale ; la seconde, nécessitant le chargement en mémoire de l’échantillon ou l’utilisation d’une structure intermédiaire autorisant un accès indexé, traite des fichiers où le nombre de lignes n’est pas connu à l’avance.
Des exemples de codes sources en R et Python permettent d’illustrer concrètement les solutions.
Mots-clés : échantillon, méthode de sélection rejet, reservoir sampling, fichier CSV, fichier texte avec séparateur tabulation, modélisation prédictive, logiciel R, python
Support de cours : Algorithmes d'échantillonnage
Références :
Wikipedia, "Reservoir sampling".
Master SISE - Remise à niveau - Python Statistique
2018-02-03 (Tag:6951142909680883833)
Le temps des recrutements pour le Master SISE va commencer bientôt. Le programme de remise à niveau pour les candidatures externes acceptées est étoffé par un chapitre consacré à Python.L’objectif est de familiariser l’étudiant avec la manipulation des données, la réalisation des calculs statistiques simples (statistiques descriptives) ou un peu plus poussées (classification automatique, clustering). Ces exercices visent aussi à introduire quelques packages Python fondamentaux, indispensables au data scientist (pandas, numpy, scipy, matplotlib).
A la sortie, l’étudiant, j’espère en tous les cas, sera fin prêt pour suivre les enseignements où nous, mes collègues et moi-même, utilisons intensivement Python, souvent en tandem avec R (j'utilise indifféremment l'un ou l'autre pour mes cours [data mining, text mining, web mining], j'avertis les étudiants un peu avant la séance simplement pour qu'ils puissent se préparer).
Document principal : Python Statistique
Outils : Anaconda Python
Exercice 1 : Pandas, manipulation des données (Produits)
Exercice 2 : Pandas, quelques traitements (Census)
Exercice 3 : Scipy, statistiques simples et avancées (Iris)
R ou Python, il faut choisir ?
2018-01-18 (Tag:7175021768317219451)
Une bonne manière de gâcher un repas entre informaticiens est de lancer un débat sur le meilleur langage de programmation (vécu). J’imagine qu’on aura sûrement la même chose si l’on essaie de comparer R et Python dans un dîner entre data scientist (je préfère ne pas essayer).Mais pourquoi les opposer finalement ? Ne peut-on pas avoir fromage et dessert au même repas (pour poursuivre dans la parabole gastronomique) ? On peut former les étudiants à ces deux outils simultanément. Je les utilise moi-même de manière indifférenciée dans mes travaux dirigés en Master SISE. Et on s’en sort plutôt bien (je trouve).
C’est le discours que je vais tenir lors de la présentation au Meetup de l’association Lyon Data Science auquel je participerai ce vendredi 19 janvier 2018. En m’appuyant sur ma propre expérience d’enseignant-chercheur et de concepteur de logiciels gratuits à visée pédagogique, je vais essayer de retracer le cheminement intellectuel qui m’a amené à utiliser intensivement à la fois R et Python dans mes enseignements actuels.
Voici le résumé et le support de la présentation.
Titre : « Place de R et Python dans les formations en data science »
Résumé : La science des données n’échappe pas à la vague des logiciels libres. Depuis plusieurs années, les deux outils les plus populaires auprès des data scientists sont R et Python selon le sondage annuel du site KDnuggets (Mai 2017). Certes, les licences présentent des subtilités un peu difficiles à suivre parfois, mais elles respectent deux caractéristiques fondamentales de mon point de vue : nous avons accès au code source, nous garantissant un certain contrôle sur les calculs et opérations réellement effectuées ; ils sont accessibles et exploitables gratuitement, quels que soient les contextes d’utilisation. De fait, l’adoption de R et Python dans les formations en data science semble évidente. Pourtant, il faut être prudent, ne serait-ce que par principe. Former les étudiants à un outil n’équivaut pas à utiliser un ou des outils pour former les étudiants. Leur usage doit s’inscrire dans une démarche pédagogique cohérente qui peut s’étendre sur plusieurs années. Il ne doit pas reposer sur des effets de modes ou des popularités qui peuvent être parfois éphémères.
Dans mon exposé, je m’appuierai sur ma propre expérience d’enseignant d’une part, de créateur de logiciels de data mining gratuits à vocation pédagogique (SIPINA, TANAGRA) d’autre part, pour essayer de cerner les attentes que l’on peut avoir vis-à-vis des outils dans les cours de statistique et de data science. L’élaboration de TANAGRA (2004) en particulier aura été l’occasion de mener une réflexion approfondie sur les caractéristiques clés que doivent présenter les logiciels pour l’enseignement. Je reviendrai rapidement dessus pour mieux rebondir sur la définition d’un cahier des charges actualisé où les compétences en programmation et les accès aux API tiennent une place importante. Dans ce contexte, que l’on pourrait qualifier de Big Data, R et Python se démarquent réellement et justifient pleinement l’investissement que l’on pourrait leur consacrer au sein des formations. D’autant plus que leur présence de plus en plus marquée dans les offres d’emploi qui nous concernent directement est une autre raison qui ne peut pas nous laisser insensible. Je m’appuierais sur une étude récente réalisée par un groupe d’étudiants du Master SISE pour essayer de cerner les mots clés importants qui caractérisent les annonces dans nos domaines en France. Python y occupe un espace assez singulier.
Plusieurs démonstrations mettant en oeuvre R et Python me permettront d'appuyer mon propos.
Support : R et Python dans les enseignements
Vidéo : Meetup à la Tour du Web
Mots-clés : data science, enseignement, formation, master data science, science de données, big data, big data analytics, logiciels libres, r, python
Ressources partagées - Apprentissage supervisé
2018-01-06 (Tag:2511374747964972023)
Antoine Rolland, un collègue qui officie à l’IUT STID de l’Université Lyon 2, m’a demandé de contribuer à la revue "Statistique et Enseignement". J’ai accepté parce que c’est lui qui me l’a demandé. Aussi parce qu’il s’agit d’une revue librement consultable, gratuitement, sans aucune contrainte.Antoine m’a proposé de faire un descriptif commenté d’un de mes supports de cours. Ca m’a un peu titillé l’esprit. Faire l’exégèse de son propre travail n’est jamais facile. J’ai eu un peu de mal à démarrer j’avoue, puis j’ai eu beaucoup de plaisir à le faire une fois lancé. Comme tout enseignant chercheur, je parle beaucoup durant un cours, sans y penser réellement de manière explicite en amont. J’aborde tout un tas de sujets en relation d’une part avec mon expérience ou même l’actualité, d’autre part avec le profil des étudiants que j’ai en face de moi. Heureusement d’ailleurs, sinon je ne vois pas très bien l’intérêt pour nous de faire des cours magistraux (CM), à ânonner béatement la même chose tous les ans en lisant les slides. Je pense même que l’interaction est la seule justification valable encore aujourd’hui de l’existence des CM. Autrement, il y a pléthore de supports sur le web, y compris des cours en vidéo très bien faits de collègues très compétents. Décalquer avec plus ou moins de bonheur ce que dit tout le monde n’a pas vraiment d’intérêt.
J’ai choisi de travailler sur mon support de cours dédié à l’Introduction de l’apprentissage supervisé. Il s’agit d’un CM crucial où j’essaie de faire appréhender aux étudiants les notions clés de l’analyse prédictive. Chaque slide est décrit de manière approfondie, avec les commentaires qui peuvent me venir à l’esprit, les points fondamentaux qu’il faut absolument souligner pour faire comprendre aux étudiants les fondements du thème étudié, les possibles digressions qui permettent d’élargir mon propos, les réactions attendues ou inattendues du public selon leur culture et leur parcours antérieur. En rédigeant l’article, je me suis rendu compte que ces éléments font tout le sel d’un exposé. Pour nous enseignants-chercheurs, il reste encore un petit espace pour les CM en présentiel devant les étudiants.
Document : Ricco Rakotomalala, « Ressources partagées – Introduction à l’apprentissage supervisé », Statistique et Enseignement, 8(2), 43-58, décembre 2017.
Bonne année 2018 - Bilan 2017
2018-01-02 (Tag:1487879846125479265)
L’année 2017 s’achève, 2018 commence. Je vous souhaite à tous une belle et heureuse année 2018.Un petit bilan chiffré concernant l'activité organisée autour du projet Tanagra pour l'année écoulée. L'ensemble des sites (logiciel, support de cours, ouvrages, tutoriels) a été visité 222.293 fois en 2017, soit 609 visites par jour.
Il y a une forte diminution de la fréquentation par rapport à l’année dernière (721 visites par jours en 2016), dû en partie aux pannes répétées de notre serveur. Je m’en excuse auprès des internautes qui, pendant plusieurs périodes, n’ont pas pu accéder aux supports et tutoriels.
Depuis la mise en place du compteur Google Analytics (01 février 2008), le groupe de sites a été visité 2.333.371 fois, soit 644 visites par jour.
Les visiteurs viennent en majorité de la France (52%), du Maghreb (16%) et de l’Afrique francophone. Les pages de supports de cours ont toujours autant de succès, en particuliers ceux dédiés à la Data Science et à la programmation (R et Python).
39 supports de cours et tutoriels supplémentaires ont été postés cette année : 18 en français, 21 en anglais.
En cette nouvelle année, je souhaite le meilleur à tous les passionnés de Data Science, de Statistique et d’Informatique.
Ricco.
Diaporama : Tanagra - Bilan 2017
LinkedIn avec Python
2017-12-17 (Tag:3075570128898707548)
LinkedIn est un réseau social professionnel. Il permet de mettre en ligne notre CV, établir des contacts, entretenir des relations, accéder ou diffuser des offres d’emploi, chercher de l’aide, indiquer ses aspirations, etc. C’est un instrument privilégié pour construire notre identité virtuelle professionnelle. L’outil est particulièrement prisé des recruteurs.Dans ce tutoriel, nous étudierons comment écrire un programme en Python permettant d’accéder aux fonctionnalités de l’API LinkedIn via le package python-linkedin. J’ai utilisé un compte LinkedIn fictif. Il s’agit avant tout de montrer la faisabilité de la chose. Nous nous attarderons sur deux étapes essentielles du dispositif : l’activation de l’API LinkedIn qui n’est pas évidente ; le package n’est pas inclus dans la distribution standard Anaconda (Python 3.6) que j’utilise, il m’a fallu l’installer et surtout le configurer (l'upgrader) spécifiquement pour qu’il fonctionne.
Mots-clés : linkedin, api linkedin, python, réseau social professionnel, package python-linkedin
Document : API LinkedIn - Python
Références :
Vantansever O., "Python-linkedin 4.0", https://pypi.python.org/pypi/python-linkedin/4.0
Google Analytics avec R
2017-12-03 (Tag:5640945788359221641)
Google Analytics est un service de mesure d’audience des sites Web. On parle de Web Analytics. L’objectif est d’apprécier la fréquentation. Mais au-delà du simple comptage, et c’est ce qui fait réellement sa force, l’outil propose de nombreuses possibilités d’études qui permettent de mieux comprendre le comportement des visiteurs. Ainsi, en identifiant les pages les plus regardées, les pages d’entrées, en analysant les trajectoires, en ventilant les accès selon les pays, etc., il nous permet de mieux organiser notre site de manière à répondre plus précisément aux attentes des internautes.RGoogleAnalytics est un package R permettant d’accéder aux données Google Analytics via une API (interface de programmation applicative). La librairie nous donne accès aux informations stockées par le service, tant en termes de fréquentation brute qu’en termes d’analyses préprogrammées. Ce document décrit l’utilisation sous R des fonctionnalités du package RGoogleAnalytics à partir des données du site Tanagra au sens large (pages du logiciel, mais aussi les pages relatives aux supports de cours, tutoriels, etc.) sur le mois de novembre 2017.
Mots-clés : logiciel R, google analytics, API, package rgoogleanalytics, analyse des fréquentations web, mesure d'audience, analyse factorielle des correspondances, afc, fréquentation du site tanagra
Document : R et Google Analytics
Données et programme : Prog. R et résultats des requêtes
Références :
Pearmain M. et contributeurs, "RGoogleAnalytics: R Wrapper for the Google Analytics API", August 2014.
Les classes R6 sous R
2017-11-18 (Tag:1740915390082425686)
Ce support fait suite à celui consacré aux mécanismes de classes sous R (S3, S4 et RC). Il présente le package R6 qui propose un cadre rigoureux pour l’implémentation des objets. La majorité des dispositifs présents dans les autres langages de programmation sont disponibles (C# par exemple, que j’enseigne par ailleurs en Master 2).Nous aborderons tour à tour les notions de définition des membres d’une classe, l’accès aux champs au sein des méthodes, la portée des membres, la définition des propriétés (similaire à ce qu’on peut avoir en Delphi ou en C# justement), la hiérarchie de classes et l’héritage.
Le modèle R6 est manifestement bien conçu. Reste à savoir s’il arrivera à s’imposer au sein de la communauté des programmeurs R. Les habitudes (le modèle S3 notamment) bien ancrées sont souvent difficiles à bousculer. L’avenir nous le dira.
Mots clés : programmation objet, classes, héritage, portée, propriétés, méthodes, membres, R6
Support de cours : Les classes R6 sous R
Références :
Winston Chang, "Introduction to R6 classes", 2017.
Ateliers : Outils de la Data Science
2017-11-13 (Tag:6740887563355059935)
C’est devenu un rituel maintenant. J’ai demandé aux étudiants du Master SISE de cette année d’assurer des ateliers techniques destinés à former leurs propres collègues sur différents outils en lien avec la data science.J’ai fait le choix de trois logiciels : SCILAB, pour qu’ils puissent se familiariser avec les environnements et langages de type Matlab ; SPAD, qui est une référence française, en particulier en ce qui concerne les composants d’analyse de données, bonifiés avec la version 9 ; SQL, qui est un langage incontournable dans notre domaine, les "sondages" de KDnuggets sur les soft de la data science le confirment tous les ans.
Les supports ci-dessous comprennent : les cours de présentation, les labs (travaux pratiques), les corrigés et les tutoriels vidéo. Tout est perfectible bien sûr. On peut toujours faire les choses mieux ou différemment ici ou là. Mais pour avoir moi-même assisté aux cours et aux labs (moi aussi, j’ai besoin de me former…), je peux assurer que chaque séance correspond à un gain en compétences substantiel.
Merci aux étudiants pour cet excellent travail qui profite à tout le monde.
| Thèmes | Présentations | Exercices | Corrigés | Tutoriels |
|---|---|---|---|---|
| Scilab 1 | | | | |
| Scilab 2 | | | | |
| Spad 1 | | | | |
| Spad 2 | | | | |
| Sql 1 | | | | |
| Sql 2 | | | | |
Note : Mettez en HD (haute définition) les vidéos sur YouTube pour un meilleur confort de visualisation.
Mécanisme des classes sous R
2017-11-06 (Tag:1054670054399089379)
R est un vrai langage de programmation qui propose plusieurs mécanismes de gestion des classes. Dans ce support, nous présentons plusieurs approches disponibles dans R.Le modèle S3, très populaire parce que le plus ancien et le plus simple, peut dérouter les informaticiens car elle n’est pas vraiment conforme aux schémas de la POO (programmation orientée objet) traditionnelle. Les modèles S4 et RC (reference classes) proposent des solutions plus rigoureuses, mais introduisent des pratiques qui sont susceptibles de décontenancer les férus de R qui ont pris l’habitude de rédiger leur code d’une certaine manière (calée sur le modèle S3).
Quelle que soit la solution adoptée, l’objectif est de pouvoir produire du code R efficace, bien organisé, nous facilitant au mieux la maintenance corrective et évolutive de nos programmes.
Mots clés : programmation objet, langage R, S3, S4, RC, classes, héritage
Support de cours : Mécanisme des classes sous R
Serveur Eric en panne
2017-11-04 (Tag:8760479072409070378)
Vous êtes plusieurs à me signaler que les tutoriels et supports de cours ne sont plus accessibles ces derniers jours. Oui, je l’avais constaté également.Durant cette fin de semaine des vacances de la Toussaint, je doute fort qu’une solution soit apportée. Il faut prendre notre mal en patience. Lundi aura lieu la reprise, il y aura enfin du personnel pour résoudre le problème j’espère.
Je suis désolé des désagréments que cela peut vous occasionner. Je les subis autant que vous.
Bien cordialement,
Ricco (04/11/2017).
PS : Le serveur du Laboratoire Eric est de nouveau fonctionnel ce matin du 06/11/2017 à 8h57.
Big Data - Panorama et outils
2017-10-11 (Tag:2980098090944154797)
Une introduction au Big Data en 20 minutes est toujours un peu compliqué. Je vais donc aller à l’essentiel pour orienter par la suite mon propos vers le big data analytics, qui est mon domaine de prédilection. Je mets en ligne ici le support que j’utiliserai. Il vaut surtout pour les nombreux liens qu’il contient. J’ai essayé de faire la part belle aux exemples d’applications.
Document : Big Data - Panorama et outils
Références :
Panne résolue
2017-08-02 (Tag:2028352897104253370)
Bonjour,Il semble que la panne ait été résolue depuis hier "01 août 2017" en journée.
Encore désolé pour la gêne occasionnée, et en espérant que la continuité du service sera assurée tout au long de l’été.
Cordialement,
Ricco (02/08/2017)
Panne serveur de fichiers
2017-07-27 (Tag:6048660170121945062)
Depuis quelques jours (depuis le 24/07/2017 en fin de journée approximativement), le serveur du Laboratoire Eric qui héberge les fichiers du projet Tanagra (logiciel, ouvrages, supports de cours, tutoriels...) est inactif. Suite à une panne de courant, il n’y a personne pour redémarrer le serveur durant la période estivale. Je l'aurais bien fait, mais le serveur est hélas situé dans une salle à laquelle je n’ai pas accès.Donc on attend. Et ça risque de durer un peu, la fermeture estivale dure un mois, notre établissement rouvre officiellement ses portes le 21 août ! Je suis désolé pour les internautes qui travaillent à partir des documents que je mets en ligne. Je le suis d’autant plus que ce second incident intervient après un fonctionnement perturbé au mois de Juin 2017 durant une douzaine de jours à cause d’un certificat de sécurité invalide. Ces difficultés sont totalement indépendantes de ma volonté et je ne peux rien faire pour y remédier. Mis à part la patience.
Comme vous êtes plusieurs à vous manifester, je préfère prendre les devants pour vous informer. Dès que tout sera rentré dans l’ordre, je vous avertirai.
Cordialement,
Ricco (27/07/2017).
Comprendre la taille d'effet (effect size)
2017-05-06 (Tag:7794333669915436362)
La taille d’effet est un indicateur permettant de rendre compte de l’intensité d’un phénomène statistique : l’écart entre des moyennes ou des proportions, les liaisons entre les variables, etc. Dans ce support, nous nous plaçons dans le cadre de l’interprétation des partitions issues d’un processus de classification automatique (clustering). Il s’agit d’identifier les caractéristiques sous-jacentes à la formation des groupes, à travers les comparaisons de moyennes pour les variables quantitatives, les comparaisons des fréquences des modalités pour les variables qualitatives. Pour faciliter la lecture, il est intéressant de pouvoir hiérarchiser les variables pour distinguer celles qui ont la plus forte influence. Un indicateur statistique simple à calculer et interprétable est nécessaire à cet égard.La mesure « valeur test » se révèle particulièrement intéressante dans ce contexte. Elle est disponible dans des logiciels et packages de R. J’ai moi-même écrit un tutoriel sur ce sujet. Elle permet de trier les variables et désigner celles qui sont les plus qualifiantes. Elle présente néanmoins un défaut qui pose problème dans le traitement des données massives. En effet, sa valeur augmente mécaniquement avec l’effectif absolu des groupes, et non avec leur effectif relatif. De fait, sur les grandes bases de données, la hiérarchie des variables n’est certes pas remise en cause, mais elles paraissent toutes significatives au regard des seuils usuels des tests statistiques, laissant à penser qu’elles pèsent toutes notoirement dans la constitution des groupes. La taille d’effet, insensible à la taille des échantillons, permet de dépasser cet inconvénient.
A travers la notion de taille d’effet, nous proposons une analyse en deux temps pour l’interprétation des résultats d’un clustering : (1) une caractérisation de la partition à travers un indicateur exprimant la proportion de variance expliquée ; (2) une caractérisation des groupes via un indicateur basé sur la corrélation.
Mots-clés : taille d'effet, effect size, d de Cohen, g de Hedges, rapport de corrélation, coefficient de corrélation bisériale ponctuelle, h de Cohen, v de Cramer, khi-2, phi, clustering, classification automatique, k-means, cah
Document : Taille d'effet
Références :
Cohen J., "Statistical Power Analysis for the behavioral sciences", Psychology Press, 1988.
Morineau A., "Note sur la caractérisation statistique d’une classe et les valeurs-tests", in Bulletin Technique du Centre de Statistique et Informatique Appliquées, 2(1-2), pp. 20-27, 1984.
Tutoriel Tanagra, "Interpréter la valeur test", avril 2008.
Tutoriel Tanagra, "Clustering : caractérisation des classes", septembre 2016.
De la statistique à la data science
2017-04-29 (Tag:21126555964129162)
Comme expliqué dans un des posts précédents, j’avais participé récemment à la conférence "De la statistique à la data science" à l’occasion des 45 ans du DUT STID de Vannes. On était plusieurs à présenter. Les vidéos sont aujourd’hui en ligne, je me fais un plaisir de les partager sur ce blog.| Auteur - Titre | Présentation |
|---|---|
| Patrice Kermorvant. Introduction de la journée. | |
| René Lefebure. Jurassic Data. | |
| Ricco Rakotomalala. Open source et data science. | |
| Stéphane Tufféry. Deep Learning. | |
| COHERIS SPAD. Nouveautés du logiciel SPAD V9. | |
| DATAIKU. Data science studio. | |
Pour une fois que je sortais de mon environnement habituel (ça n'arrive vraiment pas souvent), il me tenait à cœur de mettre en valeur le travail de nos étudiants.
Références / Slides : Open source et data science
Probabilités et quantiles sous Excel, R et Python
2017-04-26 (Tag:5468402628662753184)
J’utilise indistinctement Excel (en conjonction avec Tanagra ou Sipina), R et Python pour mes travaux dirigés (TD) de data mining et de statistique à l’Université. Souvent, je demande aux étudiants de procéder à des tests d’hypothèses pour éprouver la significativité d’un ou plusieurs coefficients dans un modèle prédictif, ou encore pour calculer les intervalles de confiance de prédiction en régression, etc.Nous sommes sur machine, il est bien évidemment hors de question d’aller consulter les tables statistiques pour obtenir les quantiles ou les p-value des lois de probabilités couramment utilisées. Dans ce tutoriel, je présente les principales fonctions pour les lois normales, Student, KHI-2 et Fisher. Je me suis en effet rendu compte que les étudiants avaient parfois du mal à faire la correspondance entre la lecture des tables et l’utilisation des fonctions qu’ils ont du mal à identifier dans les logiciels. C’est aussi l’occasion pour nous de vérifier les équivalences entre les fonctions proposées par Excel, R (package stats) et Python (package scipy). Ouf ! Du moins sur les quelques exemples illustratifs de notre document, les résultats sont parfaitement cohérents.
Mots-clés : excel, r, package stats, python, package scipy, probabilités, p-value, p-valeur, valeur-p, quantile, fractile, loi normale, loi de student, loi du khi-2, loi de fisher
Document : Calcul des probabilités et quantiles
Détection de communautés sous Python
2017-04-11 (Tag:2278915138626954759)
La détection de communautés dans les réseaux sociaux a pour objectif d’identifier les groupes d’individus entretenant des relations privilégiées. Ce thème connaît une recrudescence d’intérêt ces dernières années avec le développement des médiaux sociaux (Twitter, Facebook, etc.), multipliant les opportunités d’interactions entre les individus. Un réseau social est souvent représenté par un graphe où les sommets (nœuds) représentent les individus, les liens qu’il entretiennent sont matérialisés par les arêtes. Une communauté correspond à un groupe de nœuds présentant une forte densité de connexions.Ce tutoriel vient en complément de mon support de cours accessible en ligne qui nous servira de référence. Nous nous plaçons dans une situation particulière où le graphe est non orienté, les liaisons entre les individus – lorsqu’elles existent – sont symétriques et non pondérées c.-à-d. les connexions ont tous la même intensité.
Nous travaillerons sous Python et nous utiliserons le package igraph.
Mots clés : web mining, fouille du web, réseaux sociaux, communautés, python, package igraph
Document : Détection de communautés sous Python
Données : Données Karaté et code prog. Python
Références :
Rakotomalala R., "Détection de communautés - Diapos", mars 2017.
Open source et data science
2017-03-29 (Tag:5124327454488306336)
Je dois faire un exposé le 31 mars 2017 à l’occasion des 45 ans du DUT STID de Vannes. L’idée est de faire un état de l’art sur les logiciels open source de data science.A priori, le schéma est très simple : il faut faire un travail de recensement dans un premier temps, puis établir une série de critères qui permettent de comparer les outils. De nombreuses publications portant sur le même sujet ont adopté ce plan. Dans le cas présent, l’affaire est un peu plus difficile parce que je ne dispose que de 30 minutes. Bouffer le temps de présentation par une longue litanie des outils peu ou prou connus, ou par des tableaux au kilomètre, forcément confus parce que trop larges, ne me paraît pas très judicieux.
J’ai donc préféré adopter une approche plus dynamique : cadrer effectivement le sujet en présentant les critères important permettant de les caractériser, parler de deux études disponibles sur le site KDnuggets qui donnent une photographie assez précise du positionnement des différentes outils disponibles, et faire un focus sur R et Python qui sont incontournables aujourd’hui en montrant ce que l’on peut faire avec ces logiciels à travers les projets POC réalisés par mes étudiants du Master SISE.
Voici les slides que j’utiliserai le jour dit.
Mots clés : logiciel, data science, open source, logiciel r, python, projets étudiants
Document : Open Source et data science
Références :
Master SISE, « Etude des logiciels de data science », octobre 2016.
Piatetsky G., « R, Python Duel As Top Analytics, Data Science Software », KDnuggets 2016 Software Poll Results, June 2016.
Piatetsky G., « Gartner 2017 Magic Quadrant for Data Science Platforms: gainers and losers », KDnuggets, February 2017.
Détection de communautés - Diapos
2017-03-16 (Tag:7725326059341656867)
La détection de communautés a pour objectif de mettre en évidence des groupes d’individus qui se forment implicitement dans les réseaux sociaux. Les individus à l’intérieur d’une communauté interagissent plus fortement – et donc tissent des liens plus affirmés – entre eux qu’avec les autres. Le thème a connu un regain d’intérêt spectaculaire ces dernières années avec la multiplication des médias sociaux. Les finalités sont multiples : identifier les profils types, ajuster les recommandations, réaliser des actions ciblées, réorganiser une structure, etc.Ce support de cours décrit les tenants et aboutissants de la détection de communautés. Plusieurs algorithmes simples sont décrits. Les approches décrites s’appuient sur la représentation en graphes des réseaux sociaux.
Mots clés : web mining, communautés, réseaux sociaux, médias sociaux, algorithmes divisifs, algorithmes agglomératifs, multidimensional scaling, matrice d'adjacence
Document : Détection de communautés dans les réseaux sociaux
Références :
Tang L., Liu H., « Community detection and mining in social media », Morgan and Claypool Publishers, 2010 (http://dmml.asu.edu/cdm/).
Analyse de tweets sous R
2017-03-04 (Tag:1136721455977578836)
Twitter est devenu un instrument incontournable de communication pour tous les acteurs sociaux. Les hommes politiques, les sportifs, les dirigeants d'entreprises l'utilisent pour donner la primeur de leur actualité, leurs décisions, leurs actions à venir. Il constitue également une plate-forme d'échange qui permet à tout un chacun d'exprimer son opinion en réaction à une annonce ou à un évènement. Des informations, parfois très importantes, transitent ainsi dans tous les sens, tous les jours, sans que nous saisissions toute la portée de ce déluge de textes qui, parfois, semblent peu cohérents.Dans ce tutoriel, nous montrons comment accéder à des messages liés à un thème choisi sur Twitter. Nous initierons une étude relativement basique des propriétés des tweets dans un premier temps. Nous enchaînerons ensuite sur l'exploitation du contenu des messages. Nous travaillerons sous R en nous appuyant sur le package "twitteR" de Jeff Gentry qui se révèle particulièrement pratique (Package ‘twitteR’).
Mots clés : text mining, fouille de textes, corpus, bag of words, sac de mots, twitter, package twitteR, logiciel R, package tm
Document : Analyse de tweets sous R
Données : Collection de tweets
Références :
Wikipédia, "Twitter".
Jeff Gentry, "Package 'twitteR'".
Python : Manipulations des données avec Pandas
2017-02-21 (Tag:594407616861142837)
La manipulation des données est la base de l’activité du data scientist. Si on ne sait pas charger un fichier, exécuter des restrictions et des projections, réaliser des transformations, croiser les variables, représenter les données à l’aide de graphiques simples, la suite des opérations se révèlera très difficile. Quel que soit notre niveau de connaissances sur les techniques de machine learning, nous serions un peu comme une poule qui a trouvé un couteau : nous savons ce qu’il faut faire, mais nous ne savons pas comment faire. C’est ballot comme dirait toto.Ainsi, dans tous mes enseignements de statistique et de data mining face à un public non statisticien ou data miner (peu au fait des logiciels de data mining), je consacre systématiquement au moins un TD (travaux dirigés) à des exercices de manipulation de données : charger un fichier, réaliser des filtrages, des tris, des recherches, etc. Mes outils privilégiés jusqu’à présent étaient Excel et R. Face à la demande croissante des étudiants, j’ai décidé d’écrire un support décrivant les manipulations basiques des ensembles de données (dataset) sous Python. C’est aussi et surtout l’occasion de faire découvrir la magnifique librairie Pandas, puissante et foisonnante. Un peu trop peut-être. J’ai passé un temps monumental à l’explorer dans tous les sens. Je ne suis pourtant pas sûr d’en avoir mesuré toutes les subtilités à ce jour. Je peux comprendre qu’un néophyte se décourage rapidement face à la documentation en ligne qui est particulièrement touffue. C’est la raison pour laquelle j’ai écrit un support assez basique, schématisant les opérations les plus fréquemment réalisées, au moins pour une première mise en bouche.
Enfin, ce support a été l’occasion d’écrire un document à l’aide du notebook Jupyter. Je le connaissais depuis longtemps. Je n’ai pas été convaincu par le rendu jusqu’à présent. Mais le fait est que j’écrirai de plus en plus de tutoriels pour Python à l’avenir. Je dois explorer cette piste qui me permettrait de réduire le temps de rédaction, exploitable pour R aussi d’ailleurs. Il faut simplement que j’aie une plus grande maîtrise de l’organisation et de la mise en forme du PDF final.
Mots clés : pandas, python, manipulation des données, filtres, tableaux croisés, DataFrame, data.frame, Series, graphiques, matplotlib
Document : Manipulation des données avec Pandas
Données : Données et notebook Jupyter
Références :
Python Data Analysis Library, pandas.
Tutoriel Tanagra, "Manipulation des données avec R", août 2012.
Pandas Documentation, "Comparison with R / R libraries".
Filtrage collaboratif et recommandations - Diapos
2017-02-02 (Tag:6868577023025827955)
Le filtrage collaboratif regroupe l’ensemble des méthodes qui visent à construire des systèmes de recommandation utilisant les opinions, les évaluations et le comportement d’un groupe d’individus (Wikipédia). La vente en ligne – entres autres, on peut penser aussi aux suggestions sur les plateformes de partage de vidéos, etc. – rend ces systèmes indispensables. Nous ne disposons plus d’un vendeur qui va essayer de comprendre nos attentes pour nous aiguiller vers les bons achats (bien que l’on voie maintenant apparaître des guides qui essaient de nous prendre en main sur les sites). Et, d’un autre côté, un expert ne peut pas édicter tous les règles de gestion qui permettrait d’avancer des propositions efficaces sur un site. S’appuyer sur l’expérience commune se révèle être une stratégie féconde.Dans ce support, nous dessinons les tenants et aboutissants du domaine. Nous explicitons la démarche en détaillant concrètement deux approches, l’une centrée utilisateur (ex. client), l’autre centrée item (ex. produit). Nous constatons que des méthodes relativement simples permettent de répondre à un cahier des charges exigeant.
Mots clés : web mining, collaborative filtering, recommendation system, système de recommandation
Document : Filtrage collaboratif et système de recommandation
Références :
Ekstrand M.D., Riedl J.T., Konstan J.A., « Collaborative Filtering Recommender Systems », in Foundations and Trends in Human-Computer Interaction, vol. 4, n°2, p. 81-173, 2011.
Les expression régulières sous R
2017-01-24 (Tag:5646246825691978372)
La manipulation de documents textuels en text mining implique de nombreuses opérations de recherche, de remplacement, de nettoyage, de découpage… Il s’agit donc de pouvoir effectuer des requêtes sur du contenu qui n’est pas structuré comme le serait une base de données.Les expressions régulières constituent un outil privilégié dans ce contexte. Elles correspondent à des modèles (motifs) qui permettent de décrire des ensembles de chaînes de caractères. Les outils tels que grep() ou gsub() de R par exemple savent les mettre à profit pour effectuer des recherches ou des rechercher / remplacer dans les documents. Le dispositif peut s’appliquer au traitement de textes bruts totalement non structurés ; il peut faire merveille également dans l’exploitation des documents semi-structurés tels que les fichiers logs.
Dans ce support de cours, je décris succinctement les idées sous-jacentes aux expressions régulières et les principaux éléments de syntaxe. Un exemple réaliste de recherche dans des SMS possiblement délictueux permet d’appréhender pleinement leur intérêt.
Mots clés : text mining, fouille de textes, expressions régulières, grep, gsub, posix étendu, perl, analyse des fichiers logs
Document : Expressions régulières sous R
Fichiers : Données et programme R
Références :
Zyntrax-Info, "Regular Expressions – User Guide".
Jwang, "Utilisation des expressions régulières sous R".
Fouille d'opinions et analyse des sentiments - Diapos
2017-01-18 (Tag:3040056901209206703)
Savoir ce que pensent les "gens" (électeurs, clients, concurrents, etc.) est fondamental pour les décideurs (partis politiques, entreprise, etc.). Le web 2.0 (on parle aussi de médias sociaux ou de réseaux sociaux numériques) est un terrain privilégié pour recueillir à moindre coût l’opinion et le sentiment de tout un chacun, par rapport à une décision ou un projet politique, par rapport à un produit, etc.Dans ce support de cours, nous décrivons les enjeux et les méthodes de la fouille d’opinions (opinion mining) et, de sa déclinaison la plus usuelle, l’analyse des sentiments (sentiment analysis). Nous sommes bien dans le domaine du text mining puisque nous travaillons à partir de données textuelles. Mais les spécificités du web peuvent amener des points de vue et des outils qui permettent d’enrichir l’analyse. Nous nous attarderons notamment sur la plateforme de microblogage Twitter, support de communication particulièrement populaire aujourd’hui.
Mots clés : text mining, fouille de textes, web mining, opinion mining, sentiment analysis, analyse des tweets
Document : Opinion mining et sentiment analysis
Références :
Aggarwal C., Zhai C., "Mining Text Data", Springer, 2012.
Russell M.A., "Mining the Social Web – Data Mining Facebook, Twitter, Linkedin, Google+, Github, and more", O’Reilly, 2013.
Bonne année 2017 - Bilan 2016
2017-01-05 (Tag:7898149025768866539)
L’année 2016 s’achève, 2017 commence. Je vous souhaite à tous une belle et heureuse année 2017.Un petit bilan chiffré concernant l'activité organisée autour du projet Tanagra pour l'année écoulée. L'ensemble des sites (logiciel, support de cours, ouvrages, tutoriels) a été visité 264.045 fois en 2016, soit 721 visites par jour.
Depuis la mise en place du compteur Google Analytics (01 février 2008), le groupe de sites a été visité 2.111.078 fois, soit 649 visites par jour.
Par rapport à l’année dernière (2015), les visiteurs viennent toujours en majorité de la France (50%), du Maghreb (16%) et de l’Afrique francophone. Les pages de supports de cours ont toujours autant de succès. La page dédiée à la Programmation Statistique sous Python monte en puissance avec 31 visites par jour, mais reste loin de la Programmation R (141 sessions journalières) ou du Data Mining (126). Il reste une marge de progression.
46 supports de cours et tutoriels supplémentaires ont été postés cette année : 36 en français, 10 en anglais (hum… il y a du boulot…). Le programme de remise à niveau pour l’accession au Master SISE a été mon principal projet cet été.
En cette nouvelle année, je souhaite le meilleur à tous les passionnés de Data Science, de Statistique et d’Informatique.
Ricco.
Diaporama : Tanagra - Bilan 2016
Text mining : catégorisation de SMS sous Python
2016-12-31 (Tag:5733803713887666235)
L’objectif de la catégorisation de textes est d’associer aussi précisément que possible des documents à des classes prédéfinies. Nous nous situons dans le cadre de l’apprentissage supervisé, avec une variable cible catégorielle, souvent binaire. La particularité réside dans la nature de la variable prédictive qui est un document textuel. Mettre en œuvre directement les techniques prédictives n’est pas possible, il faut passer obligatoirement par une phase de préparation des données.
La représentation par sac de mots (bag of words) est souvent privilégiée pour ramener la description du corpus de textes en tableau individus (documents) – variables (termes) : on parle de matrice documents termes. Elle est accolée à la variable cible pour former l’ensemble de données. L’affaire est censée être réglée à ce stade puisque nous retrouvons la conformation habituelle des données propice à l’analyse prédictive. Elle ne fait que commencer en réalité car la matrice a pour singularité d’avoir une dimensionnalité élevée (plusieurs milliers de descripteurs) et d’être creuse (beaucoup de valeurs sont nulles). Certaines techniques de machine learning sont plus adaptées que d’autres. La réduction de la dimensionnalité notamment revêt une importance considérable, d’une part pour améliorer les performances, d’autre part pour rendre interprétables les résultats car, au final, au-delà de la prédiction pure, il s’agit aussi de comprendre la nature de la relation entre les documents et les classes.
Dans ce tutoriel, nous décrirons le processus de catégorisation de textes sous Python en exploitant essentiellement les capacités de text mining du package scikit-learn, lequel fournira également les méthodes de data mining (régression logistique). Nous traiterons des SMS à classer en messages « spam » (courrier indésirable, délictueux) ou « ham » (légitime). Le corpus provient de la « SMS Spam Collection v.1 » (Almeida et al., 2011).
Mots clés : text mining, fouille de textes, corpus, bag of words, sac de mots, f1-score, rappel, précision, sélection de variables, logistic regression, scikit learn, python
Document : Identification des spams dans les SMS
Données : Données et programme Python
Références :
Almeida, T.A., Gómez Hidalgo, J.M., Yamakami, « A. Contributions to the Study of SMS Spam Filtering: New Collection and Results », in Proceedings of the 2011 ACM Symposium on Document Engineering (DOCENG'11), Mountain View, CA, USA, 2011.
Excel avancé - Cours et exercices corrigés
2016-12-23 (Tag:6305243930888618516)
J’ai dû arrêter mon cours d’Excel avancé (outils d'analyse et programmation VBA - Visual Basic pour Applications) cette année. Avec un petit pincement au cœur quand même. C’était un de mes derniers enseignements devant un public non informaticien. Il me fallait développer des trésors d’ingéniosité et de patience pour persuader les étudiants que c’était intéressant pour eux (au cas où ils en douteraient) et qu’ils étaient capables de le faire (ils en doutaient vraiment beaucoup, surtout durant les premières séances). C’était d’ailleurs le dernier enseignement que je faisais de tête en m’astreignant à écrire les principales notions au tableau pour éviter d’aller trop vite (tout le monde connaît mon débit de parole cataclysmique, sans compter mon incapacité à faire cours sans pousser des beuglements avec conviction [tout le bâtiment profitait de mes séances] tant je suis submergé par ce que je fais...).Maintenant que j’arrête le cours, je sens que je vais tout oublier. J’ai donc décidé de rédiger proprement au moins la partie VBA, et de mettre de l’ordre dans mes TD en explicitant les exercices. Je les mets en ligne avec leurs corrigés pour que tout le monde puisse en profiter.
Il faut connaître un peu Excel avant de pouvoir tirer profit de ces exercices. Le TD n°1 vous permettra de vous situer par rapport au niveau attendu pour la suite des séances.
| Thème | Sujet | Corrigé |
|---|---|---|
| TD n°1. Construction d’une feuille de calcul. Références absolues et relatives. Elaboration de graphiques. | | |
| TD n°2. Introduction à la programmation VBA. Branchements conditionnels. Ecriture et utilisation des fonctions personnalisées. | | |
| TD n°3. Simulations et scénarios. Table de simulation à 1 et 2 entrées. Gestionnaire de scénarios. Programmation VBA des fonctions personnalisées avec branchement conditionnels et branchements multiples. | | |
| TD n°4. Les boucles en programmation VBA. Exploitation du type Range (plage de cellules) dans les fonctions personnalisées. | | |
| TD n°5. Résolution des problèmes et optimisation. Valeur cible et solveur. | | |
| TD n°6. Programmation VBA des fonctions personnalisées. Les boucles while et for each. Le type Variant. | | |
| TD n°7. Programmation des macros VBA. Exploitation directe des classeurs et feuilles. Programmation des simulations. | | |
| TD n°8. Programmation des macros VBA sur les sélections. Sélection simples (une seule zone) et multiple (plusieurs zones). | | |
Références :
Rakotomalala R., "Excel - Programmation VBA", Dec. 2016.
Rakotomalala R., "Page de cours - Excel avancé".
Text mining : topic model - Diapos
2016-12-11 (Tag:1487543656048627118)
Le « topic modeling » est un processus de réduction de la dimensionnalité en fouille de textes. Il cherche à mettre en exergue les « topics » (thèmes) sous-jacents aux documents d’un corpus.D’une part, les topics s’expriment dans l’espace des termes, ce qui permet de les interpréter. D’autre part, ils définissent un nouvel espace permettant de décrire les documents. Ce qui permet de mieux comprendre leur nature et les informations qu’ils (les documents) véhiculent. Les algorithmes de machine learning (supervisé ou non-supervisé) peuvent tirer parti du nouveau système de représentation, plus compact, pour réaliser des analyses plus pertinentes.
Ce support décrit deux approches particulièrement populaires dans le domaine : (1) l’approche LSI, latent semantic indexing (ou LSA – latent semantic analysis) ; (2) la LDA, latent dirichlet allocation. Nous mettrons surtout l’accent sur les idées qui les guident et la lecture des résultats.
Mais nous aborderons également une approche basée sur l’analyse factorielle des correspondances (AFC), très peu citée dans la documentation en langue anglaise. Pourtant, comme la LSI, elle s’appuie sur un mécanisme de décomposition en valeur singulière (SVD – singular value decomposition), sauf qu’elle exploite en entrée une matrice de documents termes présentant les informations sous un angle différent.
Mots clés : text mining, fouille de textes, corpus, bag of words, sac de mots, lsi, latent semantic indexing, lsa, latent semantic analysis, afc, analyse factorielle des correspondances, lda, latent dirichlet analysis, svd, singular value decomposition
Document : Topic model
Références :
Aggarwal C., Zhai C., "Mining Text Data", Springer, 2012.
Grossman D., Frieder O., "Information retrieval - Algorithms and heuristics", Second Edition, Springer, 2004.
Text mining : la catégorisation de textes - Diapos
2016-11-28 (Tag:912178801047532353)
Ce troisième volet consacré à la fouille de textes concerne la catégorisation de documents (document classification en anglais).L’affaire semble simple une fois la matrice documents termes constituée. Nous disposons d’un tableau individus variables avec comme colonne supplémentaire la classe d’appartenance de chaque document. Il s’agit d’un problème très classique d’analyse prédictive. C’est pourtant à ce stade que le vrai travail commence. En effet, nous devons faire face à quelques spécificités : nous cherchons souvent à avant tout identifier une classe contre les autres, la matrice de données est creuse et de forte dimensionnalité. Ces éléments nous amènent à approfondir plusieurs aspects particuliers de l’apprentissage supervisé.
Dans ce support, nous nous attardons sur la mesure d’évaluation des performances avec la F-Mesure (f-measure, f-score) qui permet d’arbitrer entre le rappel et la précision. Nous parlerons également des techniques supervisées rapides et agressives de sélection de variables visant à réduire la dimensionnalité. Enfin, nous étudierons plusieurs techniques prédictives populaires dans la catégorisation de textes car apportent des réponses adaptées aux singularités du domaine.
Mots clés : text mining, fouille de textes, corpus, bag of words, sac de mots, f-mesure, f-measure, rappel, précision, courbe précision rappel, micro average, macro average, sélection de variables, méthode filtre, k-ppv, k plus proches voisins, k-nn, nearest neighbor, bayésien naïf, naive bayes, modèle d'indépendance conditionnelle, méthode rocchio
Document : Catégorisation de textes
Références :
Weiss S., Indurkhya N., Zhang T., Damerau F., « Text Mining – Predictive methods for analyzing unstructured information », Springer, 2005.
Aggarwal C., Zhai C., « Mining Text Data », Springer, 2012.
Text mining : la matrice documents termes - Diapos
2016-11-19 (Tag:7310383820839760879)
Ce second volet consacré au text mining aborde la construction de la matrice documents termes. Elle est centrale dans le processus de fouille de texte. L’efficacité des techniques data mining subséquentes dépend essentiellement de sa qualité, de sa capacité à reproduire l’information pertinente contenue dans les documents textuels.Plusieurs volets sont détaillés : l’extraction des termes, la réduction de la dimensionnalité, la question de la pondération, et enfin les mesures de similarité et de distances adaptées aux spécificités du domaine.
Des traitements exemples sur un corpus jouet et sur les données « acq » de Reuters (disponibles avec le package ‘tm’ pour le logiciel R) permettent d’illustrer le propos.
Mots clés : text mining, fouille de textes, corpus, mots vides, stop words, lemmatisation, lemmatization, racinisation, stemming, term frequency, TF, inverse document frequency, IDF, TF-IDF, distance euclidienne, indice de jaccard, similarité cosinus, n-grams, n-grammes, shingles
Document : Matrice documents termes
Références :
Weiss S., Indurkhya N., Zhang T., Damerau F., « Text Mining – Predictive methods for analyzing unstructured information », Springer, 2005.
Aggarwal C., Zhai C., « Mining Text Data », Springer, 2012.
Introduction au text mining - Diapos
2016-11-14 (Tag:2483091863507676500)
J’entame cette semaine mon nouveau cours de Text Mining en Master SISE. Je l’assurai avec un binôme depuis plusieurs années déjà. Cette année j’ai décidé de le prendre en main seul afin de le coupler avec le cours de web mining et d’analyse des réseaux sociaux qui aura lieu au second semestre.Ce premier support introductif essaie de cerner la fouille de textes (text mining) en le cadrant par rapport à la démarche générique du data mining. Les principales applications sont détaillées. Une première approche avec la représentation des corpus (collection de documents) à l’aide des sacs de mots (bag of words) est initiée. Ce thème sera largement approfondi dans un second support qui sera en ligne tantôt.
Mots-clés : text mining, fouille de textes, recherche d'information, catégorisation de textes, information retrieval, document classification, clustering de textes, bag of words, sac de mots
Document : Introduction au text mining
Références :
Weiss S., Indurkhya N., Zhang T., Damerau F., « Text Mining – Predictive methods for analyzing unstructured information », Springer, 2005.
Feldman R., Sanger J., « The text mining handbook – Advanced approcahes in analyzing unstructuerd data », Cambridge University Press, 2008.
Aggarwal C., Zhai C., « Mining Text Data », Springer, 2012.
Etude des logiciels de data science
2016-10-31 (Tag:5081881052993066726)
Le logiciel est une composante clé de l’activité du data scientist. S’extasier sur la formule mathématique de la marge dans les SVM est une chose, savoir mettre en œuvre la méthode à bon escient sur une étude réelle avec des vraies données en est une autre. Et cela passe forcément par les outils.Dans le cadre de mes enseignements en Master SISE, j’ai demandé aux étudiants d’effectuer une étude exploratoire de plusieurs logiciels de data science. J’ai imposé la liste des logiciels à analyser de manière à ce que les étudiants puissent faire preuve d’adaptabilité. Mon objectif était leur faire découvrir des outils d’horizons et avec des modes opératoires différents. Ils disposaient de trois semaines, sachant qu’ils avaient des cours en parallèle, pour : prendre en main l’outil, en évaluer les contours, l’installer dans notre salle informatique, monter des études de cas (on parle de « lab » de nos jours) sous forme de travaux dirigés qu’ils devaient assurer auprès de leurs collègues, élaborer un corrigé sous forme de tutoriel animé à publier sur un site de partage de vidéo.
Les étudiants ont si bien travaillé que je me suis dit qu’il était intéressant de partager leur production avec vous. Sont recensés dans le tableau suivant : la présentation succincte de l’outil, la fiche du lab, les données associées, le corrigé accessible sur Youtube. Les logiciels ont pour point commun d’être libres ou de proposer une version d’essai gratuite suffisamment opérationnelle. D’autres outils existent bien sûr, ils seront vraisemblablement étudiés dans le futur. Et R, Python et Knime ont été laissés sciemment de côté parce qu’ils font l’objet de cours et TD par ailleurs dans le master.
Enfin, tout est perfectible bien sûr. Il s’agit là d’un certain point de vue sur les outils étudiés. Prétendre à l’exhaustivité est impossible, surtout avec des contraintes de temps fortes (préparation, présentation, durée des labs). Les présentations et les exercices constituent avant tout des points d’entrées qui nous permettent de nous initier à l’utilisation de ces logiciels. C’était l’objectif premier du projet.
| Logiciel | Présentation | Exercices | Données | Tutoriel |
|---|---|---|---|---|
| Azure Machine Learning | | | | |
| RapidMiner | | | | |
| Weka | | | | |
| Orange | | | | |
| Rattle | | | | |
| Dataiku DSS | | | | |
Références :
Piatetsky G., « Gartner 2016 Magic Quadrant for Advanced Analytics Platforms: gainers and losers », KDnuggets, Feb. 2016.
Clustering : la méthode TwoStep Cluster
2016-10-23 (Tag:2662298649283785667)
Au gré de mes pérégrinations sur le web, mon attention a été attirée par l’algorithme de classification automatique (clustering, apprentissage non supervisé) TwoStep Cluster décrit sur le site de SPSS. Il présente des caractéristiques très intéressantes de prime abord : il sait traiter les variables actives quantitatives et qualitatives, il peut appréhender des très grandes bases de données avec des temps de traitements ébouriffants, il sait détecter automatiquement le nombre adéquat de classes. La méthode répond à bien des préoccupations pratiques des data scientist dans ce type de démarche. Pourtant, très étrangement, elle est peu connue, et il n’existe pas de package pour R ou pour Python qui ait essayé de l’implémenter.En y regardant de plus près, je me suis rendu compte qu’il s’agissait d’une approche mixte (ou approche combinée) (Lebart et al., 1995 ; section 2.3) popularisée par le logiciel SPAD. Dans une première étape, des pre-clusters sont construits à l'aide d'un algorithme de partitionnement rapide. Dans une deuxième étape, ces pre-clusters sont fusionnés itérativement à l'aide d'un algorithme hiérarchique.
En réalité, la vraie originalité de la solution SPSS réside dans la stratégie de détection des classes dans la structure hiérarchique. Ce tutoriel s’attachera surtout dans un premier temps à décrypter le mécanisme d’identification du nombre "optimal" de classes. Dans un second temps, nous comparerons sur une base de taille relativement importante l’efficacité (identification du bon nombre de classes) et les temps de calcul de l’algorithme par rapport à des implémentations classiques de l’approche mixte combinant méthode des centres mobiles et classification ascendante hiérarchique, sous SPAD, Tanagra et R.
Mots clés : clustering, classification automatique, typologie, apprentissage non-supervisé, CAH, k-means, birch, ACP, classification sur facteurs, logiciel R, kmeans, hclust, bic, aic
Composants : K-MEANS, HAC
Document : TwoStep Cluster
Données : Données et programme R
Références :
IBM SPSS, "TwoStep Cluster Analysis", version 21.0.0.
Tutoriel Tanagra, "Traitement des gros volumes - CAH Mixte", octobre 2008.
L. Lebart, A. Morineau, M. Piron, « Statistique Exploratoire Multidimensionnelle », Dunod, 1995.
Clustering : algorithme des k-médoïdes - Diapos
2016-10-19 (Tag:4744395925504420810)
La méthode des k-médoïdes est une technique de classification automatique par réallocations. Sa particularité repose essentiellement sur la notion de médoïde, qui correspond au point représentatif d’un ensemble d’observations associées à un groupe. Si les classes sont relativement convexes, sa position dans l’espace de représentation est très proche du barycentre. En revanche, pour les classes non convexes, ou en présence de points atypiques, il se révèle autrement plus robuste en dépassant le caractère artificiel du barycentre.Ce support présente les idées sous-jacentes à la méthode. L’algorithme PAM (partitioning around medoids) – qui est une des implémentations les plus connues de l’approche - est détaillé, ainsi que CLARA (clustering large applications) qui se révèle plus adapté au traitement des grandes bases de données. Le critère silhouette est mis en avant pour identifier le nombre adéquat de classes, vieux serpent de mer de la classification automatique.
Mots-clés : classification automatique, typologie, clustering, apprentissage non supervisé, classification par partition, méthodes de réallocation, médoïde, PAM, partitioning aroung medoids, CLARA, clsutering large applications, critère silhouette, graphique silhouette
Document : Classification - Algorithme des k-médoïdes
Références :
Tutoriel Tanagra, "Clustering : méthode des centres mobiles", octobre 2016.
Tutoriel Tanagra, "Clustering : caractérisation des classes", septembre 2016.
Tutoriel Tanagra, "Classification ascendante hiérarchique - Diapos", juillet 2016.
Tutoriel Tanagra, "Classification automatique sous R", octobre 2015.
Tutoriel Tanagra, "Classification automatique sous Python", mars 2016.
Clustering : méthode des centres mobiles - Diapos
2016-10-12 (Tag:4407528618051231503)
La méthode des centres mobiles - méthode des K-Means - est une technique de classification automatique populaire, d’une part parce qu’elle est très simple, d’autre part parce que son implémentation ne nécessite pas de conserver en mémoire vive la totalité des données, permettant ainsi de traiter des très grandes bases. Même si par ailleurs l’algorithme est relativement lent car il nécessite le passage répété des observations.Ce support décrit l’algorithme dans les grandes lignes. Nous nous intéressons ensuite aux différentes extensions telles que le traitement des variables actives qualitatives ou mixtes (qualitatives et quantitatives), la classification floue (fuzzy c-means), et la classification de variables (classification autour des variables latentes). On se rend compte à cet égard que la méthode des centres mobiles est relativement souple et s’applique à une large palette de problèmes.
Mots-clés : classification automatique, typologie, clustering, apprentissage non supervisé, inertie inter-classes, inertie intra-classes, inertie expliquée, théorème d’huygens, classification par partition, méthodes de réallocation
Document : Classification - Méthode des centres mobiles
Références :
Tutoriel Tanagra, "Clustering : caractérisation des classes", septembre 2016.
Tutoriel Tanagra, "Classification ascendante hiérarchique - Diapos", juillet 2016.
Tutoriel Tanagra, "Classification automatique sous R", octobre 2015.
Tutoriel Tanagra, "Classification automatique sous Python", mars 2016.
Clustering : caractérisation des classes - Diapos
2016-09-28 (Tag:6770439444825122126)
L’interprétation des classes est une étape essentielle de la classification automatique. En effet, une fois les groupes constitués, il faut comprendre les mécanismes qui en sont à l’origine. Identifier les caractéristiques qui sous-tendent les différenciations entre les groupes est primordial pour s’assurer de leur crédibilité.Dans ce support de cours, nous explorons les techniques simples univariées et multivariées. Les premières ont le mérite de la facilité de calcul et de lecture, mais ne tiennent pas compte de l’effet conjoint des variables. Les secondes sont a priori plus performantes, mais nécessitent une expertise supplémentaire pour appréhender pleinement les résultats.
Mots-clés : classification automatique, typologie, clustering, apprentissage non supervisé, inertie inter-classes, inertie intra-classes, inertie expliquée, théorème d’huygens, valeur test, distance entre centres de classes, rapport de corrélation
Document : Caractérisation des classes
Dataset : Voitures
Références :
Tutoriel Tanagra, "Interpréter la valeur test", avril 2008.
Tutoriel Tanagra, "Comprendre la taille d'effet (effect size)", mai 2017.
Tutoriel Tanagra, "Classification ascendante hiérarchique - Diapos", juillet 2016.
Tutoriel Tanagra, "Classification automatique sous R", octobre 2015.
Tutoriel Tanagra, "Classification automatique sous Python", mars 2016.
Master SISE - Remise à niveau - Clustering
2016-08-18 (Tag:7570928658449124666)
Le clustering (classification automatique, typologie, apprentissage non supervisé) consiste à catégoriser des objets à partir de leurs propriétés de similarité. Ce programme de remise à niveau pour le Master SISE est consacré à la classification ascendante hiérarchique (CAH) et la méthode des centres mobiles (K-Means), techniques que l’on retrouve quasi-systématiquement dans les cours d’initiation au clustering. D’autres méthodes avancées seront étudiées en Master (méthodes adaptées aux grandes dimensions, dbscan, birch, cartes de Kohonen, etc.).Les exercices de ce thème font la part belle à l’interprétation des résultats, en particulier la caractérisation des groupes à l’aide des variables actives et illustratives. Les outils utilisés sont Excel, Tanagra et R.
Document principal : Principes de la classification automatique
Outils : Excel, Tanagra, R (RStudio), Python (Anaconda)
Exercice 1 : Classification ascendante hiérarchique, données.
Exercice 2 : Centres mobiles, données.
Exercice 3 : Étude de cas.
Master SISE - Remise à niveau - Analyse prédictive
2016-08-16 (Tag:2055506630416665731)
L’analyse prédictive a énormément contribué à la popularité du data mining et du machine learning. Dans ce programme de remise à niveau pour le master SISE, nous nous concentrons sur les techniques d’apprentissage supervisé où la variable cible est catégorielle. C’est un parti pris pédagogique sachant que la régression fait également partie de l’analyse prédictive mais, dans sa perception commune, elle est plutôt associée à la démarche économétrique et aux statistiques.Dans une première approche, nous nous focaliserons sur l’analyse discriminante linéaire et les arbres de décision. Les méthodes avancées (ex. SVM, méthodes ensemblistes [random forest, boosting, gradient boosting], réseaux de neurones, etc.) sont enseignées en Master.
Nous multiplions les outils dans ce thème : nous utilisons Excel en tandem avec Tanagra et Sipina d’une part ; R (RStudio) d’autre part. Pouvoir jongler entre les outils permet de ne pas en être dépendants.
Document principal : Principes de l’apprentissage supervisé
Outils : Excel, Tanagra, Sipina, R (RStudio), Python (Anaconda)
Exercice 1 : Analyse discriminante prédictive, données.
Exercice 2 : Analyse discriminante et sélection de variables, données.
Exercice 3 : Arbres de décision, données.
Exercice 4 : Arbres de décision – Frontières induites.
Exercice 5 : Comparaison de méthodes, données.
Master SISE - Remise à niveau - Inférence statistique
2016-08-11 (Tag:2576920341912222599)
L’inférence statistique constitue la base même de la découverte de connaissances à partir des données. Il s’agit de délimiter jusqu’à quel point un constat ou une mesure effectuée sur un échantillon (un ensemble d’observations) peut être généralisé sur l’ensemble de la population. L’approche est d’autant plus crédible que nous pouvons associer une probabilité d’erreur aux décisions que nous prenons.Le domaine est vaste et complexe. Il prend ses racines dans les calculs probabilistes. Nous simplifions un peu beaucoup dans ce programme de remise à niveau pour le master SISE en nous focalisant sur les aspects opérationnels de la pratique des statistiques : les estimations ponctuelles et par intervalle, les tests d’hypothèses.
Tous les calculs doivent être effectués sur machine à partir de fichiers de données réalistes, sous Excel et sous R.
Document principal : Inférence statistique
Outils : Excel + R (RStudio)
Exercice 1 : Lecture des tables statistiques.
Exercice 2 : Estimation et test, données.
Exercice 3 : Comparaison de populations, données.
Exercice 4 : Corrélation et régression, données.
Les cartes de Kohonen avec R
2016-08-05 (Tag:3768807276591757659)
Ce tutoriel vient compléter le support de cours consacré aux "Cartes auto-organisatrices de Kohonen". Le premier objectif est de mettre en lumière deux aspects importants de l’approche : sa capacité à résumer l’information disponible dans un espace à deux dimensions ; son couplage avec une méthode de classification automatique permettant d’associer la représentation topologique (et la lecture que l’on peut en faire) à l’interprétation des groupes issus de la typologie. Nous utiliserons le logiciel R et le package « kohonen ».Dans un deuxième temps, nous effectuerons une étude comparée de la qualité de la segmentation avec les K-Means, qui fait figure de référence, en procédant à une validation externe c.-à-d. en confrontant les regroupements proposés par les approches avec une classification préétablie. Cette procédure est souvent utilisée en recherche pour évaluer les performances des méthodes de clustering. Elle prend tout son sens lorsqu’on l’applique sur des données artificielles où l’on connait – parce que générée sciemment – la bonne typologie. Nous utiliserons les composants K-Means et Kohonen-Som de Tanagra.
Rendons à César ce qui lui appartient, ce tutoriel est en partie inspiré de l’article de Shane Lynn, accessible sur le site R-bloggers. Je me suis évertué à le compléter en introduisant les calculs intermédiaires permettant de mieux saisir le sens des graphiques, et en effectuant l’étude comparative.
Mots-clés : som, self organizing maps, kohonen, technique de visualisation, réduction de dimensionnalité, classification automatique, clustering, cah, classification mixte, logiciel R, package kohonen
Composants : KOHONEN-SOM, HAC, K-MEANS
Lien : Les cartes de Kohonen avec R
Fichier : waveform - som
Références :
Tutoriel Tanagra, "Les cartes auto-organisatrices de Kohonen - Diapos", Juillet 2016.
Tutoriel Tanagra, "Les cartes de Kohonen", Juillet 2008.
Lynn S., "Self-Organising Maps for Customer Segmentation using R", R-bloggers, February 2014.
Master SISE - Remise à niveau - Analyses factorielles
2016-08-04 (Tag:3388975546419447444)
Les techniques d’analyses factorielles sont très populaires, notamment dans le monde francophone. D’une part, parce que l’école d’analyse factorielle française a été, et est toujours, particulièrement prolifique, nous délivrant des ouvrages exceptionnels donnant tout le sel à ces techniques ; d’autre part, parce que les méthodes sont intrinsèquement performantes, nous offrant des possibilités multiples d’inspection des données.Ce programme de remise à niveau pour le Master SISE concerne l’analyse en composantes principales (ACP), l’analyse des correspondances multiples (ACM) et l’analyse factorielle des correspondances (AFC). A chaque thème est associé deux séries d’exercices : la première se présente comme un guide permettant d’assimiler les principaux repères d’une analyse ; la seconde est une étude de cas où l’étudiant doit architecturer lui-même sa démarche, en fonction des objectifs de l’étude et des caractéristiques des données.
Les supports de qualité pouvant servir de référence sont très nombreux sur internet. J’ai fait une petite sélection dans le document principal. Il est très facile d’enrichir son apprentissage en faisant quelques recherches sur Google. Le tout est de ne pas se perdre.
Document principal : Analyses factorielles
Voir aussi : Pages ACP et AFC/ACM de ce site des tutoriels
Outils : R + RStudio, Python (Anaconda)
Exercice 1 : Apprentissage ACP, données (Autos 2005).
Exercice 2 : Etude de cas ACP (Crime).
Exercice 3 : Apprentissage ACM, données (Races canines).
Exercice 4 : Etude de cas ACM (Cars preference).
Exercice 5 : Apprentissage AFC, données (Médias professions).
Exercice 6 : Etude de cas AFC (Régionales 2004).
Les cartes auto-organisatrices de Kohonen - Diapos
2016-07-31 (Tag:3750370584567953681)
Les cartes de Kohonen (en anglais, SOM : self organizing maps) sont des réseaux de neurones orientés à deux couches : l’entrée correspond à la description des données, la sortie est organisée sous forme de grille (le plus souvent) et symbolise une organisation des données. Les cartes servent à la fois pour la réduction de dimensionnalité (d’un espace à p dimensions, nous nous projetons dans un espace 2D), pour la visualisation (les proximités sur la grille correspondent à une proximité dans l’espace initial), et la classification automatique (on peut procéder à des regroupements des neurones de la couche de sortie).Ce support de cours décrit dans les grandes lignes les mécanismes sous-jacents aux cartes de Kohonen. L’accent est mis sur la visualisation qui est un de ses atouts forts. La mise en œuvre sous R (package kohonen) et Tanagra (KOHONEN-SOM) est également présentée. J’ai déjà écrit un tutoriel sur le sujet il y a fort longtemps (2008), un autre viendra incessamment où j’essaierai de mettre l’accent sur la visualisation et la robustesse de la méthode.
Mots-clés : som, self organizing maps, kohonen, technique de visualisation, réduction de dimensionnalité, classification automatique, clustering, cah, classification mixte, logiciel R, package kohonen
Composants : KOHONEN-SOM
Document : Kohonen SOM - Diapos
Références :
Tutoriel Tanagra, "Les cartes de Kohonen", Juillet 2008.
Tutoriel Tanagra, "Les cartes de Kohonen avec R", Août 2016.
Master SISE - Remise à niveau - Introduction à R
2016-07-28 (Tag:5867706686175656536)
R est multiple : il représente un langage de programmation doté des attributs principaux d’un langage (type de données, structures algorithmiques, organisation des programmes en fonctions et modules) ; il correspond à un logiciel de statistique et de data mining, doté d’une bibliothèque de fonctions extensibles à l’infini grâce au système des packages, particulièrement ingénieux je trouve, qui contribue largement à son succès ; il propose enfin des outils performants de management des données.Mon cours en Master se focalise sur le premier aspect. Le second viendra au fur et à mesure de l’étude des techniques de data mining et machine learning. Ce programme de remise à niveau pour le Master SISE est donc principalement consacré au troisième thème, celui de la manipulation des données, de l’exploration des opérations de calculs intermédiaires (transformation de variables, recodage, statistiques récapitulatives, etc.), et des représentations graphiques.
Document principal : Introduction au logiciel R
Outils : R + RStudio (conseillé, non obligatoire)
Exercice 1 : Manipulation des data frame, données.
Exercice 2 : Calculs statistiques sur vecteurs, données.
Exercice 3 : Corrélation et régression avec R, données.
Classification ascendante hiérarchique - Diapos
2016-07-25 (Tag:3298182658420135271)
La CAH (classification ascendante hiérarchique) est une technique de classification (typologie, clustering, apprentissage non supervisé) très populaire. Son succès repose – entres autres – sur la nature de la solution qu’elle propose : nous disposons à l’issue des traitements d’une série de partitions emboîtées représentées graphiquement à l’aide d’un dendrogramme. Ainsi, au lieu d’une réponse unique, très possiblement arbitraire surtout s’agissant de regroupements sans a priori d’ensembles d’observations, nous disposons de scénarios de solutions qui nous permettent d’enrichir l’analyse que nous menons sur nos données.Ce support de cours décrit dans les grandes lignes les mécanismes sous-jacents à l’algorithme d’apprentissage. La mise en œuvre sous R (hclust), Python (package scipy) et Tanagra (HAC) est également détaillée. Les nombreux tutoriels cités en bibliographie permettront aux lecteurs d’aller plus loin dans la pratique de la technique dans des problèmes réels.
Mots-clés : cah, classification ascendante hiérarchique, classification automatique, typologie, clustering, apprentissage non supervisé, tandem analysis, classification sur composantes principales, cah mixte, logiciel R, hclust, python, package scipy, distance euclidienne, stratégie d’agrégation, méthode ward, saut minimum, saut maximum, single linkage, complete linkage, classement d’un individu supplémentaire, inertie, inertie inter-classes, inertie intra-classes, théorème d’huygens
Composants : HAC, K-MEANS
Document : cah.pdf
Références :
Tutoriel Tanagra, "Classification automatique sous R", octobre 2015.
Tutoriel Tanagra, "Classification automatique sous Python", mars 2016.
ANOVA à un et deux facteurs - Diapos
2016-07-18 (Tag:9198574857779366394)
Je m’intéresse un peu à l’ANOVA (analyse de la variance ou analyse de variance) en ce moment. Ça m’a rappelé mes débuts dans l’enseignement. A l’époque, 2e moitié des années 90, on me proposait souvent des remplacements (ben oui, on est novice, on n’a pas trop le choix). Cela m’a amené à faire des grands écarts entre des cours de séries temporelles, d’ANOVA, …, de bases de données sous Paradox (qui s’en rappelle aujourd’hui ?), de programmation SQL sous Interbase (itou ?), etc. Avec le recul, je me rends compte que ces aventures auront été très formatrices.A propos de l’ANOVA donc, j’ai jeté un coup d’œil sans trop y croire dans mes archives. J’étais moins organisé que maintenant il faut dire. Grande fut ma surprise de tomber sur un support relativement construit. Du coup, j’ai décidé de le mettre en ligne en le vérifiant entièrement, en le relookant très légèrement (j’ai ajouté des couleurs, le document initial était particulièrement austère), et en introduisant les traitements sous R.
Pour rappel, l’ANOVA consiste à vérifier que plusieurs échantillons proviennent de la même population en se basant sur la comparaison des moyennes. On peut également la considérer sous le prisme de l’étude de l’influence d’une ou plusieurs variables qualitatives sur une variable d’intérêt quantitative (Wikipédia).
Mots clés : anova, analyse de variance, tests post hoc, comparaisons multiples, logiciel R, aov, pairwise.t.test, correction de bonferroni, sidak, mesures répétées
Lien : ANOVA.pdf
Données : autos_anova.xlsx
Références :
Dagnelie P., "Statistique théorique et appliquée - Tome 2. Inférence statistique à une et à deux dimensions", De Boeck, 2011.
Guenther W., "Analysis of variance", Prentice-Hall, 1964.
Master SISE - Remise à niveau - Statistique Descriptive
2016-07-12 (Tag:292768384084848232)
Voici le second opus (live is life, lalaa… lalala, toute ma jeunesse ça...) du programme de remise à niveau. Il concerne les statistiques descriptives sur tableur.Pour les initiés, il n’y a aucune difficulté. Le principal enjeu est la réalisation des différentes tâches sous Excel. Il faut une certaine connaissance du tableur, d’où la nécessité du thème précédent.
Pour les non-initiés aux statistiques, il faut un peu de lecture pour comprendre les principaux concepts de la description des données. Certains sont relativement simples (caractéristiques de tendance centrale, fréquences absolues et relatives, …), d’autres demandent un peu plus d’attention (liaison statistique, …).
Des supports de qualité sont accessibles en ligne. Ils sont référencés dans le document principal.
Document principal : Statistique descriptive
Outil : Excel (Libre ou Open Office Calc peuvent faire l’affaire)
Exercice 1 : Statistiques univariées et bivariées, données.
Exercice 2 : Choix des outils, données.
Exercice 3 : Corrélation et régression, données.
Master SISE - Programme de remise à niveau - Excel
2016-07-08 (Tag:7440475773701729679)
Ce premier thème du programme de remise à niveau pour le master SISE concerne Excel. Je sais ce qu’en pensent certains de mes congénères. Il n’en reste pas moins qu’il arrive en bonne place dans le sondage annuel des KDnuggets (ex. en 2016). Il en est de même dans les offres d’emploi. Personne ne peut négliger cela. En réalité, il ne faut pas demander à Excel ce qu’il ne sait pas faire. Nativement, les fonctions statistiques sont un peu limitées, les fonctions de data mining sont inexistantes, dire le contraire serait mentir. Mais, d'un autre côté, Excel se révèle simple mais puissant pour le management de données, tant que la volumétrie reste modérée. Dans les faits, les utilisateurs tirent pleinement profit de ses capacités en le couplant avec un outil spécialisé de data mining, via le mécanisme des add-ins (macros complémentaires) par exemple.Ce programme est consacré au traitement des listes sous Excel (réaliser les exercices à l'identique est possible sous Libre ou Open Office). Nous verrons ainsi tour à tour le filtre automatique, la mise en forme conditionnelle, le filtre avancé et l’outil tableau croisé dynamique.
Supports de référence : Excel - Traitement des listes.
Exercice 1 : Filtre automatique, données.
Exercice 2 : Mise en forme conditionnelle, données.
Exercice 3 : Filtre avancé, données.
Exercice 4 : Tableau croisé dynamique, données.
Les add-ins Tanagra et Sipina pour Excel 2016
2016-06-11 (Tag:6966042116838727062)
Les macros complémentaires (« add-in » en anglais) « tanagra.xla » et « sipina.xla » participent grandement à la diffusion des logiciels Tanagra et Sipina. Il s’agit d’intégrer des menus dédiés au data mining dans Excel, ils mettent en place une passerelle simple entre le tableur et les outils spécialisés.J’avais développé et testé les dernières versions des macros complémentaires pour Excel 2007 et 2010. Ayant pu accéder récemment à Excel 2016, vous pensez bien que j’ai tout de suite vérifié le dispositif. La conclusion est que le système fonctionne sans anicroche.
Mots-clés : importation des données, fichier excel, macro complémentaire, add-in, add-on, xls, xlsx
Lien : fr_Tanagra_Add_In_Excel_2016.pdf
Références:
Tutoriel Tanagra, "L'add-in Tanagra pour Excel 2007 et 2010", août 2010.
Tutoriel Tanagra, "L'add-in Sipina pour Excel 2007 et 2010", août 2014.
Image mining avec Knime
2016-06-07 (Tag:9040417083352747751)
La fouille d’images ou image mining est une discipline assez ancienne. Schématiquement, il s’agit d’appliquer des techniques de machine learning au contenu des images c.-à-d. à partir de leurs caractéristiques visuelles. Sa démocratisation est plus récente en revanche. J’y vois plusieurs raisons : la profusion des données images avec le web (big data, etc., etc.) nécessite un savoir faire supplémentaire, on observe d’ailleurs que le traitement d’images est de plus en plus présent dans les challenges ; l’apparition d’outils faciles à appréhender pour les férus de data mining.Le module "Image Processing" de Knime est assez symbolique de cette évolution. Il n’est même pas nécessaire de faire l’apprentissage langage de programmation. On peut réaliser une analyse complète sans avoir à écrire une seule ligne de code. Le plus important est d’avoir une vision globale de la trame de l’étude. Il nous suffit alors de définir dans le bon ordre la séquence des traitements pour obtenir des résultats qui tiennent la route.
Ce tutoriel a pour objet un problème de classement. On souhaite discerner automatiquement les photos contenant un véhicule de celles contenant tout autre type d’objet. La principale information est que, malgré des connaissances relativement succinctes en traitement d’images, j’ai pu mener à son terme l’étude avec une aisance qui en dit long sur l’utilisabilité du logiciel. Le plus difficile aura été d’identifier le composant le plus adapté à chaque étape, les tutoriels didactiques sont rares, en français n’en parlons même pas, il faut prendre un peu de temps pour lire attentivement la documentation.
Mots clés : image mining, fouille d'images, catégorisation d'images, arbres de décision, random forest
Lien : fr_Tanagra_Image_Mining_Knime.pdf
Données et programme (archive Knime) : image mining tutorial
Références :
Knime Image Processing, https://tech.knime.org/community/image-processing
S. Agarwal, A. Awan, D. Roth, « UIUC Image Database for Car Detection » ; https://cogcomp.cs.illinois.edu/Data/Car/
Programmation Python sous Spark avec PySpark
2016-05-31 (Tag:1345080265827636683)
Dans la série « je découvre Spark », voici un tutoriel consacré à la librairie PySpark pour la programmation Python sous Spark. Il vient en contrepoint à celui consacré à SparkR (pour R). La trame est exactement la même.La première partie est donc commune (installation et configuration de Spark) ; la seconde partie consacré à l’exploitation des méthodes de PySpark est originale.
La principale information est que nous avons pu réaliser exactement les mêmes traitements sous R et Python, à savoir : l’importation des données, leur partition en échantillon d’apprentissage et de test, la modélisation sur la première, la prédiction sur la seconde, l’élaboration de la matrice de confusion et le calcul des indicateurs de performances.
Tout comme pour SparkR, ce tutoriel a bénéficié du travail exploratoire des étudiants du Master SISE de cette année pour leurs projets « Big Data ». Je les remercie encore une fois.
Mots-clés : langage python, package pyspark, big data, hadoop, spark, big data analytics, anaconda, spyder, régression logistique
Lien : Python sous Spark avec PySpark
Fichiers : Données et programme Python
Références :
Spark, "Welcome to Spark Python API Docs!".
Tutoriel Tanagra, "Programmation R sous Spark avec SparkR", mai 2016.
Programmation R sous Spark avec SparkR
2016-05-19 (Tag:9212929887714250948)
Apache Spark est un framework open source de calcul distribué dédié au Big Data. Sa particularité est qu’il est capable de travailler en mémoire vive. Il est très performant pour les opérations nécessitant plusieurs itérations sur les mêmes données, exactement ce dont ont besoin les algorithmes de machine learning.Au-delà des API (modules de classes et fonctions) standards, Spark intègre des librairies additionnelles : Streaming, traitement des données en flux ; SQL, accès aux données Spark avec des requêtes SQL ; GraphX, traitement des graphes ; et, c’est ce qui nous intéresse au premier chef, MLlib, types de données et algorithmes pour le machine learning.
SparkR est un package R qui permet de manipuler les types de données et méthodes de MLlib (pas toutes, le portage est en cours) en programmation R, et de bénéficier directement des avantages de Spark (gestion de la volumétrie, calcul distribué). Ce tutoriel a pour objectif de s’initier à l’utilisation de SparkR en traitant un exemple typique d’analyse prédictive.
Enfin, et ça me fait très plaisir de pouvoir le dire, ce document doit beaucoup au travail de deux groupes d’étudiants du Master SISE pour leurs projets "Big Data", l’un avait travaillé sur "SparkR", l’autre sur "PySpark" (programmation Python, qui fera l’objet d’un autre tutoriel). Ils ont largement défriché le terrain, qu’ils en soient chaleureusement remerciés.
Mots-clés : logiciel R, package SparkR, big data, hadoop, spark, big data analytics, rstudio, régression logistique
Lien : R sous Spark avec SparkR
Fichiers : Données et programme R
Références :
Phelip A., "Découvrez SparkR, la nouvelle API de Spark", Blog Xebia, Sept. 2015.
Emaasit D., "Installing and starting SparkR locally on Windows OS and RStudio", R-bloggers, July 2015.
Tutoriel Tanagra, "Programmation Python sous Spark avec PySpark", mai 2016.
Tutoriel Tanagra, "Programmation R sous Hadoop", avril 2015.
SVM : Support Vector Machine avec R et Python
2016-05-16 (Tag:5934682766006212226)
Ce tutoriel vient compléter le support de cours consacré au « Support Vector Machine » auquel nous nous référerons constamment [SVM - Diapos] . Il met en lumière deux éléments importants de la méthode : la position des points supports et le tracé des frontières dans l’espace de représentation lorsque nous construisons un séparateur linéaire ; la complexité du paramétrage dans le recherche de la solution adéquate pour un problème artificiel dont nous maîtrisons pourtant les caractéristiques. Nous utiliserons tour à tour les logiciels R (package ‘’e1071’’) et Python (package ‘’scikit-learn’’).Nous nous concentrons sur les aspects didactiques. Pour le lecteur intéressé par les aspects opérationnels de la pratique des SVM (schéma apprentissage-test pour l’évaluation des classifieurs, identification des paramètres optimaux à l’aide des grilles de recherche), je conseille la lecture de notre support repère. Je préconiserais également la lecture des tutoriels consacrés à la comparaison des logiciels proposant les SVM et à l’étude du comportement des différents classifieurs linéaires (voir références).
Mots-clés : svm, machines à vecteurs de support, séparateurs à vaste marge, package e1071, logiciel R, logiciel Python, package scikit-learn, sklearn
Lien : SVM - Support Vector Machine
Fichier : svm_r_python.zip
Références :
R. Rakotomalala, "Support Vector Machine - Diapos", mai 2016.
Tutoriel Tanagra, "SVM - Comparaison de logiciels", oct. 2008.
Tutoriel Tanagra, "Classifieurs linéaires", mai 2013.
SVM : Support Vector Machine - Diapos
2016-05-12 (Tag:64066052035674096)
L’approche SVM (support vector machine) est une technique de data mining / machine learning très populaire dans les domaines proches de la recherche. Je l’avais directement implémentée dans Tanagra en son temps (en m’inspirant du code de Weka). J’avais ensuite intégré la librairie LIBSVM (une des très rares bibliothèques externes de Tanagra) lorsque je me suis rendu compte des performances de cette dernière.Faire un cours dessus était une autre histoire. Comment présenter les SVM en allant à l’essence des choses sans assommer les étudiants à coups de formules mathématiques plus ou moins abstraites ? J’avais demandé à un groupe d’étudiants du Master SISE de faire le cours à ma place cette année dans le cadre de l’unité d’enseignement « Travail en groupe ». L'exercice m’a surtout permis de voir les réactions des autres étudiants qui assistaient à la séance, et mettre le doigt sur les ressorts de compréhension. L’idée est de prendre le temps de détailler avec des exemples simples traités sous Excel (vraiment simples !) la résolution des problèmes d’optimisations sous-jacents à la technique. Le fichier accompagne ce support.
La présentation est complétée par la mise en œuvre de l’approche sous les logiciels libres Python (scikit-learn), R (e1071) et Tanagra (SVM et C-SVC).
Je remercie le groupe d’étudiants qui a travaillé sur ce thème. Ils s’en sont vus, mais je pense que l’essentiel du message est passé auprès de leurs camarades.
Mots-clés : svm, machines à vecteurs de support, séparateurs à vaste marge, package e1071, logiciel R, logiciel Python, package scikit-learn, sklearn
Composants : SVM, C-SVC
Lien : Support Vector Machine (SVM)
Fichier exemple : svm exemples.xlsx
Références :
Tutoriel Tanagra, "SVM - Comparaison de logiciels", oct. 2008.
Tutoriel Tanagra, "Classifieurs linéaires", mai 2013.
Tutoriel Tanagra, "Support Vector Machine avec R et Python", mai 2016.
Gradient boosting avec R et Python
2016-05-04 (Tag:855656834581201180)
Ce tutoriel fait suite au support de cours consacré au « Gradient Boosting ». Il vient également en complément des supports et tutoriels pour les techniques de bagging, random forest et boosting mis en ligne précédemment (novembre 2015).La trame sera très classique : après avoir importé les données préalablement scindées en deux fichiers (apprentissage et test), nous construisons les modèles prédictifs et nous les évaluons. Le critère taux d’erreur en test est privilégié pour comparer les performances.
La question du paramétrage, particulièrement délicate dans le cadre du gradient boosting, est étudiée. En effet, ils sont nombreux, et leur influence est considérable. Malheureusement, si l’on devine à peu près les pistes à explorer pour améliorer la qualité des modèles (plus ou moins "coller" à l’échantillon d’apprentissage c.-à-d. plus ou moins régulariser), identifier avec exactitude les paramètres à manipuler et fixer les bonnes valeurs relèvent un peu de la boule de cristal, surtout lorsqu’ils interagissent entre eux. Ici, plus que pour d’autres méthodes de machine learning, la stratégie essai-erreur prend beaucoup d'importance.
Nous utiliserons R et Python, avec les packages dédiés, dans ce tutoriel.
Mots clés : logiciel R, programmation R, arbre de décision, adabag package, rpart package, Python, scikit-learn package, boosting, random forest
Lien : Gradient boosting
Fichier : gradient_boosting.zip
Références :
R. Rakotomalala, "Gradient boosting - Diapos", avril 2016.
R. Rakotomalala, "Bagging, Random Forest, Boosting - Diapos", novembre 2015.
Gradient boosting - Diapos
2016-04-30 (Tag:615807673382713873)
Le gradient boosting est une technique ensembliste qui généralise le boosting en introduisant la possibilité d’utiliser explicitement des fonctions de coûts (le boosting classique utilise implicitement une fonction de coût exponentielle).Ces diapos montrent les tenants et aboutissants de la méthode. La régression est développée dans un premier temps. Le problème du classement est analysé par la suite.
Les solutions implémentées dans les packages pour R et Python sont étudiées.
Mots-clés : boosting, arbres de régression, package gbm, package mboost, package xgboost, logiciel R, logiciel Python, package scikit-learn, sklearn
Lien : Gradient boosting
Références :
R. Rakotomalala, "Bagging, Random Forest, Boosting - Diapos", novembre 2015.
Natekin A., Knoll A., "Gradient boosting machines, a tutorial", in Frontiers in Neurorobotics, décembre 2013.
Mining of Massive Datasets (2nd Edition)
2016-04-14 (Tag:1694028435154085747)
L'ouvrage « Mining of Massive Datasets », littéralement « Fouille de données massives », s’inscrit dans l’air du temps. Le contexte, maintes fois évoqué, est bien connu aujourd'hui : la profusion des données et la multiplication des sources, exacerbées par les outils de communication et notre mode de vie, induisent de nouveaux défis et opportunités pour le Data Mining.Par rapport aux très nombreuses références qui existent, le livre de Leskovec, Rajaraman et Ullman présente une double particularité : il est basé sur des enseignements dispensés à l’Université de Stanford, c'est dire s'il a fait ses preuves ; le livre au format PDF ainsi que tout le matériel pédagogique associé (les diaporamas relatifs à chaque chapitre en Powerpoint et PDF) sont librement accessibles sur le web. C’est Byzance ! Sachant par ailleurs que l’ouvrage imprimé est disponible dans les librairies (mais pas gratuitement).
Cette fiche de lecture retrace les principales notions présentées dans cet ouvrage.
Mots clés : big data, data science, data scientist, machine learning, statistical learning
Lien : Résumé
Références :
J. Leskovec, A. Rajaraman, J.D. Ullman, "Mining of Massive Datasets" (2nd Edition), Cambridge University Press, November 2014.
Classification automatique sous Python
2016-03-24 (Tag:8237027358481095344)
J'explore Python chaque jour, chaque semaine. Mon objectif est de pouvoir l'utiliser de manière indifférenciée avec R dans mes cours de machine learning (data mining) à l'Université.Dans cette veine, je reprends étape par étape un précédent tutoriel consacré à la classification automatique sous R. Nous constatons, pour ce qui est du clustering avec la CAH et les K-Means en tous les cas, que les deux logiciels sont équivalents. Les commandes sont similaires, non pas dans leur syntaxe, mais dans leur mode opératoire. Et les résultats sont identiques, mis à part les k-means qui sont heuristiques par nature.
Nous utilisons les packages SciPy et Scikit-learn.
Mots clés : logiciel R, classification ascendante hiérarchique, CAH, méthode des centres mobiles, k-means, package scipy, package scikit-learn, analyse en composantes principales, ACP
Composants : linkage, dendrogram, fcluster, kmeans
Lien : cah et k-means avec Python
Données : cah_kmeans_avec_python.zip
Références :
Tutoriel Tanagra, "Classification automatique sous R", octobre 2015.
Analyse prédictive sous Knime
2016-02-25 (Tag:165210326778255496)
Knime est un logiciel de data mining librement téléchargeable en ligne (Knime Analytics Platform). Je l’étudie depuis longtemps. Mon premier tutoriel à son propos date de 2008. Je me suis rendu compte récemment que je n’avais jamais écrit un guide « simple » montrant une démarche d’analyse prédictive basique sous cet outil, à savoir : (1) importer les données ; (2) les partitionner en échantillons d’apprentissage et test ; (3) construire le modèle à partir de l’ensemble d’apprentissage ; (4) l’appliquer sur l’ensemble de test pour obtenir la prédiction du modèle ; (5) confronter les valeurs observées et prédites de la variable à prédire à travers la matrice de confusion ; (6) en déduire les indicateurs (mesures) de performances des modèles (taux d’erreur, etc.).Dans un processus de « scoring », une variante est apportée à partir du point n°4 : (4’) appliquer le modèle sur l’échantillon test pour obtenir le score des individus ; (5’) construire la courbe lift cumulée ou courbe de gain à partir des valeurs observées de la variable cible et les scores.
Ce tutoriel retrace toutes ces étapes avec force copies d’écrans comme toujours. La régression logistique est mise à contribution mais le processus est transposable à toute méthode de machine learning. Nous introduirons très brièvement la sélection de variables - à la sauce Knime - dans la dernière partie.
Mots clés : régression logistique, knime, sélection de variables, échantillons d'apprentissage et de test
Lien : Analyse prédictive.pdf
Fichier : pima.xls
Références :
Knime - https://www.knime.org/
Building Machine Learning Systems
2016-02-20 (Tag:2711632607338351403)
.. with Python (2nd Edition).J’ai toujours eu des réticences à acheter et conseiller à mes étudiants des ouvrages consacrés à des outils. Généralement, ils prétendent couvrir un très large panel d’approches en quelques centaines de pages. A la sortie, on se rend compte qu’ils traitent de manière très superficielle les méthodes sous-jacentes qu’ils essaient d’illustrer. Et, de toute manière, on trouvera toujours sur le web des tutoriels en français ou en anglais, qui décriront les opérations et les sorties des logiciels de manière autrement plus approfondie. De plus, la diffusion croissante de nombreuses vidéos de démonstration sur la plate-forme d’échange YouTube modifie la donne concernant ce type de document à vocation pédagogique.
Pourquoi alors faire une fiche de lecture sur « Building Machine Learning Systems with Python » qui s’inscrit finalement dans cette lignée des ouvrages centrés sur les outils ?
Tout simplement parce que l'ouvrage de Luis Pedro Coelho et Willi Richert nous permet de cerner le champ des possibles en matière de Machine Learning sous Python. Le livre ne prétend pas à l’exhaustivité. Il ne constitue certainement pas un ouvrage sur l’apprentissage automatique. L’objectif serait plutôt de titiller la curiosité du lecteur. Pour ma part, j’y ai surtout vu une source d’inspiration intéressante me permettant de faire évoluer mes Cours / Travaux Dirigés pour mes enseignements de Data Mining - Data Science en Master Statistique et Informatique.
Mots clés : big data, data science, data scientist, machine learning, statistical learning, python
Lien : Résumé
Références :
L.P. Coelho, W. Richert, "Buildong Machine Learning Systems with Python (2nd Edition)", Packt Publishing, mars 2015.
Data Science : fondamentaux et études de cas
2016-01-07 (Tag:3883543436677093329)
Machine learning avec Python et RData Science est un terme très en vogue. Tout le monde en parle. Une requête sur Youtube du terme exact "data science" ramène 112.000 vidéos, 9.910.000 références sur Google (au 7 janvier 2016).
Cet ouvrage d’Eric Biernat et Michel Lutz aborde le thème du data science en s’appuyant sur le prisme du machine learning. Ce parti pris est heureux parce qu’il leur évite de partir dans tous les sens. Bien sûr, d’autres prismes sont possibles. Mais on peut difficilement tout traiter dans un livre. Cadrer le débat est nécessaire.
Les auteurs font le tour de quelques techniques existantes dans un premier temps. Puis, dans un second temps, ils partagent leur expérience, tant dans les missions qu’il ont eu à mener, que dans les compétitions (les fameux "challenge") auxquelles ils ont participé.
Mots clés : big data, data science, data scientist, machine learning, statistical learning, python, logiciel R
Lien : Résumé
Références :
Eric Biernat, Michel Lutz, "Data Science : fondamentaux et études de cas - Machine learning avec Python et R", Eyrolles, octobre 2015.
Bonne année 2016 - Bilan 2015
2016-01-02 (Tag:4512185363447481729)
L’année 2015 s’achève, 2016 commence. Je vous souhaite à tous une belle et heureuse année 2016.Un petit bilan chiffré concernant l'activité organisée autour de Tanagra pour l' année écoulée. L'ensemble des sites (logiciel, support de cours, ouvrages, tutoriels) a été visité 255.386 fois cette année, soit 700 visites par jour.
Depuis la mise en place du compteur Google Analytics (01 février 2008), le groupe de sites a été visité 1.847.033 fois, soit 639 visites par jour.
Qui êtes-vous en 2015 ? La majorité des visites viennent de France (46%) et du Maghreb (16 %). Puis viennent les autres pays francophones, dont une grande partie vient d'Afrique. Pour ce qui est des pays non francophones, nous observons parmi ceux qui reviennent souvent : les États-Unis, l'Inde, le Royaume Uni, l'Allemagne, le Brésil.
Que consultez-vous en priorité en 2015 ? Les pages qui ont le plus de succès sont celles qui se rapportent à la documentation sur le Data Science (Data Mining, Statistique, Machine Learning, Big Data Analytics, Analyse de Données) : les supports de cours, les tutoriels, les liens vers les autres documents accessibles en ligne, etc. On peut rapprocher la page consacrée à la Programmation R, qui est la plus consultée, à cette thématique générale. Depuis septembre 2015, une page dédiée au Machine Learning sous Python a été mis en ligne, espérons qu’elle connaîtra la même audience.
En cette nouvelle année, je souhaite le meilleur à tous les passionnés de Data Science, de Statistique et d’Informatique.
Ricco.
Diaporama : Tanagra - Bilan 2015
Random Forest et Boosting avec R et Python
2015-11-29 (Tag:4180029503214824554)
Ce tutoriel fait suite au support de cours consacré au "Bagging, Random Forest et Boosting" (cf. références). Nous montrons l’implémentation de ces méthodes sur un fichier de données. Nous suivrons à peu près la même trame que dans le support, c.-à-d. nous décrivons tout d’abord la construction d’un arbre de décision, nous mesurons les performances en prédiction, puis nous voyons ce que peuvent apporter les méthodes ensemblistes. Différents aspects de ces méthodes seront mis en lumière : l’importance des variables, l’influence du paramétrage, l’impact des caractéristiques des arbres sous-jacents (base classifier), etc.Dans un premier temps, nous mettrons l’accent sur R (packages rpart, adabag et randomforest) et Python (package scikit-learn). Disposer d’un langage de programmation permet de multiplier les analyses et donc les commentaires. Evaluer l’influence du paramétrage sur les performances sera notamment très intéressant. Dans un deuxième temps, nous étudierons les fonctionnalités des logiciels qui fournissent des solutions clés en main, très simples à mettre en œuvre, plus accessibles pour les personnes rebutées par la programmation, avec Tanagra et Knime.
Mots clés : logiciel R, programmation R, arbre de décision, adabag package, rpart package, randomforest package, Python, scikit-learn package, bagging, boosting, random forest
Composants : BAGGING, RND TREE, BOOSTING, C4.5, DISCRETE SELECT EXAMPLES
Lien : Baggin, Random Forest et Boosting
Fichier : randomforest_boosting_fr.zip
Références :
R. Rakotomalala, "Bagging, Random Forest, Boosting - Diapos", novembre 2015.
Bagging, Random Forest, Boosting - Diapos
2015-11-19 (Tag:6323484326913955876)
Les techniques ensemblistes de type bagging / boosting jouissent d’une forte popularité dans la recherche en machine learning. Les versions fondatrices sont assez anciennes, je me rappelle pour ma part avoir programmé le bagging dans la version 2.5 de Sipina, en 1996, lorsque Breiman avait mis en ligne le brouillon de son article qui sera par la suite publié dans Machine Learning. Leurs performances prédictives justifient amplement cette notoriété. Mais, notamment parce qu’elles ne se prêtent pas à des interprétations fines des relations de cause à effet, elles sont peu utilisées dans les entreprises qui s’appuient sur des processus « classiques » de scoring et d’analyse prédictive (j’encadre énormément de stage d’étudiants en master professionnels).Du moins jusqu’à présent. En effet, avec l’essor du data science, des entreprises fortement novatrices s’investissent de plus en plus dans cette voie (le nombre d’offres d’emploi où le terme data science apparaît explicitement augmente rapidement sur le site de l’APEC). La recherche appliquée devient source de dynamisme et de productivité, dans de très nombreux domaines. La valorisation des données massives devient cause nationale. Et je vois arriver une demande patente en faveur des techniques avancées de machine learning. Je me suis dit qu’il était temps d’introduire ce thème dans mon cours de data mining en Master SISE (Statistique et Informatique) à l’Université Lyon 2.
Mots-clés : bagging, boosting, random forest, forêts aléatoires, arbres de décision, package rpart, package adabag, package randomforest, logiciel R
Lien : Bagging - Random Forest - Boosting
Références :
Breiman L., « Bagging Predictors », Machine Learning, 26, p. 123-140, 1996.
Breiman L., « Random Forests », Machine Learning, 45, p. 5-32, 2001.
Freund Y., Schapire R., « Experiments with the new boosting algorithm », International Conference on Machine Learning, p. 148-156, 1996.
Zhu J., Zou H., Rosset S., Hastie T., « Multi-class AdaBoost », Statistics and Its Interface, 2, p. 349-360, 2009.
Classification automatique sous R
2015-10-31 (Tag:7018652968779376297)
Un collègue à la recherche d’un tutoriel introductif à la classification automatique (typologie, clustering en anglais) avec R m’a contacté récemment. A ma très grande surprise, je me suis rendu compte que je n’en avais pas moi-même écrit. Pourtant, j’ai abordé plusieurs fois le thème, mais sous l’angle de traitements sophistiqués (enchaînement k-means et cah, déploiement, classification sur données mixtes, …).Voici donc un petit guide montrant les principales commandes sous R, essentiellement la classification ascendante hiérarchique (CAH) et la méthode des centres mobiles (k-means). Pour ajouter un peu de sel à l’affaire, je décris des pistes pour la détermination du nombre de classes pour les k-means, j’aborde également la question de l’interprétation des groupes à l’aide de techniques statistiques univariées (statistiques comparatives) et multivariées (analyse en composantes principales - ACP). La complémentarité de cette dernière avec la classification automatique fait toujours autant de merveilles.
Mots clés : logiciel R, classification ascendante hiérarchique, CAH, méthode des centres mobiles, k-means, package fpc, analyse en composantes principales, ACP
Composants : hclust, kmeans, kmeansruns
Lien : cah et k-means avec R
Données : cah_kmeans_avec_r.zip
Références :
Marie Chavent, Page Teaching, Université de Bordeaux (consulté oct. 2015).
Python - Econométrie avec StatsModels
2015-09-28 (Tag:9160580150494389597)
StatsModels est un package dédié à la modélisation statistique. Il incorpore un grand nombre de techniques économétriques telles que la régression linéaire, le modèle linéaire généralisé, le traitement des séries temporelles (ARIMA, etc.).Dans ce tutoriel, nous essaierons de cerner les potentialités de StatsModels en déroulant une étude de cas en régression linéaire multiple. Nous aborderons tour à tour : l’estimation des paramètres du modèle à l’aide de la méthode des moindres carrés ordinaires, la mise en œuvre de quelques tests statistiques, la vérification de la compatibilité de la distribution des résidus avec l’hypothèse de normalité, la détection des points atypiques et influents, l’analyse de la colinéarité, la prédiction ponctuelle et par intervalle.
Mots clés : programmation python, économétrie, statsmodels, moindres carrés ordinaires, mco
Lien : fr_Tanagra_Python_StatsModels.pdf
Fichier : fr_python_statsmodels.zip
Références :
StatsModels: Statistics in Python
Python Package Index: StatsModels
R en ligne avec R-Fiddle
2015-09-22 (Tag:8038090697636549950)
R-Fiddle est un environnement de programmation R accessible en ligne. Il permet de coder et de faire exécuter un programme R.Ce type de solution est adapté à un utilisateur nomade qui change fréquemment de machine. Sous condition de disposer d’une connexion internet, il peut travailler sur un projet sans avoir à se préoccuper de l’installation de R sur des PC dont il ne dispose pas de droits administrateurs de toute façon. Le travail collaboratif est un autre contexte où ce dispositif peut se révéler particulièrement avantageux. Il nous permet de nous affranchir des échanges de fichiers toujours hasardeux (j’ai pas reçu ton e-mail ! qui n’a pas été confronté à cette dénégation péremptoire…) avec une gestion des versions aléatoire. Enfin, la solution nous permet de travailler sur un front-end léger, un ordinateur portable par exemple, et de déporter les calculs sur un serveur distant taillé en conséquence (dans le cloud dirait-on aujourd’hui pour faire poétique).
Dans ce tutoriel, nous étudions succinctement les fonctionnalités de R-Fiddle.
Mots clés : logiciel R, programmation R, cloud computing, analyse discriminante, régression logistique, arbre de décision, klaR package, rpart package, sélection de variables
Lien : fr_Tanagra_R_Fiddle.pdf
Fichier : fr_r_fiddle.zip
Références :
R-Fiddle - http://www.r-fiddle.org/#/
Python - Machine learning avec scikit-learn
2015-09-16 (Tag:1766550852310168124)
Honnêtement, mon intérêt pour Python doit beaucoup à la découverte des packages de statistique et de data mining qui l’accompagnent. « scikit-learn » en fait partie. Il se revendique comme une librairie de « machine learning ».Machine learning (apprentissage automatique en français, c’est moins sexy d’un coup) est un champ d’étude de l’intelligence artificielle, qui est une branche de l’informatique. Quand on s’intéresse de plus près aux démarches et aux techniques, on se rend vite compte que nous sommes très proches de ce qu’on appelle par ailleurs modélisation statistique, analyse exploratoire des données, ou encore techniques de data mining. Je le dis souvent à mes étudiants, plutôt que de s’intéresser aux origines ou aux communautés, il est plus profitable de s’intéresser aux finalités. Et scikit-learn propose une panoplie d’outils assez large, couvrant en grande partie l’activité typique du data analyst : l’apprentissage supervisé avec le classement et la régression, l’apprentissage non supervisé (clustering), la réduction de dimension (comprenant les méthodes factorielles), la sélection de modèles, et le preprocessing des données (transformation de variables).
Ce support détaille quelques fonctionnalités de scikit-learn à travers le prisme de l’analyse prédictive. Plusieurs thèmes sont abordés : la construction des modèles, leur évaluation sur un échantillon test, l’utilisation de la validation croisée lors du traitement des petits échantillons, la recherche des paramètres optimaux des algorithmes d’apprentissage, la sélection de variables. Nous nous appuyons sur le fameux fichier PIMA que j’utilise beaucoup dans mes enseignements en raison de ses vertus pédagogiques.
Mots clés : langage python, numpy, scikit-learn, machine learning, data mining, modélisation statistique, validation croisée, matrice de confusion, taux d'erreur, taux de succès, sensibilité, rappel, précision, courbe de gain, courbe lift cumulée
Lien : Machine learning avec scikit-learn
Fichiers : Exemples illustratifs
Références :
Vidéo : Régression Logistique avec Python / Scikit-Learn, juillet 2021
Site officiel : scikit-learn - Machine Learning in Python
Python - Statistiques avec SciPy
2015-08-30 (Tag:787338356911880737)
SciPy est une bilbilothèque de calcul scientifique pour Python. Elle couvre de nombreux domaines (intégration numérique, interpolation, optimisation, traitement d’images, etc.). Dans ce support, nous nous intéressons plus particulièrement aux routines de statistique et de classification automatique (clustering).SciPy s’appuie sur les structures de données de NumPy (vecteurs, matrices).
Mots clés : langage python, numpy, matrice, array, scipy, statistique, classification automatique, apprentissage non-supervisé, clustering
Lien : Statistiques avec SciPy
Fichiers : Exemples illustratifs
Références :
SciPy Reference sur SciPy.org
The Glowing Python, "K-Means clustering with SciPy", 2012.
Emergence Wiki, "Introduction aux tests de normalité avec Python", 2015.
Python - Official Site
Python - Les matrices avec NumPy
2015-08-14 (Tag:7837777332080363759)
Ce support présente la manipulation des matrices via NumPy. Le type array est commun aux vecteurs et matrices, la spécificité tient à l’adjonction d’une seconde dimension pour disposer les valeurs au sein d’une structure lignes x colonnes.Les matrices ouvrent la porte à des opérateurs qui jouent un rôle fondamental en modélisation statistique et en statistique exploratoire (ex. inversion de matrice, résolution d’équations, calcul des valeurs et des vecteurs propres, décomposition en valeurs singulières, etc.).
Mots clés : langage python, numpy, matrice, array, création, extraction
Lien : Les matrices avec NumPy
Fichiers : Exemples illustratifs
Références :
NumPy Reference sur SciPy.org
Pucheu, Corsellis, Bansard, "Python et le module NumPy", 2001.
Haenel, Gouillart, Varoquaux, "Python Scientific Lecture Notes", lu en août 2015.
Python - Official Site
Python - Les vecteurs avec NumPy
2015-08-11 (Tag:3846468465678573627)
Le module « NumPy » (Numeric Python) est particulièrement populaire sous Python parce qu’il propose un ensemble de structures et de routines permettant de gérer efficacement les grands tableaux. Il est de fait sous jacent à de très nombreux modules de calcul scientifique et de manipulation de fichiers numériques (ex. image). Les modules de statistique et de data science ne font pas exception. La très grande majorité d’entre eux utilisent Numpy. Il est donc très important pour nous de cerner au mieux les principales fonctionnalités de cet outil.Dans ce support, je présente le traitement des vecteurs avec les outils de Numpy. Je le présente comme un cas à part en veillant à ne pas déborder sur la gestion des matrices car ce dernier thème fera l’objet d’un autre document.
Mots clés : langage python, numpy, vecteur, array, création, extraction
Lien : Les vecteurs avec NumPy
Fichiers : Exemples illustratifs
Références :
NumPy Reference sur SciPy.org
Pucheu, Corsellis, Bansard, "Python et le module NumPy", 2001.
Haenel, Gouillart, Varoquaux, "Python Scientific Lecture Notes", lu en août 2015.
Python - Official Site
Python - La distribution Anaconda
2015-08-07 (Tag:8658724536747666954)
Arrivé à ce stade de mon cours (cf. les séances précédentes), je souhaitais l’orienter vers le calcul scientifique, en particulier la programmation statistique. J’avais identifié quelques packages comme les incontournables numpy et scipy, d’autres également avaient attiré mon attention, pandas, statsmodels, ou encore scikit-learn par exemple.A priori, la démarche est simple. Il suffit d’installer ces packages pour pouvoir les exploiter. Et là j’ai compris ma douleur. Non pas que l’opération soit compliquée en définitive, mais parce que trouver une documentation simple et directement reproductible sous Windows est apparemment très difficile (en août 2015). Je suis finalement tombé sur une excellente page qui détaille très bien la démarche. Mais ça m’a posé question. Je voyais mal mes étudiants jongler avec ce type de manipulations sur les machines hyper protégées de nos salles informatiques. Les problèmes de configurations qui bouffent une séance TP, où tout le monde reste les bras ballants en attendant que les machines fonctionnent correctement, j’en ai suffisamment vécu comme cela. Il m’est apparu préférable d’opter pour une solution plus avenante.
Et je l’ai trouvée en Anaconda. Il s’agit d’une distribution alternative de Python. Elle intègre de manière standard un grand nombre de packages, notamment ceux dédiés au calcul scientifique. Ils sont par conséquent disponibles dès l’installation de la distribution. Et pour ceux qui souhaitent aller plus loin, pour une mise à jour ou pour l’intégration d’un package non initialement prévu par exemple, elle propose le gestionnaire de package Conda qui semble simplifier grandement les opérations. Enfin, Anaconda propose l’environnement de développement Spyder, plus sympathique que l’usuel IDLE, et la console IPython, là également avec des fonctionnalités supplémentaires.
Ce tutoriel décrit brièvement l’installation et l’utilisation de la distribution Anaconda.
Mots clés : langage python, anaconda, EDI, environnement de développement intégré, spyder, ipython
Lien : La distribution Anaconda
Références :
Anaconda - Scientific Python Distribution
Python - Official Site
Les fichiers sous Python - Diapos
2015-08-04 (Tag:6640479352643067959)
Construire des applications un tant soit peu évoluées nécessite de savoir stocker les informations sur un support non volatile. C’est le rôle des fichiers. Ils permettent de pérenniser les données, ils peuvent également servir de support pour les communications inter-applications.Ce support est consacré aux fichiers sous Python. Nous nous focalisons sur les fichiers texte non-structuré ou structuré. Dans ce dernier cas, nous traiterons des formats json (javascript objet notation) et xml (extensible markup language), largement utilisés pour l’échange de contenus complexes.
Mots clés : langage python, fichier texte, json, xml
Lien : Les fichiers sous Python
Fichiers : Exemples illustratifs
Références :
Python - Official Site
Les classes sous Python - Diapos
2015-07-31 (Tag:4768607613632218514)
Ce support décrit la déclaration, la définition, l’implémentation et l’instanciation des classes sous Python. La présentation est conventionnelle pour que la transposition aux autres langages ne soit pas déroutante. Python en effet intègre des particularités qui sont étonnantes je trouve. Les détailler amènerait des fausses idées qui pourraient être préjudiciables aux étudiants lorsqu’ils étudieront d’autres langages objets. J’ai donc préféré les passer sous silence.Les mécanismes de classes telles que l’héritage et le polymorphisme sont abordés, que même que les collections d’objets.
Mots clés : langage python, classe, instance, programmation objet, champs, méthodes, héritage, polymorphisme, liste polymorphe, variable de classe
Lien : Les classes sous Python
Fichiers : Exemples illustratifs
Références :
Python - Official Site
Collection d'objets sous Python - Diapos
2015-07-28 (Tag:2742477050986730901)
Ce support traite des collections d’objets. Python fournit des outils souples et faciles à utiliser. Les tableaux peuvent être de taille fixe ou variable, modifiables ou non, l’accès peut être réalisé avec un indice ou des plages d’indices. L’utilisation des indices négatifs n’est pas commun et semble, à ma connaissance, être spécifique à Python.Le type dictionnaire permettant de s’affranchir des indices mérite une mention spéciale.
Un aparté à propos des chaînes de caractères qui constituent un cas particulier des listes est également proposé. Des méthodes qui leur sont propres ouvre la porte à des traitements très puissants (ex. recherche, comptage de séquences, etc.).
Mots clés : langage python, tuple, liste, dictionnaire, chaîne de caractères
Lien : Collections d'objets sous Python
Fichiers : Exemples illustratifs
Références :
Python - Official Site
Fonctions et modules sous Python - Diapos
2015-07-24 (Tag:6346863206166865371)
Ce support décrit l’élaboration et l’utilisation des fonctions sous Python. Les fonctions sous Python rappellent celles de R, entres autres : les paramètres ne sont pas typés, il est possible de leur attribuer des valeurs par défaut, il est possible de spécifier leur nom lors de l’appel. Le mécanisme des variables globales est un peu particulier en revanche.Les modules permet d’améliorer la modularité des applications. Leur création et leur usage est réellement facile sous Python. Des modules standards directement utilisables sont disponibles (math, random, etc.).
L'installation et la mise en oeuvre des modules spécialisés (statistique, etc.) seront décrits dans un autre support.
Mots clés : langage python, fonctions, procédures, modules, passage de paramètres, portée des variables
Lien : Programmation modulaire sous Python
Fichiers : Exemples illustratifs
Références :
Python - Official Site
Introduction à Python - Diapos
2015-07-22 (Tag:8883555826417298867)
Mon premier contact avec Python date du début des années 2000. Un langage de programmation inconnu - pour moi - m’intéresse toujours. J’avoue que l’intérêt ne m’a pas forcément sauté aux yeux après avoir effectué quelques essais. Un langage objet de plus, interprété de surcroît (et l’interpréteur ne brillait pas par ses performances à cette époque), ne me semblait pas follement enthousiasmant par rapport à l’existant.Ma curiosité a de nouveau été attisée au milieu des années 2000 lorsque je me suis intéressé au logiciel de data mining Orange. En effet, ce dernier proposait une librairie pour Python, donnant à l’utilisateur de définir des séquences de traitement évoluées permettant de mener des études complètes, en partant de la préparation des données, en passant par la construction de modèles prédictifs et leur évaluation, pour aboutir à leur déploiement.
C’était un moment crucial parce qu’à la même période, je m’interrogeais sur l’opportunité d’enseigner R en tant que langage de programmation - et non pas en tant que simple logiciel de statistique, la nuance mérite d’être soulignée - à l’Université. Finalement, j’avais fait le pari de R. Bien m’en a pris, c’est un cours qui est apprécié, et la page web dédiée est la plus visitée de mon site.
Ces dernières années, j’ai vu Python arriver (revenir) en force, avec deux caractéristiques qui m’interpellent forcément : il est devenu un des langages privilégiés pour l’enseignement de la programmation ; il est très populaire dans le domaine du data science, au point d’être positionné comme un concurrent sérieux pouvant mettre à mal la suprématie de R. Hé ben dis donc, manifestement, il est temps de reconsidérer la question attentivement.
Pourquoi cette percée de Python ? La question est vaste. Pour ma part, j’ai identifié plusieurs aspects qui m’intéressent particulièrement. (1) Il possède toutes les fonctionnalités d’un langage de programmation évolué, et il est pourtant simple à appréhender. Pour préparer mon cours et me familiariser avec le langage, je me suis échiné à refaire tous les TP de mes cours de programmation. Je les ai réalisés en un temps record alors que je ne connaissais pas du tout le langage. Ça ne trompe pas ce genre de choses. (2) Il propose aujourd’hui des bibliothèques de calcul performantes pour le traitement et l’analyse de données, en particulier pour le machine learning. Celui d’Orange que j’avais cité plus haut, mais aussi scikit-learn que je dois absolument tester dans un prochain tutoriel. Et il y en a d’autres. (3) Un élément clé dans le contexte actuel où le big data provoque la frénésie, voire l’hystérie, de tous les acteurs de la société, il permet d’implémenter des applications dans des nouveaux environnements tels que Hadoop (programmation map reduce) ou Spark (en utilisant les API de MLlib). Ouh là là, là aussi je sens que des tutoriels vont venir. (4) Enfin, par rapport à R, il présente l’avantage d’être plus généraliste, plus adapté à un cours générique d’initiation à la programmation. R en revanche me semble plus approprié lorsqu’il s’agit d’approfondir la programmation statistique.
J’ai donc décidé de passer à Python mon cours de programmation en L3 IDS. Ce premier post me donne l’opportunité de partager mes diapos pour la première séance où j’introduis les principales notions du langage, avant de lancer les étudiants sur une série d’exercices sur machine. Les étudiants sont assez hétérogènes, certains ont déjà programmé dans d’autres langages, d’autres ont eu à peine 6 heures d’algorithmie dans les jambes. Je dois schématiser autant que possible, voire simplifier, pour ne laisser personne en chemin.
D’autres diapos suivront, abordant les différents thèmes de la programmation Python.
Mots clés : langage python, types de données, affectation, calculs, structures algorithmiques, branchements conditionnels, boucles
Lien : Introduction à Python
Fichiers : Exemples illustratifs
Références :
Python - Official Site
Programmation MapReduce sous R - Diapos
2015-07-14 (Tag:3117218234503629459)
Tous les étés, j’essaie de faire le bilan de mes cours et je regarde ceux que je pourrais faire évoluer. Introduire le principe MapReduce dans mon cours de programmation R en Master SISE me titillait depuis un moment déjà. J’avais écrit plusieurs documents à cet effet (qui sont parmi les plus consultés sur ce site d’ailleurs). Mais convertir un tutoriel en cours n’est pas aussi simple qu’on pourrait le penser. Une séance se construit et doit suivre une certaine progression. La pire des configurations qui puisse arriver, c’est l’étudiant les bras ballants devant le PC qui me sort « je ne comprends pas du tout ce qu’on doit faire ». Ouh là là, c’est généralement très mauvais signe ce genre de choses. Un thème supplémentaire veut dire aussi qu’il faudra au mieux tasser les autres chapitres sur les séances restantes. Il faut être prudent, à vouloir tout faire, on ne fait pas grand chose souvent.Tout cela longuement soupesé, voici les diapos que j’utiliserai pour la 7ème séance de mon cours de programmation R. Il ne me reste plus qu’à élaborer les exercices pratiques qui complètent le créneau horaire. L’idée comme d’habitude est de commencer avec des questions simples avant d’embrayer avec des sujets nettement compliqués qui devraient - sans avoir à le demander explicitement, toute l’astuce est là - emmener les étudiants à les finir en travail personnel.
Mots-clés : big data, big data analytics, mapreduce, package rmr2, hadoop, rhadoop, logiciel R, langage R
Lien : Programmation MapReduce sous R
Références :
Tutoriel Tanagra, "MapReduce avec R", février 2015.
Tutoriel Tanagra, "Programmation R sous Hadoop", avril 2015.
Big Data et Machine Learning...
2015-07-05 (Tag:2939970141871607935)
... Manuel du data scientist« Big data », « data science » sont des termes dont la popularité est croissante dixit Google Trends. « Machine learning » revient à la mode. Regroupant ces trois appellations, cet ouvrage s’inscrit à l’évidence dans l’air du temps. Son objectif est de clarifier les différentes notions qui gravitent dans la sphère « big data », un domaine que tout le monde identifie comme porteur de perspectives majeures pour les années à venir.
Il se propose de nous guider dans la compréhension des enjeux des projets de data science, en traitant des concepts théoriques (nouvelles approches de stockage des données, méthodes d’apprentissage automatique), et en décrivant les technologies et les outils. Il s’adresse aux décideurs informatiques, aux professionnels du décisionnel et des statistiques, aux architectes informatiques, aux responsables métiers.
Mots clés : big data, data science, data scientist, machine learning, statistical learning
Lien : Résumé
Références :
P. Lemberger, M. Batty, M. Morel, J.L. Rafaëlli, "Big Data et Machine Learning - Manuel du data scientist", Dunod, 2015.
Data Science Studio
2015-06-19 (Tag:4518920558049338029)
L’évolution du métier de statisticien s’accompagne de l’arrivée de logiciels de nouvelle génération. Mon attention a été attirée récemment par le logiciel Data Science Studio (DSS) de la société Dataiku. Un logiciel de plus me direz-vous. Oui et non. Certes, la trame du processus d’analyse reste la même : accéder aux données, les préparer, créer des modèles statistiques, valider ces derniers. Mettre au point des méthodes et des implémentations performantes reste d’actualité. C’est le mode opératoire proposé qui est nouveau. L’outil fonctionne de manière comparable à Azure Machine Learning Studio de Microsoft que j’avais présenté sur ce blog bien que, fondamentalement, il soit différent parce que ne repose pas exclusivement sur le paradigme SaaS (logiciel en tant que service) .Les traits communs de ces outils de nouvelle génération peuvent se résumer de la manière suivante (de manière non exhaustive) : architecture client-serveur, travail en ligne et pilotage via une interface web, possibilité de mettre en place un travail collaboratif, simplification à l’extrême des process, centré sur les aspects opérationnels.
Dans ce tutoriel, je présente la version Community Edition du logiciel DSS. Je me situe sur un processus « Machine Learning » d’analyse prédictive c.-à-d. développer un modèle statistique de scoring. J’explore de manière relativement sommaire les possibilités de l’outil. D’une part, parce que dans une première approche, il convient de rester schématique pour bien discerner ses principales caractéristiques. D’autre part, parce qu’il serait vain de vouloir tout résumer dans un document de quelques pages toutes ses fonctionnalités. Le lecteur curieux pourra se référer au site de documentation de l’éditeur ou aux tutoriels accessibles sur youtube.
Mots-clés : régression logistique, analyse prédictive, machine learning, arbre de décision
Lien : fr_Tanagra_DSS_dataiku.pdf
Fichier : spambase.txt
Références :
Dataiku - Data Science Studio - http://www.dataiku.com/
Tutoriel Tanagra, "Azure Machine Learning", novembre 2014.
Extraction des règles d'association - Diapos
2015-06-04 (Tag:1339531931002712953)
L’extraction des règles d’association a connu une popularité fulgurante dès leur publication par Agrawal et al. (1993). Notamment parce que la méthode répond à un réel besoin (rechercher les relations pertinentes entre les variables est la base même de la statistique exploratoire), parce qu’elle produit une connaissance facile à interpréter et, reconnaissons-le, parce qu’elle a ouvert un champ d’étude où les chercheurs ont pu s’exprimer à loisir (développement d’algorithmes efficaces pour le traitement des très gros volumes, développement des mesures pour identifier les règles les plus « intéressantes », etc.).Dans ces diapos que j’utilise pour mes enseignements, je m’attache surtout à décrire les finalités et la démarche. L’exposé en lui-même prend peu de temps durant la séance. La suite est consacrée à la mise en œuvre sur plusieurs outils. Je présente quelques logiciels (SIPINA avec le module d’extraction de règles, TANAGRA, R avec le package « arules », SPAD), mais j’aurais tout aussi bien pu parler de KNIME, RAPIDMINER, ORANGE ou WEKA. Les logiciels diffèrent essentiellement par le format de données accepté en entrée, le paramétrage par défaut, et le mode de présentation des sorties. Un des enjeux de la séance justement est de faire travailler les étudiants sur différents outils et de comparer les règles produites. L’algorithme étant déterministe, on devrait obtenir les mêmes résultats à paramétrage égal. Les étudiants peuvent le vérifier.
Mots clés : règles d'association, itemset, itemset fréquent, itemset fréquent fermé, itemset fréquent maximal, eclat, apriori, fp-growth, support, confiance, lift, mesures d'intérêt des règles
Composants Tanagra : A PRIORI, A PRIORI MR, A PRIORI PT, FREQUENT ITEMSETS, SPV ASSOC RULE, SPV ASSOC TREE
Lien : Règles d'association
Références :
Tutoriel Tanagra, "Règles d'association - Comparaison de logiciels", novembre 2008.
Pratique de la régression - Version 2.1
2015-05-23 (Tag:8264563616369111623)
Miraculeusement, je vais disposer de plus d’heures pour le cours d’Économétrie - Modélisation statistique en L3 IDS. Les bonnes nouvelles vous donnent toujours du cœur à l’ouvrage. Je me suis demandé comment je pouvais faire évoluer ce cours pour tirer parti de cette nouvelle configuration.La première piste est d’étoffer les TD où nous avancions un peu à marche forcée, je le reconnais. Avec des séances supplémentaires, nous pourrons aborder plus de sujets, mais aussi élargir la panoplie des logiciels utilisés. Je suis persuadé que faire travailler les étudiants sur différents outils est une très bonne manière… de les détacher des outils justement, de prendre de la hauteur pour s’attacher à l’essentiel. Quand on sait vraiment conduire, que ce soit une 2 CV ou une Lamborghini, on saura faire. Après, il y a des spécificités qu’il faut savoir exploiter, mais c’est après, lorsqu’on veut approfondir. On sait très bien qu’il y a des choses qu’on pourra faire avec une 2 CV mais pas avec une Lamborghini, et inversement.
La seconde piste est de compléter le cours en abordant /approfondissant certains thèmes. La question de la direction à prendre se pose. Beaucoup de domaines sont déjà abordés, comment élargir sans semer en route les étudiants ? Après réflexion, les pistes de l’ANOVA et ANCOVA me paraissent les plus intéressantes - et les moins déroutantes - en utilisant le prisme de la régression sur variables qualitatives, nominales et ordinales. Les étudiants verront ces sujets (ANOVA, etc.) dans la suite de leur cursus. En adoptant délibérément l’éclairage de la régression, on évite la redondance, tout en leur permettant de consolider leurs compétences en terme d’analyse.
Dans cette nouvelle version 2.1 du fascicule consacré à la « Pratique de la Régression Linéaire Multiple », je me suis donc attelé à compléter le chapitre 4 consacré à la régression sur variables exogènes qualitatives, qui passe à 57 pages maintenant. J’ai bénéficié de l’éclairage additionnel de la page Régression de l’IDRE (Institute for Digital Research and Education - UCLA) où la question de la régression sur exogènes qualitatives est brillamment exploré avec des exemples traités sous les logiciels SAS et R. C’est Byzance. J’ai intégré les thèmes les plus intéressants dans le chapitre existant (qui a été un peu réorganisé en conséquence), en reproduisant les calculs - sur les données du fascicule - sous Excel.
Mots-clés : régression sur exogènes qualitatives, anova, ancova, comparaison de moyennes, analyse des interactions, analyse de contrastes
Ouvrage : Ricco Rakotomalala, « Pratique de la Régression Multiple - Diagnostic et sélection de variables - Version 2.1 », Mai 2015.
Données : Dataset - Pratique de la régression
Références : Ma page de cours « Économétrie ».
Reconnaissance faciale et détection de l’âge
2015-05-19 (Tag:4237537811761693713)
A cette époque de la saison, je réfléchis aux thèmes des projets big data que je pourrais proposer à mes étudiants du Master SISE (Statistique et Informatique) l’année prochaine. Je dois toujours composer avec deux contraintes opposées : il faut que les sujets soient assez classiques pour que les étudiants puissent consolider leurs acquis ; mais il faut aussi qu’ils soient assez innovants pour titiller leur intérêt, pour les faire sortir des sentiers battus, rechercher de l’information par eux-mêmes, défricher un terrain inconnu afin d’apprendre à discerner l’essentiel de l’accessoire.Mon rôle dans cette histoire consiste à cerner suffisamment chaque thème afin de déterminer d’une part son intérêt pédagogique, d’autre part la faisabilité du projet dans le temps qui est imparti, environ 1 mois sachant que les étudiants doivent dans le même temps suivre les cours, travailler sur les projets des autres matières, voire passer les épreuves validant certains UE (Unité d’Enseignement). Il ne s’agit pas de les envoyer au casse-pipe sans filet.
Cette année, entres autres projets potentiels, j’ai décidé de m’intéresser à la reconnaissance faciale. Ce n’est pas très nouveau en soi, mais nous faisons rarement travailler nos étudiants là-dessus, je me dis que le terrain peut s’avérer fertile. En me documentant sérieusement sur la question, je suis tombé sur un article décrivant un nouvel outil - tout bonnement extraordinaire - mis en ligne par Microsoft. Il détermine automatiquement votre âge et votre sexe à partir de votre photo. On va nettement plus loin que la simple reconnaissance dans ce cas. Bien évidemment, j’ai multiplié les tests : photos prises de face, de biais, éclairage fort, faible, pénombre, contre-jour, visage rasé de près ou pas, etc. A force, on devine à peu près les critères qui peuvent jouer. J’avoue surtout avoir passé un moment particulièrement amusant en testant différentes photos et noter l’âge proposé pour chaque configuration. Au passage, Microsoft dit qu’il ne conserve pas les photos soumises. Heureusement car, dans le cas contraire, ils auraient eu là une occasion unique de se constituer une base de photos d’identité mondiale. Bon, dans le même temps, des plaisantins doivent s’ingénier à tester leurs animaux domestiques, leurs voitures, ou que sais-je encore, je n’ose même pas imaginer.
Peut-être qu’on n’ira pas jusqu’à ce stade dans les projets - détection de l’âge et du sexe à partir de photos d’identité - avec mes étudiants. Mais il y a clairement matière à travailler dans le domaine. J’ai même lu récemment qu’on pouvait effectuer la reconnaissance faciale… de dos (ce n'est pas vraiment ça quand on lit l'article, mais l'idée est amusante). On n’arrête pas le progrès, on n’arrête pas l’imagination des ingénieurs surtout.
Testez-vous : quel est votre âge ?
Mots-clés : reconnaissance faciale, traitement d’images, image mining, big data analytics, fouille de données complexes
Prédicteurs catégoriels en Rég. Logistique
2015-04-29 (Tag:5531536566028256493)
La régression logistique vise à construire un modèle permettant de prédire une variable cible binaire à partir d’un ensemble de variables explicatives (descripteurs, prédicteurs, variables indépendantes) numériques et/ou catégorielles. Elles sont traitées telles quelles lorsque ces dernières sont numériques. Elles doivent être recodées lorsqu’elles sont catégorielles. Le codage en indicatrices 0/1 (dummy coding) est certainement la méthode la plus utilisée.La situation se complique lorsque l’on procède à une sélection de variables. L’idée est de déterminer les prédicteurs qui contribuent significativement à l’explication de la variable cible. Il n’y a aucun problème quand nous considérons une variable numérique, elle est soit exclue soit conservée dans le modèle. Mais comment procéder lorsqu’on manipule une explicative catégorielle ? Devons-nous traiter les indicatrices associées à une variable comme un bloc indissociable ? Ou bien pouvons-nous les dissocier, en ne conservant que certaines d’entre elles ? Est-ce que cette stratégie est légitime ? Comment lire les coefficients dans ce cas.
Dans ce tutoriel, nous étudions les solutions proposées par les logiciels R 3.1.2, SAS 9.3, Tanagra 1.4.50 et SPAD 8.0. Nous verrons que les algorithmes de sélection de variables s’appuient sur des critères spécifiques selon les logiciels. Nous constaterons surtout qu’ils proposent des approches différentes lorsque nous sommes en présence des explicatives catégorielles. Cela n’est pas sans conséquence sur la qualité prédictive des modèles.
Mots-clés : régression logistique, sélection de variables, variables explicatives catégorielles, codage disjonctif complet, sas, proc logistic, logiciel R, stepaic, spad
Composants : BINARY LOGISTIC REGRESSION
Lien : fr_Tanagra_Categorical_Selection_Log_Reg.pdf
Fichier : heart-c.xlsx
Références :
R. Rakotomalala, "Pratique de la régression logistique - Régression logistique binaire et polytomique", Version 2.0, Juin 2011.
Tutoriel Tanagra, "Codage disjonctif complet", mars 2008.
Programmation R sous Hadoop
2015-04-06 (Tag:6099329878879122538)
L’objectif de ce tutoriel est de montrer, in fine, la programmation sous R de l’algorithme de comptage de mots – le fameux « wordcount » – à partir d’un ensemble de fichiers stockés sur HDFS.L’exemple « wordcount » fait référence. Il est décrit partout sur le web. Mais, à bien y regarder, les tutoriels qui le reprennent sont (très) rarement reproductibles. Les fichiers de travail ne sont pas disponibles. On ne voit pas vraiment comment on y accède avec R lorsqu’ils sont stockés sur le système de fichier HDFS. Bref, on ne peut pas faire tourner les programmes et se rendre compte réellement de leur mode de fonctionnement.
Nous allons reprendre tout cela étape par étape. Nous décrirons avec force détails chaque stade de processus, en partant de l’installation d’ un cluster hadoop mono-nœud sur une machine virtuelle jusqu’à la programmation sous R, en passant par l’installation de R et de l’environnement de programmation client – serveur RStudio Server.
Les étapes et, par conséquent les sources d’erreurs, sont nombreuses. Nous utiliserons moults copies d’écran pour appréhender concrètement chaque opération. D’où ce format de présentation inhabituel pour un tutoriel.
Mots-clés : big data, big data analytics, mapreduce, package rmr2, package rhdfs, hadoop, rhadoop, logiciel R, rstudio, rstudio server, cloudera, langage R
Didacticiel : fr_Tanagra_Hadoop_with_R.pdf
Fichiers : hadoop_with_r.zip
Références :
Hugh Devlin, "Mapreduce in R", Jan. 2014.
Tutoriel Tanagra, "MapReduce avec R", février 2015.
Tutoriel Tanagra, "Programmation R sous Spark avec SparkR", mai 2016.
Classeur économétrie
2015-04-01 (Tag:1050651274747894489)
Un contact internet très récent m’a rappelé un outil que j’avais mis en ligne il y a une dizaine d’années et qui n’était pas référencée sur ce blog. Je l’avais quelque peu oublié j’avoue. A force de faire tellement de choses, je ne sais plus parfois si j’ai déjà abordé tel ou tel thème dans mes tutoriels. Heureusement, la recherche par mots-clés sur ce site me permet de me repérer rapidement.L’outil en question est un classeur Excel dédié à la régression linéaire multiple. Il a été programmé par Mlle NGUYEN LAO Bao Truc, étudiante de notre département informatique et statistique, alors en stage à l’été 2005. Il reprend dans les grandes lignes le contenu de mon cours d’économétrie de Licence L3 Informatique décisionnelle et statistique.
Ainsi, les principaux résultats que la macro produit à partir d’un tableau individus - variables sont : calcul des statistiques descriptives, estimation des coefficients, élaboration du tableau d'analyse de variance, test de significativité globale du modèles, test de significativité individuelle des coefficients, analyse des résidus, détection des points atypiques et influents, détection de la colinéarité.
L’outil n’est pas une macro complémentaire à proprement parler. Il faut copier et coller vos données dans la feuille principale du classeur. Le transformer en add-in générique est d’ailleurs une extension qui peut s’avérer intéressante. Il faudrait le compléter avec un dispositif - boîte de dialogue de paramétrage par exemple - permettant de sélectionner les données, où qu’elles soient situées dans un classeur quelconque, de spécifier les paramètres de l’analyse (niveau de confiance), etc. Avis aux férus de programmation VBA.
Mots-clés : régression linéaire simple, régression linéaire multiple, économétrie, classeur excel, macro-complémentaire, add-in
Didacticiel : Classeur régression - Manuel de l'utilisateur
Classeur Excel : Regression_L3_IDS.xls
Référence :
Ricco Rakotomalala, "Cours économétrie - L3 IDS", Département Informatique et Statistique, Université Lyon 2.
Hyper-threading et disque SSD
2015-03-15 (Tag:5382650396947939957)
Après plus de 6 années de bons et loyaux services, j'ai décidé de changer ma machine de développement. Il faut dire que l'ancienne (Intel Core 2 Quad Q9400 2,66 Ghz tournant sous Windows 7 64 bits) commençait à émettre des bruits inquiétants. Les ventilateurs soufflaient au maximum quasiment en permanence. J'étais obligé de mettre de la musique pour couvrir les borborygmes de la bête et pouvoir travailler en toute quiétude.Bon, le choix de la nouvelle machine était une autre affaire. J'ai passé l'âge de la course à la puissance - qui est forcément vaine de toute manière, vu l'évolution fulgurante de l'informatique. J'étais néanmoins sensible à deux aspects que je ne pouvais pas évaluer auparavant : est-ce que la technologie hyper-threading est efficace dans la programmation multithread des algorithmes de data mining ? Est-ce qu'utiliser des fichiers temporaires pour soulager l'occupation mémoire prend une autre tournure lorsqu'on s'appuie sur un disque SSD.
La nouvelle bête est ainsi équipée d'un processeur Core I7 4770S cadencé à 3,1 Ghz (4 cœurs physiques mais 8 threads logiques avec la technologie hyper-threading) et d'un disque système SSD. Ce n'est pas la gloire mais ça me permet d'évaluer les deux thèmes ci-dessus en reprenant les calculs décrits dans d'anciens tutoriels que j'avais mis en ligne il y a un certain temps déjà : "Multithreading équilibré pour la discriminante" (juin 2013), où il est question d'une implémentation multithread, le nombre de threads est paramétrable, de l'analyse discriminante ; "Sipina - Traitement des très grands fichiers" (octobre 2009), où je présentais une solution qui consistait à copier les données organisées en colonnes sur disque (bien avant l'heure - la solution date de 1998, du temps où disposer de 64 Mo de RAM était éminent - une version très fruste des bases de données orientées colonnes), tous les accès lors de la construction des arbres se fait sur disque, un système de cache vient accélérer la lecture.
Nous reproduisons dans ce tutoriel les deux études précitées utilisant le logiciel SIPINA. Notre objectif est d'évaluer le comportement de ces solutions (implémentation multithread, copie des données sur disque pour alléger l'occupation mémoire) sur notre nouvelle machine qui, de par ses caractéristiques, devrait en tirer expressément avantage.
Mots-clés : hyper-threading, disque ssd, solid-state drive, multithread, multithreading, traitement des très grands fichiers, core i7, sipina, arbres de décision, analyse discriminante linéaire
Didacticiel : fr_Tanagra_Hyperthreading.pdf
Références :
Tutoriel Tanagra, "Multithreading équilibré pour la discriminante", juin 2013.
Tutoriel Tanagra, "Multithreading pour les arbres de décision", novembre 2010.
Tutoriel Tanagra, "Sipina - Traitement des très grands fichiers", octobre 2009.
Analyse de corrélation - Version 1.1
2015-03-08 (Tag:898574720958927874)
La corrélation est souvent présentée vite fait comme un préambule à la régression simple dans les ouvrages d'économétrie. Pourtant, elle ouvre la porte à des analyses très riches sur les relations entre les variables. De nombreuses méthodes exploratoires reposent sur la notion de corrélation entre les variables.La première version de cet ouvrage (version 1.0, mai 2008) essayait d'aller un peu plus loin qu'un simple exposé de principe sur la corrélation et les calculs y afférents. Je me suis appuyé sur de nombreuses sources. Mais j'avoue surtout avoir été influencé par la lecture de la monographie de Chen et Popovich (2002). Rarement j'ai vu une telle qualité de rédaction autour de la notion de corrélation. Je n'aurais jamais pensé non plus qu'on pouvait en écrire autant sur la corrélation.
Dans cette nouvelle version (1.1), j'ai (re)découvert le package "psych" de Revelle (version 1.5.1 - janvier 2015) pour R en accédant à l'ouvrage de statistique sous R qu'il a mis en ligne (cf. références ci-dessous). J'ai constaté que le package intégrait plusieurs procédures dédiées à la corrélation. J'ai ainsi pu valider tous les calculs que j'ai pu faire sur tableur dans la version précédente de mon propre ouvrage (obtenir des résultats concordants avec d'autres chercheurs est toujours rassurant), j'ai aussi découvert de nouveaux outils traitant des matrices des corrélations.
Une section consacrée aux traitements sous R - utilisant le package "psych" - a été rajoutée en annexes.
Bien évidemment, le fichier Excel retraçant tous les exemples illustratifs accompagne ce document.
Mots-clés: corrélation, comparaison de corrélations, corrélation partielle, corrélation semi-partielle, rho de spearman, tau de kendall, transformation de fisher, package psych
Ouvrage : Analyse de corrélation - Étude des dépendances - Variables quantitatives (Version 1.1)
Données : Dataset - Analyse de corrélation
Autres références :
Chen P., Popovich P., "Correlation: Parametric and Nonparametric Measures", Sage University Papers Series on Quantitative Applications in the Social Sciences, no. 07-139, 2002.
Revelle W., "An introduction to psychometric theory with applications in R", consulté en Mars 2015.
MapReduce avec R
2015-02-15 (Tag:8610923225290246091)
« Big Data » (« mégadonnées » ou « données massives » en français), en veux-tu en voilà. Tout le monde en parle, c’est le sujet à la mode. Il suffit de voir l’évolution des requêtes associées sur Google Trends pour s’en rendre compte. Leur valorisation est un enjeu fort, on parle de « big data analytics ». Dans les faits, il s’agit d’étendre le champ d’application des techniques de statistique exploratoire et de data mining à de nouvelles sources de données dont les principales caractéristiques sont la volumétrie, la variété et la vélocité.L’informatique distribuée est un pilier essentiel du big data. Il est illusoire de vouloir augmenter à l’infini la puissance des serveurs pour suivre la croissance exponentielle des informations à traiter. La solution passe par une coopération efficace d’une myriade de machines connectées en réseau, assurant à la fois la gestion de la volumétrie et une puissance de calcul décuplée. « Hadoop » s’inscrit dans ce contexte. Il s’agit d’un framework Java libre de la fondation Apache destiné à faciliter la création d’applications distribuées et échelonnables . « Distribuées » signifie que le stockage et les calculs sont réalisés à distance sur un cluster (groupe) de nœuds (de machines). « Echelonnables » dans le sens où si l’on a besoin d’une puissance supplémentaire, il suffit d’augmenter le nombre de nœuds sans avoir à remettre en cause les programmes et les architectures. Dans cette optique, MapReduce de Hadoop joue un rôle important. C’est un modèle de programmation qui permet de distribuer les opérations sur des nœuds d’un cluster. L’idée maîtresse est la subdivision des tâches que l’on peut dispatcher sur des machines distantes, ouvrant ainsi la porte au traitement de très grosses volumétries. Une série de dispositifs sont mis en place pour assurer la fiabilité du système (ex. en cas de panne d’un des nœuds).
Dans ce tutoriel, nous nous intéressons à la programmation MapReduce sous R. Nous nous appuierons sur la technologie RHadoop de la société Revolution Analytics. Le package « rmr2 » en particulier permet de s’initier à la programmation MapReduce sans avoir à installer tout l’environnement, tâche qui, en soi, est déjà suffisamment compliquée comme cela. Il existe des tutoriels consacrés à ce thème sur le net. Celui Hugh Devlin (janvier 2014) en est une illustration . Mais il s’adresse à un public connaisseur des statistiques et de la programmation R, en commençant notamment par faire le parallèle (c’est de circonstance) avec la fonction lapply() que les apprentis du langage R ont souvent bien du mal à appréhender. Au final, il m’a fallu beaucoup de temps pour réellement saisir la teneur des fonctions étudiées. J’ai donc décidé de reprendre les choses à zéro en commençant par des exemples très simples dans un premier temps, avant de progresser jusqu’à la programmation d’algorithmes de data mining, la régression linéaire multiple en l’occurrence.
Mots-clés : big data, big data analytics, mapreduce, package rmr2, anova, régression linéaire, hadoop, rhadoop, logiciel R, langage R
Didacticiel : fr_Tanagra_MapReduce.pdf
Fichiers : fr_mapreduce_with_r.zip
Références :
Hugh Devlin, "Mapreduce in R", Jan. 2014.
Tutoriel Tanagra, "Programmation parallèle sous R", juin 2013.
Tutoriel Tanagra, "Programmation R sous Hadoop", avril 2015.
Validation croisée, Bootstrap - Diapos
2015-02-12 (Tag:1897308461220250408)
En apprentissage supervisé, Il est couramment admis qu’il ne faut pas utiliser les mêmes données pour construire un modèle prédictif et estimer son taux d’erreur. L’erreur obtenue dans ces conditions est (très souvent) trop optimiste, laissant à croire que le modèle présentera d’excellentes performances en prédiction.Un schéma type consiste à subdiviser les données en 2 parties (holdout approach) : un premier échantillon, dit d’apprentissage sert à élaborer le modèle ; en second échantillon, dit de test, sert à en mesurer les performances. Les indicateurs reflètent alors honnêtement le comportement du modèle en déploiement. Hélas, sur des petites bases, cette approche pose problème. En réduisant le volume de données présenté à l’algorithme d’apprentissage, nous prenons le risque de ne pas saisir toutes les subtilités de la relation entre la variable cible et les prédictives. Dans le même temps, la partie dévolue au test reste réduite, l’estimation de l’erreur est empreint d’une forte variabilité.
Dans ce support, je présente les techniques de ré-echantillonnage (validation croisée, leave-one-out et bootstrap) destinées à estimer l’erreur du modèle élaboré à partir de la totalité des données disponibles. Une étude sur données simulées (les «ondes» de Breiman et al., 1984) permet d'analyser le comportement des approches en les croisant avec différents algorithmes d’apprentissage (arbres de décision, analyse discriminante linéaire, réseaux de neurones [perceptron multi-couches]).
Mots clés : méthodes de ré-échantillonnage, évaluation de l’erreur, validation croisée, bootstrap, leave one out, resampling error estimate, holdoutn schéma apprentissage-test
Composants : CROSS-VALIDATION, BOOTSTRAP, TEST, LEAVE-ONE-OUT
Lien : resampling_evaluation.pdf
Références :
A. Molinaro, R. Simon, R. Pfeiffer, « Prediction error estimation: a comparison of resampling methods », in Bioinformatics, 21(15), pages 3301-3307, 2005.
Tutoriel Tanagra, "Validation croisée, bootstrap, leave-one-out", mars 2008.
Arbres de classification - Théorie et pratique
2015-02-11 (Tag:1749816089696635444)
La classification automatique ou analyse typologique (« clustering » en anglais) vise les regrouper les individus en paquets homogènes. Les individus qui ont des caractéristiques similaires (proches) sont réunis dans un même groupe (cluster, classe) ; les individus présentant des caractéristiques dissemblables (éloignées) sont associés à des groupes différents.Nous présentons dans ce tutoriel les arbres de classification. La démarche s’intègre dans un cadre cohérent par rapport aux arbres de décision et régression, bien connus en data mining. La différence réside dans la mise en place d’un critère multivarié pour quantifier la pertinence des segmentations durant la construction de l’arbre. Nous avions déjà présenté succinctement la méthode dans un précédent didacticiel (avril 2008). Mais nous nous étions focalisés sur les aspects opérationnels (manipulations dans Tanagra et lecture des résultats). Dans ce nouveau document, nous nous attardons sur les fondements théoriques de l’approche. Nous montrons que nous pouvons appréhender de manière indifférenciée les bases comportant des variables actives quantitatives ou qualitatives, ou un mix des deux.
Par la suite, nous détaillons la mise en œuvre de la méthode à l’aide de plusieurs logiciels dont SPAD qui, à ma connaissance, est le seul à proposer une interface graphique interactive pour la construction des arbres de classification.
Mots clés : classification automatique, clustering, arbres de classification, interprétation des classes, clustering tree, valeur test, spad, ict, logiciel R, package party
Composants : MULTIPLE CORRESPONDENCE ANALYSIS, CTP, CT, GROUP CHARACTERIZATION
Lien : fr_Tanagra_Clustering_Tree.pdf
Données : tutorial_clustering_tree.zip
Références :
R. Rakotomalala, « Arbres de classification ».
Tutoriel Tanagra, "Arbres de classification", avril 2008.
Decision Trees for Analytics...
2015-01-16 (Tag:173394547876898411)
... Using SAS Enterprise Miner.Cet ouvrage de Barry de Ville et Padraic Neville effectue un large tour d’horizon des arbres décision et de leur implémentation dans SAS Enterprise Miner (SAS EM). Il s’intéresse à la fois aux aspects historiques, théoriques et pratiques.
Il a attiré mon attention parce qu’il s’agit des arbres de décision, une méthode dont la popularité n’est plus à démontrer ; parce qu’on nous parle de SAS EM qui, quoiqu’on en dise, est un outil connu et reconnu ; enfin, parce que les auteurs sont des personnalités à qui on n’apprend pas grand-chose s’agissant de l’implémentation des arbres de décision dans les logiciels.
J’essaie de retracer dans le résumé ci-dessous les grandes lignes de l’ouvrage.
Mots clés : arbres de décision, arbres de segmentation, sas, sas em, enterprise miner
Composants Tanagra : C4.5, C-RT, CS-CRT, CS-MC4, ID3
Lien : Résumé
Références :
Barry de Ville and Padraic Neville, "Decision Trees for Analytics Using SAS Enterprise Miner", SAS Institute, June 2013.
Méthodologie statistique pour l'analyse prédictive
2014-12-31 (Tag:2368699815373569968)
Google est mon ami, tout le monde l’a bien compris (ça rime !). Je passe beaucoup de temps à effectuer des recherches sur le web, à lire, à classer les documents, à les annoter pour pouvoir les reprendre plus facilement lorsqu’il s’agira d’écrire un tutoriel sur tel ou tel sujet.Tout récemment, je suis tombé sur le document « Méthodologie statistique pour la discrimination et classement » de Pierre Traissac. Je lis d’abord un peu en diagonale parce qu’il y a des mots-clés qui me parlent… et d’un coup je me rends compte que l’auteur nous livre là une trame particulièrement claire d’une démarche d’analyse prédictive, si populaire en data science (data mining). Je me suis dit qu’il serait intéressant d’en faire un petit résumé.
Mots clés : analyse prédictive, analyse discriminante prédictive, analyse discriminante linéaire, régression logistique, arbres de décision, arbres de segmentation, cart
Composants Tanagra : BINARY LOGISTIC REGRESSION, LINEAR DISCRIMINANT ANALYSIS, C-RT
Lien : Résumé
Références :
Pierre Traissac, "Méthodologie statistique pour la discrimination et le classement. Application au ciblage des interventions nutritionnelles", in Padilla M, Delpeuch F, Le Bihan G, Maire B, editors. Les politiques alimentaires en Afrique du Nord D'une assistance généralisée aux interventions ciblées. Paris: Karthala; 1995. p. 393-431.
Références connexes :
B. Marie, F. Delpeuch, M. Padilla, G. Le Bihan, "Le ciblage dans les politiques et programmes nutritionnels", in Padilla M, Delpeuch F, Le Bihan G, Maire B, editors. Les politiques alimentaires en Afrique du Nord D'une assistance généralisée aux interventions ciblées. Paris: Karthala; 1995. p. 35-57.
P. Traissac P., B. Marie, F.Delpeuch, "Aspects statistiques du ciblage des politiques et programmes nutritionnels dans les pays en voie de développement", in Laloë Francis (ed.), Perrier X. (ed.), Pavé A. (pref.) De l'observation à l'analyse : implication de la biométrie dans les pays de développement. Paris : Société Française de Biométrie, 1998, (15), (Session de Biométrie ; 15). Journées de la Société Française de Biométrie, Carcassonne (FRA), 1997, p. 79-98.
Règles de décision prédictives - Diapos
2014-12-30 (Tag:3360196328220534471)
Bien connu des chercheurs d’obédience « machine learning », l’induction de règles prédictives est rarement mise en avant en « statistical learning ». Cela m’a paru toujours un peu étrange, bien que faire la distinction entre les deux communautés n’est pas toujours évidente. Pour ma part, j’évite d’entrer dans ce genre de discussions. Pour simplifier, j’associe l’esprit « machine learning » à l’ouvrage de Tom Mitchell (1997), « statistical learning » est plutôt rattaché au livre de Hastie, Tibshirani et Friedman (2009). Et je m’en tiens à cette idée. Je mesure parfaitement en revanche les compétences que je cherche à transmettre à mes étudiants, c’est ce qui importe après tout.Pour en revenir à l’apprentissage des règles de décision dans le cadre de l’analyse prédictive, je présente dans ces slides les différentes méthodes d’élaboration de bases de règles à partir de données. Les méthodes separate-and-conquer, par opposition aux techniques divide-and-conquer c.-à-d. les arbres de décision, y ont la part belle. Je détaille les différentes méthodes top-down aboutissant à un système prédictif sous la forme d’une liste de décision (decision list en anglais) ou en un ensemble de règles non imbriquées (règles non ordonnées – unordered rules). Pour élargir le débat, je parle également, de manière plus ou moins détaillée des autres approches, moins connues, mais qui ont pourtant mobilisé des énergies à différentes périodes : les techniques bottom-up, les algorithmes génétiques, les règles d’association prédictives, les règles prédictives floues.
Des tutoriels permettant de pratiquer ces techniques sur des données réelles à l’aide de logiciels librement accessibles sont référencés.
Mots clés : induction de règles, règles prédictives, listes de décision, base de connaissances, CN2, arbres de décision
Composants Tanagra : DECISION LIST, RULE INDUCTION, SPV ASSOC RULE
Lien : Règles de décision prédictives
Données : weather rule induction data
Références :
Tutoriel Tanagra,"Induction de règles prédictives", novembre 2009.
Tutoriel Tanagra, "Induction de règles floues avec Knime", janvier 2010.
J. Furnkranz, "Separate-and-Conquer Rule Learning", Artificial Intelligence Review, 13: 3-54, 1999.
Data Mining with Decision Trees
2014-12-20 (Tag:1785887678977224741)
Comme tout enseignant-chercheur, je passe beaucoup de temps à lire. Habituellement, j’essaie de trouver à la bibliothèque les ouvrages qui m’intéressent. Quand je vois que ça tient vraiment la route, je l’achète. Cette stratégie n’est pas trop possible pour les livres en anglais. Dans ce cas, j’acquière le livre sur la foi d’un titre, d’un auteur, d’un résumé, d’une quatrième de couverture, … et il m’arrive de les lire un peu en diagonale à l’arrivée parce que je suis un peu déçu ou bien parce que ça ne correspond pas vraiment à ce que je cherchais.Pour rentabiliser ces lectures, et m’obliger à scruter attentivement tout livre qui me passe entre les mains, j’ai décidé d’inaugurer un nouveau thème sur ce blog : les résumés d’ouvrages. L’idée est de les rendre plus accessible en essayant d’en cerner la teneur. Si ça peut inciter les étudiants à lire d’avantage, ce n’est pas plus mal.
Dans ce post, je décris le livre de Rokach et Maimon consacré aux arbres de décision.
Mots clés : arbres de décision, arbres de segmentation, chaid, c4.5, cart
Composants Tanagra : C4.5, C-RT, CS-CRT, CS-MC4, ID3
Lien : Résumé
Références :
L. Rokach and O. Maimon, "Data Mining with Decision Trees - Theory and Applications", Series in Machine Perception and Artificial Intelligence, vol. 61, World Scientific Publising, 2007.
Introduction aux arbres de décision - Diapos
2014-12-18 (Tag:4864054596164513380)
Au milieu des années 90, « faire du data mining » était assimilé à construire des arbres de décision. Le raccourci était bien évidemment trop simpliste, même si les arbres constituent effectivement une des méthodes phares du data mining (on dirait data science aujourd’hui).Mes diapos sur les arbres ont été parmi les premiers que j’aie rédigés pour mes cours de data mining à l’Université. Ils avaient très peu évolué depuis parce que, entres autres, la méthode – la construction d’un arbre unique à partir d’un échantillon d’apprentissage - est bien établie et a connu peu de bouleversements fondamentaux depuis la fin des années 80. Il n’en reste pas moins qu’au fil des années, mon discours a évolué. Notamment parce que les outils actuels proposent des fonctionnalités de plus en plus performantes pour l’exploration interactive, pour l’appréhension de la volumétrie, etc. Je le disais verbalement. Je me suis dit qu’il était temps de matérialisé cela sur le support que j’utilise pour mes présentations. Je l’ai également complété en insérant les références sur les nombreux tutoriels récents que j’ai pu écrire sur l’induction des arbres à l’aide de différents logiciels.
Mots clés : arbres de décision, arbres de segmentation, chaid, c4.5, cart, sipina, logiciel R, spad, package rpart, tree, party, arbres interactifs
Composants Tanagra : C4.5, C-RT, CS-CRT, CS-MC4, ID3
Lien : Introduction aux arbres de décision
Références :
R. Rakotomalala, "Arbres de décision", Revue MODULAD, n°33, pp. 163-187, 2005.
Débogage sous RStudio
2014-12-07 (Tag:5739425554084121726)
Durant les travaux dirigés pour mon cours de programmation R, les étudiants me sollicitent pour les aider à identifier les bugs qui bloquent leurs programmes. Parfois, je vois immédiatement le problème parce qu’il y a une erreur de syntaxe, ou enchaînement d’accolades mal maîtrisé. Souvent, je leur dis d’émailler leur code de print() pour que l’on puisse comprendre l’enchaînement des opérations et évaluer l’état des variables importantes dans le programme. Rapidement dans ce cas, les incohérences apparaissent, et la correction apparaît évidente (elle l’est toujours après coup).Une autre solution est possible si l’on travaille sous RStudio. Nous pouvons nous appuyer sur le débogueur intégré. Le post ci-dessous, accessible sur le site de l’éditeur de l’outil, décrit la procédure à suivre. Il détaille les outils et options disponibles. La possibilité de lancer pas-à-pas les lignes d’instruction est absolument indispensable lorsqu’on souhaite tracer l'exécution d'un programme. RStudio propose un dispositif particulièrement complet.
RStudio s’impose de plus en plus comme un environnement de développement intégré (EDI) incontournable pour le langage R. J’ai moi-même utilisé Tinn-R pendant longtemps avant de finalement passer à RStudio. Cette popularité ne se démentira avec ce type de fonctionnalité.
Mots-clés : logiciel R, programmation R, environnement de développement intégré, EDI, rstudio, débogage
Lien : Jonathan McPherson, Debugging with RStudio, avril 2015 (pdf) ; Josh Paulson, "Breakpoint Troubleshooting", juin 2105 (pdf).
Références :
Site de RStudio, http://www.rstudio.com/
Andrea Spano, "Visual debugging with RStudio", Milano-R.
Tutoriel Tanagra, "Tinn-R, un éditeur de code pour R", février 2012.
Azure Machine Learning
2014-11-27 (Tag:8165309030042434434)
Microsoft Azure est la plateforme cloud de Microsoft. Elle offre un certain nombre de services pour le stockage, le calcul, le traitement et la transmission des données, la gestion des bases de données, le développement d’applications, etc . Azure Machine Learning (Azure ML) est un service dédié à l’analyse prédictive. Il propose les fonctionnalités nécessaires à la construction de modèles prédictifs, à leur évaluation, et à leur déploiement. Des algorithmes maisons, adossés à des méthodes reconnues, sont implémentées (régression logistique, forêts aléatoires, etc.). Nous pouvons démultiplier les analyses puisque Azure ML intègre le logiciel R et la grande majorité des packages associés. De fait, réaliser des traitements en ligne avec du code R est possible. Nous étudierons avec beaucoup de curiosité cette opportunité. Azure Machine Learning Studio (ML Studio) est un front end accessible via un navigateur web. Il permet de piloter des analyses via l’élaboration de diagrammes de traitements, à l’instar des outils bien connus de data mining. On parle souvent de programmation visuelle (cf. SPAD, SAS EM, IBM SPSS Modeler, etc.).Le data science rentre de plain pied dans l’ère du "cloud computing" avec Azure ML. Les données sont stockées on ne sait où (les fameux "data centers") et les calculs sont effectués à distance sur des serveurs externalisés. Un simple navigateur suffit pour développer les analyses et réaliser les traitements. Ainsi, un client léger avec des capacités limitées ne nous pénalise en rien, tant en matière de volumétrie qu’en matière de temps de calcul.
Microsoft propose une tarification sophistiquée du service. Mais nous pouvons nous exercer gratuitement sur l’outil ML Studio via le site https://studio.azureml.net/, en nous connectant avec un compte e-mail Microsoft. J’ai utilisé mon compte "@live.fr" en ce qui me concerne. Dans ce tutoriel, je montre les principales fonctionnalités de l’outil en réalisant quelques traitements types d’analyse prédictive.
Mots clés : cloud computing, azure, machine learning, régression logistique, k-means, decision forest, random forest, courbe roc, auc
Composants Tanagra : SAMPLING, BINARY LOGISTIC REGRESSION, BAGGING + RND TREE, SCORING, ROC CURVE
Lien : Azure Machine Learning
Données : breast.txt
Références :
Microsoft Azure, http://azure.microsoft.com/fr-fr/
Azure Machine Learning, http://azure.microsoft.com/fr-fr/services/machine-learning/
R. Casteres, [Article en Français] "Predict Wine Quality with Azure Machine Learning", août 2014.
Clustering de variables qualitatives - Diapos
2014-11-12 (Tag:7698834134369055126)
La classification de variables qualitatives vise à regrouper les variables en groupes homogènes. Les variables situées dans un même groupe sont fortement liées entre elles, celles situées dans des groupes différents le sont faiblement. Deux approches sont décrites. La première exploite le v de Cramer, la matrice de dissimilarités qui en est déduite permet de lancer une classification ascendante hiérarchique (CAH) avec les stratégies d’agrégation usuelles (lien minimum, lien maximum, méthode de Ward, etc.). La seconde repose sur la notion de variable latente, une « moyenne » résumant l’information portée par un groupe de variables. Le barycentre d’un ensemble de variables étant ainsi défini, il est possible de s’appuyer sur les algorithmes bien connus de classification (CAH, mais aussi les algorithmes de type k-means, etc.).La classification de variables donne une indication sur les liaisons et les redondances, mais elle ne permet pas d’identifier la nature des relations entre les variables c.-à-d. les associations entre les modalités. A partir de ce constat, nous introduisons la classification de modalités de variables qualitatives. Deux pistes sont explorées. La première, tout comme pour la classification de variables, prend pour point de départ la définition la similarité entre modalités. Le processus de classification (CAH) s’appuie sur la matrice des dissimilarités qui en découle. La seconde est de type « tandem analysis » (tandem clustering). Dans une première étape, une analyse des correspondances multiples (ACM) permet de projeter les modalités dans un nouvel espace de représentation. La typologie est réalisée à partir des coordonnées factorielles des modalités qui font figure d’individus dans la seconde étape.
Le jeu de données et le programme R qui ont servi à illustrer ce document sont téléchargeables.
Mots clés : classification automatique, typologie, clustering, classification de variables qualitatives, acm, analyse des correspondances multiples, afcm, tandem analysis, tandem clustering, package clustofvar, hclustvar, package hmisc, varclus, classification ascendante hiérarchique, CAH, indice de dice, logiciel R
Composants : CATVARHCA
Lien : Classification de variables qualitatives
Données : catvarclus.zip
Références :
Tutoriel Tanagra, "Classification de variables qualitatives", décembre 2013.
La page Excel'Ense de Modulad
2014-11-06 (Tag:4298827671510236623)
La revue MODULAD est consacrée aux statistiques et traitement de données. Elle est éditée depuis 1988. Elle met l’accent sur le bon usage des méthodes et des outils. En janvier 2005, la version papier est abandonnée au profit d’une diffusion sur le web. Tout un chacun peut accéder librement aux articles et aux ressources associées sans avoir à s’enregistrer.Une des forces de la revue est d’avoir su trouver un équilibre entre les fondements théoriques, la pratique, et les outils. Elle ouvre la porte aux non-spécialistes, attachés aux aspects applicatifs, mais désireux de s’appuyer sur des références théoriques solides. La politique éditoriale de la revue évoque, bien avant l’heure, ce que l’on a coutume d’appeler aujourd’hui « data science » ou encore « big data analytics ».
La page Excel’Ense montre l’attachement de la revue au caractère pratique de l’analyse de données. Il s’agit d’un « cahier d’information et d’échanges, ciblé sur l’exploitation des données et l’enseignement de la statistique avec un tableur, le prototype étant Excel ». Concrètement, des classeurs types et macros-complémentaires (add-ins) adaptés à différents problèmes statistiques sont mis à disposition des lecteurs (ex. calcul des coefficients d’autocorrélation, construction de plans d’expériences factoriels complets, tests de Wilcoxon, tirage d’un échantillon stratifié, etc.). Nous pouvons les charger et appliquer les techniques proposées sur nos propres données via Excel.
Dans ce tutoriel, nous étudions l’add-in « Explore.xla » de Jacques Vaillé (2011). L’auteur met à notre disposition plusieurs outils et méthodes statistiques pour l’analyse exploratoire des données. Certains d’entre eux, très simples, sont pourtant particulièrement utiles. Une macro par exemple permet de réaliser un graphique nuage de points étiquetés à l’aide des labels des observations, chose impossible à faire avec les fonctions standards d’Excel. Une documentation accompagne la librairie. Nous nous en tiendrons aux techniques d’analyse factorielle dans notre présentation.
Mots clés : analyse en composantes principales, acp, analyse des correspondances binaires, analyse factorielle des correspondances, afc
Composants : PRINCIPAL COMPONENT ANALYSIS, CORRESPONDENCE ANALYSIS
Lien : fr_Tanagra_ExcelEnse.pdf
Données : excelense_explore.zip
Références :
Jacques Vaillé, « La statistique au service des données : quelques macros Excel pour faire de l’analyse exploratoire des données », La revue MODULAD, n°43, 2011.
La revue MODULAD, la page Excel’Ense : http://www.modulad.fr/excel.htm
Induction par arbre avec WinIDAMS
2014-10-28 (Tag:6288538791020851306)
WinIDAMS (Internationally Developed Data Analysis and Management Software Package) est un logiciel de statistique développé sous l’égide de l’UNESCO. J’en avais dessiné les contours récemment (« Statistiques avec WinIDAMS », octobre 2014). J’avais remarqué durant cette étude la procédure SEARCH consacrée à l’apprentissage par arbre. Elle intègre les arbres de décision et de régression, ainsi qu’une méthode que l’on voit peu dans les logiciels, et qui s’apparente à une régression par morceaux. Plutôt que d’incorporer la description de SEARCH dans le document générique consacré à WinIDAMS, j’ai préféré écrire un tutoriel à part car plusieurs éléments avaient attiré mon attention.(1) L’outil propose des sorties qui permettent de retracer le processus de construction de l’arbre. (2) Cette caractéristique est d’autant plus intéressante que la documentation technique décrit les formules utilisées avec force détail (« WinIDAMS Reference Manual (release 1.3) », april 2008 ; Chapter 56, « Searching for structure »). Nous pourrons ainsi de reproduire les calculs intermédiaires pour comprendre pleinement la teneur des méthodes. (3) J’avoue avoir été d’autant plus curieux d’étudier la procédure que j’avais remarqué parmi les contributeurs des auteurs qui ont énormément œuvré dans la popularisation de l’induction par arbre, notamment J.N. Morgan et J. Sonquist qui comptent parmi les références les plus anciennes et les plus prolifiques dans le domaine. Mieux appréhender leur vision ne peut qu’améliorer notre compréhension de ces méthodes. (4) Enfin, la troisième option proposée par SEARCH (Analysis = Regression) correspond à une méthode que je n’ai jamais rencontré dans d’autres outils. Forcément, cela m’a interpelé. De par ma trajectoire scientifique, je suis toujours très curieux de tout ce qui touche aux arbres.
Ce tutoriel décrit les tenants et aboutissants des 3 options (CHI, MEANS, REGRESSION) de la procédure SEARCH de WinIDAMS.
Mots clés : arbre de décision, arbre de régression, régression linéaire, variation
Lien : fr_Tanagra_WinIDAMS_Tree_Induction.pdf
Données : tree_winidams.zip
Références :
UNESCO, "WinIDAMS 1.3 Reference Manual", 2008.
WinIDAMS Advanced Guide, "Example 10: Searching for Structure".
Statistiques avec WinIDAMS
2014-10-16 (Tag:1683726855478999444)
WinIDAMS (Internationally Developed Data Analysis and Management Software Package) est un logiciel de statistique développée sous l’égide de l’UNESCO. Le projet prend ses sources dans les années 70. Mais la première mouture réellement estampillée IDAMS date de la fin des années 80. Deux versions sont développées en parallèle : l’une pour les ordinateurs IBM Mainframe, l’autre pour les PC sous MS-DOS . L’idée est de fédérer (comme Roger du même nom) les spécialistes de différents pays pour développer un outil qui exprime la quintessence du savoir statistique. J’avoue avoir eu le vertige lorsque j’ai consulté pour la première fois la liste des contributeurs. Cornaqué par un tel aréopage d’experts internationaux, l’outil devrait présenter de très grandes qualités.Ce tutoriel décrit la mise en œuvre de WinIDAMS sur un fichier exemple. Nous porterons une attention particulière à l’’importation des données car le logiciel procède de manière assez singulière. Puis, nous effectuerons une rapide découverte de quelques méthodes exploratoires en précisant pour chacune d’elles le paramétrage et la lecture (d’une partie) des résultats. Nous mettrons en parallèle les sorties d’autres logiciels tels que Tanagra et SAS.
Mots clés : classification automatique, typologie, clustering, CAH, proc cluster, analyse discriminante, proc discrim, analyse en composantes principales, factor analysis, proc factor, sas
Composants : HAC, PRINCIPAL COMPONENT ANALYSIS, CANONICAL DISCRIMINANT ANALYSIS, LINEAR DISCRIMINANT ANALYSIS
Lien : fr_Tanagra_WinIDAMS.pdf
Données : winidams_pottery.zip
Références :
UNESCO, "WinIDAMS 1.3 Reference Manual", 2008.
La discrétisation des variables quantitatives (slides)
2014-10-02 (Tag:5102085080387891081)
La discrétisation est une opération de recodage. Elle consiste à transformer une variable quantitative en une qualitative ordinale. Elle procède par découpage en intervalles. Deux questions clés se posent alors durant le processus : (1) combien d’intervalles (de classes) faut-il produire ? (2) comment déterminer les seuils (les bornes) de découpage.Cette opération rentre dans le cadre de la préparation des données. Elle rend possible l’utilisation des techniques statistiques qui ne traitent que les variables qualitatives (ex. induction de règles, construction des grilles de score…) ; elle permet d’harmoniser les bases lorsque nous faisons face à des tableaux hétérogènes (avec un mix de variables qualitatives et quantitatives) ; elle permet également de nettoyer les données en éliminant par exemple l’influence exagérée des données aberrantes.
Je décris dans ce support les enjeux et la démarche de discrétisation. Le point le plus important à retenir est qu’il faut absolument utiliser toute l’information disponible pour obtenir des résultats satisfaisants. Nous devons notamment exploiter pleinement la variable cible lorsque nous nous plaçons dans un schéma d’apprentissage supervisé.
Mots clés : discrétisation, chi-merge, mdlp, mdlpc, intervalles de fréquences égales, intervalles de largeurs égales, arbres de décision, arbres de régression, package discretization, logiciel R
Composants Tanagra : EQFREQ DISC, EQWIDTH DISC, MDLPC
Lien : Discrétisation
Références :
Tutoriel Tanagra, "Discrétisation - Comparaison de logiciels", février 2010.
Tutoriel Tanagra, "Discrétisation contextuelle - La méthode MDLPC", mars 2008.
Nouveaux arbres interactifs dans SPAD 8
2014-08-17 (Tag:2405924149600055912)
Les arbres de décision interactifs font partie de la panoplie d’outils privilégiés du data miner . D’une part parce que l’induction par arbres en elle-même est une méthode intéressante : elle se positionne honorablement par rapport aux autres techniques prédictives en termes de performance ; elle fournit une connaissance intelligible, facilement interprétable ; ses conditions d’utilisation sont particulièrement larges, aucune hypothèse sur les distribution n’est nécessaire, nous pouvons directement mixer les variables prédictives quantitatives et qualitatives, elle sait effectuer les codages les plus appropriés en fonction de la variable cible. D’autre part, du fait qu’elle soit interactive, elle donne la possibilité aux experts du domaine de guider l’exploration des solutions en accord avec des connaissances qui ne sont pas directement disponibles dans les données traitées. De fait, tous les grands éditeurs de logiciels de statistique et de data mining se doivent de proposer les outils – c’est un vrai critère de différenciation entre les logiciels – qui permettent aux utilisateurs d’interagir avec l’arbre de décision élaboré au préalable par les approches bien connues telles que CHAID, CART, C4.5 ou leurs variantes.J’avais déjà présenté les arbres de décision de la version 7 de SPAD précédemment (janvier 2010). Aujourd’hui, je décris le module proposé par SPAD 8. En effet, il a connu une évolution importante, tant en qualité graphique, qu’en matière d’utilisabilité (grosso modo, un mix d’efficacité et d’ergonomie). Il me semblait intéressant d’étudier cette nouvelle mouture pour cerner ce que nous pouvons faire avec les arbres de décision interactifs. Je me concentre sur les fonctionnalités d’exploration dans ce tutoriel. Pour ce qui est du stockage du modèle et de son déploiement, le mieux est de lire/relire le précédent document.
Mots clés : arbres de décision interactifs, induction interactive, SPAD 8
Lien : fr_Tanagra_Arbres_Spad_8.pdf
Données : faible poids bebes.xlsx
Références :
Logiciel SPAD, SPAD.
Tutoriel Tanagra, "Arbres de décision interactifs avec SPAD", Janvier 2010.
R. Rakotomalala, "Arbres de décision", Revue Modulad, n°33, 2005.
Etude du logiciel Sipina
2014-08-10 (Tag:6662871583089023093)
Dans le cadre du transfert du contenu de l’ancienne version française du site de Sipina, j’ai redécouvert un projet réalisé par des étudiants de Master 2 (DESS) il y a une douzaine d’années.Le document liste les principaux menus du logiciel. Une étude comparative de quelques algorithmes d'induction d'arbres sur un même jeu de données est réalisée. Les étudiants ont surtout eu le mérite de manipuler un logiciel que je n’avais absolument pas documenté à l'époque, un véritable tour de force.
Petit commentaire important. Sipina intégrait des méthodes ensemblistes (bagging, boosting, arcing) que j’ai décidé de désactiver par la suite, n’étant pas très satisfait du mode opérationnel de cette fonctionnalité. Le document étant antérieur à cette modification, ces outils y sont décrits.
Les méthodes ensemblistes sont aujourd'hui disponibles de manière générique dans Tanagra. Elles peuvent s’appliquer à tout algorithme d’apprentissage supervisé.
Mots-clés : sipina, arbres de décision
Référence : C. Levieux, M. Fihue, « Etude du logiciel SIPINA (Version Expérimentale) », sous la direction de P.L. Gonzales, DESS d’Ingénierie et de Statistique, Année 2001-2002.
Nouveau site web pour Sipina (FR)
2014-08-08 (Tag:721060744706675224)
Le logiciel SIPINA est sur le web depuis le milieu des années 90. Le site, toujours actif aujourd’hui, a été exclusivement en anglais pendant très longtemps. Une version française a été mise en ligne en 2008. J’avais fait le choix d’un hébergeur de blog gratuit pour des raisons de maintenance et d’organisation. Récemment les conditions générales de l’hébergeur ont évolué. Il s’autorise à intégrer quelques espaces publicitaires sur les blogs des utilisateurs gratuits. Depuis début août, une énorme annonce orne la page de garde du site, masquant presque totalement (sur les ordinateurs à faible résolution) le texte de présentation.Bon, je peux comprendre qu’une entreprise ait besoin de ressources pour fonctionner. Mais, pour ma part, cette nouvelle situation ne me convient pas. Parce que ce n’était pas le deal initial. Parce que je ne souhaite pas associer Sipina, ni Tanagra, à une forme quelconque de monétisation. La solution la plus simple a donc été de transférer le contenu du site sur un nouveau serveur. Dorénavant, l’URL à utiliser – à partir d’août 2014 – sera : http://sipina-arbres-de-decision.blogspot.fr/
Ce n’est pas plus mal. Ca m’a pris un peu de temps, mais finalement cette transition aura été l’occasion pour moi de réorganiser la présentation, en mettant en valeur les documents importants pour la prise en main de Sipina, et ceux qui caractérisent le mieux les particularités du logiciel.
L’ancien site restera actif pendant une courte période encore, le temps de vérifier que tout a bien été récupéré.
Mots clés : sipina, site web en français
Référence : http://sipina-arbres-de-decision.blogspot.fr/
L'add-in Sipina pour Excel 2007 et 2010
2014-08-07 (Tag:1219192801103771716)
Ce tutoriel décrit succinctement l’installation de l’add-in "sipina.xla" dans Excel 2007. La transposition à Excel 2010 est immédiate. Un document similaire existe pour Tanagra. Il m’a semblé néanmoins nécessaire de repréciser la démarche, notamment parce que plusieurs internautes m’en ont fait la demande. D’autres didacticiels existent pour les versions antérieures d’Excel (1997 à 2003) et pour le tableur Calc d’Open Office et de Libre Office.Mots-clés : importation des données, fichier excel, macro complémentaire, add-in, add-on, xls, xlsx
Lien : fr_sipina_excel_addin.pdf
Données : heart.xls
Références:
Tutoriel Tanagra, "Les add-ins Tanagra et Sipina pour Excel 2016", juin 2016.
Tutoriel Tanagra, "L'add-in Tanagra pour Excel 2007 et 2010", août 2010.
Tutoriels animés sur YouTube
2014-07-09 (Tag:964874624768469874)
Il y a tutoriels et tutoriels. On voit de plus en plus aujourd’hui des guides d’utilisation de logiciels de data mining sur la plate-forme youtube. Pour avoir moi-même exploré la réalisation de didacticiels en flash (ex. analyse discriminante, régression logistique, arbres de décision), je mesure parfaitement l’intérêt de ce type de média. Pourtant, j’ai finalement choisi de privilégié les textes rédigés avec des copies d’écran. Pour la principale raison que je peux ainsi, à tout moment, ouvrir des parenthèses : proposer un prisme différent par rapport à l’action qui est décrite, parler des autres logiciels proposant des fonctionnalités similaires, m’autoriser des digressions théoriques et méthodologiques, mettre en contrepoint les autres techniques de data mining, …Il n’en reste pas moins que l’idée des tutoriels animés reste une piste très intéressante. J’ai découvert par hasard plusieurs documents relatifs à Sipina et Tanagra sur youtube, élaborés par des utilisateurs que je remercie très chaleureusement ici (1, 2, 3, 4, 5).
De manière générale, je conseille souvent à mes étudiants d’explorer attentivement ce média pour se familiariser avec des outils dont nous ne disposons pas à l’Université. J’avoue passer moi-même beaucoup de temps à scruter le mode opératoire des différents logiciels. Les principaux éditeurs ont parfaitement compris l’intérêt de la chose et proposent aujourd’hui des démonstrations de très grande qualité. Il suffit d’effectuer quelques requêtes sur youtube pour s’en rendre compte (ex. Coheris Spad, Statistica, Spss, Sas, etc.)...
SQL Server Data Mining Add-Ins
2014-07-02 (Tag:8248275365671090169)
Excel – le tableur de manière général – est très populaire auprès des « data scientist » . Mais, s’il est effectivement performant pour la manipulation et la préparation des données, il est moyennement apprécié concernant les calculs statistiques, parce que moins précis et affublé d’une bibliothèque de fonctions limitée . Pour palier cette faiblesse, de nombreux add-ins (macro complémentaires) existent pour compléter ses capacités d’analyse.Dans ce tutoriel, nous décrivons plusieurs cas d’utilisation des techniques de data mining fournies par l’add-in « SQL Server Data Mining Add-ins ». Plusieurs traits distinctifs apparaissent clairement a posteriori. L’outil couvre parfaitement la pratique usuelle du data mining (ex. le module d’apprentissage supervisé permet de construire différents modèles sur un échantillon d’apprentissage, d’en mesurer et comparer les performances sur un échantillon test, d’effectuer le déploiement sur des données non-étiquetées). Il mise sur une très grande simplicité d’utilisation. Les manipulations sont intuitives. Il n’est pas nécessaire de scruter des heures durant l’aide en ligne pour réaliser une étude. Cette apparente simplicité ne doit pas masquer la complexité de certaines opérations. L’outil effectue automatiquement des choix (ex. discrétisation automatique des variables, sélection des variables pertinentes, etc.) dont on doit avoir conscience pour apprécier pleinement la pertinence des résultats présentés.
Mots clés : excel, tableur, analyse prédictive, arbres de décision, réseau de neurones, bayésien naïf, régression logistique, perceptron,classification automatique, clustering, k-means, règles d'association, scoring, courbe de gain, courbe lift, data mining client for excel
Lien : SSAS
Données : SSAS dataset, cover type
Références :
Microsoft, "SQL Server - Analysis Services Data Mining".
L'add-in Real Statistics pour Excel
2014-06-13 (Tag:8028536802426317453)
Excel – je dirais plutôt le tableur de manière générique - est un des outils favoris des « data scientist ». Les sondages Kdnuggets sur la question le confirment. Il arrive systématiquement dans les 3 premiers logiciels les plus utilisés ces dernières années. Les raisons de ce succès ont été maintes fois évoquées sur ce blog : il est très répandu, tout le monde sait le manipuler, c’est un instrument puissant pour la mise en forme et la préparation des données.Excel est moins à son avantage lorsqu’il s’agit d’effectuer des calculs statistiques. D’aucuns pointent du doigt son manque de précision et la relative pauvreté de sa bibliothèque de fonctions statistiques et d’analyse de données. Les add-ins (ou add-on, macros complémentaires) semblent alors constituer une solution privilégiée pour associer les calculs spécialisés aux fonctionnalités usuelles des tableurs.
La librairie « Real Statistics » du Dr Charles Zaiontz est une solution simple comme je les aime. La copie d’un fichier « RealStats-2007.xlam » (pour la version 2007 d’Excel) suffit pour disposer pleinement de toutes les fonctionnalités. Il n’y a pas d’installation fastidieuse à réaliser, avec des bibliothèques à tiroirs que l’on est obligé de chercher à droite et à gauche. La macro complémentaire se suffit à elle-même, elle ne repose pas sur une DLL compilée. Grâce à cette autonomie, il a été possible de multiplier les versions pour les différentes configurations d’Excel (des add-ins existent pour Excel 2013, 2010, versions antérieures à Excel 2003, version pour Mac). Les résultats des calculs statistiques sont insérés dans les feuilles de calculs sous forme de formules s’appuyant sur des fonctions standards d’Excel (ex. les opérations matricielles, nous pouvons ainsi retracer les étapes des traitements) ou de nouvelles fonctions spécifiques intégrées dans la librairie, que nous pouvons appeler directement dans d’autres feuilles de calculs. Il y a donc deux manières d’utiliser l’add-in : soit, comme nous le ferons dans ce tutoriel, exploiter les boîtes de dialogue dédiées permettant de spécifier les données à traiter et paramétrer les méthodes ; soit en appelant directement les nouvelles fonctions disponibles.
« Real Statistics » est une excellente librairie, à conseiller aux personnes qui souhaitent travailler exclusivement dans l’environnement Excel pour réaliser les traitements statistiques. Elle est d’autant plus intéressante qu’elle est accompagnée d’une documentation particulièrement riche, permettant de comprendre dans le détail la teneur de chaque méthode. Nous décrivons dans ce tutoriel le mode opératoire de l’add-in et, dans certains cas, nous comparons les résultats avec ceux de Tanagra 1.4.50.
Mots clés : excel, tableur, test d'indépendance du khi-2, comparaison de moyennes, test de mann-whitney, test de comparaison pour échantillons appariés, test des rangs signés de wilcoxon, anova à 1 facteur, régression linéaire, régression logistique, manova, analyse en composantes principales
Composants : CONTINGENCY CHI-SQUARE, THEIL U, T-TEST, T-TEST UNEQUAL VARIANCE, MANN-WHITNEY COMPARISON, MULTIPLE LINEAR REGRESSION, WILCOXON SIGNED RANKS TEST, ONE-WAY ANOVA, PRINCIPAL COMPONENT ANALYSIS, BINARY LOGISTIC REGRESSION, ONE-WAY MANOVA, BOX'S M TEST, PAIRED T-TEST, KRUSKAL-WALLIS 1-WAY ANOVA
Lien : fr_Tanagra_Real_Statistics.pdf
Données : credit_approval_real_statistics.xlsx
Références :
Dr. Charles Zaiontz, "Real Statistics Using Excel".
Le tableur Gnumeric
2014-05-25 (Tag:8078790809180931010)
Le tableur est un outil privilégié des data scientist. C’est ce que nous révèle l’enquête annuelle du portail KDNuggets. Excel arrive régulièrement parmi les trois logiciels les plus utilisés ces cinq dernières années (enquêtes 2013, 2012, 2011, 2010, 2009). En France, cette popularité est largement confirmée par sa présence quasi-systématique dans les offres d’emploi relatives au traitement exploratoire des données (statistique, data mining, data science, big data / data analytics, etc.) accessibles sur le site de l’APEC (Association Pour l’Emploi des Cadres). Excel est nommément cité, mais il faut surtout y voir une reconnaissance des aptitudes et capacités de l’outil tableur. D’autres suites bureautiques, dont certaines sont libres, proposent un module équivalent (ex. CALC de la suite LibreOffice).Ce tutoriel est consacré au tableur libre Gnumeric. Il présente des caractéristiques intéressantes : le setup et l’installation sont de taille réduite parce qu’il ne fait pas partie d’une suite bureautique ; il est rapide et léger ; il est dédié au calcul numérique et intègre de manière native un menu « Statistics » avec les procédures statistiques courantes (tests paramétriques, tests non paramétriques, régression, analyse en composantes principales, etc.) ; et, il semble plus précis que les tableurs de référence (McCullough, 2004 ; Keeling and Pavur, 2011). Ces deux derniers aspects ont attiré mon attention et m’ont convaincu de l’étudier plus en détail. Dans ce qui suit, nous effectuons un rapide tour d’horizon d’une sélection des procédures statistiques de Gnumeric. Pour certaines, nous comparons les résultats à ceux de Tanagra 1.4.50.
Mots clés : gnumeric, tableur, statistique descriptive, analyse en composantes principales, acp, régression linéaire multiple, test des rangs signés de wilcoxon, test de comparaison de moyenne - variances inégales, test de mann et whitney, analyse de variance, anova
Composants : MORE UNIVARIATE CONT STAT, PRINCIPAL COMPONENT ANALYSIS, MULTIPLE LINEAR REGRESSION, WILCOXON SIGNED RANKS TEST, T-TEST UNEQUAL VARIANCE, MANN-WHITNEY COMPARISON, ONE-WAY ANOVA
Lien : fr_Tanagra_Gnumeric.pdf
Données : credit_approval.zip
Références :
Gnumeric, "The Gnumeric Manual, version 1.12".
K.B. Keeling, R. Pavur, « Statistical Accuracy of Spreadsheet Software », The Amercial Statistician, 65:4, 265-273, 2011.
Sipina - Version 3.12
2014-05-19 (Tag:7899363457743630341)
Le transfert entre le tableur Excel et Sipina a été fiabilisé sur les bases de taille modérée (sur les grandes bases, plusieurs centaines de milliers d’observations, mieux vaut toujours passer par l’importation directe de fichier au format texte .TXT). La gestion du point décimal a été améliorée. La transformation automatique est maintenant bien plus rapide qu’auparavant.La précision des seuils numériques affichés dans un arbre de décision devient paramétrable. L’utilisateur y accède vient un nouvel item dans le menu « Tree Management ».
Site web : Sipina
Chargement : Fichier setup
Du Data Mining au Big Data
2014-05-18 (Tag:4123677173588239276)
Ces dernières années de nouveaux termes très « fashion » sont apparus dans le domaine de l’exploitation des données en vue de la prise de décision. On parle de « data science », du métier de « data scientist », de « big analytics », de « predictive analytics », « d’open data », de « social media mining », etc. On les place souvent dans le nouveau contexte du « big data ».A bien y regarder dans les articles où il en est question, parmi les principaux enjeux figurent le stockage, le traitement, l’analyse et la valorisation des données massives (big data), le respect de la vie privée, la sécurisation des informations. Est-ce si nouveau que cela ? Est-ce que cela mérite autant d’effervescence ? Ou bien est-ce seulement un replâtrage par rapport à l’analyse de données et aux statistiques exploratoires, comme ont eu tendance à le dire les statisticiens lorsque le phénomène data mining est apparu à l’orée des années 90.
L’affaire est d’importance en ce qui concerne notre Département Informatique et Statistique. Notre offre de formation couvre entres autres la statistique et le data mining (SISE), l’informatique décisionnelle (business intelligence, IIDEE), la sécurité informatique (OPSIE). Domaines que l’on cite très souvent dans le contexte du « big data ». Est-ce suffisant dans le futur ? Faut-il présenter un nouveau diplôme spécifiquement estampillé « big data » ? Ou bien doit-on veiller surtout à renouveler à bon escient nos maquettes comme nous le faisons tous les 5 ans lors des campagnes d’habilitation ? Est-ce qu’il y a matière à introduire de nouveaux enseignements dans cette perspective, des cours concrets avec un savoir et un savoir faire à prodiguer à nos étudiants, des compétences qu’ils pourront valoriser dans leur vie professionnelle ? Ou bien doit-on se contenter de présentations générales positionnant la nouvelle configuration de la gestion, du traitement et de l’exploitation des données ?
Il est difficile voire impossible d’avoir une position tranchée. Pour l’heure, je partage avec vous le fruit de mes réflexions que j’ai livrées lors d’une présentation récente. J’ai placé le big data dans la perspective d’une évolution du « knowldege discovery » (« data science » devrait-on dire alors ?) liée au progrès technologique, avec notamment l’impact considérable des nouvelles technologies et du web sur la circulation de l’information. Ce support vaut aussi pour les très nombreux liens internet que j’ai consultés durant la préparation de mon exposé. Il préfigure le prisme que j’utiliserai dans mon cours d’introduction au data mining (devrais-je dire désormais « introduction au big data » ?).
Mots clés : data mining, big data, data science, data scientist, big analytics, predictive analytics, open data
Lien : Du Data Mining au Big Data - Enjeux et opportunités
Références :
M.P. Hamel D. Marguerite, "Analyse des big data – Quels usages, quels défis", La note d’analyse, Commissariat Général à la Stratégie et à la Prospective, Département Questions Sociales, N°8, Novembre 2013.
Anne Lauvergeon et al., "Ambition 7 : La valorisation des données massives (Big Data)", in « Un principe et sept ambitions pour l’innovation - Rapport de la commission Innovation 2030 », Octobre 2013.
Régression linéaire pour le classement
2014-04-29 (Tag:1984299071300453899)
Ces slides font suite au tutoriel consacré à l’utilisation de la régression linéaire multiple dans un problème de classement. La trame est la même. On montre (1) que la démarche est tout à fait licite lorsque la variable cible est binaire, il existe une passerelle avec l’analyse discriminante linéaire ; (2) les tests d’évaluation globale du modèle et de pertinence des variables sont applicables.Mots clés : apprentissage supervisé, discrimination, classement, régression linéaire multiple, analyse discriminante linéaire, significativité globale du modèle, significativité individuelle des coefficients, R2, lambda de wilks
Lien : regression_multiple_pour_le_classement.pdf
Références :
Tutoriel Tanagra, "Analyse discriminante et régression linéaire", avril 2014.
Analyse discriminante et régression linéaire
2014-04-20 (Tag:5459275410198679265)
Bien que s’inscrivant toutes deux dans le cadre de l’analyse prédictive, l’analyse discriminante linéaire et la régression linéaire multiple répondent à des problématiques différentes. La première cherche à prédire une variable cible qualitative nominale à partir d’un ensemble de variables prédictives quantitatives (ou qualitatives recodées en indicatrices numériques). Pour la seconde, la variable cible est quantitative. La finalité, les calculs sous-jacents et le mécanisme inférentiel ne sont pas les mêmes.Pourtant, de nombreux auteurs indiquent qu’il y a des similarités entre ces deux approches. Mieux même, dans le cas particulier d’une variable cible binaire, il est possible de reproduire à l’identique les sorties de l’analyse discriminante à partir des résultats de la régression.
Dans ce tutoriel, nous décrivons les connexions entre les deux approches dans le cas d’une variable cible binaire. Nous détaillons les formules permettant de retrouver les coefficients de l’analyse discriminante à partir de ceux de la régression linéaire. Il apparaît que, si l’équivalence est totale lorsque les classes sont équilibrées, il est nécessaire d’introduire une correction additionnelle de la constante lorsque les effectifs ne sont pas identiques dans les deux groupes. La formule correspondante est explicitée. Nous réalisons les calculs sous Tanagra (classes équilibrées) et sous R (classes non équilibrées).
Mots clés : analyse discriminante prédictive, analyse discriminante linéaire, régression linéaire multiple, lambda de wilks, distance de mahalanobis, fonction score, classifieur linéaire, sas, proc discrim, proc stepdisc
Composants : LINEAR DISCRIMINANT ANALYSIS, MULTIPLE LINEAR REGRESSION
Lien : fr_Tanagra_LDA_and_Regression.pdf
Données : lda_regression.zip
Références :
C.J. Huberty, S. Olejnik, « Applied MANOVA and Discriminant Analysis »,Wiley, 2006.
R. Tomassone, M. Danzart, J.J. Daudin, J.P. Masson, « Discrimination et Classement », Masson, 1988.
Text mining avec Knime et RapidMiner
2014-04-12 (Tag:8219098433873303071)
L’approche statistique du « text mining » consiste à transformer une collection de documents textuels en une matrice de valeurs numériques sur laquelle nous pouvons appliquer les techniques d’analyse de données. Bien évidemment, d’autres prismes existent. Je préfère prendre mes précautions avant la levée de bouclier des linguistes et autres tenants des approches sémantiques. Il y a de la place pour tout le monde.Dans ce tutoriel, je reprends un des exercices de catégorisation de textes (fouille de textes) que j’encadre en Master SISE du Département Informatique et Statistique de l’Université Lumière Lyon 2. Nous effectuons la totalité des opérations sous R. L’utilisation des packages spécialisés ‘XML’ et ‘tm’ facilitent grandement les opérations, avouons-le. Je me suis demandé s’il était possible de réaliser les mêmes traitements à l’aide d’autres logiciels libres. J’ai beaucoup cherché. Trouver de la documentation qui corresponde véritablement à ce que je souhaitais mettre en place n’a pas été facile (et encore, je savais exactement ce qu’il y avait à faire, ça aide pour les recherche sur le web). J’ai finalement réussi à reproduire (à peu près) la totalité de la séance sous les logiciels Knime 2.9.1 et RapidMiner 5.3.
Mots clés : text mining, fouille de textes, catégorisation de textes, arbres de décision, j48, svm linéaire, base reuters, format XML, stemming, stopwords, matrice documents-termes
Lien : fr_Tanagra_Text_Mining.pdf
Données : text_mining_tutorial.zip
Références :
Wikipedia, "Document classification".
S. Weiss, N. Indurkhya, T. Zhang, "Fundamentals of Predictive Text Mining", Springer, 2010.
Grille de score
2014-02-13 (Tag:6081906573113768441)
En scoring, un cadre particulier de l’apprentissage supervisé où la variable cible est binaire (modalité positive vs. négative), une grille de score est un système de notation permettant d’apprécier la propension à être positif des individus. Il peut s’agir par exemple de situer la capacité d’une personne à rembourser un crédit contracté auprès d’un établissement bancaire, on aurait alors un mécanisme du type : personne en CDI, + 30 points ; propriétaire de son logement, + 20 points ; elle n’a pas d’autre crédit en cours, +25 points ; etc.Des outils classiques de l’apprentissage statistique (régression logistique, analyse discriminante, etc.) permettent d’estimer directement la probabilité d’être positif des individus. Malheureusement, les solutions fournies – les coefficients des modèles prédictifs, parfois positifs, d’autres fois négatifs, appliquées à des variables définies sur des échelles différentes – s’avèrent quelquefois peu lisibles, hors de portée des non-initiés. L’objectif de la grille de score est de transformer ces coefficients en un système de points entrant dans une notation globale des individus. Cette représentation cumule plusieurs avantages : le score global est calibré, son domaine de définition est connu à l’avance (ex. 0 à 100) ; le déploiement est facilité, il suffit de recenser les caractéristiques des individus et de sommer les points associés ; l’interprétation est immédiate, l’influence des caractéristiques sur l’appréciation d’un individu est directement identifiable.
Ce support décrit la transformation des coefficients d’un modèle issu de la régression logistique en un système de notation.
Mots clés : scoring, grille de score, apprentissage supervisé,discrétisation, mdlpc
Lien : grille_de_score.pdf
Données : pret_acceptation_score.xls
Références :
G. Saporta, « Probabilités, Analyse de données et Statistique », Technip, 2006 ; pp. 462 à 467, section 18.4.3 « Un exemple de 'credit scoring' ».
J.P. Nakache, J. Confais, « Statistique explicative appliquée », Technip, 2003 ; pp. 58 à 60, section 2.2.2 « SCORE : construction d’un score ».
Tanagra, 10 ans déjà
2014-01-02 (Tag:8995842514468356757)
Tout d’abord, permettez-moi de vous présenter tous mes vœux de bonheur, de santé et de réussite pour cette année 2014 qui commence.Pour Tanagra, 2014 revêt une importance assez particulière. Il y a 10 ans presque jour pour jour, la première version du logiciel a été mise en ligne. Conçu à l’origine comme un outil de data mining gratuit à l’usage des étudiants et des chercheurs, le projet a un peu changé de nature ces dernières années. Aujourd’hui, Tanagra est surtout un projet pédagogique qui propose un point d’accès aux techniques statistiques et au data mining. Il s’adresse aux étudiants, mais aussi aux chercheurs d’autres domaines (psychologie, sociologie, archéologie, etc.). Il permet, j’espère, de rendre plus attractif, plus limpide, la mise en œuvre de ces techniques sur des études réelles.
Cette mutation s’est accompagnée d’un recentrage de mon activité. Le logiciel Tanagra évolue toujours (nous en sommes à la version 1.4.50), de nouvelles méthodes sont ajoutées, les composants existants sont régulièrement améliorés, mais dans le même temps je mets l’accent sur la documentation sous forme d’ouvrages, de supports de cours et de tutoriels. L’idée sous-jacente est très simple : comprendre les tenants et aboutissants des méthodes reste la meilleure manière d’apprendre à utiliser les logiciels qui les proposent.
Sur ces 5 dernières années (01/01/2009 au 31/12/2013), mon site a connu 677 visites par jour. Les 10 pays qui viennent le plus souvent sont : la France, le Maroc, l’Algérie, la Tunisie, les Etats-Unis, l’Inde, le Canada, la Belgique, le Royaume-Uni et le Brésil. La page de support de cours est la plus consultée (https://eric.univ-lyon2.fr/ricco/cours/supports_data_mining.html ; 99 visites par jour, 6 minutes 35 secondes de temps moyen passé sur la page). Dans le même temps, je note avec beaucoup de satisfaction que les pages en anglais sont globalement autant visitées que celles en français. Je me dis que l’effort d’internationalisation sert à quelque chose.
J’espère que ce travail vous sera utile encore pour longtemps, et que 2014 sera le théâtre d’échanges toujours aussi enrichissants pour les uns comme pour les autres.
Ricco.
Classification de variables qualitatives
2013-12-21 (Tag:8269136024513147472)
La classification automatique vise à regrouper les objets en paquets. Les objets similaires sont classés dans un même groupe ; ceux qui sont différents sont classés dans des groupes différents.Dans ce tutoriel, nous décrivons une technique de classification ascendante hiérarchique (CAH) des modalités de variables qualitatives nominales due à Abdallah et Saporta (1998). Nous montrons sa mise en oeuvre à l’aide du composant CATVARHCA introduit dans la version 1.4.50 de Tanagra. Ce dernier intègre la possibilité d’utiliser des variables illustratives, permettant ainsi d’enrichir l’interprétation des résultats. Dans un second temps, pour bien cerner les tenants et aboutissants de l’approche, nous détaillons les différentes étapes des calculs sous le logiciel R 3.0.1.
Enfin, dans une troisième et dernière partie, nous présenterons des approches alternatives de catégorisation des modalités des variables qualitatives. L’une, implémentée dans le package "Hmisc", s’appuie sur une autre mesure de dissimilarité. L’autre, de type "tandem analysis", procède par une CAH sur les coordonnées factorielles des modalités issues d’une ACM. Nous comparerons les résultats obtenus avec ceux de CATVARHCA. Nous constaterons que ces approches sont tout à fait valables et proposent des résultats exploitables.
Mots clés : classification automatique, typologie, clustering, classification de variables qualitatives, acm, analyse des correspondances multiples, tandem analysis, package clustofvar, hclustvar, package hmisc, varclus, classification ascendante hiérarchique, CAH, indice de dice, détection du nombre de groupes
Composants : CATVARHCA
Lien : fr_Tanagra_Cat_Variable_Clustering.pdf
Données : vote_catvarclus.zip
Références :
H. Abdallah, G. Saporta, « Classification d’un ensemble de variables qualitatives », in Revue de Statistique Appliquée, Tome 46, N°4, pp. 5-26, 1998.
M. Chavent, V. Kuentz, B. Liquet, J. Saracco, « Classification de variables : le package ClustOfVar », in Actes des 43èmes journées de Statistique (SFDS), Tunisie, 2011.
F.E. Harrel Jr., "Hmisc : Harrel Miscellaneous - 3.13-0".
Tutoriel Tanagra, "Classification de variables", Mars 2008.
Tanagra - Version 1.4.50
2013-12-18 (Tag:3780933642248093604)
Des améliorations ont été introduites, un nouveau composant est ajouté.HAC. Classification ascendante hiérarchique. Le temps de calcul a été très fortement amélioré. Nous détaillerons la nouvelle procédure utilisée dans un prochain tutoriel.
CATVARHCA. Classification des modalités des variables qualitatives. Basée sur les travaux d’Abdallah et Saporta (1998), le composant réalise une classification ascendante hiérarchique des modalités de variables qualitatives, la distance utilisée est l’indice de Dice. Plusieurs stratégies d’agrégation sont proposées : saut minimum, saut maximum, lien moyen, méthode de Ward. Un tutoriel viendra décrire la méthode.
Page de téléchargement : setup
Classification automatique sur données mixtes
2013-11-23 (Tag:8255248831039326876)
La classification automatique ou typologie (clustering en anglais) vise à regrouper les observations en classes : les individus ayant des caractéristiques similaires sont réunis dans la même catégorie ; les individus présentant des caractéristiques dissemblables sont situés dans des catégories distinctes. La notion de proximité est primordiale dans ce processus. Elle est quantifiée différemment selon le type des variables. La distance euclidienne est souvent utilisée (normalisée ou non) lorsqu’elles sont quantitatives, la distance du khi-2 lorsqu’elles sont qualitatives (les individus qui possèdent souvent les mêmes modalités sont réputées proches).L’affaire se corse lorsque nous sommes en présence d’un mix de variables quantitatives et qualitatives. Certes il est toujours possible de définir une distance prenant en compte simultanément les deux types de variables (ex. la distance HEOM). Mais le problème de la normalisation est posé. Telle ou telle variable ne doit pas avoir une influence exagérée uniquement de par sa nature.
Précédemment, nous avons présenté l’analyse factorielle de données mixtes (AFDM) . Il s’agit de projeter les observations dans un repère factoriel élaboré à partir d’un mélange de variables actives qualitatives et quantitatives. On montre que l’approche est équivalente à l’ACP normée (analyse en composantes principales) lorsque les variables sont toutes quantitatives, à l’ACM (analyse des correspondances multiples) lorsqu’elles sont toutes qualitatives.
Nous proposons dans ce tutoriel de réaliser la classification sur données mixtes en deux étapes : [1] nous procédons tout d’abord à une AFDM pour produire une représentation intermédiaire des données ; [2] puis, nous effectuons une classification ascendante hiérarchique (CAH) à partir des facteurs « représentatifs » de l’AFDM. Cette analyse en deux temps est couramment utilisée même lorsque les variables sont exclusivement quantitatives (on passe par l’ACP) ou qualitatives (ACM). L’idée est de procéder à un nettoyage des données – une sorte de régularisation – en éliminant les derniers facteurs qui correspondent à du bruit spécifique à l’échantillon que nous utilisons c.-à-d. des informations qui correspondent aux fluctuations d’échantillonnage ne reflétant en rien un phénomène réel dans la population. Les résultats sont ainsi plus stables.
Nous utiliserons les logiciels Tanagra 1.4.49 et R (package ade4) dans ce tutoriel.
Mots clés : AFDM, analyse factorielle des données mixtes, classification automatique, typologie, cah, classification ascendante hiérarchique, logiciel R, package ade4, dudi.mix, dist, hclust, cutree, logiciel R, description des groupes
Composants : AFDM, HAC, GROUP CHARACTERIZATION, SCATTERPLOT
Lien : fr_Tanagra_Clustering_Mixed_Data.pdf
Données : bank_clustering.zip
Références :
Jérôme Pagès, « Analyse Factorielle de Données Mixtes », Revue de Statistique Appliquée, tome 52, n°4, 2004 ; pages 93-111.
Tutoriel Tanagra, "Analyse factorielle de données mixtes - Diapos", Août 2013.
Scilab et R - Performances comparées
2013-11-11 (Tag:1186482350308722908)
Nous avons fait connaissance du logiciel Scilab dans un précédent tutoriel . Nous étions arrivés à la conclusion qu’il se positionnait très bien comme une alternative à R dans le domaine du data mining même si, en matière de nombre de bibliothèques de méthodes statistiques et de data mining, il restait largement en retrait.Dans ce second volet, nous nous intéressons aux performances de Scilab lors du traitement d’un grand fichier avec 500.000 observations et 22 variables. « Grand fichier » étant tout à fait relatif, nous le confrontons à la référence R pour mieux situer son comportement. Deux critères sont utilisés pour effectuer les comparaisons : l’occupation mémoire du logiciel mesurée dans le gestionnaire de tâches Windows, le temps de traitement à chaque étape du processus.
Il serait vain d’espérer obtenir une vision exhaustive. Pour délimiter notre champ d’étude, nous avons établi un scénario ultra-classique de data mining : charger un fichier de données, construire le modèle prédictif avec l’analyse discriminante linéaire, calculer la matrice de confusion et le taux d’erreur en resubstitution . Bien évidemment, l’étude est forcément parcellaire. Il apparaît que Scilab semble moins à son avantage dans la gestion des données. Il est largement au niveau en revanche en ce qui concerne les traitements, cette dernière appréciation étant toutefois tributaire des packages ou toolbox utilisés.
Mots-clés : scilab, toolbox, nan, analyse discriminante prédictive, analyse discriminante linéaire, logiciel R, analyse prédictive, sipina
Didacticiel : fr_Tanagra_Scilab_R_Comparison.pdf
Données : waveform_scilab_r.zip
Références :
Scilab - https://www.scilab.org/fr
Michaël Baudin, "Introduction à Scilab", Developpez.com.
Data Mining avec Scilab
2013-11-05 (Tag:2641213254580975805)
Je connais le nom « Scilab » depuis fort longtemps. Je l’avais catalogué dans la catégorie des logiciels de calcul numérique, au même titre qu’Octave ou, pour parler d’outils commerciaux, de Matlab que j’avais moi-même utilisé du temps où j’étais étudiant. J’y voyais très peu d’intérêt dans le contexte du traitement statistique des données et du data mining.Récemment un collègue mathématicien m’en a reparlé. Il s’étonnait de la faible visibilité de Scilab au sein de la communauté du data mining, sachant qu’il présente des fonctionnalités tout à fait similaires à celle de R. Ah bon ? Je ne voyais pas les choses ainsi. Curieux comme je suis, je me suis bien évidemment documenté sur la question en fixant un objectif simple : est-ce qu’il est possible de réaliser - simplement, sans contorsions extravagantes – un schéma type d’analyse prédictive avec Scilab ? A savoir : charger un fichier de données (échantillon d’apprentissage), construire un modèle prédictif, en détailler les caractéristiques, charger un échantillon test, appliquer le modèle sur ce second ensemble de données, élaborer la matrice de confusion et calculer le taux d’erreur en test.
Nous verrons dans ce tutoriel que la tâche a été réalisée avec succès, relativement facilement. Scilab est tout à fait armé pour réaliser des traitements statistiques. D’emblée, deux petits bémols me sont clairement apparus lors de la prise en main de Scilab : les librairies de fonctions statistiques existent mais ne sont pas aussi fournies que celles présentes dans R ; leur documentation laisse vraiment à désirer, j’ai du pas mal batailler – et encore, je savais exactement ce que je cherchais – avant de trouver les indications nécessaires sur le web.
Il reste qu’au final, je suis très satisfait de cette première expérience. J’ai découvert un excellent outil gratuit, souple et performant, très facile à prendre en main, qui s’avère être une alternative tout à fait crédible à R dans le domaine du data mining.
Mots-clés : scilab, toolbox, nan, libsvm, analyse discriminante prédictive, analyse discriminante linéaire, logiciel R, analyse prédictive
Didacticiel : fr_Tanagra_Scilab_Data_Mining.pdf
Données : data_mining_scilab.zip
Références :
Scilab - https://www.scilab.org/fr
ATOMS : Homepage - http://atoms.scilab.org/
Wikilivres, "Découvrir Scilab"
Michaël Baudin, "Introduction à Scilab", Developpez.com.
Programmation à partir d'objets statistiques sous R
2013-10-22 (Tag:3100048809318796146)
R est un langage de programmation, R est aussi un logiciel de statistique. L’outil prend tout son sel lorsque nous dérivons de nouvelles méthodes à partir des résultats fournis par une approche existante.Dans ce document, nous montrons comment programmer une procédure statistique à partir de l’objet de type lm issue de la régression linéaire multiple. Le rôle de la commande « attributes » qui permet d’en énumérer les propriétés est primordial dans ce cadre. Il permet d’identifier les données intermédiaires que nous pouvons exploiter dans les calculs subséquents. Un petit exemple de recherche de la meilleure régression simple à partir d’un ensemble de variables prédictives candidates permet de mieux situer le potentiel du dispositif.
Nous ne l’abordons pas dans ce support, mais une extension naturelle de la démarche serait d’encapsuler les nouvelles procédures et fonctions dans un package, et de le diffuser à grande échelle sur le web.
Mots clés : programmation r, objets, listes, attributes, summary, logiciel r
Lien : Programmation à partir d'objets statistiques sous R
Références :
Vincent Goulet, " Introduction à la programmation en R ".
La classe data frame sous R
2013-10-20 (Tag:4096622656208426283)
La classe « data frame » est primordiale sous R. Elle est dédie à la gestion des ensembles de données de type individus – variables (lignes x colonnes). Ce qui correspond au format le plus répandu en statistique exploratoire et data mining.Un objet data frame est une liste de vecteurs de même longueur. Ils représentent les variables de la base à traiter. Ils sont le plus souvent numériques (variables quantitatives) ou de type factor (variables qualitatives). Nous pouvons également considérer le data frame sous l’angle d’une matrice de valeurs. A cet égard, R propose de nombreuses fonctionnalités pour réaliser des restrictions et des projections via l’indexation par des vecteurs de booléens, qui peut éventuellement résulter d’une condition. Mettre en place des requêtes complexes devient relativement aisé.
Dans sa dernière partie, notre document présente l’utilisation des outils sapply() et lapply(). Ils sont destinés à appliquer des traitements sur les colonnes successives d’un ensemble de données en appelant des fonctions callback. Ils s’avèrent particulièrement performants par rapport à une programmation usuelle s’appuyant sur des boucles.
Mots clés : programmation r, data.frame, listes, sapply, lapply, importation de fichiers, package xlsx, excel, logiciel r
Lien : Le type data frame sous R
Références :
Vincent Goulet, " Introduction à la programmation en R ".
Tableaux et matrices sous R
2013-10-19 (Tag:1340916549748592669)
« Tableaux et matrices sous R » est le document de référence pour la 4ème séance du cours de programmation R. Une matrice est un vecteur encapsulé dans une structure particulière possédant l’attribut dim. L’accès indicé (ligne, colonne) devient possible.Nous pouvons réaliser des extractions de lignes et/ou de colonnes. La manipulation des matrices préfigure ainsi les fonctionnalités applicables sur le type data frame qui représente les ensembles de données (un tableau individus x variables peut être assimilé à une matrice d’une certaine manière).
Enfin, les matrices proposent des opérateurs qui leur sont propres (inversion, produit matriciel, diagonalisation, décomposition en valeurs singulières, etc.). La fonction apply() permet de s’affranchir des boucles en appliquant une fonction callback sur les lignes ou les colonnes d'une matrice.
Mots clés : programmation r, tableau, matrice, apply, logiciel r
Lien : Tableaux et matrices sous R
Références :
Vincent Goulet, " Introduction à la programmation en R ".
Manipulation des vecteurs sous R
2013-10-17 (Tag:6817460799593258771)
Le vecteur est l’objet de base dans R. Il sert à stocker une collection de valeurs de même type. Toute donnée est placée dans un vecteur dans R. Un scalaire est en réalité un vecteur de taille 1. R propose toute une panoplie d’outils pour leur manipulation. Nous pouvons extraire une sous-partie des valeurs, les trier, effectuer des opérations sur plusieurs vecteurs, réaliser des calculs récapitulatifs.Deux principes forts régissent le fonctionnement des vecteurs : sauf utilisation d’opérateurs spécifiques, les opérations s’effectuent toujours élément par élément (element-wise en anglais) ; quand les tailles des vecteurs ne sont pas compatibles, R applique le recyclage c.-à-d. la réplication des valeurs. Ces particularités m’ont beaucoup rebuté quant à l’utilisation du langage R à mes débuts. Elles m’empêchaient d’interpréter correctement les codes sources que je trouvais ici ou là sur le web.
Après coup, une fois ces notions assimilées, une des barrières à l’entrée de la compréhension du langage R est allègrement franchie.
Mots clés : programmation r, vecteur, type factor, concaténation, c(), logiciel r
Lien : Manipulation des vecteurs sous R
Références :
Vincent Goulet, " Introduction à la programmation en R ".
Programmation modulaire sous R
2013-10-16 (Tag:3990807585369719821)
« Programmation modulaire sous R » décrit le découpage des programmes en procédures et fonctions dans un premier temps, puis en modules dans un second temps. Comme pour tout langage de programmation, il est possible d’agencer un projet en blocs de manière à réduire (voire éliminer) la redondance et maximiser la réutilisation.Cette étape est une première étape vers le partage du code avec les autres programmeurs. En effet, il est très facile de distribuer les procédures et fonctions d’un module en diffusant le fichier « .r ». On peut faire mieux encore en l’organisant sous forme de package (cf. référence ci-dessous).
On notera deux petites curiosités concernant le langage R : une fonction –qui correspond à un bloc d’instructions - renvoie quand même une valeur même si on ne le fait pas explicitement ; il est possible de renvoyer plusieurs résultats via le mécanisme des listes, qui se révèle particulièrement souple.
Mots clés : instructions, bloc d'instruction, fonctions, procédures, modules, source(), logiciel r
Lien : Programmation modulaire sous R
Références :
Vincent Goulet, " Introduction à la programmation en R ".
Christophe Genolini, "Construire un Package - Classic et S4".
Les bases du langage R
2013-10-13 (Tag:7263504358863951813)
Régulièrement à la mi-août, je me demande ce que je peux améliorer dans mes enseignements pour l’année universitaire à venir. Cette fois-ci, j’ai décidé de mettre sous forme de slides mon cours de R. Je n’ai jamais souhaité le faire jusqu’à présent. Il y a suffisamment de supports en ligne. Je me contentais donc de donner aux étudiants les principaux repères au tableau (écrire au tableau était aussi une manière de canaliser mon enthousiasme), en les redirigeant sur les documents les plus intéressants que j’ai pu trouver ici ou là. Au fil du temps, j’ai réussi (j'espère) à affiner la présentation pour faire passer les bons messages dans chaque séance. Je me suis rendu compte que je disais les choses à peu près de la même manière ces dernières années. Il était temps de coucher tout cela sur papier (enfin… sur PDF).« Introduction à la programmation R » correspond à ma première séance sur R en Master 2 IDS-SISE (Informatique et Statistique, Data Mining). Il s’agit d’introduire R en tant que langage de programmation dans un premier temps. De fait, j’occulte sciemment les fonctionnalités statistiques en adoptant une présentation ultra-classique d’un cours de programmation quelconque (ex. Pascal, C, etc.). Sont ainsi décrits les types de données (sous leur forme scalaire), les entrées et sorties à la console, les structures algorithmiques (branchements conditionnels, boucles indicées, boucles conditionnelles). La séance est complétée par une série d’exercices d’algorithmie directement appliqués sur machines.
Mots clés : programmation r, types de données, branchements conditionnels, boucles, séquences, logiciel r
Lien : Introduction à R
Références :
Vincent Goulet, " Introduction à la programmation en R ".
Tanagra - Version 1.4.49
2013-09-15 (Tag:4967411874709011572)
Quelques perfectionnements concernant les techniques d’analyse factorielle (ACP – analyse en composantes principales, ACM – analyse des correspondances multiples, AFC – analyse factorielle des correspondances, AFDM – analyse factorielle des données mixtes) ont été introduites. Les sorties en particulier ont été complétées, suite à l’écriture de supports de cours relatives à ces méthodes durant cet été 2013.La rotation VARIMAX a été améliorée. Merci à Frédéric Glausinger d’avoir proposé un code optimisé.
La correction de Benzecri a été ajoutée dans l’affichage des résultats de l’ACM. Merci à Bernard Choffat pour cette suggestion.
Page de téléchargement : setup
Analyse Factorielle de Données Mixtes - Diapos
2013-08-24 (Tag:8198270336583807768)
Voici le dernier opus de l’été 2013 consacré aux supports de cours sur les techniques factorielles. Nous détaillons l’analyse factorielle de données mixtes (AFDM) c.-à-d. capable de traiter simultanément les variables actives quantitatives et qualitatives. Curieusement, contrairement aux autres méthodes pour lesquelles il existe pléthore d’écrits, on trouve peu de documents dédiés à l’AFDM sur le net. Pourtant elle couvre une situation que l’on rencontre fréquemment dans les problèmes réels. Et, de plus, elle généralise de manière élégante l’analyse en composantes principales et l’analyse des correspondances multiples que l’on retrouve lorsque les variables sont exclusivement quantitatives ou qualitatives.Ce document repose sur l’article de Pagès (2004) que j’ai découvert par hasard lors de mes pérégrinations sur le site NUMDAM (extraordinaire portail que je conseille à tout le monde, vous y trouverez des vraies pépites !). L’approche présentée est programmée dans le package FactoMineR pour le logiciel R. Je l’ai également développée dans Tanagra, comme je le fais habituellement lorsque je cherche à appréhender précisément les contours d’une méthode.
En préparant ce support, j’ai creusé un peu plus le domaine. Je me suis rendu compte que l’AFDM, sous différentes appellations, était présente dans d’autres packages pour R (ade4, pcamixdata), qui font état d’autres références bibliographiques. Bien évidemment, je me suis précipité pour comparer les implémentations. Elles produisent des résultats identiques. Le fondement et l’expression des techniques sont bien les mêmes. Le contraire eut été passablement ennuyeux. Des approches censées traiter le même problème proposant des résultats divergents est toujours déroutant pour les praticiens de l’analyse de données.
Ce support est accompagné du fichier utilisé pour illustrer la méthode. Le programme R permettant d’obtenir tous les résultats intermédiaires est également fourni.
Mots clés : analyse factorielle de données mixtes, AFDM, logiciel R, package ade4, package factominer, package pcamixdata
Composants : AFDM
Lien : AFDM.pdf
Données : AFDMMaterial.zip
Références :
Pagès, J., "Analyse factorielle de données mixtes", Revue de Statistique Appliquée, vol. 52, no. 4, pp. 93-111, 2004.
Tutoriel Tanagra, "Analyse factorielle de données mixtes".
Analyse des correspondances multiples - Diapos
2013-08-12 (Tag:450898409082411629)
L’analyse des correspondances multiples (ACM) ou analyse factorielle des correspondances multiples (AFCM) est le pendant de l’analyse en composantes principales lorsque toutes les variables actives sont qualitatives. Elle répond donc à la même problématique mais en se plaçant dans un cadre différent : elle substitue la distance du KHI-2 à la distance euclidienne pour mesurer les proximités entre les individus ; elle utilise le PHI-2 à la place de la corrélation pour quantifier les liaisons entre les variables.L’approche est séduisante parce que, peut être plus que les autres méthodes factorielles, elle se prête à une multitude de points de vue. Il est possible de la mettre en œuvre avec un programme d’analyse des correspondances simples ou d’analyse en composantes principales. Le tout est de préparer les données à bon escient, préparations qui constituent d’autant de prismes sur les mêmes données.
Ce support de cours décrit les tenants et aboutissants de l’ACM. Il met l’accent sur la lecture des résultats. Les sorties des principaux logiciels d’analyse de données (SPAD, SAS, R et Tanagra) sont mis en parallèle. Bien évidemment, on retrouve exactement les mêmes résultats. Seule la présentation diffère.
Mots clés : analyse factorielle des correspondances multiples, AFCM, analyse des correspondances multiples, ACM, logiciel R, package ade4, SAS, proc corresp, SPAD
Composants : MULTIPLE CORRESPONDENCE ANALYSIS
Lien : ACM.pdf
Données : ACMMaterial.zip
Références :
Tanagra, "Analyse des correspondances multiples - Outils".
Analyse en composantes principales - Diapos
2013-07-29 (Tag:3060290597084547472)
Mon premier contact avec l’analyse en composantes principales, technique populaire s’il en est, a été l’excellent ouvrage (pour l'économétrie) de Christian Labrousse (« Introduction à l’économétrie », édition de 1983, chapitre 7). J’avoue que ça a été un vrai désastre. Le féru d’économétrie que j’étais, qui ne carburait qu’à la somme des carrés des résidus et au maximum de vraisemblance, a été complètement dérouté par cette histoire de régression sans variable endogène, où les erreurs seraient comptées orthogonalement. Il faut dire aussi que l’auteur n’a pas été très tendre en présentant l’ACP sans aucun exemple illustratif, et en expliquant en conclusion du chapitre qu’elle s’avérait souvent décevante car : soit elle ne proposait que des solutions évidentes ; soit la lecture des résultats reposait quasi entièrement sur les connaissances du domaine, exogènes aux données.
J’en étais resté à ces idées plutôt négatives lorsque j’ai fait une double découverte qui m’a ouvert les yeux, et m’a emmené à considérer sous un tout autre angle les techniques factorielles en général. J’ai eu accès à la bibliothèque aux extraordinaires ouvrages d’Escofier - Pagès (1988) et de Volle (1985) qui présentent l’ACP sous un angle autrement plus sympathique. Et, dans le même temps, j’ai découvert les logiciels SPAD.N, CHADOC, et STATITCF dans les salles de libre accès de l’Université. Enfin, je pouvais toucher du doigt ce qu’on pouvait obtenir de l’analyse en composantes principales en la mettant en œuvre sur des vrais fichiers de données. Et ça a été une vraie révélation. Depuis, je n’ai eu cesse d’explorer le domaine, en lisant d’autres ouvrages (pour changer, les meilleurs sont en français, voir la bibliographie), en testant d’autres logiciels, en écrivant mes propres implémentations. Par exemple, je me suis ainsi rendu compte qu’il y avait plusieurs manières de programmer l’ACP en étudiant les différences entre princomp() et prcomp() de R. Je trouve tout ça passionnant, aujourd’hui et pour longtemps encore j’imagine.
Il fallait bien que je me lance à un moment ou un autre. J’ai décidé d’écrire un support sur l’ACP bien qu’elle ne fasse pas partie de mes cours attitrés. Un support de plus serait-on tenté de dire, faites « analyse en composantes principales » dans Google pour voir. Ce document essaie surtout de faire la synthèse des nombreux tutoriels que j’ai écrits sur les différents aspects de l’ACP, disponibles sur ce site. Il est un peu verbeux pour des diapos car, à terme, il servira de base pour l’écriture d’un fascicule de cours dédié à la pratique de l’analyse factorielle.
Mots clés : analyse en composantes principales, ACP, logiciel R, package ade4, package ca, package factominer, package psych, princomp, prcomp, sas, proc factor, spad, analyse en facteurs principaux, analyse de harris, rotation varimax
Composants : PRINCIPAL COMPONENT ANALYSIS, FACTOR ROTATION, PRINCIPAL FACTOR ANALYSIS
Lien : ACP.pdf
Données : autos-acp-diapos.xls
Page de cours : Cours Analyse factorielle
Références :
B. Escofier, J. Pagès, "Analyses factorielles simples et multiples. Objectifs, méthodes et interprétation", Dunod, 1988.
M. Volle, "Analyse des données", Economica, 1985.
Analyse des correspondances discriminante - Diapos
2013-07-13 (Tag:2448206788111177586)
L’analyse des correspondances discriminante (ACD) est le pendant de l’analyse factorielle discriminante pour les variables descriptives qualitatives. Les observations sont regroupées en classes, et sont décrites par un ensemble de descripteurs. L’objectif est de construire des facteurs, combinaisons linéaires des indicatrices de ces descripteurs, qui permettent de discerner au mieux les classes.Dans ce diaporama, nous explicitons les fondements de la méthode. Nous montrons sa mise en œuvre et la lecture des résultats. Le tutoriel dédié à l’ACD (cf. références) est un bon complément à ce diaporama. Les données exemples sont traitées avec Tanagra et R.
Mots clés : analyse factorielle discriminante, ACD, discriminant correspondence analysis, DCA, analyse discriminante descriptive, analyse des correspondances, logiciel R, package ca
Composants : DISCRIMINANT CORRESPONDENCE ANALYSIS
Lien : ACD.pdf
Données : ACDMaterial.zip
Références :
H. Abdi, « Discriminant correspondence analysis », In N.J. Salkind (Ed.): Encyclopedia of Measurement and Statistics. Thousand Oaks (CA): Sage. pp. 270-275, 2007.
Tanagra, "Analyse des correspondances discriminante - Tutoriel".
Analyse factorielle des correspondances - Diapos
2013-07-01 (Tag:6700281762316447430)
L’analyse des correspondances simples (AFC pour analyse factorielle des correspondances) est une technique factorielle qui vise à présenter de manière synthétique et graphiquement les informations contenues dans les grands tableaux croisés. L’objectif est d’une part d’identifier les similitudes et différences entre les profils lignes (entre les profils colonnes), d’autre part de mettre en évidence les attractions / répulsions entre les modalités lignes et colonnes. Elle s’applique principalement aux tableaux de contingence. Mais elle peut également s’étendre à tous tableaux croisés de valeurs positives, pourvu que les notions de marges et de profils soient licites.Dans ce support de cours (sous forme de diaporama), nous présentons l’AFC en plusieurs étapes. Nous partons tout d’abord de la notion de distance entre profils (lignes et colonnes), puis nous montrons comment calculer l’association les modalités lignes et colonnes via la statistique du test du KHI-2 d’indépendance. Nous constatons que ces analyses sont autant des points de vue différents de l’information contenue dans le tableau de données. Nous présentons alors l’AFC à travers la décomposition en valeurs singulières du tableau des résidus standardisés. Par rapport à l’école française qui montre plutôt l’AFC comme une double analyse en composante principale (ACP), ce mode de présentation - que l’on retrouve dans les ouvrages en langue anglaise - a l’avantage de mettre en évidence la simultanéité de l’analyse en ligne et en colonne du tableau.
Un exemple est traité à l’aide des logiciels SPAD, SAS, TANAGRA et R. Les données et codes sources associés sont accessible via le lien ci-dessous. Nous mettons également en référence plusieurs tutoriels où nous avions montré la mise en œuvre de la méthode sur d’autres jeux de données, à l’aide d’autres logiciels.
Mots clés : analyse factorielle des corresponsances, AFC, analyse des correspondances simples, logiciel R, package ade4, package ca, package FactoMineR
Composants : CANONICAL DISCRIMINANT ANALYSIS
Lien : AFC.pdf
Données : AFCMaterial.zip
Références :
Tanagra, "AFC - Association médias et professions".
Tanagra, "Analyse des correspondances - Comparaisons".
Tanagra, "Analyse factorielle des correspondances avec R".
Programmation parallèle sous R
2013-06-17 (Tag:8838441096300230341)
Les ordinateurs personnels sont de plus en plus performants. Ils sont maintenant pour la plupart dotés de processeurs multi-cœurs. Dans le même temps, les logiciels grands publics de Data Mining, libres ou non, restent souvent monothread. Un seul cœur est sollicité durant les calculs, tandis que les autres restent inactifs. Ca fait un peu gaspillage.Récemment, nous avons introduit deux variantes multithread de l’analyse discriminante linéaire dans Sipina 3.10 et 3.11. Après une analyse succincte de l’algorithme, nous nous sommes concentrés sur la construction de la matrice de variance covariance intra-classes qui semblait constituer le principal goulot d’étranglement du processus. Deux types de décomposition des calculs ont été proposés, que nous avons exploité en nous appuyant sur la programmation multithread sous Delphi (langage de développement de Sipina). Nous avons constaté que l’amélioration des performances par rapport à la version séquentielle est spectaculaire lorsque l’ensemble des cœurs disponibles sur la machine sont pleinement utilisés.
Durant le travail d’analyse qui m’a permis de mettre au point les solutions introduites dans Sipina, j’avais beaucoup étudié les mécanismes de parallélisation disponibles dans d’autres outils de Data Mining. Ils sont plutôt rares en réalité. J’avais quand même noté que des stratégies très perfectionnées sont proposées pour le logiciel R. Il s’agit souvent d’environnements qui permettent d’élaborer des programmes tirant parti des capacités étendues des machines à processeurs multi-cœurs, multiprocesseurs, et même d’un cluster de machines. Je me suis intéressé en particulier au package « parallel » qui est lui-même une émanation des package « snow » et « multicore » . Entendons-nous bien, la librairie ne permet pas d’accélérer miraculeusement une procédure existante. En revanche, elle nous donne l’opportunité d’exploiter efficacement les ressources machines à condition de reprogrammer la procédure en réorganisant judicieusement les calculs. L’idée maîtresse est de pouvoir décomposer le processus en tâches que l’on peut exécuter en parallèle, charge à nous par la suite d’effectuer la consolidation.
Dans ce tutoriel, nous détaillons la parallélisation d’un algorithme de calcul d’une matrice de variance covariance intra-classes sous R 3.0.0. Dans un premier temps, nous décrivons un programme séquentiel, mais facilement transformable. Dans un deuxième temps, nous utilisons les outils des packages « parallel » et « doParallel » pour lancer les tâches élémentaires sur les cœurs disponibles. Nous comparerons alors les temps de traitement. Disons-le d’emblée, contrairement aux exemples jouets que l’on peut consulter ici ou là sur le web, le bilan est passablement mitigé quand il s’agit de traiter des bases volumineuses réalistes. Les solutions achoppent sur la gestion des données.
Mots-clés : analyse discriminante linéaire, logiciel R, package parallel, package doparallel, parLapply, mclapply, foreach
Didacticiel : fr_Tanagra_Parallel_Programming_R.pdf
Fichiers : parallel.R, multithreaded_lda.zip
Références :
R-core, Package 'parallel', April 18, 2013.
Multithreading équilibré pour la discriminante
2013-06-04 (Tag:8559945433596892734)
Dans le document « Multithreading pour l’analyse discriminante », nous présentions une implémentation multithread de l’analyse discriminante à destination des machines à processeurs multi-coeurs ou multiprocesseurs. A occupation mémoire égale par rapport à la version séquentielle, elle permettait de réduire les temps de calculs dans des proportions considérables en fonction des caractéristiques des données. La solution présentait néanmoins deux faiblesses : le nombre de coeurs utilisé était tributaire du nombre de classes K dans la base à traiter ; l’équilibrage des charges entre les cœurs dépendait de leur fréquence. Ainsi, sur une des bases d’expérimentation avec K = 2 classes très fortement déséquilibrées, le gain était quasi-nul par rapport à la version monothread.Dans ce tutoriel nous présentons une nouvelle solution implémentée dans Sipina 3.11. Au prix d’une occupation mémoire accrue, que nous préciserons, elle permet de surmonter les deux goulots d’étranglement pointés sur la version précédente. Les capacités de la machine sont pleinement utilisées. Plus intéressant même, le nombre de threads devient paramétrable, permettant à l’utilisateur d’adapter les ressources machines à exploiter pour le traitement des données.
Pour mieux situer les améliorations induites par notre stratégie, nous comparons nos temps d’exécution avec la version multithread parcimonieuse en mémoire développée précédemment, la version séquentielle, et la référence SAS 9.3 (proc discrim).
Mots-clés : sipina, multithreading, thread, multithreaded data mining, multithread processing, analyse discriminante prédictive, analyse discriminante linéaire, sas, proc discrim
Didacticiel : fr_Tanagra_Sipina_LDA_Threads_Bis.pdf
Données : multithreaded_lda.zip
Références :
Tanagra, "Multithreading pour les arbres de décision".
Tanagra, "Analyse discriminante linéaire - Comparaisons".
Wikipédia, "Analyse discriminante linéaire".
Sipina - Version 3.11
2013-05-30 (Tag:266766810703800966)
Une nouvelle version multithread de l’analyse discriminante linéaire est ajoutée dans Sipina 3.11. Par rapport à la précédente, elle présente le double avantage (1) de pouvoir utiliser tous les ressources disponibles sur les machines à processeurs multi-cœurs ou multiprocesseur ; (2) de mieux équilibrer la répartition des charges. Elle est en revanche plus gloutonne en espace mémoire, les structures internes de calcul sont dupliquées M fois (M est le nombre de threads).Un tutoriel viendra comparer le comportement de cette nouvelle approche avec la version précédente et l’implémentation monothread.
Site web : Sipina
Chargement : Fichier setup
Multithreading pour l'analyse discriminante
2013-05-25 (Tag:5750219052902680950)
Le volume des données à traiter ne cesse d’augmenter dans le Data Mining. Avec le phénomène « Big Data », la gestion de la volumétrie devient un critère clé. Dans le même temps, nos machines personnelles sont de plus en plus puissantes, intégrant pour la très grande majorité d’entre eux plusieurs cœurs de calcul, si ce n’est plusieurs processeurs. Et pourtant, rares sont les logiciels généralistes qui exploitent pleinement les possibilités des machines modernes.A l’instar d’un précédent document où nous détaillons une solution basée sur les threads pour l’induction des arbres de décision , nous proposons une nouvelle stratégie multithread pour l’analyse discriminante linéaire (prédictive) dans SIPINA 3.10. Cette méthode, très favorablement connue des statisticiens, est curieusement peu implémentée dans les logiciels d’obédience informatique. Alors que, sauf cas pathologiques que l’on sait identifier , elle présente des performances en prédiction comparables aux autres techniques linéaires sur la majorité des données, je pense notamment à la très populaire régression logistique (Saporta, 2006 – page 480 ; Hastie et al., janv. 2013 – page 128). Et, en termes de rapidité de traitements sur les grandes bases, elle est incomparablement plus rapide, plus encore lorsque nous exploitons l’architecture multi-coeur (ou multiprocesseur) des machines comme nous le constaterons durant nos expérimentations.
Pour mieux situer les améliorations induites par notre stratégie, nous comparons nos temps d’exécution avec des logiciels reconnus tels que SAS 9.3 (proc discrim), R (lda du package MASS) et Revolution R Community (une version « optimisée » de R).
Mots-clés : sipina, multithreading, thread, multithreaded data mining, multithread processing, analyse discriminante prédictive, analyse discriminante linéaire, sas, proc discrim, logiciel R, lda, package MASS
Composants : LINEAR DISCRIMINANT ANALYSIS
Didacticiel : fr_Tanagra_Sipina_LDA_Threads.pdf
Données : multithreaded_lda.zip
Références :
Tanagra, "Multithreading pour les arbres de décision".
Tanagra, "Analyse discriminante linéaire - Comparaisons".
Wikipédia, "Analyse discriminante linéaire".
Sipina - Version 3.10
2013-05-23 (Tag:5814075861645185803)
L’analyse discriminante linéaire a été améliorée. Toutes les opérations sont réalisées en une seule passe sur les données.Une version multithreadée de l’analyse discriminante linéaire a été ajoutée. Elle améliore la rapidité d’exécution en répartissant les calculs sur les éventuels coeurs (ordinateur avec un processeur multicoeur) ou processeurs (ordinateur multiprocesseur) présents sur la machine.
Un tutoriel à venir décrira le comportement de ces nouvelles implémentations sur quelques grandes bases de données.
Site web : Sipina
Chargement : Fichier setup
Classifieurs linéaires
2013-05-11 (Tag:334899540971735886)
L’apprentissage supervisé a pour objectif de mettre au jour une liaison fonctionnelle f(.) entre une variable cible Y (variable à prédire, variable expliquée, etc.) que l’on cherche à prédire et une ou plusieurs variables prédictives (les descripteurs, les variables explicatives, etc.) (X1, X2, ..., Xp). La fonction est paramétrée.Dans ce tutoriel, nous étudions le comportement de 5 classifieurs linéaires sur des données artificielles. Les modèles linéaires sont des outils privilégiés de l’apprentissage supervisé. En effet, s’appuyant sur une simple combinaison linéaire des variables prédictives, ils présentent l’avantage de la simplicité : la lecture de l’influence de chaque descripteur est relativement facile (signes et valeurs des coefficients) ; les techniques d’apprentissage sont souvent rapides, même sur de très grandes bases de données. Nous nous intéresserons plus particulièrement à : (1) le modèle bayésien naïf (modèle d’indépendance conditionnelle), (2) l’analyse discriminante linéaire, (3) la régression logistique, (4) le perceptron simple, et (5) les machines à vaste marge (SVM, support vector machine).
L’expérimentation a été entièrement menée sous le logiciel R. Nous montrons également la mise en oeuvre de ces différentes techniques avec les logiciels Tanagra, Knime, Orange, RapidMiner et Weka.
Mots clés : modèles linéaires, bayésien naïf, modèle d'indépendance conditionnelle, analyse discriminante prédictive, régression logistique, perceptron, réseaux de neurones, svm linéaire, arbres de décision, rpart, random forest, forêts aléatoires, k-nn, k-ppv, plus proches voisins, package e1071, package MASS, package nnet, package lattice, package rpart, package rf, package class
Composants : NAIVE BAYES CONTINUOUS, LINEAR DISCRIMINANT ANALYSIS, BINARY LOGISTIC REGRESSION, MULTILAYER PERCEPTRON, SVM
Lien : fr_Tanagra_Linear_Classifier.pdf
Données : linear_classifier.zip
Références :
Wikipedia, "Linear Classifier".
Associations dans la distribution SIPINA
2013-04-23 (Tag:86436168139003867)
SIPINA est surtout connu pour ses algorithmes d’induction d’arbres de décision. En réalité, la distribution inclut deux autres outils peu connus du grand public : REGRESS, spécialisé dans la régression linéaire multiple, nous l’avions décrit dans un de nos anciens tutoriels ; et un logiciel d’extraction de règles d’association, appelé prosaïquement « Association Rule Software » (ARS).Depuis TANAGRA, qui intègre plusieurs composants pour l’extraction des règles d’association, ARS est très peu utilisé. J’en parle très peu moi-même. Mais comme l’outil apparaît dans le menu intégré dans Excel via la macro complémentaire « sipina.xla », plusieurs internautes m’ont demandé plus de précisions quant à son utilisation et ses spécificités.
Dans ce tutoriel, je décris la mise en œuvre du logiciel ARS lorsqu’on le lance à partir d’Excel. Comme nous le verrons par la suite, l’interaction avec le tableur introduit des opportunités très précieuses en matière d’exploration des résultats. C’est un aspect très important tant la profusion des règles peut rapidement déconcerter. Pourvoir les filtrer et les trier de différentes manières est un atout fort dans la détection des règles les plus « intéressantes » au regard des objectifs de l’utilisateur. Les outils d’Excel nous seront d’un très grand secours à cet égard.
Mots clés : règles d'association, tableur, excel, mesures d'intérêt des règles
Composants : ASSOCIATION RULE SOFTWARE
Lien : fr_Tanagra_Association_Sipina.pdf
Données : market_basket.zip
Références :
R. Rakotomalala, « Règles d’association »
Tanagra, "Règles d'association - Comparaison de logiciels"
Paramétrer le perceptron multicouche
2013-04-15 (Tag:8443688834050209459)
Au premier abord, les réseaux de neurones artificiels semblent toujours un peu énigmatiques. Justement parce qu’il est question de « neurones », et que la plupart des références qui les présentent commencent quasiment toujours par des grandes envolées sur les métaphores biologiques, faisant miroiter la perspective de doter les machines d’une intelligence. Pour l’étudiant que j’étais, tout ça me paraissait bien inaccessible… et surtout ça ne répondait pas du tout aux questions simples – mais bon on est là pour réaliser des traitements après tout – que je me posais : Est-ce que la de méthode est applicable à l’analyse prédictive ? Pour quelles configurations de données et classes de problèmes est-elle la plus performante ? Comment fixer les valeurs des paramètres – s’ils existent – associés à la méthode pour la rendre plus efficace sur mes données ?Avec le temps, et une lecture assidue de la documentation y afférente, j’ai fini par comprendre que le perceptron multicouche était l’approche la plus populaire en apprentissage supervisée, qu’elle était très performante pourvu que l’on sache définir correctement le nombre de neurones dans les couches cachées. Deux extrêmes tout aussi funestes sont à éviter : si on n’en met pas assez, le modèle est peu compétitif, incapable de retranscrire la relation (le concept) entre la variable cible et les prédicteurs ; si on en met trop, le modèle devient trop performant sur l’échantillon d’apprentissage, ingérant les particularités de ce dernier, non transposables dans la population.
Ceci étant posé, on vient alors nous annoncer qu’il n’y a pas de méthode universelle pour définir le bon paramétrage et qu’il faut en réalité tâtonner en s’appuyant sur des heuristiques plus ou moins heureuses. Tout ça paraît assez obscur. L’incompréhension vient souvent du fait que, d’une part, on a du mal à appréhender le rôle des neurones de la couche intermédiaire – si l’on s’en tient à une seule couche cachée - dans la modélisation ; d’autre part, on perçoit mal également l’impact de l’augmentation ou la diminution de leur nombre.
Dans ce tutoriel, nous allons essayer d’expliciter le rôle des neurones de la couche cachée du perceptron. Nous utiliserons des données générées artificiellement pour étayer notre propos. Nous nous en tenons à 2 variables explicatives afin de pouvoir projeter les données dans le plan et ainsi décrire concrètement le comportement de l’approche. Nous travaillons avec Tanagra 1.4.48 dans un premier temps puis, dans un second temps, nous proposerons une petite routine de détection automatique du nombre optimal de neurones pour R 2.15.2 (package nnet).
Mots clés : apprentissage supervisé, réseau d neurones, perceptron simple, perceptron multicouche, sélection de variables
Composants : MULTILAYER PERCEPTRON, FORMULA
Lien : fr_Tanagra_Optimal_Neurons_Perceptron.pdf
Données : artificial2d.zip
Références :
Tanagra, "Réseaux de neurones avec SIPINA, TANAGAR et WEKA".
Wikipedia, "Multilayer perceptron".
.
Analyse des correspondances multiples - Outils
2012-12-24 (Tag:2964936801206523512)
L’analyse des correspondances multiples (ACM) est une technique factorielle qui s’applique aux tableaux « individus - variables », ces dernières étant exclusivement catégorielles. On peut la voir comme une variante de l’analyse en composantes principales (il y a de nombreuses manières de la voir en réalité). D’ailleurs, lorsque les descripteurs sont tous binaires, les deux approches se rejoignent. A la sortie, nous obtenons une description synthétique des données qui préserve les proximités entre les individus, met en évidence les liaisons entre les variables et, éventuellement, permettre de situer des groupes d’observations partageant les mêmes caractéristiques. Je n’en dirai pas plus, il existe de très nombreux supports de qualité sur internet qui permettent de situer relativement simplement les tenants et aboutissants de cette méthode.Nous avons décrit la mise en œuvre de l’ACM dans plusieurs tutoriels, notamment sous Tanagra et sous R avec le package FactoMiner. Les sorties du composant « MULTIPLE CORRESPONDENCE ANALYSIS » ayant été complétées dans la version 1.4.48 de Tanagra, je me suis dit que la meilleure manière de situer les avancées est de comparer les tableaux de résultats fournis par Tanagra avec ceux des autres logiciels. Ce travail permet aux étudiants de se dégager de l’autocratie des logiciels : comprendre la méthode est le plus important, qu’importent les outils, tous – normalement, si ce n’est pas le cas il faut comprendre pourquoi – fourniront en définitive les mêmes résultats.
Dans un premier temps, nous décrirons la mise en œuvre de Tanagra sur une base de données comportant 8403 individus décrits par 23 variables. Nous mettrons en parallèle les sorties de SAS 9.3 (PROC CORRESP). Par la suite, nous mènerons la même étude avec R via le package « ade4 », puis avec STATISTICA. Nous constaterons que si les solutions numériques sont identiques, la manière de les présenter peut différer d’un logiciel à l’autre.
Mots clés : analyse des correspondances multiples, ACM, analyse factorielle des correspondances multiples, AFCM, logiciel R, package ade4, statistica, sas, proc corresp, détection du nombre de facteurs
Composants : MULTIPLE CORRESPONDENCE ANALYSIS, PARALLEL ANALYSIS
Lien : Tutoriel ACM
Données : mca_loisirs.zip
Références :
H. Abdi, D. Valentin, « Multiple correpondence analysis », In N.J. Salkind (Ed.): Encyclopedia of Measurement and Statistics. Thousand Oaks (CA): Sage, 2007.
Analyse des correspondances discriminante
2012-12-15 (Tag:5641161286711732617)
L’analyse factorielle discriminante ou analyse discriminante descriptive vise à décrire et à expliquer l’appartenance des observations à des groupes prédéfinis à partir d’un ensemble de variables explicatives (variables prédictives, descripteurs). Etant basée sur la décomposition de la variance, elle ne s’applique qu’aux variables explicatives quantitatives. La solution n’est pas directement transposable aux variables catégorielles (qualitatives).J’ai découvert récemment un article d’Hervé Abdi (2007). Il propose d’exploiter les propriétés de l’analyse factorielle des correspondances (AFC) pour résoudre le problème de l’analyse discriminante descriptive sur variables catégorielles. L’approche, appelée « discriminant correspondence analysis » traduite librement par « analyse des correspondances discriminante », repose sur une transformation ingénieuse des données « individus x variables » en un tableau de contingence un peu particulier. A la sortie nous obtenons des résultats qui décrivent les relations entre les modalités de la variable cible (qui définissent l’appartenance aux groupes) et celles des variables explicatives qualitatives. Il est même possible d’obtenir une représentation graphique révélant les attractions et répulsions.
Dans ce tutoriel, nous montrons la mise en œuvre de la méthode dans Tanagra 1.4.48. Nous reprendrons l’exemple de l’article de référence de la méthode. Il s’agit de caractériser la provenance des vins à partir de leurs propriétés. Notre objectif est d’expliquer pas à pas l’approche en associant les résultats de Tanagra à chaque étape de l’article. Par la suite, nous reproduisons les calculs à l’aide d’un programme écrit pour le logiciel R.
Mots clés : analyse factorielle discriminante, ACD, discriminant correspondence analysis, DCA, analyse discriminante descriptive, analyse des correspondances, logiciel R, package xlsx, package ca
Composants : DISCRIMINANT CORRESPONDENCE ANALYSIS
Lien : Tutoriel DCA
Données : french_wine_dca.zip
Références :
H. Abdi, « Discriminant correspondence analysis », In N.J. Salkind (Ed.): Encyclopedia of Measurement and Statistics. Thousand Oaks (CA): Sage. pp. 270-275, 2007.
Analyse des correspondances - Comparaisons
2012-12-12 (Tag:1817609395576183678)
L’analyse des correspondances est une méthode statistique de réduction de dimension. Elle propose une vision synthétique de l’information intéressante d’un tableau de contingence. Son pouvoir de séduction repose en grande partie sur les représentations graphiques qu’elle propose. Elles nous permettent de situer facilement (beaucoup le pensent en tous cas) les similarités (dissimilarités) et les attractions (répulsions) entre les modalités. L’AFC est bien une technique factorielle. Les facteurs – les variables latentes – qui en sont issus sont des combinaisons linéaires des points modalités (lignes ou colonnes) exprimés par des profils (lignes ou colonnes).Dans ce tutoriel, nous décrivons la mise en œuvre de l’AFC dans plusieurs logiciels : la version 1.4.48 de Tanagra qui intègre des nouveautés destinées à améliorer la lecture des résultats ; le logiciel R avec les packages « ca » et « ade4 » ; le logiciel OpenStat ; et le logiciel SAS qui servira de référence. Nous constaterons – comme toujours – que tous ces logiciels produisent exactement les mêmes résultats numériques (heureusement !). Les différences se situent essentiellement au niveau de la mise en valeur des sorties.
Mots clés : afc, analyse factorielle des correspondances, représentation quasi-barycentrique, logiciel R, package ca, package ade4, openstat, sas
Composants : CORRESPONDENCE ANALYSIS
Lien : fr_Tanagra_Correspondence_Analysis.pdf
Données : statements_foods.zip
Références :
M. Bendixen, « A practical guide to the use of the correspondence analysis in marketing research », Marketing Research On-Line, 1 (1), pp. 16-38, 1996.
Tutoriel Tanagra, "AFC - Association médias et professions".
Tanagra - Version 1.4.48
2012-12-01 (Tag:1802548569734759433)
De nouveaux composants ont été implémentés.K-Means Strengthening. Ce composant m’a été suggéré par Mme Claire Gauzente. Il s’agit de « confirmer » une partition existante (ex. issue d’une CAH – Classification ascendante hiérarchique) à l’aide de plusieurs passes de l’algorithme des centres mobiles. Une comparaison des partitions avant et après optimisation est proposée, indiquant l’efficacité de la post-optimisation. Dans Tanagra, l’approche peut intervenir après toute technique de clustering. Merci à Claire pour cette idée très intéressante.
Discriminant Correspondence Analysis. Analyse factorielle discriminante pour les variables qualitatives (Hervé Abdi, 2007). Elle vise à caractériser l’appartenance des individus à des groupes (définies par une variable cible) à l’aide d’un ensemble de variables descriptives qualitatives. La méthode s’appuie sur une transformation du tableau de données attribut-valeur en un tableau de contingence qui permet l’application d’une analyse factorielle des correspondances. Nous retrouvons dès lors le mode de lecture habituel des résultats de cette dernière (coordonnées factorielles, contributions, qualité de représentation).
D’autres composants ont été améliorés.
HAC. Après le choix du nombre de classes dans le dendrogramme dans la classification ascendante hiérarchique, une dernière passe sur les données est effectuée, affectant chaque individu de l’échantillon d’apprentissage au centre de classes qui leur est le plus proche. La même approche est mise en œuvre lorsqu’il s’agit de déployer le modèle de classification aux individus supplémentaires. De fait, il peut y avoir incohérence entre le nombre d’observations affiché sur les nœuds du dendrogramme et le nombre d’individus dans les classes. Tanagra fournit à présent les deux informations. Seule la seconde est utilisée pour le déploiement et le calcul des statistiques descriptives subséquentes (moyennes conditionnelles pour la comparaison des groupes, etc.).
Correspondence Analysis. Tanagra fournit maintenant les coefficients des fonctions de projection pour les lignes et colonnes supplémentaires dans l’analyse factorielle des correspondances (AFC). Il sera ainsi possible de calculer facilement les coordonnées factorielles d’un nouveau point décrit par un profil ligne ou colonne. Enfin, les tableaux de résultats peuvent être triés suivant les contributions aux axes des lignes et des colonnes.
Multiple correspondence analysis. Plusieurs améliorations ont été apportées à l’analyse factorielle des correspondances multiples (AFCM) : le composant sait prendre en compte les variables supplémentaires quantitatives et qualitatives ; les variables peuvent être triées selon leur contribution aux axes ; tous les indicateurs d’évaluation peuvent être réunis dans un seul grand tableau pour une vision synthétique des résultats, cette fonctionnalité est surtout intéressante si on s’en tient à un faible nombre de facteurs ; les fonctions de score sont fournies, elles permettent de calculer facilement les coordonnées factorielles des individus supplémentaires en dehors de Tanagra.
Des tutoriels viendront décrire la mise en œuvre de ces composants dans des études de cas réalistes.
Page de téléchargement : setup
Data Mining avec Orange
2012-10-30 (Tag:6356419299977173729)
Exceptionnellement, je présente dans ce post un tutoriel que je n’ai pas écrit, découvert au fil de mes recherches sur le net. Il décrit en détail, et surtout de manière particulièrement claire, les fonctionnalités du logiciel Orange.Je trouve ce document très intéressant parce qu’il nous permet de cerner ce que nous pouvons attendre d’un logiciel de Data Mining. Il s’articule autour d’une démarche classique d’analyse de données : importation, vérification et préparation des données, visualisation graphique, modélisation, évaluation.
Par rapport aux autres logiciel libres (ou accessibles gratuitement), Orange est très « user-friendly ». Il se démarque par ses outils graphiques, intuitifs et interactifs.
Mots clés : logiciel orange, arbres de décision, induction de règles, classifieur bayesien naïf, cah, classification ascendante hiérarchique, k-means, nuées dynamiques, courbe roc, matrice de coûts
Lien : Janez Demsar, "Data Mining".
Références :
Orange - Data Mining Fruitful & Fun -- http://orange.biolab.si/
Analyse en facteurs principaux
2012-09-25 (Tag:9068149878500710327)
On parle souvent de l'analyse en facteur principaux (AFP) en contrepoint à l'analyse en composantes principales (ACP) dans la littérature anglo-saxonne. Qu’est ce qui les distingue, qu’est-ce qui les réunit ? Ce sont des techniques factorielles, raison pour laquelle on les confond bien souvent. Mais l’ACP cherche à résumer de manière la plus efficace possible l’information disponible en s’intéressant à la variabilité totale portée par chaque variable de la base. Il s’agit donc d’une technique de compression, intéressante surtout lorsque l’on cherche à exploiter les facteurs dans des études subséquentes (ex. analyse discriminante sur facteurs). En revanche, l’AFP cherche à structurer l’information en s’intéressant à la variabilité commune aux variables. L’idée est de mettre en avant des facteurs sous-jacents (variables latentes) qui associent deux ou plusieurs colonnes des données. L’influence des variables qui font cavalier seul, indépendantes des autres, devrait être écartée.Elles sont donc différentes de par la nature des informations qu’elles exploitent. Mais la nuance n’est pas évidente. D’autant plus qu’elles sont souvent regroupées dans le même outil dans certains logiciels, que les tableaux de résultats sont identiques, et que les interprétations sont finalement très proches.
Dans ce tutoriel, nous décrirons trois techniques d’analyse factorielle pour variables quantitatives (Principal Component Analysis - ACP, Principal Factor Analysis, Harris Component Analysis). Nous nous en tiendrons aux algorithmes non itératifs pour les deux dernières. L’ACP, maintes fois présentée, servira surtout de repère pour les deux suivantes. Nous les distinguerons en détaillant la matrice (de corrélation pour l’ACP) qui sera présentée à l’algorithme de diagonalisation. Ce prisme permet de comprendre le type d’information que les méthodes mettent en avant à l’issue des calculs. Pour appuyer l’exposé, nous préciserons chaque étape des opérations sous le logiciel R en mettant en miroir les résultats fournis par SAS (PROC FACTOR). Par la suite, nous décrirons leur mise en œuvre sous les logiciels Tanagra 1.4.47, R avec le package PSYCH et SPSS 12.0.1.
Mots clés : ACP normée, analyse en facteurs principaux, analyse de Harris, corrélation reproduite, corrélation résiduelle, corrélation partielle, rotation varimax, logiciel R, package psych, principal( ), fa( ), proc factor, SAS, SPSS
Composants : PRINCIPAL COMPONENT ANALYSIS, PRINCIPAL FACTOR ANALYSYS, HARRIS COMPONENT ANALYSIS, FACTOR ROTATION
Lien : fr_Tanagra_Principal_Factor_Analysis.pdf
Données : beer_rnd.zip
Références :
D. Suhr, "Principal Component Analysis vs. Exploratory Factor Analysis".
Tanagra - Version 1.4.47
2012-09-24 (Tag:7128580671110969540)
Non iterative Principal Factor Analysis (PFA). Analyse en facteurs principaux est une technique factorielle qui cherche à mettre en évidence les variables latentes qui lient deux ou plusieurs variables actives de la base de données. A ce titre, à la différence de l’analyse en composante principales (ACP), elle s’intéresse uniquement à la variabilité partagée entre les variables. Dans les faits, elle travaille à partir d’une variante de la matrice des corrélations où pour chaque variable, sur la diagonale principale, nous remplaçons la valeur 1 par sa proportion de variance expliquée par les autres variables.Harris Component Analysis. C’est une technique factorielle qui s’intéresse à la variabilité partagée entre les variables. Elle travaille sur une seconde variante de la matrice des corrélations où les liaisons entre deux variables sont accentuées lorsqu’elles (l’une des deux ou les deux) présentent une relation forte avec les autres variables de la base. Seule l’approche non itérative a été implémentée.
Analyse en composantes principales (ACP). L’outil est complété avec la reconstitution de la matrice de corrélation. Il est aussi réorganisé en interne afin que la structure puisse couvrir les différentes variantes de techniques factorielles pour variables quantitatives ou mixtes.
Ces trois techniques peuvent être couplées avec la rotation orthogonale des axes (FACTOR ROTATION).
Elles peuvent également être couplées avec les composants d’aide à la détection du nombre adéquat d’axes : PARALLEL ANALYSIS et BOOTSTRAP EIGENVALUES.
Page de téléchargement : setup
Analyse factorielle de données mixtes
2012-09-03 (Tag:5829272854631367361)
Habituellement, on utilise l’analyse en composantes principales (ACP) lorsque toutes les variables actives sont quantitatives, l’analyse des correspondances multiples (ACM ou AFCM) lorsqu’elles sont toutes catégorielles. Mais que faire lorsque nous avons un mix des deux types de variables ?L’analyse factorielle des données mixtes (AFDM) de Jérôme Pagès (Pagès, 2004) s'appuie le codage disjonctif complet des variables qualitatives. Mais elle introduit une subtilité supplémentaire. A l’instar de l’ACP normée où l’on réduit les variables (c’est une forme de recodage) pour uniformiser leurs influences, il propose de substituer au codage 0/1 des variables qualitatives un codage 0/x où « x » est savamment calculé à partir des fréquences des modalités. On peut dès lors utiliser un programme usuel d’ACP pour mener l’analyse (Pagès, 2004 ; page 102). Les calculs donc bien maîtrisés. L’interprétation des résultats requiert en revanche un effort supplémentaire puisqu’elle sera différente selon que l’on étudie le rôle d’une variable quantitative ou qualitative.
Dans ce tutoriel, nous montrons la mise en œuvre de l’AFDM avec les logiciels Tanagra 1.4.46 et R 2.15.1 (package FactoMineR). Nous mettrons l’accent sur la lecture des résultats. Il faut pouvoir analyser simultanément l’impact des variables quantitatives et qualitatives lors de l’interprétation des facteurs. Les outils graphiques sont très précieux dans cette perspective.
Mots clés : ACP, ACM, AFCM, AFDM, corrélation linéaire, rapport de corrélation, package FactoMineR, logiciel R
Composants : AFDM, SCATTERPLOT WITH LABEL, CORRELATION SCATTERPLOT, VIEW MULTIPLE SCATTERPLOT
Lien : fr_Tanagra_AFDM.pdf
Données : AUTOS2005AFDM.txt
Références :
Jérôme Pagès, « Analyse Factorielle de Données Mixtes », Revue de Statistique Appliquée, tome 52, n°4, 2004 ; pages 93-111.
Tanagra - Version 1.4.46
2012-09-01 (Tag:4742628750087519417)
AFDM (Analyse factorielle des données mixtes). Etend l’analyse en composantes principales (ACP) aux données comportant un mélange de variables quantitatives et qualitatives. La méthode est due à Pagès (2004). Un tutoriel viendra décrire la mise en œuvre de la méthode et la lecture des résultats.Page de téléchargement : setup
Manipulation des données avec R
2012-08-08 (Tag:293116318583292725)
Le logiciel R est à la fois un logiciel de statistique, sa bibliothèque de fonctions est quasi-infinie, et un langage de programmation, avec tous les attributs associés (types de données, branchements conditionnels, boucles, modularité…).Mais, on le met peu souvent en avant, R est aussi un excellent outil de préparation des données. Il propose l’équivalent des fonctionnalités qui font la popularité des tableurs dans la phase de pré-traitement (filtres, filtres élaborés, élaboration de variables synthétiques, tris, tableaux croisés dynamiques, etc.).
Dans ce tutoriel, nous présentons succinctement les possibilités de R en matière de manipulation de données. Nous aborderons tour à tour : le filtrage, les statistiques descriptives ciblées sur des sous-populations, les tris et, très brièvement, les outils graphiques.
Analyse discriminante linéaire - Comparaisons
2012-07-17 (Tag:4759144020358341648)
L’analyse discriminante est à la fois une méthode prédictive et descriptive. Dans le premiers cas, on se réfère souvent à l’analyse discriminante linéaire. On cherche à produire un système de classement qui permet d’affecter un groupe à un individu selon ses caractéristiques (les valeurs prises par les variables indépendantes). Dans le second cas, on parle d’analyse factorielle discriminante. L’objectif est de produire un système de représentation synthétique où l’on distinguerait au mieux les groupes, en fournissant les éléments d’interprétation permettant de comprendre ce qui les réunit ou les différencie. Les finalités ne sont donc pas intrinsèquement identiques même si, en creusant en peu, on se rend compte que les deux approches se rejoignent. Certaines références bibliographiques entretiennent d’ailleurs la confusion en les présentant dans un cadre unique.Tanagra opère clairement la distinction en proposant les deux méthodes dans des composants différents : LINEAR DISCRIMINANT ANALYSIS (onglet SPV LEARNING) pour la prédiction, CANONICAL DISCRIMINANT ANALYSIS (onglet FACTORIAL ANALYSIS) pour la description. Il en est de même pour SAS avec respectivement les procédures DISCRIM et CANDISC. D’autres en revanche les associent. C’est le cas des logiciels SPSS et R, mélangeant des résultats de teneur différente. Pour les spécialistes qui savent distinguer les éléments importants selon le contexte, cet amalgame n’est pas un problème. Pour les néophytes, c’est un peu plus problématique. On peut être perturbé par des informations qui ne semblent pas en rapport direct avec les finalités de l’étude.
Dans ce tutoriel, nous détaillons dans un premier temps les sorties de Tanagra 1.4.45 concernant l’analyse discriminante linéaire. Dans un second temps, nous les mettrons en parallèle avec les résultats fournis par les logiciels R 2.15.1, SAS 9.3 et SPSS 12.0.1. L’objectif est de discerner les informations importantes pour l’analyse prédictive c.-à-d. obtenir un système simple d’affectation des individus aux classes, avoir des indications sur le rôle (interprétation) et la pertinence (significativité) des variables, et disposer d’un mécanisme de sélection de variables.
Mots clés : analyse discriminante linéaire, analyse discriminante prédictive, sélection de variables, logiciel sas, stepdisc, discrim, candisc, logiciel R, package xlsx, package MASS, lda, package klaR, greedy.wilks, matrice de confusion, taux d'erreur en resubstitution, proc discrim, proc stepdisc
Composants : LINEAR DISCRIMINANT ANALYSIS, CANONICAL DISCRIMINANT ANALYSIS, STEPDISC
Lien : fr_Tanagra_LDA_Comparisons.pdf
Données : alcohol
Références :
Wikipedia - "Analyse discriminante linéaire"
La compilation sous R
2012-07-10 (Tag:2450224327928445311)
De temps en temps, des informaticiens me tombent dessus en m’assénant que R est bien beau, mais que ça reste un langage interprété, donc notoirement lent. Invariablement je réponds que c’est indéniable, mais que nos programmes représentent la plupart du temps un enchaînement d’appels de fonctions qui, elles, sont compilées (depuis la version 2.14 tout du moins). De fait, les temps de traitements sont très peu grevés par les caractéristiques de l’interpréteur. Avec un peu d’expérience, on se rend compte que R est surtout mal à l’aise lorsque nous implémentons explicitement des boucles (ex. la boucle for). Il faut donc les éviter autant que possible.J’en étais resté à cette idée lorsque j’ai découvert le package « compiler » de Luke Tierney, inclus dans la distribution standard de R 2.14 . Il serait possible de compiler très simplement un bloc d’instructions intégré dans une fonction. Dans certaines configurations, que l’on s’attachera à déterminer justement, le « byte code » qui en découle se révèlerait nettement plus performant que le code natif passé à la moulinette de l’interpréteur.
Dans ce tutoriel, nous programmons deux traitements classiques de l’analyse de données, (1) avec et (2) sans l’utilisation des boucles : le centrage réduction des variables d’un data frame et le calcul d’une matrice de corrélation par produit matriciel. Dans un premier temps, nous mesurons les temps d’exécution respectifs des versions interprétées. Dans un second temps, nous les compilons avec la fonction « cmpfun » du package compiler, puis nous les évaluons de nouveau.
Nous constatons que le gain en vitesse d’exécution de la version compilée est particulièrement spectaculaire pour les versions avec boucles, il est négligeable en revanche pour les secondes variantes.
Mots clés : package compiler, cmpfun, byte code, package rbenchmark, benchmark
Lien : fr_Tanagra_R_compiler_package.pdf
Programme : compilation_r.zip
Références :
Luke Tierney, "A Byte Code Compiler for R", Department of Statistics and Actuarial Science, University of Iowa, March 30, 2012.
Package 'compiler' - "Byte Code Compiler"
ACP sur corrélations partielles (suite)
2012-06-16 (Tag:7873013339025735081)
Dans certains cas, les résultats de l’analyse en composantes principales propose des résultats guère décisifs, parce qu’évidents. C’est le cas lorsque l’étude est dominée par l’influence de quelques variables qui pèsent exagérément sur toutes les autres. On parle « d’effet taille ». Il est alors généralement conseillé d’ignorer la première composante pour se concentrer sur l’étude des suivantes. Mais ce n’est pas aussi simple car nous sommes alors confrontés à d’autres problèmes. Par exemple, les guides usuels (règle de Kaiser, scree plot, etc) pour la détection du nombre adéquat de facteurs deviennent inopérants. En effet, mis à part le premier, les axes sont portés par des valeurs propres très faibles, laissant à penser qu’ils correspondent à des informations résiduelles, négligeables. Bien malin celui qui pourrait dès lors déterminer les facteurs « intéressant » pour l’interprétation.Dans un ancien document, nous analysions les mensurations des différentes parties du corps. L’idée était de détecter les concomitances (ex. celui qui a de gros genoux a-t-il aussi de grosses chevilles). Très rapidement, nous nous sommes rendu compte que la taille, le poids et le genre pesaient fortement sur toutes les autres, masquant les relations pouvant exister entre les variables. Pour dépasser cette contrariété, j’avais proposé de réaliser l’ACP, non pas à partir de la matrice des corrélations brutes, mais à partir des corrélations partielles, en contrôlant l’impact des trois variables ci-dessus (cf. Saporta, 2006 ; page 197). Le diagramme de traitements était un peu complexe, mais les résultats en valaient la peine. Nous retrouvions bien les similitudes qu’il pouvait y avoir selon les différentes régions du corps.
Très récemment, je me suis rendu compte que ce type d’analyse est proposé de manière native par la proc factor du logiciel SAS. Je me suis jeté dessus pour vérifier que l’on retrouvait bien les mêmes résultats, ce qui est le cas, c’est toujours rassurant. C’est ce nouveau traitement qui vient compléter ce tutoriel (Section 7).
Enfin, puisque la procédure est somme toute assez simple, je l’ai également programmée sous R en exploitant princomp( ). La difficulté réside dans une préparation adéquate des données (Section 8). Bien évidemment, quel que soit le logiciel utilisé, nous avons exactement les mêmes résultats.
Mots clés : corrélation partielle, analyse en composantes principales, acp, sas, proc factor, partial, logiciel R, princomp, varimax
Composants : Principal Component Analysis, Scatterplot, 0_1_Binarize, Residual Scores, VARHCA, Parallel Analysis, Factor Rotation
Lien : fr_Tanagra_PartialCorrelation_PCA_continued.pdf
Données : body.xls ; body_sas.zip
Références :
Tutoriel Tanagra, "Travailler sur les corrélations partielles"
Tutoriel Tanagra, "ACP avec Tanagra - Nouveaux outils"
ACP avec Tanagra - Nouveaux outils
2012-06-15 (Tag:8388452127357418413)
L’analyse en composantes principales (ACP) est une technique exploratoire très populaire. Selon les points de vue, on peut la considérer : comme une technique descriptive où l’on essaie de résumer les données dans ses dimensions les plus importantes ; comme une technique de visualisation où l’on essaie de préserver les proximités entre les individus dans un espace de représentation réduit ; comme une technique de compression de l’information ; etc.Outre les excellents ouvrages en langue française qui les décrivent, les références sont suffisamment abondantes sur le web pour que chacun se fasse son idée. J’en ai moi-même beaucoup parlé dans plusieurs didacticiels et, récemment, j’ai décrit la programmation sous R du test de Bartlett, de l’indice KMO (MSA – Measure of Sampling Adequacy), et des indicateurs pour la détermination du nombre de facteurs en ACP. On les trouve rarement sous une forme native dans les logiciels libres, je me suis dit qu’il était opportun de les intégrer dans Tanagra 1.4.45.
Dans ce tutoriel, nous décrivons la mise en œuvre de ces nouveaux outils. Nous mettrons en parallèle, quand cela est possible, les résultats de la PROC FACTOR de SAS. Nous avons choisi cette dernière plutôt que PRINCOMP parce que ses sorties sont plus complètes.
Mots clés : analyse en composantes principales, acp, sas, proc princomp, proc factor, test de sphéricité de Bartlett, logiciel R, scree plot, cattell, règle de kaiser, règle de karlis saporta spinaki, test des bâtons brisés, analyse parallèle, randomisation, bootstrap, corrélation, corrélation partielle, rotation varimax, classification de variables, msa index, indice kmo, cercle des corrélations
Composants : PRINCIPAL COMPONENT ANALYSIS, CORRELATION SCATTERPLOT, PARALLEL ANALYSIS, BOOTSTRAP EIGENVALUES, FACTOR ROTATION, SCATTERPLOT, VARHCA
Lien : fr_Tanagra_PCA_New_Tools.pdf
Données : beer_pca.xls
Références :
Tutoriel Tanagra - "ACP – Description de véhicules"
Tutoriel Tanagra - "Analyse en Composantes principales avec R"
Tutoriel Tanagra - "ACP sous R - Indice KMO et test de Bartlett"
Tutoriel Tanagra - "ACP avec R - Détection du nombre d'axes"
Tanagra - Version 1.4.45
2012-06-12 (Tag:2363874061890054091)
Plusieurs nouveautés autour de l’analyse en composantes principales (ACP).PRINCIPAL COMPONENT ANALYSIS. Sorties additionnelles pour le composant : Dessin de la scree plot et de la courbe de l’inertie expliquée ; ACP normée – Aide à la détection du nombre d’axes avec les seuils de Kaiser-Guttman, de Karlis-Saporta-Spinaki, test des bâtons brisés de Legendre-Legendre ; ACP normée – test de Bartlett et indice KMO (indice MSA de Kaiser-Mayer-Olkin) si le déterminant de la matrice des corrélations est supérieur à 1E-45 ; ACP normée – Affichage de la matrice des corrélations brutes et des corrélations partielles.
PARALLEL ANALYSIS. Le composant calcule la distribution des valeurs propres pour un jeu de données généré aléatoirement. Il procède par randomisation. Il s’applique à l’analyse en composantes principales et l’analyse des correspondances multiples. Un facteur est considéré significatif si sa valeur propre est supérieure au quantile d’ordre 0.95 (paramétrable).
BOOTSTRAP EIGENVALUES. Calcul par ré-échantillonnage bootstrap de l’intervalle de variation des valeurs propres. Un axe est significatif si sa valeur propre est supérieure à un seuil qui dépend de la méthode sous-jacente (ACP ou ACM), ou si la borne basse de la valeur propre d’un axe est supérieure à la borne haute de la suivante. Le niveau de confiance 0.90 est paramétrable. S’applique à l’analyse en composantes principales et l’analyse des correspondances multiples.
JITTERING. S’applique aux composants de visualisation de nuages de points (SCATTERPLOT, CORRELATION SCATTERPLOT, SCATTERPLOT WITH LABEL, VIEW MULTIPLE SCATTERPLOT). Modifie très légèrement, aléatoirement, la position des points dans le nuage pour que l’utilisateur puisse identifier les superpositions.
RANDOM FOREST. Libération de la mémoire non utilisée après apprentissage des arbres de décision. Dans un apprentissage simple, cela ne porte pas à conséquence. En revanche, dans les méthodes ensemble (BAGGING, BOOSTING, et les RANDOM FOREST) où l’on empile un très grand nombre d’arbres, les capacités de calcul sont très largement améliorées. Merci à Vincent Pisetta de m’avoir signalé cet écueil.
Page de téléchargement : setup
ACP avec R - Détection du nombre d'axes
2012-06-03 (Tag:196706099335894582)
L’analyse en composantes principales (ACP) est une technique exploratoire très populaire. Il s’agit de résumer l’information contenue dans un fichier en un certain nombre de variables synthétiques, combinaisons linéaires des variables originelles. On les appelle « composantes principales », ou « axes factoriels », ou tout simplement « facteurs ». Nous devons les interpréter pour comprendre les principales idées forces que recèlent les données.Le choix du nombre de facteurs est très important. L’enjeu est de distinguer d’une part l’information pertinente (le « signal »), véhiculée par les axes que l’on choisit de retenir ; et d’autre part, l’information résiduelle – le « bruit » issu des fluctuations d’échantillonnage – traduite par les derniers facteurs que l’on choisit de négliger.
Dans ce tutoriel, nous présentons plusieurs méthodes de détermination du nombre adéquat de facteurs. Nous nous concentrerons tout d’abord sur les procédures simples, facilement opérationnelles. Les techniques de ré-échantillonnage, efficaces certes, mais gourmandes en ressources surtout lorsque la taille des fichiers augmente, feront l’objet d’une description à part. Nous détaillerons les calculs à partir des résultats d’une ACP normée menée sur une base relativement réduite. Nous travaillerons dans un premier temps avec le couple TANAGRA + tableur Excel puis, dans un second temps, nous décrirons la même analyse menée à l’aide de la fonction PRINCOMP du logiciel R. Ce document a été inspiré par plusieurs articles référencés en bibliographie.
Mots clés : analyse en composantes principales, acp, princomp, test de sphéricité de Bartlett, xslx package, logiciel R, scree plot, cattell, règle de kaiser, règle de karlis, test des bâtons brisés, analyse parallèle, randomisation, bootstrap, corrélation, corrélation partielle
Composants : PRINCIPAL COMPONENT ANALYSIS, LINEAR CORRELATION, PARTIAL CORRELATION
Lien : fr_Tanagra_Nb_Components_PCA.pdf
Données : crime_dataset_pca.zip
Références :
D. Jackson, “Stopping Rules in Principal Components Analysis: A Comparison of Heuristical and Statistical Approaches”, in Ecology, 74(8), pp. 2204-2214, 1993.
P. Neto, D. Jackson, K. Somers, “How Many Principal Components? Stopping Rules for Determining the Number of non-trivial Axes Revisited”, in Computational Statistics & Data Analysis, 49(2005), pp. 974-997, 2004.
Tutoriel Tanagra - "ACP – Description de véhicules"
Tutoriel Tanagra - "Analyse en Composantes principales avec R"
Tutoriel Tanagra - "ACP sous R - Indice KMO et test de Bartlett"
ACP sous R - Indice KMO et test de Bartlett
2012-05-26 (Tag:7874973794022905920)
L’analyse en composantes principales (ACP) est une technique exploratoire très populaire. Il y a différentes manières de l’appréhender, en voici une très simplifiée : « partant d’une base de données à ‘’n’’ observations et ‘’p’’ variables, toute quantitatives, on cherche à résumer l’information disponible à l’aide de quelques variables synthétiques qu’on appelle facteurs ». Leur nombre n’est pas défini à l’avance, sa détermination est d’ailleurs un enjeu fort dans le processus. Généralement, on en prend au moins deux afin de disposer d’une représentation graphique des individus et des variables dans le plan.Nous avons présenté maintes fois l’ACP auparavant, tant pour le logiciel R que pour Tanagra. Dans ce tutoriel, nous décrivons deux indicateurs de qualité de l’analyse qui sont directement proposés dans des logiciels commerciaux célèbres (SPSS et SAS pour ne pas les citer), mais que l’on retrouve peu ou prou dans les logiciels libres. On notera qu’ils ne sont pas non plus repris dans les ouvrages qui font référence en français. Il s’agit du test de sphéricité de Bartlett et de l’indice KMO (Kaiser – Mayer – Olkin) mesurant l’adéquation de l’échantillon. Plusieurs internautes m’ayant posé la question sur la manière des le obtenir sous R, je me suis dit qu’il y a avait là quelque chose à faire.
Dans ce qui suit, nous présentons succinctement les formules de calcul, nous leur associons un programme écrit en R, et nous montrons leur mise en œuvre sur un fichier de données. Nous comparons nos sorties avec celles du logiciel SAS.
Mots clés : analyse en composantes principales, acp, spss, sas, proc factor, princomp, indice kmo, msa index, test de sphéricité de Bartlett, xslx package, psych package, logiciel R
Composants : VARHCA, PRINCIPAL COMPONENT ANALYSIS
Lien : fr_Tanagra_KMO_Bartlett.pdf
Données : socioeconomics.zip
Références :
Tutoriel Tanagra - "ACP – Description de véhicules"
Tutoriel Tanagra - "Analyse en Composantes principales avec R"
SPSS - "Factor algorithms"
SAS - "The Factor procedure"
Le format de fichier "sparse"
2012-05-22 (Tag:6998803742786182490)
Le traitement statistique des documents non-structurés est un vrai challenge. « Non-structuré » est a priori difficile à cerner. Dans le cadre du data mining, on l’utilise généralement (en simplifiant à l'extrême, je vois déjà les puristes bondir) pour toute donnée qui s’écarte du classique attribut-valeur où l’observation est décrite par un vecteur de longueur constante de caractéristiques (ex. un client est décrit par son âge, son revenu, …).Ainsi, même si intrinsèquement le texte et l’image, pour ne citer qu’eux, ont une structure interne cohérente, un pré-traitement est nécessaire pour parvenir à une description « attribut-valeur ». Cette transformation engendre des tableaux de données volumineux avec certaines spécificités. Il est possible de les exploiter pour proposer un format de description parcimonieux, et aboutir à des fichiers de taille réduite. Il s’agit en quelque sorte d’une forme de compression sans perte. Mais le fichier reste lisible avec un simple éditeur de texte. Comme nous le constaterons pour l’exemple que nous traiterons, la réduction de la taille du fichier n’est absolument pas négligeable.
Dans ce tutoriel, nous décrivons le format de fichier « sparse » (format « creux », extension .data ou .dat) pour la régression et le classement reconnu par Tanagra (depuis la version 1.4.44), il est directement inspiré du format traité par les bibliothèques de calcul « svmlight », « libsvm » et « libcvm ». Nous illustrons son exploitation dans un processus de catégorisation de texte appliquée à la base Reuters, bien connue en data mining.
Mots clés : support vector machine, machines à vecteur de support, séparateur à vaste marge, svm, libsvm, c-svc, régression logistique, tr-irls, apprentissage supervisé, scoring, courbe roc, auc, aire sous la courbe
Composants : VIEW DATASET, CONT TO DISC, UNIVARIATE DUISCRETE STAT, SELECT FIRST EXAMPLES, C-SVC, SCORING, ROC CURVE
Lien : fr_Tanagra_Sparse_File_Format.pdf
Données : reuters.data.zip
Références :
T. Joachims, "SVMlight: Support Vector Machine".
UCI Repository, "Reuters-21578 Text Categorization Collection".
La librairie LIBCVM (Core Vector Machine)
2012-05-18 (Tag:1527078686134146226)
Les Support Vector Machine (SVM) constituent des méthodes particulièrement efficaces en apprentissage supervisé. De par leur grande stabilité, elles sont bien adaptées aux problèmes comportant un grand nombre de descripteurs relativement à la taille d’échantillon . Elles sont moins à leur avantage lorsque le nombre d’observations « n » devient important. En effet, une implémentation naïve est de complexité O(n^3) en temps de calcul et O(n^2) en espace de stockage. De fait, obtenir la solution optimale n’est pas possible en pratique. Les implémentations recherchent des solutions approchées, et en profitent au passage pour réduire les complexités.J’ai découvert récemment la librairie LIBCVM. L’idée des auteurs est très astucieuse, ils tiennent le raisonnement suivant (traduction très libre) : « Puisqu’on ne peut obtenir que des solutions approchées, on peut s’appuyer sur une formulation équivalente de la recherche des points supports, la recherche de la plus petite boule englobante (Minimum Enclosing Ball) en géométrie computationnelle, et utiliser les résultats obtenus avec cette dernière ». A la sortie, tout comme les SVM, la technique produit une série de points supports utilisables pour la prédiction, les performances prédictives sont similaires voire améliorées, avec une capacité accrue d’appréhension des grandes bases (en nombre d’observations).
Les méthodes CVM (Core Vector Machine) et BVM (Ball Vector Machine) dédiées à l’apprentissage supervisé sont implémentées dans la librairie LIBCVM. Il s’agit une extrapolation de la bibliothèque LIBSVM (version 2.85), bien connue des chercheurs. Le code source en C++ étant disponible, j’ai compilé LIBCVM (version 2.2 [beta], 29 août 2011) en DLL et je l’ai intégrée dans TANAGRA 1.4.44. Dans ce tutoriel, nous décrivons le comportement des méthodes CVM et BVM sur la base « Web data set » accessible sur le site des auteurs. Nous comparons les performances (qualité de prédiction, temps de calcul) avec celles de la méthode C-SVC de la librairie LIBSVM.
Mots clés : support vector machine, machines à vecteur de support, séparateur à vaste marge, svm, libcvm, cvm, bvm, libsvm, c-svc
Composants : SELECT FIRST EXAMPLES, CVM, BVM, C-SVC
Lien : fr_Tanagra_LIBCVM_library.pdf
Données : w8a.txt.zip
Références :
I.W. Tsang, A. Kocsor, J.T. Kwok : LIBCVM Toolkit, Version: 2.2 (beta)
C.C Chang, C.J. Lin : LIBSVM -- A Library for Support Vector Machines
Tanagra - Version 1.4.44
2012-05-14 (Tag:5391018316617476624)
LIBSVM (http://www.csie.ntu.edu.tw/~cjlin/libsvm/). Mise à jour de la librairie LIBSVM version 3.12 (Avril 2012) [concerne les composants de support vector machine : C-SVC, Epsilon-SVR, nu-SVR]. Les calculs sont plus rapides. Possibilité de normalisation ou non des données (elle était imposée auparavant).LIBCVM (http://c2inet.sce.ntu.edu.sg/ivor/cvm.html ; version 2.2). Intégration de la librairie LIBCVM. Deux méthodes sont disponibles : CVM et BVM (Core Vector Machine et Ball Vector Machine). Possibilité de normalisation ou non des données.
TR-IRLS (http://autonlab.org/autonweb/10538). Mise à jour de la librairie TR-IRLS pour la régression logistique sur de grandes bases de données, comportant un grand nombre de descripteurs (dernière version disponible - 08/05/2006). Calcul automatique de la déviance, et amélioration de l’affichage des coefficients (plus de décimales). Accès à plusieurs paramètres de l’algorithme d’apprentissage (règles d’arrêt).
FICHIER SPARSE. Importation des fichiers “sparse” (cf. format SVMLight, LibSVM ou LibCVM), extensions .DAT ou .DATA Les données peuvent être relatives à l’apprentissage supervisé ou à la régression. Le format est décrit en ligne (http://c2inet.sce.ntu.edu.sg/ivor/cvm.html).
SÉLECTION DES INDIVIDUS. Un nouveau composant pour la sélection des m premiers individus parmi n dans une branche du diagramme. Cette option est utile lorsque le fichier résulte de la concaténation des échantillons d’apprentissage et de test.
Page de téléchargement : setup
Revolution R Community 5.0
2012-04-30 (Tag:4665761942164980176)
Le logiciel R est en train de bouleverser le panorama des logiciels de statistique et de data mining. Le système des packages est un de ses principaux atouts. Il peut être enrichi à l’infini. Toute méthode statistique est potentiellement disponible dans R.Mais si les packages sont nombreux, rares sont les projets qui cherchent à améliorer le moteur même de R, l’application principale. J’ai découvert récemment les travaux de la société Revolution Analytics. Elle commercialise Revolution R Enterprise qui : améliore très significativement les performances de calculs de R, est capable de traiter les grandes bases de données, et propose un EDI (environnement de développement) évolué avec un débogueur intégré. Cette version étant payante, je n’ai pas pu la tester. En revanche, la société distribue également une version communautaire qui, elle, est en libre accès. Bien évidemment, je me suis précipité dessus pour voir ce qu’il en était.
Revolution R Community est une variante améliorée de R. Elle n’intègre pas les fonctionnalités additionnelles de la version Enterprise. L’effort porte essentiellement sur les performances. Deux aspects sont mis en avant : elle intègre la bibliothèque de calcul mathématique Intel ; elle est capable de titrer profit des processeurs multi-cœurs. Des comparatifs sont accessibles en ligne. Apparemment, le gain est spectaculaire pour les techniques de data mining s’appuyant sur des calculs matriciels.
Dans ce tutoriel, nous étendons le « benchmark » à d’autres méthodes de data mining. Nous étudions les performances de « Revolution R Community 5.0 – 64 bits » : pour la régression logistique (glm) ; l’analyse discriminante (lda du package MASS) ; l’induction des arbres de décision (rpart du package du même nom) ; de l’analyse en composantes principales (ACP) avec deux techniques : celle reposant sur le calcul des valeurs propres (princomp) et celle s’appuyant la décomposition en valeurs singulières (prcomp). Nous utilisons une variante binaire de la base « wave » (Breiman et al., 1984) pour mesurer les temps de calculs.
Mots-clés : logiciel R, script r, revolution analytics, revolution r community, régression logistique, glm, analyse discriminante linéaire, lda, analyse en composantes principales, acp, princomp, prcomp, calcul matriciel, valeurs propres, vecteurs propres, eigen, décomposition en valeurs singulières, svd, arbres de décision, cart, rpart
Lien : fr_Tanagra_Revolution_R_Community.pdf
Fichier : revolution_r_community.zip
Références :
Revolution Analytics, "Revolution R Community".
La proc logistic de SAS 9.3
2012-04-26 (Tag:3384765476175287428)
Un étudiant est venu me voir une fois pour me demander si je comptais décrire l’utilisation de la « proc logistic » de SAS durant mon cours de régression logistique (Master SISE) . Je lui ai dit qu’on utilisait suffisamment d’outils comme ça (R, SPAD, SIPINA, TANAGRA et le tableur EXCEL), je ne voyais pas trop l’intérêt de voir un logiciel supplémentaire. D’autant plus que le plus important finalement est de bien maîtriser la chaîne de traitements, de comprendre la finalité et les implications de chacune des étapes, et de savoir lire les résultats. Qu’importe l’outil, la démarche reste toujours la même. Et puis, tout à fait prosaïquement, les heures ne sont malheureusement pas extensibles à l’infini dans nos Universités. Je lui dis alors que SAS étant disponible dans nos salles informatiques, il ne tenait qu’à lui de s’exercer en récupérant les très nombreux tutoriels accessibles sur internet.Après coup, je suis allé vérifier moi-même sur le web. Et je me suis rendu compte qu’ils ne sont pas si nombreux que ça finalement les tutoriels en français, avec des copies d’écran explicites, montrant de manière simple et didactique la chaîne complète de traitements allant de l’importation de données jusqu’à la récupération des résultats. Je me suis dit qu’il y avait là des choses à faire.
Dans ce tutoriel, nous décrivons l’utilisation de la « proc logistic » de SAS 9.3, sans et avec la sélection de variables. Nous en profiterons pour étudier ses performances (essentiellement la rapidité de calcul) sur une base de grande taille. Nous comparerons les valeurs obtenues avec celles de Tanagra 1.4.43.
Mots-clés : sas, proc logistic, régression logistique
Composants : BINARY LOGISTIC REGRESSION
Lien : fr_Tanagra_SAS_Proc_Logistic.pdf
Fichier : wave_proc_logistic.zip
Références :
SAS - "The LOGISTIC Procedure"
R. Rakotomalala, "Pratique de la régression logistique - Régression logistique binaire et polytomique", Version 2.0, Juin 2011.
Tutoriel Tanagra - "Régression logistique sur les grandes bases"
SAS Add-in 4.3 pour Excel
2012-04-14 (Tag:3163638688842225044)
Le logiciel SAS est bien connu des statisticiens. Il est présent sur le marché des logiciels de statistique depuis un grand nombre d’années maintenant. Il jouit d’une excellente réputation. Son principal défaut, outre le fait qu’il n’est pas accessible gratuitement, est qu’il faut connaître les instructions SAS, et de manière plus générale le langage de macro-commandes, pour pouvoir réellement l’exploiter.SAS propose plusieurs solutions pour dépasser cet écueil. Entres autres, il a développé une macro complémentaire (add-in en anglais) pour la suite Office de Microsoft . Je l’ai découvert très récemment sur les machines des salles informatiques de notre département (Département Informatique et Statistique – Université Lyon 2 – http://dis.univ-lyon2.fr/). Je me suis intéressé en particulier à l’add-in dévolue au tableur Excel. De fait, 3 tâches pas toujours évidentes à mettre en œuvre dans la version standard de SAS sont très largement facilitées : l’importation d’un fichier Excel dans SAS, le paramétrage et le lancement des techniques statistiques, la récupération des résultats dans le tableur aux fins de visualisation ou d’élaboration des rapports.
Dans ce tutoriel, nous décrivons le comportement de la macro complémentaire lors de la mise en œuvre des tests non paramétriques de comparaisons de populations et de la régression logistique avec sélection de variables. Nous mettrons en parallèle les résultats obtenus avec le logiciel Tanagra. L’idée est de comparer les calculs et le mode de présentation des résultats.
Mots-clés : excel, sas, add-on, add-in, macro complémentaire, régression logistique, tests non paramétriques
Composants : MANN-WHITNEY COMPARISON, KRUSKAL-WALLIS 1-WAY ANOVA, MEDIAN TEST, VAN DER WAERDEN 1-WAY ANOVA, ANSARI-BRADLEY SCALE TEST, KLOTZ SCALE TEST, MOOD SCALE TEST
Lien : fr_Tanagra_SAS_AddIn_4_3_for_Excel.pdf
Fichier : scoring_dataset.xls
Références :
SAS - http://www.sas.com/
SAS - "SAS Add-in for Microsoft Office"
Tutoriel Tanagra - "L'add-in Tanagra pour Excel 2007 et 2010"
Tanagra - Version 1.4.43
2012-03-28 (Tag:8848503754047613850)
Quelques bugs ont été corrigés et quelques nouvelles fonctionnalités ajoutées.Le calcul des contributions des individus dans l'ACP (PRINCIPAL COMPONENT ANALYSIS) ont été corrigées. Il était faussé lorsque nous travaillons sur un sous-échantillon de notre fichier de données. Cette erreur m'a été signalée par M. Gilbert Laffond.
La normalisation des facteurs après VARIMAX (FACTOR ROTATION) ont été corrigés de manière à ce que leur variance coïncide avec la somme des carrés des corrélations avec les axes, et donc avec la valeur propre associée à l'axe. Cette modification m'a été suggérée par M. Gilbert Laffond.
Dans le calcul de l'intervalle de confiance bootstrap de la Régression PLS (PLS CONF. INTERVAL), une erreur survenait lorsque le nombre d'axes demandé était supérieur au nombre de variables prédictives. Il est maintenant réduit d'autorité. Cette erreur m'a été signalée par M. Alain Morineau.
Dans certaines circonstances, une erreur peut survenir dans FISHER FILTERING, surtout lorsque Tanagra est exécuté via Wine sous Linux. Le composant a été sécurisé. Cette erreur m'a été signalée par M. Bastien Barchiési.
La vérification des données manquantes durant l'importation est maintenant optionnelle. La performance peut être privilégiée pour le traitement des très gros fichiers. Nous retrouvons les temps de traitement des versions 1.4.41 et précédentes.
Le menu «COMPONENT / COPY RESULTS » envoie des informations au format HTML qui sont maintenant compatibles avec le tableur Calc de la suite bureautique Libre Office (3.5.1). Il fonctionnait déjà avec le tableur Excel auparavant. Curieusement, la copie vers le tableur OOCalc d'Open Office n'est pas possible à l'heure actuelle (Open Office 3.3.0).
Page de téléchargement : setup
Sipina add-on pour OOCalc
2012-03-23 (Tag:8426644695048074271)
La connexion entre les logiciels de data mining et un tableur est primordiale pour la popularité des premiers. Lorsqu’il s’agit de manipuler des bases de taille « raisonnable », avec plusieurs milliers d’observations et quelques dizaines de variables, le tableur est très pratique pour la gestion et le prétraitement des données (transformation, recodage, etc.). A l’issue de l’analyse, il constitue également un outil privilégié pour la mise en forme des résultats. Il n’est pas surprenant dès lors que des éditeurs de logiciels proposent des solutions de couplage fort sous forme de macro complémentaire pour Excel (ex. XLMiner). Particulièrement édifiant, des éditeurs tels que SAS s’y sont mis également. Notons enfin que Microsoft propose son propre add-in pour Excel basé sur le moteur « SQL Server Analysis Services ».Tout ça est très bien. On notera simplement que si les solutions commerciales sont assez répandues pour Excel, les équivalents gratuits sont plutôt rares. Il y a bien sûr SIPINA et TANAGRA dont la macro complémentaire date de 2006 ; il y a RExcel qui permet d’établir connexion entre Excel et R ; à force de chercher sur le net, j’ai réussi à en dénicher d’autres : XL-Statistics ; XL Toolbox ; etc.
Mais Excel lui-même n’est pas gratuit. Heureusement, il existe des alternatives crédibles avec le tableur des suites bureautiques gratuites Open Office et Libre Office. Véritable signe des temps, je constate qu’une bonne partie de mes étudiants préfèrent utiliser ces logiciels plutôt que de s’embarquer dans des copies plus ou moins piratées de la suite MS Office. Ce qui constitue une véritable avancée. D’où la question suivante : existe-t-il des add-on dédiés au calcul statistique qui s’intégreraient dans le tableur libre Calc ? Après quelques recherches, j’ai découvert, entres autres, quelques produits intéressants tels que Statistical Data Analyser for OOCalc, R4Calc. Nous les étudierons de manière approfondie dans un prochain tutoriel.
En ce qui nous concerne, l’add-on Tanagra pour Calc existe depuis 2006. En revanche, je n’ai jamais pris le temps de transposer l’idée à SIPINA alors que, par ailleurs, la macro-complémentaire « sipina.xla » pour Excel existe depuis plusieurs années. Cet oubli est réparé avec la version 3.9 de SIPINA (du 22 mars 2012). Nous montrons dans ce tutoriel l’installation et la mise en œuvre de l’add-on pour Open Office Calc 3.3.0. La transposition à Libre Office 3.5.1 est immédiate.
Mots-clés : calc, open office, libre office, oocalc, add-on, add-in, macro complémentaire, sipina
Lien : fr_sipina_calc_addon.pdf
Fichier : heart.xls
Références :
Tutoriel Tanagra - Connexion Excel - Sipina
Tutoriel Tanagra - Tanagra add-on pour Open Office Calc 3.3
Open Office - http://www.openoffice.org/fr/
Libre Office - http://fr.libreoffice.org/
Sipina - Version 3.9
2012-03-22 (Tag:3830393810682371611)
L'add-on « SipinaLibrary.oxt » a été rajouté à la distribution. A partir d'un menu additionnel intégrée au tableur CALC, il permet de lancer directement le logiciel SIPINA sur une sélection de données. L'add-on fonctionne pour les suites bureautiques Open Office (testée pour la version 3.3.0) et Libre Office (version 3.5.1).Rappelons qu'un add-on, sous forme de macro-complémentaire (sipina.xla), permet également à SIPINA de s'intégrer dans le tableur Excel.
Site web : Sipina
Chargement : Fichier setup
Références :
Tutoriel Tanagra - Connexion Excel - Sipina
Open Office - http://www.openoffice.org/fr/
Libre Office - http://fr.libreoffice.org/
Introduction à R - Arbre de décision
2012-03-14 (Tag:7500496515697106216)
Dans la même veine que le précédent consacré à la régression logistique, ce tutoriel présente l’induction des arbres de décision sous le logiciel R sans entrer dans les arcanes de la programmation. Un minimum est fait sur les structures de données (data.frame, vecteurs, matrices).Finalement, on s’en sort plutôt bien. Il est possible de mener une étude complète avec le peu de choses mises en avant dans ce document : construction d’un modèle sur un échantillon d’apprentissage, prédiction sur un échantillon test, élaboration de la matrice de confusion, calcul du taux de mauvais classement.
Nous utilisons en priorité la procédure rpart du package du même nom. Par la suite, nous montrons qu’il est possible de mener les mêmes analyses avec les procédures incluses dans les packages tree et party.
Ces deux derniers tutoriels récents s’inscrivent dans un de mes cours de data mining où je souhaite faire découvrir le logiciel R aux étudiants sans entrer dans les détails de la programmation sous R.
Mots-clés : logiciel R, arbres de décision, matrice de confusion, taux d’erreur, package xlsx, fichier excel
Lien : introduction_arbre_de_decision_avec_r.pdf
Fichier : intro_arbres_avec_r.zip
Références :
R Project,"The R Project for Statistical Computing"
R. Rakotomalala, « Arbres de décision », Revue Modulad, N°33, 2005.
Introduction à R - Régression logistique
2012-03-09 (Tag:7031019866060685315)
PSPP, une alternative à SPSS
2012-02-25 (Tag:7874539197070319773)
Tout le monde l’aura compris, je passe énormément de temps à analyser les logiciels de statistique et de data mining gratuits découverts ici ou là sur le web. Je suis toujours enthousiasmé à l’idée de découvrir les dispositifs imaginés par les uns et les autres pour proposer aux utilisateurs, nous, des solutions de traitement de données. Au fil des années, j’en suis arrivé à la conclusion qu’il n’existe pas de mauvais logiciels. Il y a simplement des outils plus ou moins adaptés à des contextes d’utilisation qu’il nous appartient de cerner, en tenant compte de nos objectifs, des caractéristiques de nos données, de notre mode opératoire, de nos affinités, etc. On ne gagnera jamais le Paris-Dakar avec une Formule Un ; Sébastien Loeb, aussi fort soit-il, ne peut pas gagner un rallye avec une semi-remorque (j’imagine hein, avec lui on ne sait jamais). C’est l’une des raisons pour lesquelles je parle énormément des autres logiciels, autres que ceux que je développe moi-même. Plus nous en verrons, plus nous saurons nous détacher de l’outil pour nous concentrer sur les finalités, les techniques, l’exploitation des résultats. C’est ce qui importe en définitive.Dans ce tutoriel, nous décrivons le logiciel PSPP. Ses promoteurs la positionnent comme une alternative à SPSS (« PSPP is a program for statistical analysis of sampled data. It is a free replacement for the proprietary program SPSS, and appears very similar to it with a few exceptions. »). Plutôt que de procéder à une analyse exhaustive de ses fonctionnalités, ce qui est déjà très bien fait par ailleurs , avec en particulier le document en français de Julie Séguéla (« Introduction au logiciel PSPP – Version 0.4.0 », 2006 ; 119 pages ), nous préférons décrire quelques procédures statistiques en mettant en miroir les résultats fournis par Tanagra, R 2.13.2 et OpenStat (build 24/02/2012). C’est une manière de les valider mutuellement. Plus que les plantages, les erreurs de calculs sont la hantise des informaticiens. Obtenir des résultats identiques pour les mêmes traitements avec plusieurs logiciels n’est pas un gage d’exactitude. En revanche, en cas de disparités, il y a clairement un problème. L’affaire devient diablement compliquée lorsque ces disparités ne surviennent que dans des situations que l’on a du mal à identifier.
Mots-clés : pspp, logiciel R, openstat, spss, statistiques descriptives, comparaison de moyennes, test de student, welch test, comparaison de variances, test de levene, test du khi-2, tableau de contingence, analyse de variance, anova, régression linéaire multiple, courbe roc, critère auc, aire sous la courbe
Composants : MORE UNIVARIATE CONT STAT, GROUP CHARACTERIZATION, CONTINGENCY CHI-SQUARE, LEVENE'S TEST, T-TEST, T-TEST UNEQUAL VARIANCE, PAIRED T-TEST, ONE-WAY ANOVA, MULTIPLE LINEAR REGRESSION, ROC CURVE
Lien : fr_Tanagra_PSPP.pdf
Fichier : autos_pspp.zip
Références :
GNU PSPP, http://www.gnu.org/software/pspp/
R Project for Statistical Computing, http://www.r-project.org/
OpenStat, http://www.statprograms4u.com/
Tinn-R, un éditeur de code pour R
2012-02-17 (Tag:6664398795572294696)
TINN-R est mon éditeur de code favori pour le logiciel R. Je l’utilise pour mes enseignements. Je me rends compte d’ailleurs que je ne suis pas le seul à l’apprécier. Ça ne veut pas dire qu’il est le meilleur (si tant est qu’il en existe). Je constate tout simplement qu’il présente des qualités intéressantes dans mon contexte : il est simple, léger, facile à manipuler, sans pour autant être limité face aux autres outils accessibles gratuitement. Il convient parfaitement pour la conception de petits scripts « .r ».Dans ce didacticiel, nous décrivons succinctement les principales fonctionnalités de TINN-R. Nous mettrons l’accent sur les erreurs fréquemment rencontrées avec l’outil. Après plusieurs années de pratique, je commence à identifier les différents écueils qui laissent parfois perplexes les utilisateurs. Ce didacticiel ne sera jamais définitif, au fil des années il sera complété au fur et à mesure des problèmes rencontrés et, je l’espère, résolus.
Bien évidemment, pour pouvoir exploiter TINN-R, il faut que le logiciel R lui-même soit déjà installé sur notre machine.
Mots-clés : logiciel R, tinn-r, éditeur de code, EDI
Lien : fr_Tanagra_Tinn_R.pdf
Références :
Site du logiciel Tinn-R ; Site du logiciel R.
R. Rakotomalala, "Cours de programmation R".
KDNuggets Polls, « R GUIs you use frequently », Avril 2011.
Developpez.com, « Quel éditeur utilisez-vous pour R ? », Mars 2010.
Vérification des données manquantes - Tanagra
2012-02-05 (Tag:7098964887815913410)
Jusqu’à la version 1.4.41, Tanagra ne gérait pas les données manquantes parce qu’il me semblait pédagogiquement intéressant que les étudiants, qui constituent quand même le principal public de Tanagra, réfléchissent et traitent explicitement en amont ce problème difficile. Le pire serait de s’en remettre aveuglément au logiciel c.-à-d. de le laisser choisir à notre place un traitement automatique inadapté au cadre de notre étude, aux caractéristiques de nos données, etc. Ainsi, Tanagra se contentait de tronquer le fichier à l’importation dès le premier obstacle rencontré. Ce traitement sans concessions déroutait souvent l’utilisateur, d’autant plus qu’aucun message d’erreur n’était envoyé. Il se demandait alors pourquoi, alors que toutes les conditions semblent réunies, les données n’étaient pas correctement chargées.Avec la nouvelle version 1.4.42, l’importation des fichiers TXT (fichiers textes avec séparateur tabulation), des fichiers XLS (Excel 97-2003), et le transfert des données via les add-in pour Excel (jusqu’à Excel 2010) et LibreOffice 3.4/OpenOffice 3.3, ont été modifiés. Tanagra parcourt bien toutes les lignes de la base. Il se contente simplement de sauter les observations incomplètes et/ou comportant des incohérences (ex. une valeur non numérique pour un attribut initialement détecté quantitatif). Et, surtout, un message d’erreur explicite comptabilise le nombre de lignes ignorées. L’utilisateur est mieux informé. Cette approche très simpliste correspond à la stratégie « listwise deletion » . Ses faiblesses sont largement identifiées . Pour nous, il s’agit surtout d’alerter l’utilisateur sur les problèmes rencontrés lors de la lecture du fichier de données. Libre à lui de poursuivre directement si ce traitement par défaut lui convient. Ce qui n’est pas très conseillé quand même dans la plupart des cas. Les études que nous avons menées pour la régression logistique le montrent bien.
Dans ce tutoriel, nous montrons la gestion des données manquantes lors de l’envoi des données d’Excel vers Tanagra via la macro complémentaire Tanagra.xla. Certaines cellules du fichier Excel sont vides. Cet exemple illustre bien le nouveau comportement de Tanagra. Nous obtiendrions des résultats identiques si nous importions directement le fichier XLS ou si nous importions le fichier au format TXT correspondant.
Mots clés : données manquantes, données incohérentes, missing data, missing values, importation des fichiers textes, excel, macro complémentaire, tanagra.xla
Composants : DATASET, VIEW DATASET
Lien : fr_Tanagra_Missing_Data_Checking.pdf
Fichier : ronflement_with_missing_empty.zip
Références :
Wikipedia, "Listwise deletion".
Tanagra - Version 1.4.42
2012-02-04 (Tag:8742739977900775300)
La macro complémentaire Tanagra.xla est maintenant compatible avec les versions 64 bits d’Excel (en plus des versions 32 bits gérées auparavant).Avec le gestionnaire de mémoire FastMM, Tanagra peut adresser 3 Go de RAM sur les versions 32 bits de Windows, et 4 Go sur les versions 64 bits. La capacité à traiter des très grands fichiers est largement améliorée.
L’importation des fichiers texte (séparateur tabulation) et xls (Excel 97-2003) a été sécurisée. Auparavant, lorsqu’une ligne invalide était rencontrée (valeur manquante ou incohérente), le chargement était interrompu et les données tronquées. Maintenant, Tanagra saute la ligne incriminée et poursuit le chargement pour les observations restantes. Le nombre de lignes ignorées sont indiquées dans le rapport d’importation.
Page de téléchargement : setup
Régression logistique sur les grandes bases
2012-01-26 (Tag:3863774136355773432)
Gratter les millisecondes est le péché mignon des informaticiens. Au-delà de la petite satisfaction personnelle, il y a quand même des enjeux forts derrière l’optimisation des programmes. Notre rôle est de produire des logiciels fiables, rapides, avec une occupation mémoire contenue. Dans le cadre du data mining, cela se traduit par la capacité à traiter les grandes bases de données. Certes, dans la phase finale où il s’agit de produire le modèle qui sera déployé dans le système d’information, qu’importe finalement que les calculs durent une 1/2 heure ou une 1/2 journée. Mais il y a la phase exploratoire en amont, lorsque nous cherchons les solutions les mieux adaptées à notre problème. Plus rapide sera l’outil, plus de configurations nous pourrons tester. Nous aurons ainsi de meilleures chances de mettre en évidence la solution la plus efficace.Il m’est apparu intéressant de comparer les temps de traitement et l’occupation mémoire de la régression logistique de Tanagra avec ceux des autres outils gratuits largement répandus au sein de la communauté du Data Mining. J’avais déjà mené un travail similaire par le passé. La nouveauté dans ce tutoriel est que nous nous situons dans un nouveau cadre : j’utilise maintenant un OS 64 bits (Windows 7), et certains de ces logiciels sont justement passés aux 64 bits avec des capacités de traitements accrus comme on a pu le constater pour les algorithmes de construction des arbres de décision . J’ai donc largement augmenté la taille de la base à traiter (300.000 observations et 121 variables prédictives). Pour corser l’affaire, des attributs générés complètement aléatoirement ou de manière à être corrélés avec les variables initiales ont été rajoutées. L’objectif est d’observer le comportement des logiciels durant la recherche des prédicteurs pertinents.
Dans ce comparatif, outre Tanagra 1.4.41 (32 bits), nous utiliserons les logiciels R 2.13.2 (64 bits), Knime 2.4.2 (64 bits), Orange 2.0b (build 15 oct 2011, 32 bits) et Weka 3.7.5 (64 bits).
Mots clés : régression logistique, grands fichiers, grandes bases, gros volumes, comparaison de logiciels, glm, stepAIC, logiciel R, knime, orange, weka
Composants : BINARY LOGISTIC REGRESSION, FORWARD LOGIT
Lien : fr_Tanagra_Perfs_Bis_Logistic_Reg.pdf
Fichier : perfs_bis_logistic_reg.zip
Références :
R. Rakotomalala, "Pratique de la régression logistique - Régression logistique binaire et polytomique", Version 2.0, Juin 2011.
Tutoriel Tanagra, "Régression logistique - Comparaison de logiciels".
Sipina - Version 3.8
2012-01-18 (Tag:4450655076092716061)
Les logiciels (SIPINA RESEARCH, REGRESS et ASSOCATION RULE SOFTWARE) associés à la distribution SIPINA ont été mis à jour avec quelques améliorations.SIPINA.XLA. La macro complémentaire fonctionne indifféremment avec les versions 32 et 64 bits d’Excel (testée jusqu’à Excel 2010).
Importation des fichiers textes. Le temps de traitement a été amélioré. Cette modification joue également sur le temps de transfert durant l’envoi des données d’Excel vers les logiciels via la macro-complémentaire (qui utilise un fichier temporaire au format texte).
Association rule software. L’interface a été simplifiée, l’affichage des règles est rendue plus lisible.
S'appuyant sur le gestionnaire de mémoire FastMM, ces 3 logiciels peuvent adresser jusqu'à 3 Go sous Windows 32 bits et 4 Go sous Windows 64 bits. Les capacités de traitement sont améliorées.
Site web : Sipina
Chargement : Fichier setup
Références :
Tutoriel Tanagra - Connexion Excel - Sipina
Delphi Programming Resource - FastMM, a Fast Memory Manager
Arbres de décision sur les grandes bases (suite)
2012-01-10 (Tag:1583834591583320128)
S’endormir sur ses lauriers est impossible en informatique. Tout évolue très vite : matériel, système, logiciel. C’est un de ses principaux attraits d’ailleurs. La vérité d’aujourd’hui n’est pas celle d’hier, elle sera peut être différente demain, il faut être sur le qui-vive. Ayant changé de système, je suis passé à Windows 7 en 64 bits (avec un Quad Core Q9400 à 2.66 Ghz), j’étais curieux de voir le nouveau comportement des outils analysés dans un ancien document dont l'objet était l'analyse comparative des performances des différents logiciels de data mining durant l'apprentissage d'un arbre de décision. Surtout que plusieurs de ces outils sont passés à une version 64 bits (Knime, RapidMiner, R).J’ai donc reproduit la même analyse avec les mêmes données et mesuré les mêmes critères : temps de traitement et occupation mémoire. J’ai constaté que la grande majorité des outils ont bien progréssé en termes de temps de traitement, à des degrés divers néanmoins. En revanche, les évolutions ne sont pas manifestes concernant l’occupation mémoire. Nous détaillons tout cela dans la dernière section de cette nouvelle version de notre tutoriel.
Mots clés : c4.5, arbres de décision, grandes bases de données, comparaison de logiciels, knime2.4.2, orange 2.0b, r 2.13.2, rapidminer 5.1.011, sipina 3.7, tanagra 1.4.41, weka 3.7.4, windows 7 - 64 bits
Composants : SUPERVISED LEARNING, C4.5
Lien : fr_Tanagra_Perfs_Comp_Decision_Tree_Suite.pdf
Lien (2) : Copies d'écran avec les versions des logiciels utilisées dans cette mise à jour.
Données : wave500k.zip
Références :
Tanagra, "Traitement de gros volumes - Comparaison de logiciels".
Tanagra, "Arbres de décision sur les grands fichiers (mise à jour)".
R. Quinlan, « C4.5 : Programs for Machine Learning », Morgan Kaufman, 1993.
Arbres sur les " très" grandes bases (suite)
2012-01-10 (Tag:4791357352784556020)
Triturer des très grands fichiers était de fantasme ultime du data miner a-t-on coutume de dire. Etant passé récemment à un système 64 bits (mieux vaut tard que jamais), je me propose d’étudier le comportement des outils spécifiquement dédiés à ce système, principalement Knime 2.4.2 et RapidMiner 5.1.011.Ce document vient compléter une étude récente où nous traitions une base moyennement volumineuse avec 500.000 observations et 22 variables. Nous poussons le curseur un peu plus loin en reprenant un tutoriel où le fichier à traiter comportait 9.634.198 observations et 41 variables, (quasiment) impossible à faire tenir en mémoire sur un système 32 bits. L’idée était alors de montrer qu’un système de swap adapté aux algorithmes d’apprentissage, l’induction d’un arbre de décision en l’occurrence, permettait d’appréhender de très grandes bases avec des temps de traitement raisonnables. La procédure avait été implémentée dans Sipina.
Dans ce tutoriel, nous constatons que le passage aux 64 bits augmente considérablement les capacités de calcul des logiciels de Data Mining. C’est indéniable. Mais il faut disposer d’une machine à l’avenant pour en tirer réellement parti.
Mots clés : gros volumes, très grands fichiers, grandes bases de données, arbre de décision, échantillonnage, sipina, knime, rapidminer, windows 7 - 64 bits
Composants : ID3
Lien : fr_Tanagra_Tree_Very_Large_Dataset.pdf
Données : twice-kdd-cup-discretized-descriptors.zip
Références :
Tutoriel Tanagra, « Arbres de décision sur les grandes bases (suite) ».
Tutoriel Tanagra, « Sipina - Traitement des très grands fichiers »
Bonne année 2012 - Bilan 2011
2012-01-02 (Tag:1956636285136031252)
L'année 2011 s'achève, 2012 commence. Je vous souhaite à tous une belle et heureuse année 2012.Un petit bilan chiffré concernant l'activité organisée autour de Tanagra pour l' année écoulée. L'ensemble des sites (logiciel, support de cours, ouvrages, tutoriels) a été visité 281.352 fois cette année, soit 770 visites par jour. Par comparaison, nous avions 349 visites journalières en 2008, 520 en 2009 et 662 en 2010.
Qui êtes-vous ? La majorité des visites viennent de France et du Maghreb. Puis viennent les autres pays francophones, une grande partie vient d'Afrique. Pour ce qui est des pays non francophones, nous observons parmi ceux qui reviennent souvent : les États-Unis, l'Inde, le Royaume Uni, l'Italie, le Brésil, l'Allemagne, etc.
Que consultez-vous en priorité ? Les pages qui ont le plus de succès sont celles qui se rapportent à la documentation sur le Data Mining : les supports de cours, les tutoriels, les liens vers les autres documents accessibles en ligne, etc. Ce n'est guère étonnant. Au fil des années, plus que la programmation et la promotion de Tanagra, je passe de plus en plus de temps moi-même à écrire des fascicules de cours et des tutoriels, à étudier le comportement des différents logiciels. Je constate d'ailleurs que ma page consacrée à la Programmation R fait une percée dans le top 10.
Encore Bonne Année 2012 à tous. Que chacun puisse mener à bien les projets qui leur sont les plus précieux.
Ricco.
Diaporama : Tanagra - Bilan 2011
Connexion entre R et Excel via RExcel
2011-12-30 (Tag:2306590969994601593)
Le couplage entre un logiciel spécialisé de data mining et un tableur est un argument certain pour la praticabilité du premier. Quasiment tout le monde sait manipuler un tableur, ne serait-ce que pour ouvrir un fichier de données et en visualiser le contenu. De même, les opérations de vérification, les calculs statistiques simples, les transformations de données, sont très facilement réalisables dans un tableur. D’ailleurs, un signe qui ne trompe pas, outre les enquêtes du site KDNUGGETS qui montre la popularité d’Excel auprès des data miners, tous les logiciels dignes de ce nom savent importer directement les fichiers au format Excel.Très récemment, un étudiant me demandait s’il était possible de réaliser des échanges de données à la volée entre R et Excel. L’enjeu n’est pas tant l’importation des données au format Excel, des packages s’en chargent très bien (le package xlsx par exemple), mais de disposer des fonctionnalités simplifiées de transfert entre Excel et R, que ce soit pour les data frame (ensemble de données) ou, plus généralement, pour tout vecteur et matrice de données. En cherchant un peu, très rapidement, la réponse a été oui. RExcel répond exactement à ce cahier des charges. En y regardant de plus près, je me suis même rendu compte que la solution proposée est de très grande qualité et va nettement au-delà du simple échange de vecteurs de valeurs.
Nous présentons donc la bibliothèque RExcel dans ce tutoriel. Nous nous contenterons de décrire le transfert des données. Nous ferrons un très rapide tour d’horizon des autres fonctionnalités dans la conclusion.
Mots clés : importation des données, fichier excel, xls, xlsx, connexion, macro complémentaire, addin, add-in, add-on, régression linéaire multiple, logiciel R
Composants : lm, stepAIC, predict
Lien : fr_Tanagra_RExcel.pdf
Données : ventes_regression_rexcel.zip
Références :
T. Baier, E. Neuwirth, "Powerful data analysis from inside your favorite application"
L'add-in Tanagra pour Excel 2010 - 64 bits
2011-12-27 (Tag:6467006628321950945)
La macro complémentaire « Tanagra.xla » actuelle fonctionne pour les versions 32 bits d’Excel (jusqu’à Excel 2010). Quelle que soit la version de Windows, y compris les versions 64 bits de Windows (ma configuration actuelle est un Windows 7 version 64 bits, version française).Elle ne fonctionne pas en revanche lorsqu’il s’agit de lancer de connecter Tanagra avec la version 64 bits d’Excel 2010. Il faut la modifier. Dans ce didacticiel, nous montrons la procédure à suivre.
Attention, les copies d’écran ont été réalisées à l’aide d’Excel 2007, néanmoins les menus devraient être à peu près les mêmes sous Excel 2010.
Un grand merci à Mme Nathalie Jourdan-Salloum de m’avoir signalé le problème et de m’avoir indiqué la solution.
Mots clés : importation des données, fichier excel, macro-complémentaire, add-in, addin, add-on, xls, xlsx
Lien : fr_Tanagra_Addin_Excel_64_bit.pdf
Références :
Tanagra, "L'add-in Tanagra pour Excel 2007 et 2010".
Tanagra, "Importation fichier XLS (Excel) - Macro complémentaire".
Données manquantes en déploiement
2011-12-24 (Tag:1508484756322221636)
Le traitement des valeurs manquantes est un problème difficile, maintes fois étudié lorsqu’il s’agit d’analyser son impact sur les caractéristiques du modèle prédictif élaboré à partir des données d’apprentissage. Nous avons mené une expérimentation récemment. Il s’agissait de comparer les mérites respectifs des différentes approches (suppression de lignes ou imputation) sur les performances de la régression logistique.Mais qu’en est-il lors du déploiement d’un modèle ? Curieusement, les écrits sont rares, voire très rares sur le sujet. Pourtant le problème est d’importance. Imaginons une situation concrète. Nous avons construit un super modèle à l’aide de la régression logistique. Nous l’intégrons dans notre système d’information. Une fiche client arrive, nous souhaitons le scorer pour connaître son appétence à un nouveau produit. Et là, patatras, la personne n’a pas mentionné son salaire dans sa fiche. Or, cette variable figure dans votre équation. Que faire ?
Dans ce tutoriel, nous supposons que le modèle prédictif a été construit selon un processus classique. La question des données manquantes n’est pas posée pour l’apprentissage. En revanche, elle est posée lors du déploiement. Nous souhaitons classer des individus dont la description est incomplète. Nous comparerons alors deux approches de substitution – l’une univariée, l’autre multivariée – de valeurs manquantes pour le déploiement. Nous montons une expérimentation sous R pour évaluer empiriquement leurs performances respectives sur plusieurs bases de données benchmark bien connues de la communauté du Data Mining.
Nous nous plaçons dans un cadre spécifique dans ce tutoriel : le modèle prédictif est issu de la régression logistique ; toutes les variables prédictives sont quantitatives ; la probabilité d'apparition d'une valeur manquante est la même pour toutes les variables décrivant l'individu à traiter.
Mots clés : données manquante, données manquantes, déploiement, classement, régression logistique, logiciel r, glm, lm, NA
Composants : Binary Logistic Regression
Lien : fr_Tanagra_Missing_Values_Deployment.pdf
Données et script R : md_logistic_reg_deployment.zip
Références :
Howell, D.C., "Treatment of Missing Data".
M. Saar-Tsechansky, F. Provost, “Handling Missing Values when Applying Classification Models”, JMLR, 8, pp. 1625-1657, 2007.
Données manquantes - Régression logistique
2011-12-03 (Tag:5486528756091734604)
L’appréhension des données manquantes est un problème difficile. Non pas à cause de sa gestion informatique qui est relativement simple, il suffit de signaler les valeurs manquantes par un code spécifique, mais plutôt à cause des conséquences de leur traitement (suppression des lignes ou des colonnes du fichier ; ou remplacement par une valeur calculée à partir de observations disponibles, on parle alors d’imputation) sur les caractéristiques des modèles élaborés.Nous en avions parlé dans un précédent document. Il s’agissait alors d’étudier l’impact des différentes techniques de traitement de valeurs manquantes sur les arbres de décision construits avec la méthode C4.5 (Quinlan, 1993) dans le logiciel Sipina. Aujourd’hui, nous réitérons l’analyse en étudiant leur influence sur les résultats de la régression logistique. Nous utiliserons principalement le logiciel R 2.13.2, avec la procédure glm(.). Par la suite, nous examinerons le comportement des outils proposés dans des logiciels tels qu’Orange 2.0b, Knime 2.4.2 et RapidMiner 5.1 placés dans un contexte identique.
Nous nous plaçons dans la configuration suivante dans ce tutoriel : (1) les valeurs manquantes sont MCAR, nous avons écrit un programme qui retire de manière complètement aléatoire les valeurs dans l’échantillon d’apprentissage ; (2) nous appliquons la régression logistique sur les données d’apprentissage post-traitées ; (3) nous évaluons les différentes techniques de traitement des données manquantes en observant le taux de bon classement (ou taux de succès) du modèle sur un échantillon test à part qui, lui, ne comporte aucune valeur manquante.
Mots clés : donnée manquante, données manquantes, valeurs manquantes, régression logistique, listwise deletion, imputation, missing values, missing data, logiciel R, glm
Lien : fr_Tanagra_Missing_Values_Imputation.pdf
Données et script R : md_experiments.zip
Références :
Howell, D.C., "Treatment of Missing Data".
Allison, P.D. (2001), « Missing Data ». Sage University Papers Series on Quantitative Applications in the Social Sciences, 07-136. Thousand Oaks, CA : Sage.
Little, R.J.A., Rubin, D.B. (2002), « Statistical Analysis with Missing Data », 2nd Edition, New York : John Wiley.
Extraction des itemsets fréquents
2011-10-03 (Tag:1911930121280889267)
La recherche des régularités dans les bases de données est l'idée principale du data mining. Ces régularités s'expriment sous différentes formes. Dans l'analyse du panier d'achats de consommateurs, l'extraction des itemsets consiste à mettre en exergue les cooccurrences entres les produits achetés c.-à-d. déterminer les produits (les items) qui sont " souvent " achetés simultanément. On parle alors d'itemsets fréquents. Par exemple, en analysant les tickets de caisse d'un supermarché, on pourrait produire des itemsets (un ensemble d'items) du type " le pain et le lait sont présents dans 10% des caddies ".La recherche des itemsets fréquents est souvent présentée comme un préalable à l'extraction des règles d'association où l'on essaie, en sus, de mettre en évidence des relations de causalité. En reprenant notre exemple ci-dessus, une règle possible serait " ceux qui ont acheté du pain et du lait ont aussi acheté du beurre ". L'objectif est d'exploiter ce type de connaissance pour mieux agencer les rayons (mettre le beurre pas trop loin du pain et du lait) ou pour faire une offre promotionnelle ciblée (faire une promotion sur le pain et le lait dans le but d'augmenter les ventes de beurre).
En réalité, les itemsets fréquents sont en elles-mêmes porteuses d'informations. Savoir quels sont les produits achetés ensembles permet d'identifier les liens existants entre eux et, par là, de réaliser une typologie des achats ou de dégager des comportements types chez les consommateurs. Dans le cas du pain et du lait, il s'agit certainement d'achats relatifs au petit déjeuner. Si les consommateurs se mettent à acheter conjointement de la viande et du charbon, nous sommes en été, c'est la saison des barbecues…
Dans ce tutoriel, nous décrivons la mise en œuvre du composant FREQUENT ITEMSETS de Tanagra, basé sur la bibliothèque " apriori.exe " de Borgelt. Nous utilisons un petit jeu de données pour que tout un chacun puisse reconstituer manuellement les résultats produits par le logiciel. Ils (les résultats) seront mis en parallèle avec ceux fournis par le package arules du logiciel R basée sur la même bibliothèque. Mais, dans un premier temps, essayons d'expliciter les différentes notions liées à l'extraction des itemsets.
Mots clés : itemsets fréquents, itemsets fermés, itemsets maximaux, itemsets générateurs, règles d’association, logiciel R, package arules
Composants : FREQUENT ITEMSETS
Lien : fr_Tanagra_Itemset_Mining.pdf
Données : itemset_mining.zip
Références :
C. Borgelt, "A priori - Association Rule Induction / Frequent Item Set Mining"
R. Lovin, "Mining Frequent Patterns"
Mise à jour de A PRIORI PT
2011-09-25 (Tag:7761634091519351806)
A PRIORI PT est un des rares composants de Tanagra basé sur une bibliothèque externe, le programme " apriori.exe " de Borgelt en l'occurrence . Jusqu'à la version 1.4.40 de Tanagra, nous utilisions la version 4.31 de l'exécutable (du 12/03/2007). Nous introduisons une version autrement plus récente (5.57 du 02/09/2011) dans Tanagra 1.4.41. Les paramètres étant légèrement modifiés, il a fallu adapter le programme appelant. Néanmoins, le fonctionnement reste identique, il en est de même en ce qui concerne la lecture des résultats.Nous reprenons un ancien tutoriel pour décrire le comportement de cette nouvelle mouture. Nous ne revenons pas sur le détail (importation des données, choix des variables, paramétrage) de l'utilisation du composant APRIORI PT, puisque cela a déjà été fait. Nous essayons surtout de mettre en évidence les progrès du module en termes de temps de traitements. Force est de constater qu'ils sont particulièrement impressionnants.
Mots clés : règles d’association, traitement de grandes bases
Composants : A PRIORI PT
Lien : fr_Tanagra_AprioriPT_Updated.pdf
Données : assoc_census.zip
Références :
Tutoriel Tanagra, "Règles d'association avec APRIORI PT"
C. Borgelt, "A priori - Association Rule Induction / Frequent Item Set Mining"
Tutoriel Tanagra, « Les règles d’association – A priori »
Tanagra - Version 1.4.41
2011-09-22 (Tag:1317430217965053043)
Nouveautés de cette version.A PRIORI PT. Ce composant génère des règles d'association. Il est basé sur le programme apriori.exe de Borgelt qui a été mis à jour. Il s'appuie maintenant sur la version 5.57 du 02/09/2011. Le progrès de cette nouvelle mouture, en termes de temps de calcul, est impressionnant.
FREQUENT ITEMSETS. Egalement basé sur le programme apriori.exe de Borgelt (version 5.57), ce composant génère les itemsets fréquents, fermés, maximaux, ou générateurs.
Des tutoriels viendront bientôt décrire le fonctionnement de ces nouveaux outils.
Page de téléchargement : setup
Tanagra add-on pour OpenOffice Calc 3.3
2011-07-16 (Tag:1370367100099593725)
Tanagra add-on pour OpenOffice 3.3 et LibreOffice 3.4.La connexion avec les tableurs est certainement un des facteurs de large diffusion de Tanagra. Il est facile de manipuler ses données à son aise dans le tableur OpenOffice Calc (jusqu'à la version 3.2) et de l'envoyer vers Tanagra via l'addon "TanagraLibrary.zip".
Récemment, des internautes m'ont signalé que le mécanisme ne fonctionnait plus avec les versions récentes d'OpenOffice (version 3.3), et de son dérivé LibreOffice (version 3.4). En me penchant sur la question, je me suis rendu compte que, plutôt qu'une simple correction, il était plus approprié de produire un module respectant la nouvelle norme de gestion des extensions de ces outils. La bibliothèque "TanagraModule.oxt" a dont été créée.
Ce tutoriel vise à documenter son installation et sa mise en œuvre sous OpenOffice Calc 3.3. La transposition à LibreOffice 3.4 est immédiate.
Mots clés : importation des données, tableur, openoffice, libreoffice, add-in, addon, excel
Composant : View Dataset
Lien : fr_Tanagra_Addon_OpenOffice_LibreOffice.pdf
Données : breast.ods
Références :
Tutoriel Tanagra, "Connexion Open Office Calc"
Tutoriel Tanagra, "Connexion Open Office Calc sous Linux"
Tanagra - Version 1.4.40
2011-07-05 (Tag:3275218600450942722)
Quelques améliorations pour cette nouvelle version.L'addon de connexion avec le tableur Open Office Calc a été renouvelé. Il ne fonctionnait plus pour les versions récentes (Open Office 3.3 et LibreOffice 3.4). Une autre librairie a été rajoutée ("TanagraModule.oxt") pour ne pas interférer avec l'ancienne, toujours fonctionnelle pour les versions précédentes d'Open Office (3.2 et antérieures). Un tutoriel décrivant son installation sera mis en ligne bientôt. Je profite de cette mise à jour pour redire à quel point la liaison entre un tableur et un outil spécialisé de Data Mining est profitable. Les professionnels, les praticiens, ceux qui s'attaquent à des vrais problèmes avec des vraies données, connaissent l'importance du tableur dans la pratique journalière des statistiques et du data mining. Le sondage annuel organisé par le site kdnuggets.com le montre suffisamment (2011, 2010, 2009, ...). Il faut simplement savoir en circonscrire les limites en fonction de ses objectifs et de son contexte. Et comme outil pédagogique, le tableur est ce qui se fait de mieux pour comprendre les techniques. Les modifications m'ont été suggérées par Jérémy Roos (OpenOffice) et Franck Thomas (LibreOffice).
Notons qu'un addon similaire existe pour le logiciel R (R4Calc).
L'ACP non normée est maintenant disponible. Il est possible de la mettre en œuvre en désactivant l'option de standardisation des données dans le composant Principal Component Analysis. Modification suggérée par Elvire Antanjan.
La régression simultanée (régressions croisées) a été introduite. Inspirée sur logiciel LazStats qui n'est malheureusement plus accessible librement aujourd'hui. La technique est décrite dans notre fascicule accessible en ligne "Pratique de la régression linéaire - Diagnostic et sélection de variables" (section 3.6).
Les codes couleurs selon les p-value (probabilités critiques) ont été implémentées pour le composant Linear Correlation. Modification suggérée par Samuel KL.
Encore une fois, merci infiniment à toutes les personnes qui par leurs commentaires et leurs indications me permettent d'améliorer Tanagra.
Page de téléchargement : setup
Pratique de la Régression Linéaire (version 2)
2011-06-22 (Tag:5068876761400410967)
Le fascicule consacré à la pratique de la régression linéaire a été mis à jour. Cette nouvelle version se distingue (et celles qui suivront) par les graphiques en couleur (hé oui, on en apprend à tout âge...).Plus sérieusement, un chapitre a été ajouté, d'autres ont été complétés. Je distinguerais volontiers :
Chapitre 3 - Colinéarité et sélection de variables. Deux sections ont été ajoutées : régressions partielles, régressions croisées.
Chapitre 4 - Régression sur des exogènes qualitatives. Ce chapitre a été profondément remanié. Je confesse avoir été énormément influencé par la lecture de l'extraordinaire ouvrage de M.A. Hardy, " Regression with dummy variables " (cf. bibliographie). Mon travail a surtout consisté à reprendre les parties qui me paraissaient les plus intéressantes de l'ouvrage, en l'inscrivant dans mon propre canevas de présentation et en utilisant mes propres exemples. Le fichier LOYER, entres autres, est mis à toutes les sauces dans ce chapitre.
Chapitre 6 - Détection et traitement de la non linéarité. Ce chapitre fait écho à une première approche de la non-linéarité concernant la régression simple développé dans le premier volume sur la régression (chapitre 6 aussi, c'est une coïncidence). Des approches plus génériques sont mises en avant dans ce document, dans un premier temps pour la régression simple, dans un second temps pour la régression multiple. Ce chapitre doit beaucoup à l'extraordinaire ouvrage de Aïvazian (cf. bibliographie). Je l'ai depuis plus de 20 ans. A chaque que je l'ouvre, je (re)découvre des choses intéressantes. Je l'ai également beaucoup mis à contribution pour mon fascicule consacré à la corrélation.
Mots-clés : régression linéaire simple et multiple, étude des résidus, points aberrants et points influents, colinéarité et sélection de variables, variables exogènes qualitatives, rupture de structure, non-linéarité
Techniques décrites : test de durbin-watson, test des séquences, qraphique qq-plot, test de symétrie des résidus, test de jarque-bera, résidu standardisé, résidu studentisé, dffits, distance de cook, dfbetas, covratio, sélection forward, backward, stepwise, codage centerd effect, codage cornered effect, codage contrastes, test de chow, test de non-linéarité
Ouvrage : Pratique de la régression linéaire multiple – Diagnostic et sélection de variables
Fichiers : fichiers_pratique_regression.zip
Tanagra - Version 1.4.39
2011-05-26 (Tag:8091611081247121748)
Quelques corrections mineures pour la version 1.4.39 de Tanagra.Pour le composant PCA (Analyse en Composantes Principales), lorsque l'utilisateur demande explicitement tous les axes factoriels, Tanagra n'en génère aucun. Signalée par Jérémy Roos.
La régression logistique multinomiale (Multinomial Logistic Regression) implémentée dans la version précédente plante. Il n'était pas possible notamment de reproduire le tutoriel qui était en ligne. Signalée par Nicole Jurado.
Il n'était pas possible de calculer les scores avec le composant PLS-DA (Régression PLS - Analyse discriminante) c.-à-d. mettre le composant SCORING à la suite de PLS-DA. Signalée par Carlos Serrano.
Toutes ces erreurs ont été corrigées dans cette version 1.4.39. Je ne le répéterai jamais assez. Merci infiniment à toutes les personnes qui par leurs commentaires et leurs indications me permettent d'améliorer Tanagra.
Page de téléchargement : setup
Régression avec le logiciel LazStats (OpenStat)
2011-05-25 (Tag:2853294083956444210)
LazStats est un logiciel de statistique programmé et diffusé par Bill Miller, le père du logiciel OpenStat, très connu des statisticiens depuis un certain nombre d'années. Ce sont des outils de très grande qualité, avec une rigueur de calcul appréciable. OpenStat fait partie des logiciels de statistique que je privilégie lorsque je souhaite valider mes propres implémentations.Le logiciel LazStats, qui est une émanation de la première version en Delphi de OpenStat, est de très bonne facture si j'en juge sa stabilité face aux multiples tests que j'ai pu effectuer. J'ai choisi de présenter la version Windows parce que j'ai l'habitude de travailler sous cet environnement. Une version Linux est accessible sur le site de diffusion pour ceux qui le désirent. Il est également possible de télécharger des versions pour Mac OSX et Linux 64 bits.
L'autre véritable évolution ces dernières années est la mise à disposition d'une documentation de plus en plus riche sur le site web d'OpenStat. Un ouvrage décrit les méthodes statistiques, des tutoriels rédigés décrivent leur mise en œuvre et, pour enfoncer le clou, des tutoriels animés (fichiers .wmv) montrent les séquences de manipulations à réaliser pour mener les analyses. Le travail accompli est vraiment remarquable. Je m'y réfère souvent pour situer ce que je fais moi-même.
Dans ce tutoriel, nous décrivons les fonctionnalités de LazStats en matière de régression linéaire multiple.
Mots clés : économétrie, régression linéaire simple, régression linéaire multiple, sélection de variables, forward, backward, stepwise, régressions croisées
Lien : fr_Tanagra_Regression_LazStats.pdf
Données : conso_vehicules_lazstats.txt (attention au point décimal !)
Références :
LazStats - http://www.statprograms4u.com/
REGRESS dans la distribution SIPINA
2011-05-14 (Tag:3536232572318674476)
Peu de personnes le savent. En réalité, plusieurs logiciels sont installés lorsque l'on récupère et que l'on exécute le SETUP de SIPINA (setup_stat_package.exe). Je n'en parle pas beaucoup parce que les autres techniques proposées (Régression Linéaire Multiple et Règles d'Association) sont déjà intégrées dans TANAGRA qui est très largement diffusé.Pourquoi en parler aujourd'hui alors ? Tout simplement parce que, concernant REGRESS en tous les cas, je me suis rendu compte en préparant le fascicule de cours consacré à la régression linéaire simple et multiple (Econométrie - Régression Linéaire Simple et Multiple), que le relatif manque de puissance du logiciel - par rapport à TANAGRA - est largement compensé par une grande facilité d'utilisation. Pour les utilisateurs qui souhaitent manipuler un outil simple, sans fioritures, REGRESS peut encore rendre de grands services.
REGRESS a été recompilé en introduisant deux améliorations : il peut s'intégrer dans le tableur Excel via une macro-complémentaire maintenant, la même que celle de SIPINA (SIPINA.XLA), cela accroît grandement sa facilité d'utilisation ; j'ai revérifié les formules pour qu'elles soient complètement cohérentes avec celles obtenues par tableur décrites dans mes fascicules de cours.
Mots clés : logiciel regress, économétrie, régression linéaire simple, régression linéaire multiple, points aberrants, points atypiques, points influents, normalité des résidus, test de Jarque-Bera, droite de Henry, normal probability plot, q-q plot, macro complémentaire, sipina.xla, add-in
Lien : fr_sipina_regress.pdf
Données : ventes-regression.xls
Références :
R. Rakotomalala, "Econométrie - Régression Linéaire Simple et Multiple".
Régression linéaire simple et multiple
2011-05-10 (Tag:5140793150212189361)
Ce document décrit les principes et techniques de la régression linéaire simple et multiple. Décomposé en deux parties : régression simple puis régression multiple, il aborde tous les points importants de la modélisation statistique. Les concepts sont explicités à l'aide d'exemples traités sur tableur. Tous les calculs sont très largement détaillés. Les fichiers associés sont accessibles en ligne.Il correspond à un enseignement d'économétrie de niveau licence (L3). Il est d'ailleurs associé au cours que je dispense aux étudiants de la Licence IDS (Informatique décisionnelle et statistique) du Département Informatique et Statistique de l'Université Lyon 2 (http://dis.univ-lyon2.fr).
Il vient en complément du fascicule consacré à la " Pratique de la régression linéaire multiple " accessible en ligne depuis quelque temps déjà (dans l'agencement du cours, il le précède plutôt).
Enfin, la mise en œuvre et la lecture des résultats de la régression sur des logiciels de data mining et de statistique sont décrites dans un chapitre dédié (tanagra, logiciel r, sas, spad, spss, statistica).
Mots-clés : économétrie, régression linéaire simple, régression linéaire multiple, droitereg
Thèmes abordés : principes de la régression, estimation / estimateur des moindres carrés ordinaires, tableau d'analyse de variance, coefficient de détermination, test de significativité globale de la régression, test de significativité individuelle des coefficients, test de significativité d'un bloc de coefficients, intervalle de confiance des coefficients, test de conformité à un standard des coefficients, prédiction ponctuelle, prédiction par intervalle, comparaison des paramètres des régressions dans différentes sous-populations
Ouvrage : econometrie_regression.pdf
Fichiers : econometrie_regression_fichiers.zip
Classifieur Bayesien Naïf - Diaporama
2011-03-31 (Tag:9107433993075068317)
Le classifieur bayesien naïf (le modèle d'indépendance conditionnelle) est très populaire en recherche (text mining, etc.), mais peu utilisée par les praticiens du data mining en entreprise (études marketing). Pourtant, la technique cumule les qualités : incrémentalité, capacité à traiter de très grandes bases (tant en nombre de lignes que de colonnes), simplicité des calculs (ce qui fait peut être son succès auprès des informaticiens), performances comparables aux autres techniques supervisées. Une des raisons de cette défection est qu'elle est mal comprise. Beaucoup pensent qu'il n'est pas possible d'en déduire un modèle explicite facile à déployer. Quand on regarde ce que propose le standard PMML pour son intégration dans les systèmes d'information, on peut effectivement s'interroger sur son intérêt. Ajouté à cela, l'interprétation des résultats qui est inhérente à toute étude, c.-à-d. l'analyse de la relation de chaque prédicteur avec la variable cible, semble bien compromise également.Pourtant, à bien y regarder, on se rend compte que l'on peut facilement dériver un modèle explicite sous forme de combinaisons linéaires des prédicteurs. Nous avions implémenté cette approche dans Tanagra. Nous avons montré dans plusieurs tutoriels (cf. références) l'intérêt de ces calculs supplémentaires relativement simples finalement. Dans cette optique, le classifieur bayesien naïf se pose comme un challenger tout à fait valable des techniques populaires telles que la régression logistique. A l'époque des dits tutoriels, Tanagra était le seul logiciel libre (ou à accès gratuit) à proposer la présentation des modèles sous cette forme. Je ne sais pas aujourd'hui.
Ce diaporama, qui me servira de support pour mes cours, vient présenter la méthode de manière unifiée (prédicteurs quantitatifs et qualitatifs). A terme, il constituera un chapitre d'un ouvrage consacré à l'analyse discriminante prédictive.
Diaporama imprimable : Classifieur Bayesien Naïf
Références :
Tutoriel Tanagra, "Le classifieur Bayesien Naïf revisité"
Tutoriel Tanagra, "Bayesien Naïf pour Prédicteurs Continus"
Régression - Déploiement de modèles
2011-03-20 (Tag:194893244177904541)
Le déploiement est une des principales finalités du Data Mining. Il s'agit d'appliquer les modèles sur de nouveaux individus de la population. En apprentissage supervisé, il s'agit de leur attribuer leur classe d'appartenance ; en apprentissage non supervisé, l'objectif est de les associer à un groupe qui leur serait le plus similaire. Concernant la régression, appliquer le modèle sur des nouveaux individus consiste à prédire la valeur de la variable dépendante quantitative (variable endogène, variable cible) à partir de leur description c.-à-d. les valeurs prises par les variables indépendantes (variables exogènes).L'opération est simple lorsqu'il s'agit d'implémenter une régression linéaire multiple ou une régression PLS. Nous récupérons les coefficients du modèle, nous les appliquons sur la description des nouveaux individus à étiqueter. L'affaire devient compliquée lorsque nous souhaitons manipuler des modèles plus complexes, soit parce qu'issus d'enchaînements d'opérations (ex. analyse factorielle + régression sur axes), soit parce que nous ne disposons pas d'une expression explicite simple du modèle (Support Vector Regression avec un noyau non linéaire). Il est donc primordial que le logiciel qui a servi à la construction des modèles puisse se charger lui-même du déploiement.
Avec Tanagra, il est possible de déployer facilement les modèles dans le cadre de la régression, même lorsqu'ils sont le fruit d'une succession d'opérations. Il faut simplement préparer le fichier de données d'une manière particulière.
Dans ce didacticiel, nous montrons comment organiser efficacement le fichier pour faciliter le déploiement. Par la suite, nous apprenons plusieurs modèles prédictifs (régression linéaire multiple, régression PLS, support vector régression avec un noyau RBF, arbre de régression, régression sur axes factoriels), que nous appliquons sur les nouvelles observations à étiqueter. Nous exportons les prédictions dans un fichier au format Excel. Enfin, nous vérifions leur cohérence. L'idée est d'identifier les techniques qui produisent des prédictions similaires.
Mots clés : déploiement, régression linéaire multiple, régression pls, support vector regression, SVR, arbres de régression, cart, analyse en composantes principales, régression sur axes factoriels
Composants : MULTIPLE LINEAR REGRESSION, PLS REGRESSION, PLS SELECTION, C-RT REGRESSION TREE, EPSILON SVR, PRINCIPAL COMPONENT ANALYSIS, RECOVER EXAMPLES, EXPORT DATASET, LINEAR CORRELATION
Lien : fr_Tanagra_Multiple_Regression_Deployment.pdf
Données : housing.xls
Références :
R. Rakotomalala, Régression linéaire multiple - Diaporama
Régression linéaire - Lecture des résultats
2011-02-11 (Tag:6416682080233267919)
La régression linéaire multiple est une technique de modélisation statistique. Elle vise à prédire et expliquer les valeurs prises par une variable endogène quantitative Y à partir de p variables exogènes X1, …, Xp, quantitatives ou qualitatives rendues binaires par recodage.Dans ce tutoriel, à travers un exemple de prédiction de la consommation des véhicules à partir de leur poids, de leur cylindrée et de leur puissance, nous décrirons les sorties de TANAGRA en leur associant les formules utilisées. Nous mettrons en avant le rôle de la matrice (X'X)^(-1) fournie depuis la version 1.4.38. Elle est importante car elle tient une place centrale dans les tests généralisés sur les coefficients. Nous en accomplirons quelques uns manuellement avec le tableur Excel.
Dans un deuxième temps, nous réaliserons la régression à l'aide du logiciel R. Nous mettrons en parallèle ses résultats avec ceux de TANAGRA. Nous identifierons les objets qui fournissent les informations nécessaires aux différents post-traitements, notamment les tests généralisés. Nous effectuerons alors les calculs réalisés précédemment dans Excel directement dans R.
Mots clés : régression linéaire multiple, logiciel R, lm, tests généralisés, tests de conformité, tests de comparaison
Composants : MULTIPLE LINEAR REGRESSION
Lien : fr_Tanagra_Multiple_Regression_Results.pdf
Données : cars_consumption.zip
Références :
R. Rakotomalala, Régression linéaire multiple - Diaporama
Tanagra - Version 1.4.38
2011-02-04 (Tag:7673205510687933698)
Quelques corrections mineures pour la version 1.4.38 de Tanagra.Les codes couleurs des tests de normalité ont été harmonisés (NORMALITY TEST). Selon la procédure, les couleurs associées aux p-value n'étaient pas cohérents, induisant en erreur le praticien. Ce problème m'a été signalé par M. Laurent Garmendia.
Suite à des indications de M. Oanh Chau, je me suis rendu compte que la standardisation des variables pour la HAC (classification ascendante hiérarchique) était basée sur l'écart-type d'échantillon. Ce n'est pas une erreur en soi. Mais du coup, la somme des indices de niveau dans le dendrogramme ne coïncidait pas avec la TSS (total sum of squares). C'est plus gênant. L'écart est surtout perceptible sur les petits fichiers, il s'estompe lorsque l'effectif augmente. La correction a été introduite, maintenant le « BSS ratio » vaut bien 1 lorsque nous avons la partition triviale c.-à-d. un individu par groupe.
La régression linéaire multiple (MULTIPLE LINEAR REGRESSION) fournit maintenant la matrice (X'X)^(-1). Elle permet de déduire la matrice de variance covariance des coefficients (en la pré-multipliant par la variance estimée de l'erreur). Elle rentre aussi dans les tests généralisés sur les coefficients : les tests de conformité simultanés; les tests de combinaisons linéaires. Ces tests sont décrits (entres autres) dans les diaporamas de mes enseignements d'économétrie en Licence IDS.
Enfin, les sorties de l'analyse discriminante descriptive (CANONICAL DISCRIMINANT ANALYSIS) ont été complétées. Les barycentres des groupes (Group centroïds) sur les axes factoriels sont directement fournies.
Merci infiniment à toutes les personnes qui, par leurs commentaires ou leurs suggestions, m'aident à améliorer quotidiennement le travail que je mets en ligne (logiciel, documents).
Page de téléchargement de Tanagra : setup
Régression Linéaire Multiple - Diaporama
2011-01-31 (Tag:2503824876330350156)
Toujours dans la série « Je refais mes diapos de mon cours d'Économétrie », voici le support consacré à la « Régression Linéaire Multiple ».Pour comprendre les formules, je montre le détail des calculs dans le tableur Excel. Franchement, je ne connais pas de meilleure approche pédagogique pour que tout un chacun puisse comprendre l'enchaînement des opérations, notamment tout ce qui concerne les calculs matriciels pour la production des estimateurs et de leurs variances.
Diaporama imprimable : Régression Linéaire Multiple
Données : Cigarettes.xls
Page du cours d'Économétrie de la Licence : Économétrie
Régression Linéaire Simple - Diaporama
2011-01-27 (Tag:6556774402445821978)
Dans la série « Je refais les diaporamas de mon cours d'économétrie », voici le support consacré à la « Régression Linéaire Simple ».Il développe tous les thèmes abordés en cours. Il ne comporte pas les démonstrations en revanche. Je les fais au tableau. En effet, il y a les formules, mais il y a surtout la démarche sous-jacente, les ressorts qui permettent de mettre en évidence tel ou tel résultat. Et quel que soit l'exhaustivité d'un support, il y a des choses que l'on ne peut développer que verbalement, en comptant sur l'interactivité des étudiants (allez les gars, dormez pas quoi...).
Et puis, il faut bien justifier le fait que je vienne à la fac pour faire le zouave devant tout le monde.
Diaporama imprimable : Régression linéaire simple
Données : rendements agricoles.xls
Page du cours d'Économétrie de la Licence : Économétrie
Introduction à l'Econométrie - Diaporama
2011-01-17 (Tag:8914168233066896070)
De l'Économétrie au Data Mining, le chemin n'est pas aussi long qu'on peut le croire. Finalement, il s'agit de détecter des formes de régularités dans les données, de s'assurer qu'elles représentent réellement une causalité (économique ou autres), puis de les exploiter par la suite. Seuls le domaine d'application et les techniques utilisées sont différents.Ce diaporama correspond à mon Introduction à l'Économétrie pour mon cours en Licence Informatique Décisionnelle et Statistique du Département Informatique et Statistique (http://dis.univ-lyon2.fr) de la Faculté de Sciences Économiques de l'Université Lyon 2.
Diaporama imprimable : Introduction à l'Économétrie
Diaporama animé : Introduction à l'Économétrie
Analyse factorielle discriminante - Diaporama
2011-01-14 (Tag:4898380952052108060)
L'analyse factorielle discriminante ou analyse discriminante descriptive est une technique factorielle qui vise à expliquer à l'aide d'un ensemble de variables l'appartenance des individus à des groupes (classes) prédéfinis. C'est dont avant tout une méthode descriptive. Néanmoins, de par sa définition, elle a des connexions très importantes avec l'analyse discriminante bayesienne ou analyse discriminante prédictive, bien connue en apprentissage supervisé et en reconnaissance de formes.L'analyse discriminante descriptive fait partie des approches factorielles. On montre assez facilement qu'elle constitue une déclinaison particulière de l'analyse canonique et de l'analyse en composantes principales.
Ce nouveau diaporama est le support que j'utiliserai dorénavant pour décrire la méthode auprès de mes étudiants. On peut la décomposer en trois grandes parties : présentation de la méthode et principaux éléments théoriques ; lecture des résultats, notamment l'interprétation des axes factoriels ; mise en œuvre dans les logiciels tels que Tanagra (Canonical Discriminant Analysis), R (lda) et SAS (candisc).
Ce support doit beaucoup aux excellents ouvrages de Tenenhaus (2007) et Saporta (2006) indiqués dans la bibliographie.
Mots clés : analyse factorielle discriminante, analyse discriminante descriptive, logiciel R, lda, sas, candisc
Composants : CANONICAL DISCRIMINANT ANALYSIS
Lien : analyse_discriminante_descriptive.pdf
Données : wine_quality.xls
Références :
Wikipédia, "Analyse discriminante"
D. Garson, "Discriminant Function Analysis"
Bonne année 2011 - Bilan 2010
2011-01-03 (Tag:2382466255620394789)
L'année 2010 s'achève, 2011 commence. Je vous souhaite à tous une belle et heureuse année 2011.Un petit bilan chiffré concernant l'activité organisée autour de Tanagra pour l' année écoulée. L'ensemble des sites (logiciel, support de cours, ouvrages, tutoriels) a été visité 241.765 fois cette année, soit 662 visites par jour. Par comparaison, nous avions 349 visites journalières en 2008 et 520 en 2009.
Qui êtes-vous ? La majorité des visites viennent de France et du Maghreb (62 %). Puis viennent les autres pays francophones, une grande partie vient d'Afrique. Pour ce qui est des pays non francophones, nous observons parmi ceux qui reviennent souvent : les États-Unis, l'Inde, le Royaume Uni, l'Allemagne, le Brésil, etc.
Que consultez-vous en priorité ? Les pages qui ont le plus de succès sont celles qui se rapportent à la documentation sur le Data Mining : les supports de cours, les tutoriels, les liens vers les autres documents accessibles en ligne, etc. Ce n'est guère étonnant. Au fil des années, plus que la programmation et la promotion de Tanagra, je passe de plus en plus de temps moi-même à écrire des fascicules de cours et des tutoriels, à étudier le comportement des différents logiciels.
Encore Bonne Année 2011 à tous. Que chacun puisse mener à bien les projets qui leur sont les plus précieux.
Ricco.
Diaporama : Tanagra - Bilan 2010
ACP avec FactoMineR et dynGraph
2010-12-24 (Tag:564582915688282621)
Il y a deux manières d'appréhender la représentation graphique des données en Data Mining. La première consiste à la considérer comme un outil de présentation des résultats. Le graphique vient appuyer le texte et les tableaux pour mettre en évidence les informations produites par l'analyse. Par exemple, on annonce dans le texte que les ventes de bonnets augmentent en hiver, une petite courbe où l'on distingue les pics de ventes en fin et en début d'année vient confirmer cela.La seconde cherche à intégrer la représentation graphique dans le processus exploratoire même. Ici, elle devient un outil supplémentaire de détection des régularités, des singularités et des relations qui peuvent exister dans les données. A cet égard, les logiciels modernes, avec des fonctionnalités graphiques de plus en plus puissantes, ouvrent des perspectives incroyables. Comme je le dis souvent : un graphique bien senti vaut largement mieux qu'une série de ratios à l'interprétation confuse ou mal maîtrisée.
Dans ce didacticiel, nous menons une analyse en composantes principale avec le logiciel R. Nous l'avions déjà réalisée précédemment avec la procédure princomp(). Ici, nous réitérons l'étude avec la procédure PCA() du package FactoMineR. De nombreux indicateurs sur les éléments (variables, individus) actifs ou illustratifs sont directement fournis maintenant, facilitant grandement la tâche du praticien. Il n'est plus nécessaire de les post-calculer à l'aide de formules plus ou moins complexes comme nous avions pu le faire dans le précédent document. Par la suite, sur la base des indicateurs livrés par PCA(), nous procéderons à une exploration graphique à l'aide de l'outil dynGraph du package éponyme. Nous constaterons que les possibilités en matière d'analyse interactive sont nombreuses.
Mots clés : logiciel R, analyse en composantes principales, ACP, cercle de corrélation, variables illustratives, factominer, dyngraph, analyse graphique interactive
Composants : PCA, dynGraph
Lien : acp_avec_factominer_dyngraph.pdf
Données : acp_avec_factominer_dyngraph.zip
Références :
G. Saporta, « Probabilités, analyse des données et statistique », Dunod, 2006 ; pages 155 à 179.
Tutoriel Tanagra, "ACP - Description de véhicules"
F. Husson, J. Josse, S. Le, J. Pages, Le package FactoMineR pour R ; http://factominer.free.fr/
S. Le, J. Durand, Le package dynGraph pour R ; http://dyngraph.free.fr/
Outils pour le développement d'applications
2010-12-19 (Tag:6316412227010750361)
Un tutoriel un peu différent des autres cette fois-ci. J'y parle des outils et langages de programmation pour le développement d'applications de data mining.Lancer un débat à propos du " meilleur langage de programmation " est une excellente manière de plomber une soirée entre informaticiens. La question sous-jacente est " quel est le langage qui permet de développer l'application la plus performante, la plus rapide… ".
De très bon enfant, l'atmosphère devient très vite orageuse, voire délétère. Des personnes, fort charmantes la plupart du temps, adoptent un comportement passionné, voire passionnel, montent sur leurs grands chevaux (tagada, tagada) en assénant des arguments parfois complètement irrationnels. Je sais de quoi je parle, j'en fais partie quand je me laisse aller. Pourtant, finalement, trancher dans ce genre de débat serait assez facile. Il suffit de caractériser les problèmes que l'on cherche à résoudre, écrire un code équivalent dans les différents langages, et étudier le comportement de l'exécutable généré. C'est ce que nous allons faire dans ce didacticiel en nous plaçant dans deux situations couramment rencontrées lors de la programmation d'algorithmes d'exploration de données. On verra que le résultat n'est pas du tout celui qu'on attendait (si on en attendait un, ouh là là je vois déjà certains bondir), loin de là.
Tout d'abord, corrigeons un abus de langage (si je puis dire), la performance n'est pas une affaire de langage, mais plutôt une affaire de technologie et de compilateur. Nous le verrons, le même code source, compilé avec des outils différents, peut aboutir à des exécutables avec des comportements très différents. Nous étudierons dans ce document : C# avec Visual C# Express de Microsoft ; Pascal avec Borland Delphi 6.0 ; Pascal avec le compilateur Free Pascal 2.2.4 de Lazarus 0.9.28 ; C++ avec Borland C++ Builder 4 ; C++ avec Dev C++ (compilateur G++) ; Java exécuté via la JRE1.6.0_19 sous Windows (Eclipse est l'outil de développement que j'ai utilisé). Tous ces outils, excepté Borland C++ Builer 4, sont accessibles gratuitement sur le net. Pour tous, j'ai sélectionné les options de compilations qui optimisent la rapidité d'exécution.
Les performances sont évaluées en mesurant les temps de calculs des exécutables lancés via le shell, en dehors de l'EDI (Environnement de Développement Intégré) pour éviter les interférences. Ma machine étant multi-cœur, temps utilisateur et temps CPU sont quasiment les mêmes. Nous nous contenterons du premier. Chaque programme est lancé 10 fois. Nous calculons la moyenne.
Mots-clés : langage de programmation, c++, c#, delphi, pascal, java
Didacticiel : fr_Tanagra_Programming_Language.pdf
Code source : programming_language.zip
Régles d'association - Données transactionnelles
2010-12-15 (Tag:4965205724158589713)
L’extraction des règles d’association est une des applications phares du data mining. L’idée est de mettre à jour des régularités, sous forme de cooccurrences, dans les bases de données. L’exemple emblématique est l’analyse des tickets de caisses des grandes surfaces : on veut découvrir des règles de comportement du type « si le client a acheté des couches et des lingettes, il va acheter du lait de croissance ». Auquel cas, il est peut être opportun de mettre les rayons adéquats dans la même zone du magasin (c’est le cas en ce qui concerne l’hypermarché que je fréquente habituellement). La partie « si » de la règle est appelée « antécédent », la partie « alors » est le « conséquent ».Il est possible de rechercher des cooccurrences dans les tableaux individus – variables que l’on manipule avec les logiciels de Data Mining usuels. Mais bien souvent, surtout dans le cadre de l’induction des règles d’association, les données peuvent se présenter sous la forme d’une base transactionnelle. Si l’on reprend l’exemple de l’analyse des tickets de caisse, nous disposons d’une liste de produits par caddie.
Cette représentation des données est assez naturelle eu égard au problème que l’on souhaite traiter. Elle présente aussi l’avantage d’être plus compacte puisque seuls sont effectivement listés les produits observés dans chaque caddie. Nous n’avons pas besoin de nous préoccuper des produits qui n’y sont pas, surtout qu’ils peuvent être très nombreux si l’on se réfère aux nombre d’articles que peut proposer une enseigne de grande distribution.
Pour autant que ce mode de description soit naturel, il s’avère que de nombreux logiciels ne savent pas l’appréhender directement. On observe curieusement un vrai clivage entre les outils à vocation professionnelle et ceux issus du monde universitaire. Les premiers savent pour la plupart manipuler ce type de fichier. C’est le cas des logiciels SPAD 7.3 et SAS Enterprise Miner 4.3 que nous étudions dans ce didacticiel. Les seconds en revanche demandent une transformation préalable des données pour pouvoir fonctionner. Nous utiliserons une macro VBA fonctionnant sous Excel pour transformer nos données en base « individus – variables » binaire propice au traitement sous Tanagra 1.4.37 et Knime 2.2.2. Attention, nous devons respecter le cahier des charges initial, à savoir s’intéresser uniquement aux règles signalant la présence simultanée des produits dans les caddies. Il n’est pas question, consécutivement à un codage « présent – absent » mal maîtrisé, de produire des règles mettant en évidence l’absence simultanée de certains produits. Cela peut être intéressant dans certains cas, mais ce n’est pas l’objectif de notre analyse.
Mots-clés : règle d'association, règles d'association, spad 7.3, sas em 4.3, knime 2.2.2, filtrage des règles, lift
Composants : A PRIORI
Didacticiel : fr_Tanagra_Assoc_Rule_Transactions.pdf
Données : assoc_rule_transactions.zip
Références :
Wikipedia, "Association rule learning"
Arbres de décision sur les grands fichiers (mise à jour)
2010-12-11 (Tag:8787608128406418185)
Dans un post assez ancien ("Traitement de gros volumes - Comparaison de logiciels" - septembre 2008), je comparais le comportement de plusieurs logiciels lors du traitement d'un fichier relativement volumineux avec les arbres de décision.J'y décrivais entres autres le comportement de Tanagra version 1.4.27 sortie en aout 2008. Depuis, ma machine de développement a changé ; Tanagra lui-même a changé, nous en sommes à ce jour à la version 1.4.37 ; et Sipina a lui aussi été modifié (version 3.5), avec l'introduction du multithreading pour certaines techniques d'induction d'arbres. Je me suis dit qu'il était temps d'étudier les performances en rééditant l'expérimentation dans les mêmes conditions.
Concernant Tanagra et Sipina, les seuls logiciels que j'ai analysés dans ce nouveau contexte, l'amélioration des temps de traitement est manifeste. Après, il faut discerner ce qui est imputable au changement de machine, et ce qui revient aux modifications dans les implémentations. Nous avançons quelques pistes dans notre document.
Les nouveaux résultats ont été ajoutés dans la dernière section (section 5) du PDF.
Lien : fr_Tanagra_Perfs_Comp_Decision_Tree.pdf
Multithreading pour les arbres de décision
2010-11-18 (Tag:1429640065830637930)
Une grande partie des PC modernes sont équipés de processeurs multi-cœurs. Dans les faits, l'ordinateur fonctionne comme s'il disposait de plusieurs processeurs. Certains d'ailleurs, les gros serveurs notamment, en disposent effectivement. Les logiciels et les algorithmes de data mining doivent être aménagés pour pouvoir en tirer profit. A l'heure actuelle, rares sont les outils à large diffusion qui exploitent ces nouvelles caractéristiques des machines.En effet, l'affaire n'est pas simple. Il est impossible de mettre en place une démarche générique qui serait valable quelle que soit la méthode d'apprentissage utilisée. Pour une technique donnée, décomposer un algorithme en tâches que l'on peut exécuter en parallèle est un domaine de recherche à part entière. Les publications scientifiques regorgent de propositions en tous genres, tant au niveau méthodologique (modification des algorithmes) qu'au niveau technologique (implémentation sur les machines). Une grande majorité d'entre elles s'intéressent surtout à l'implantation sur de gros systèmes. Il y a très peu de propositions de solutions légères que l'on peut introduire facilement sur des logiciels destinés aux ordinateurs personnels.
Dans ce didacticiel, une solution basée sur les threads est mise en avant. Elle est implantée dans la version 3.5 de Sipina.
Mots-clés : multithreading, thread, threads, arbres de décision, chaid, sipina 3.5, knime 2.2.2, rapidminer 5.0.011
Didacticiel : fr_sipina_multithreading.pdf
Données : covtype.arff.zip
Références :
Wikipedia, "Arbres de décision"
Aldinucci, Ruggieri, Torquati, " Porting Decision Tree Algorithms to Multicore using FastFlow ", Pkdd-2010.
Création de rapports avec Tanagra
2010-10-24 (Tag:5179482806277068333)
Le reporting est un vrai critère de différenciation entre les logiciels de data mining à vocation professionnelle et ceux issus de la recherche. Pour un praticien (ex. chargé d'études), il est important de pouvoir récupérer facilement le fruit de son travail dans un traitement de texte ou dans un diaporama. L'affaire devient particulièrement intéressante lorsqu'il dispose déjà d'une sortie au format tableur. En effet les résultats se présentent souvent sous la forme de divers tableaux et, éventuellement, de graphiques. Le nec plus ultra est de pouvoir définir à l'avance des maquettes de rapports que l'on nourrit simplement à l'issue des calculs et que l'on peut imprimer directement. Pour le chercheur qui développe des outils, tout cela est bien beau, mais ce n'est absolument pas valorisable académiquement. Je me vois très mal pour ma part proposer un article dans une revue montrant que je suis capable d'intégrer automatiquement des camemberts 3D dans un fichier PDF. De fait, les outils élaborés par les chercheurs se contentent souvent de sorties textes, certes complètes, mais peu présentables en l'état dans des rapports destinés à être diffusés à large échelle. Les sorties de R ou de Weka en sont un exemple édifiant.Tanagra, créé par un enseignant chercheur, s'inscrit dans la même démarche. Rien n'a été initialement prévu pour le reporting. Et pourtant, paradoxalement, il propose dans un des ses menus (DIAGRAM / CREATE REPORT) un outil de création de rapports. C'est la conséquence heureuse d'un choix technologique effectué lors de l'écriture du cahier des charges du logiciel.
Revenons un peu en arrière pour comprendre la démarche. Lorsque j'avais écrit SIPINA (version 3.x), je me suis rendu compte que la construction des fenêtres d'affichage des résultats me prenait énormément de temps, plus que l'écriture des algorithmes de calculs. Dans mon optique, ce n'était pas une bonne chose car cela me détournait de ma principale préoccupation : comprendre les méthodes, les implémenter, les évaluer, en parler. Lorsque j'ai réfléchi aux spécifications de Tanagra, je me suis dit qu'il fallait absolument définir une fenêtre d'affichage standardisée, forcément avec des sorties textes, mais avec néanmoins une présentation relativement attrayante. Et là, j'ai redécouvert le HTML. C'est un peu amusant à dire, surtout en 2003. Le HTML permet de faire un effort minimum de description des sorties, une seule méthode dans la classe de calcul suffit (un peu comme Weka pour ceux qui sont allés voir le code source), tout en obtenant une présentation avenante. De plus, il est possible de mettre en évidence les informations importantes à lire en priorité. Par exemple, rien que pouvoir attribuer des codes couleurs à des tranches de p-value est infiniment précieux.
Par la suite, j'ai réalisé que le choix du HTML allait s'avérer doublement judicieux. En effet, c'est un standard largement répandu. Sans effort de programmation supplémentaire, nous pouvons d'une part récupérer les sorties dans le tableur Excel ; d'autre part, nous pouvons exporter les fenêtres de visualisation dans un fichier externe et visualiser les résultats dans un navigateur web, indépendamment du logiciel Tanagra. De fait, leur diffusion est largement facilitée.
Ce sont ces fonctionnalités de " reporting " de Tanagra que nous présentons dans ce didacticiel.
Mots-clés : rapport, reporting, arbre de décision, c4.5, régression logistique, codage disjonctif, courbe roc, échantillon d'apprentissage, échantillon test, sélection de variables
Composants : GROUP CHARACTERIZATION, SAMPLING, C4.5, TEST, O_1_BINARIZE, FORWARD-LOGIT, BINARY LOGISTIC REGRESSION, SCORING, ROC CURVE
Didacticiel : fr_Tanagra_Reporting.pdf
Données : heart disease
Bayesien naïf pour prédicteurs continus
2010-10-20 (Tag:2621093312309162878)
Le classifieur bayesien naïf est une méthode d'apprentissage supervisé qui repose sur une hypothèse simplificatrice forte : les descripteurs (Xj) sont deux à deux indépendants conditionnellement aux valeurs de la variable à prédire (Y). Pourtant, malgré cela, il se révèle robuste et efficace. Ses performances sont comparables aux autres techniques d'apprentissage. Diverses raisons sont avancées dans la littérature. Nous avions nous même proposé une explication basée sur le biais de représentation dans un précédent tutoriel . Lorsque les prédicteurs sont discrets, on se rend compte aisément que le classifieur bayesien naïf est un séparateur linéaire. Il se pose donc en concurrent direct des autres techniques du même acabit, telles que l'analyse discriminante, la régression logistique, les SVM (Support Vector Machine) linéaires, etc.Dans ce tutoriel, nous décrivons le modèle d'indépendance conditionnelle dans le cadre des variables prédictives quantitatives. La situation est un peu plus complexe. Nous verrons que, selon les hypothèses simplificatrices utilisées, il peut être considéré comme un séparateur linéaire ou quadratique. Il est alors possible de produire un classifieur explicite, facilement utilisable pour le déploiement. Les idées mises en avant dans ce tutoriel ont été implémentées dans Tanagra 1.4.37 (et ultérieure). Cette représentation du modèle est originale. Je ne l'ai pas retrouvée dans les autres logiciels libres que j'ai l'habitude de suivre (pour l'instant…).
Ce document est organisé comme suit. Tout d'abord (section 2), nous détaillons les aspects théoriques de la méthode. Nous montrons qu'il est possible de parvenir à un modèle explicite que l'on peut exprimer sous la forme d'une combinaison linéaire des variables ou du carré des variables. Dans la section 3, nous décrivons la mise en œuvre de la méthode à l'aide du logiciel Tanagra. Nous confrontons les résultats avec ceux des autres séparateurs linéaires (régression logistique, SVM linéaire, analyse discriminante PLS, analyse discriminante de Fisher). Dans la section 4, nous comparons l'implémentation de la technique dans différents logiciels. Nous mettrons surtout l'accent sur la lecture des résultats. Enfin, section 5, nous montrons l'intérêt de l'approche sur les très grands fichiers. Nous traiterons la base " mutants " comprenant 16592 observations et 5408 variables prédictives avec une rapidité hors de portée des autres techniques.
Mots-clés : classifieur bayesien naïf, modèle d'indépendance conditionnelle, rapidminer 5.0.10, weka 3.7.2, knime 2.2.2, logiciel R, package e1071, analyse discriminante, analyse discriminante pls, régression pls, svm linéaire, régression logistique
Composants : NAIVE BAYES CONTINUOUS, BINARY LOGISTIC REGRESSION, SVM, C-PLS, LINEAR DISCRIMINANT ANALYSIS
Didacticiel : fr_Tanagra_Naive_Bayes_Continuous_Predictors.pdf
Données : breast ; low birth weight
Références :
Wikipedia, "Naive bayes classifier"
Tanagra, "Classifieur bayesien naïf pour les prédicteurs discrets"
Tanagra - Version 1.4.37
2010-10-19 (Tag:1123133217367631567)
Naive Bayes Continuous est un composant d'apprentissage supervisé. Il implémente le modèle d'indépendance conditionnelle pour les prédicteurs continus (quantitatifs). La principale originalité est dans la production d'un modèle explicite sous forme d'une combinaison linéaire des variables prédictives et, éventuellement, de leur carré.Les fonctionnalités de reporting ont été améliorées.
Tanagra - Version 1.4.37
2010-10-19 (Tag:933692695073583440)
Naive Bayes Continuous est un composant d'apprentissage supervisé. Il implémente le modèle d'indépendance conditionnelle pour les prédicteurs continus (quantitatifs). La principale originalité est dans la production d'un modèle explicite sous forme d'une combinaison linéaire des variables prédictives et, éventuellement, de leur carré.Les fonctionnalités de reporting ont été améliorées.
Nouvelle interface pour RapidMiner 5.0
2010-10-04 (Tag:5955557375309857866)
La société Rapid-I, à travers leur logiciel phare RapidMiner, est un acteur très dynamique du l'informatique décisionnelle. Au-delà de l'outil, elle propose des solutions et des services dans le domaine de l'analyse prédictive, data mining et du text mining. Son site web regorge d'informations (blog, tutoriels, vidéos, forum, newsletter, wiki, etc.).La version 5.0 de RapidMiner (Community Edition - Téléchargeable gratuitement) propose une interface profondément remaniée, s'inspirant visiblement de Knime. Les ressemblances entre les deux produits sont frappantes. Je me suis dit qu'il était opportun d'étudier cela en détail, en évaluant son comportement dans le cadre d'une analyse type. Nous souhaitons mettre en place le processus suivant : (1) construire et afficher un arbre de décision à partir d'un ensemble d'observations étiquetées ; (2) sauvegarder l'arbre dans un fichier au format PMML en vue d'un déploiement ultérieur ; (3) évaluer les performances en généralisation du classifieur à travers la validation croisée ; (4) utiliser le modèle pour classer un ensemble d'observations non étiquetées contenues dans un second fichier, les résultats (descripteurs et étiquette attribuée) doivent être consignés dans un troisième fichier au format CSV.
Ce sont là des tâches très classiques du data mining. Nous les avons maintes fois décrites dans nos didacticiels (ex. SPAD, ...). Raison de plus pour vérifier s'il est aisé de les mener à bien avec cette nouvelle version de RapidMiner. En effet, avec la précédente mouture, certains enchaînements étaient compliqués. Mettre en place une validation croisée par exemple demandait une organisation, certes très rigoureuse dans son esprit, mais peu intuitive.
Mots-clés : rapidminer, knime, validation croisée, arbres de décision, déploiement
Didacticiel : fr_Tanagra_RapidMiner_5.pdf
Données : adult_rapidminer.zip
Références :
Rapid-I, "RapidMiner"
Le format PMML pour le déploiement de modèles
2010-09-21 (Tag:5226542016612459250)
Le déploiement des modèles est une étape importante du processus Data Mining. Dans le cadre de l'apprentissage supervisé, il s'agit de réaliser des prédictions en appliquant les modèles sur des observations non étiquetées. Nous avons décrit à maintes reprises la procédure pour différents outils (ex. Tanagra, Sipina, Spad, ou encore R). Ils ont pour point commun d'utiliser le même logiciel pour la construction du modèle et son déploiement.Ce nouveau didacticiel se démarque des précédents dans la mesure où nous utilisons un logiciel tiers pour le classement des nouvelles observations. Il fait suite à une remarque qui m'a été faite par Loïc LUCEL (merci infiniment Loïc pour tes précieuses indications), il m'a fait prendre conscience de deux choses : le déploiement donne sa pleine mesure lorsqu'on le réalise avec un outil dédié au management des données, nous prendrons l'exemple de PDI-CE (Kettle) ; nous accédons à une certaine universalité lorsque nous décrivons les modèles à l'aide de standards reconnus/acceptés par la majorité des logiciels, en l'occurrence le standard de description PMML.
J'avais déjà parlé à plusieurs reprises de PMML. Mais jusqu'à présent, je ne voyais pas trop son intérêt si nous n'avons pas en aval un outil capable de l'appréhender de manière générique. Dans ce didacticiel, nous constaterons qu'il est possible d'élaborer un arbre de décision avec différents outils (SIPINA, KNIME et RAPIDMINER), de les exporter en respectant la norme PMML, puis de les déployer de manière indifférenciée sur des observations non étiquetées via PDI-CE. L'adoption d'un standard de description des modèles devient particulièrement intéressante dans ce cas.
Un peu à la marge de notre propos, nous décrirons des solutions de déploiement alternatives dans ce didacticiel. Nous verrons ainsi que Knime possède son propre interpréteur PMML. Il est capable d'appliquer un modèle sur de nouvelles données, quel que soit l'outil utilisé pour l'élaboration du modèle. L'essentiel est que le standard PMML soit respecté. En ce sens, Knime peut se substituer à PDI-CE. Autre piste possible, Weka, qui fait partie de la suite " Pentaho Community Edition ", possède un format de description propriétaire directement reconnu par PDI-CE.
Mots-clés : déploiement, pmml, arbres de décision, rapidminer 5.0.10, weka 3.7.2, knime 2.1.1, sipina 3.4
Didacticiel : fr_Tanagra_PDI_Model_Deployment.pdf
Données : heart-pmml.zip
Références :
Data Mining Group, "PMML standard"
Pentaho, "Pentaho Kettle Project"
Pentaho, "Using the Weka Scoring Plugin"
Pentaho Data Integration
2010-09-10 (Tag:8243747181021210766)
L'informatique décisionnelle (" Business Intelligence - BI " en anglais, ça fait tout de suite plus glamour) fait référence à " l'exploitation des données de l'entreprise dans le but de faciliter la prise de décision ". Des suites logicielles se proposent de prendre en charge le processus complet. J'ai choisi de mettre en avant la suite Open Source Pentaho, mais les principes énoncés sont valables pour la grande majorité des logiciels du domaine.Il existe deux versions de Pentaho. L'édition entreprise est payante, elle donne accès à une assistance. Je ne l'ai pas testée. La " Community Edition " (Pentaho CE) est téléchargeable librement. Elle est développée et maintenue par une communauté de développeurs. Je ne situe pas bien différences entre les deux versions. Pour ma part, je me suis focalisé sur la version non payante, pour que tout un chacun puisse reproduire les opérations que je décris.
Ce document présente la mise en oeuvre de Pentaho Data Integration Community Edition (PDI-CE, appelée également Kettle), l'outil ETL de la suite Pentaho CE. Je me contente d'une description succincte pour deux raisons : ce type d'outil n'entre pas directement dans mon champ de compétences (qui est le data mining) ; j'en parle surtout pour préparer un prochain tutoriel dans lequel je montre le déploiement de modèles élaborés à l'aide de Knime, Sipina ou Weka via PDI-CE.
Mots-clés : ETL, pentaho data integration, community edition, kettle, extraction de données, importation de données, alimentation, transformation, businness intelligence, informatique décisionnelle
Didacticiel : PDI-CE
Données : titanic32x.csv.zip
Références :
Comment ça marche.net, "Informatique décisionnelle (Business Intelligence)"
Pentaho, Pentaho Community
Connexion Sipina/Excel via OLE [XL-SIPINA]
2010-08-30 (Tag:977209489511357210)
La connexion entre un logiciel de data mining et Excel (et plus généralement les tableurs) est un enjeu fort. Nous l'avions maintes fois abordée dans nos didacticiels. Au fil du temps, la solution basée sur l'utilisation des macros complémentaires (add-in) s'est imposée, tant pour SIPINA que pour TANAGRA. Elle est simple, fiable, performante. Elle ne nécessite pas développer des versions spécifiques. La connexion avec Excel est une simple fonctionnalité additionnelle de la distribution standard.Avant de parvenir à cette solution, nous avions exploré différentes pistes. Dans ce didacticiel, nous présentons la solution XL-SIPINA basée sur la technologie OLE de Microsoft. A contre-pied des macros complémentaires, cette version de SIPINA choisit d'intégrer Excel dans le logiciel de Data Mining. Le dispositif fonctionne plutôt bien. Néanmoins, il a finalement été abandonné pour deux raisons : (1) nous étions obligé de développer/compiler des versions spéciales qui ne fonctionnent que si Excel est présent sur la machine de l'utilisateur ; (2) les temps de transferts " objet Excel - Sipina " via OLE s'avèrent dissuasifs lorsque la taille de la base augmente.
Il faut donc prendre XL-SIPINA comme un exercice de style. Il y a toujours un peu de nostalgie lorsque je fais un retour en arrière sur des voies que j'ai explorées et que j'ai finalement abandonnées. Peut être d'ailleurs ne suis-je pas allé totalement au bout des choses.
Dernière remarque. A l'origine, l'application a été développée à l'aide d'Office 97. Je me rends compte qu'elle reste d'actualité encore aujourd'hui, elle fonctionne parfaitement avec Office 2010.
Mots-clés : excel, tableur, sipina, xls, xlsx, xl-sipina, arbres de décision
Logiciel : XL-SIPINA
Didacticiel : fr_xls_sipina.pdf
Données : autos
L'add-in Tanagra pour Excel 2007 et 2010
2010-08-27 (Tag:8047273879088338540)
La macro complémentaire (" add-in " en anglais) " tanagra.xla " participe grandement à la diffusion du logiciel Tanagra. Le principe est simple, il s'agit d'intégrer un menu Tanagra dans Excel. Ainsi l'utilisateur peut lancer les calculs statistiques sans avoir à quitter le tableur. Pour simple qu'elle soit, cette fonctionnalité facilite le travail du data miner. Le tableur est un des outils les plus utilisés pour la préparation des données (cf. KDNuggets Polls: Tools / Languages for Data Cleaning - 2008). En intégrant le logiciel de data mining dans cet environnement, on évite au praticien des manipulations répétitives et fastidieuses : importation, exportation, vérifier la compatibilité des formats, etc.L'installation de l'add-in sous Office XP (valable de Office 1997 à Office 2003) est décrite dans un de nos didacticiels. La procédure devient caduque dans Office 2007 et Office 2010 dans la mesure où les menus d'Excel ont été réorganisés. Pourtant la macro reste opérationnelle. Il est dommage que les utilisateurs ne puissent pas en profiter.
Dans ce didacticiel, nous détaillons la démarche à suivre pour intégrer la macro Tanagra dans les nouvelles versions d'Excel. Nous nous concentrerons sur Office 2007 dans un premier temps, nous verrons que la procédure est aussi valable pour Office 2010. Ce passage à des versions récentes d'Excel n'est absolument pas anodin. En effet, par rapport aux précédentes, elles peuvent gérer un nombre plus important de lignes et de colonnes. Nous pouvons ainsi traiter une base allant jusqu'à 1.048.575 observations (la première ligne correspond aux noms des variables) et 16.384 variables.
Nous traiterons pour notre part une base comportant 100.000 observations et 22 variables. Il s'agit d'une version du fichier "waveform" bien connu des informaticiens. Notons que ce fichier, de par le nombre de lignes, ne peut pas être manipulé par les versions antérieures d'Excel.
La procédure décrite dans ce document est également valable pour la macro complémentaire associée au logiciel SIPINA (sipina.xla).
Mots-clés : importation des données, fichier excel, macro complémentaire, add-in, add-on, xls, xlsx
Composants : VIEW DATASET
Lien : fr_Tanagra_Add_In_Excel_2007_2010.pdf
Données : wave100k.xlsx
Références:
Tutoriel Tanagra, "Les add-ins Tanagra et Sipina pour Excel 2016", juin 2016.
Tutoriel Tanagra, "Importation fichier XLS (Excel) - Macro complémentaire".
Tutoriel Tanagra, "Connexion Open Office Calc".
Tutoriel Tanagra, "Connexion Open Office Calc sous Linux".
Tutoriel Tanagra, "Connexion Excel - Sipina"
Filtrage des prédicteurs discrets
2010-06-28 (Tag:472065972861721958)
La sélection de variables est un dispositif crucial de l'apprentissage supervisé. On cherche à isoler le sous-ensemble de prédicteurs qui permet d'expliquer efficacement les valeurs de la variable cible.Trois approches sont généralement citées dans la littérature. Les méthodes " embedded " intègrent directement la sélection dans le processus d'apprentissage. Les méthodes " wrapper " optimisent explicitement un critère de précision, le plus souvent le taux d'erreur . Elles ne s'appuient en rien sur les caractéristiques de l'algorithme d'apprentissage qui est utilisé comme une boîte noire.
Enfin, troisième et dernière approche que nous étudierons dans ce didacticiel, les méthodes " filter " agissent en amont, avant la mise en œuvre de la technique d'apprentissage, et sans lien direct avec celui-ci. On présume donc qu'un processus indépendant basé sur un critère ad hoc permettrait de détecter les prédicteurs pertinents quel que soit l'algorithme d'apprentissage mis en œuvre en aval. Le pari est osé, voire hasardeux. Et pourtant, certaines expérimentations montrent que l'approche est viable même lorsque la méthode d'apprentissage utilise dans le même temps un dispositif intégré (embedded) de sélection de variables (les arbres de décision avec C4.5 par exemple ).
Nous nous intéressons aux méthodes de filtrage (filter) basées sur le principe suivant : le sous-ensemble de prédicteurs sélectionnés doit être composé de variables fortement liées avec la variable cible (pertinence) mais faiblement liées entre elles (absence de redondance). Deux idées sont à mettre en exergue dans ce schéma : (1) comment mesurer la liaison entre variables, sachant que nous nous restreignons aux cas des prédicteurs discrets ; (2) comment traduire la redondance dans un sous ensemble de variables.
Dans ce didacticiel, nous décrirons plusieurs méthodes de filtrage basées sur une mesure de corrélation pour variables discrètes. Nous les appliquerons sur un ensemble de données qui sera spécialement préparé pour mettre en évidence leur comportement. Nous évaluerons alors leurs performances en construisant le modèle bayesien naïf à partir des sous-ensembles de variables sélectionnées. Nous mènerons l'expérimentation à l'aide du logiciel Tanagra ; par la suite, nous passerons en revue les méthodes filtres implémentées dans plusieurs logiciels libres de data mining (Weka 3.6.0, Orange 2.0b, RapidMiner 4.6.0, R 2.9.2 - package FSelector).
Mots clés : méthodes de filtrage, filter approach, correlation based measure, modèle bayesien naïf, modèle d'indépendance conditionnelle
Composants : FEATURE RANKING, CFS FILTERING, MIFS FILTERING, FCBF FILTERING, MODTREE FILTERING, NAIVE BAYES, BOOTSTRAP
Lien : fr_Tanagra_Filter_Method_Discrete_Predictors.pdf
Données : vote_filter_approach.zip
Références :
Rakotomalala R., Lallich S., "Construction d'arbres de décision par optimisation", Revue Extraction des Connaissances et Apprentissage, vol. 16, n°6/2002, pp.685-703, 2002.
Tutoriel Tanagra, "Stepdisc - Analyse discriminante" ; "Stratégie wrapper pour la sélection de variables" ; "Wrapper pour la sélection de variables (suite)"
Data Mining sous R - Le package rattle
2010-06-15 (Tag:8820203845592400056)
Le père de Tanagra est aussi un fan de R. Cela peut paraître étrange et/ou contradictoire. Mais en réalité, je suis surtout un grand fan de Data Mining. Et le logiciel en est un maillon essentiel. Je passe ainsi beaucoup de temps à les disséquer, à évaluer leur comportement face aux données, et analyser leur code source lorsque cela est possible, bref, à les étudier sous toutes les coutures. Ce travail me passionne tout simplement. Je l'ai toujours fait. Avec Internet, je peux partager le fruit de mes réflexions avec d'autres utilisateurs.Dans ce tutoriel, nous présentons le package rattle pour R spécialisé dans le Data Mining. Il n'intègre pas de nouvelles méthodes d'apprentissage, il vise plutôt à rajouter une interface utilisateur graphique (GUI en anglais, " graphical user interface ") à R. Ainsi, un praticien, ignorant tout du langage de programmation R, pourra néanmoins piloter ses analyses en cliquant simplement sur des menus ou des boutons, un peu à l'image du mode " Explorer " du logiciel Weka. Rien de bien révolutionnaire donc, mais ô combien important pour les utilisateurs novices qui veulent aller à l'essentiel : traiter leurs données à l'aide de R sans avoir à investir dans l'apprentissage fastidieux de la programmation.
Pour décrire le fonctionnement de rattle, nous reprenons la trame du document de présentation publié par son auteur dans le journal de R (voir référence). Nous réaliserons la succession d'opérations suivantes : charger le fichier, le scinder en échantillons d'apprentissage et de test, définir le rôle des variables (cible vs. prédictives), réaliser quelques statistiques descriptives et graphiques pour appréhender les données, construire les modèles prédictifs sur l'échantillon d'apprentissage, les jauger sur l'échantillon test à travers les outils usuels d'évaluation (matrice de confusion, quelques courbes).
Mots clés : logiciel R, rpart, random forest, glm, arbres de décision, régression logistique, forêt aléatoire, forêts aléatoires
Lien : fr_Tanagra_Rattle_Package_for_R.pdf
Données : heart_for_rattle.txt
Références :
Togaware, "Rattle"
CRAN, "Package rattle - Graphical user interface for data mining in R"
G.J. Williams, "Rattle: A Data Mining GUI for R", in The R Journal, Vol. 1/2, pages 45--55, december 2009.
Déploiement des modèles prédictifs avec R
2010-06-11 (Tag:7393482437860158505)
L'industrialisation est l'étape ultime du data mining. Dans le cadre prédictif, l'objectif est de classer un individu à partir de sa description. Elle repose sur la possibilité de sauver, de diffuser et d'exploiter le classifieur élaboré lors de la phase d'apprentissage dans un environnement opérationnel. On parle de déploiement.Dans ce tutoriel, nous présentons une stratégie de déploiement pour R. Elle repose sur la possibilité de sauvegarder des modèles dans des fichiers binaires via le package filehash. Certes, nous aurons encore besoin du logiciel R dans la phase d'industrialisation (pour le classement de nouveaux individus), mais plusieurs aspects militent en faveur de cette stratégie : R est librement accessible et utilisable dans quelque contexte que ce soit ; il fonctionne indifféremment sous Windows, sous Linux et sous MacOS (http://www.r-project.org/); nous pouvons le piloter en mode batch c.-à-d. tout programme peut faire appel à R en sous main, lui faire exécuter une tâche, et récupérer les résultats.
Nous écrirons trois programmes distincts pour différencier les étapes. Le premier construit les modèles à partir des données d'apprentissage et les stocke dans un fichier binaire. Le second charge les modèles et les utilise pour classer les individus non étiquetés d'un second ensemble de données. Les prédictions sont sauvées dans un fichier CSV. Enfin, le troisième charge les prédictions et la vraie classe d'appartenance conservée dans un troisième fichier, il construit les matrices de confusion et calcule les taux d'erreur. Les méthodes de data mining utilisés sont : les arbres de décision (rpart) ; la régression logistique (glm) ; l'analyse discriminante linéaire (lda) ; et l'analyse discriminante sur facteurs de l'ACP (princomp + lda). Avec ce dernier cas, on montre que la stratégie reste opérationnelle même lorsque la prédiction nécessite un enchaînement d'opérations complexes.
Mots clés : logiciel R, déploiement, industrialisation, rpart, lda, pca, glm, arbres de décision, analyse discriminante, régression logistique, analyse en composantes principales, analyse discriminante sur facteurs
Lien : fr_Tanagra_Deploying_Predictive_Models_with_R.pdf
Données : pima-model-deployment.zip
Références :
R package, "Filehash : Simple key-value database"
Kdnuggets, "Data mining deployment Poll"
Traitement des très grands fichiers avec R
2010-06-02 (Tag:1040026436184776081)
Le traitement des grands fichiers est un problème récurrent du data mining. Dans ce didacticiel, nous étudierons une solution mise en place dans R sous la forme d'une libraire. Le package " filehash " permet de copier (de " dumper " carrément) tous types d'objets sur le disque, les données mais aussi les modèles. Il utilise un format de type base de données. Il présente un avantage énorme, il est possible d'utiliser les fonctions statistiques standards ou issus d'autres packages sans avoir à procéder à une quelconque adaptation. Au lieu de manipuler des data.frame en mémoire, elles travaillent sur des data.frame stockés sur le disque, de manière totalement transparente. C'est assez épatant, il faut l'avouer. Les capacités de traitement sont largement améliorées et, dans le même temps, la dégradation du temps de calcul n'est pas rédhibitoire.Néanmoins, nous constaterons que les fonctions R n'étant pas spécifiquement conçus pour l'appréhension des grands ensembles de données, lorsque nous augmentons encore nos exigences, les calculs ne sont plus possibles alors que les ressources ne sont pas entièrement utilisées. C'est un peu la limite des approches génériques. La modification des algorithmes d'apprentissage est souvent nécessaire pour exploiter au mieux les particularités du contexte. Il faudrait même aller plus loin. Pour obtenir des résultats réellement probants, il faudrait à la fois adapter les algorithmes d'apprentissage et organiser en conséquence les données sur le disque. Une solution qui conviendrait à tout type d'analyse paraît difficile, voire illusoire.
Pour évaluer la solution apportée par le package " filehash ", nous étudierons le temps de calcul et l'occupation mémoire, avec ou sans swap sur le disque, lors du calcul de statistiques descriptives, de l'induction d'un arbre de décision avec rpart du package du même nom, et de la modélisation à l'aide de l'analyse discriminante avec la fonction lda de la librairie MASS.
Nous réaliserons les mêmes opérations dans SIPINA. En effet, ce dernier propose également une solution de swap pour l'appréhension des très grandes bases de données. Nous pourrons ainsi comparer les performances des stratégies implémentées.
Mots clés : gros volumes, très grands fichiers, grandes bases de données, arbre de décision, analyse discriminante, sipina, C4.5, rpart, lda
Lien : fr_Tanagra_Dealing_Very_Large_Dataset_With_R.pdf
Données : wave2M.txt.zip
Références :
R package, "Filehash : Simple key-value database"
Tutoriel Tanagra, « Traitement de gros volumes – Comparaison de logiciels »
Tutoriel Tanagra, « Sipina - Traitement des très grands fichiers »
Yu-Sung Su's Blog, "Dealing with large dataset in R"
Tanagra dans La revue Modulad (2005)
2010-05-18 (Tag:8371380758009321634)
Toujours au chapitre nostalgie, le grand nettoyage de printemps se prête beaucoup à l'exhumation de documents anciens, j'ai retrouvé la version longue de l'article EGC publiée dans la revue Modulad (n°32 – 2005).La revue MODULAD cumule les avantages. Elle est présente depuis longtemps déjà, la pérennité est souvent un gage de qualité. Elle est en langue française. Elles ne sont pas nombreuses dans notre domaine. Et (surtout serais-je tenté de dire), elle est accessible librement en ligne. Nous pouvons donc accéder à des articles très intéressants, récents ou plus anciens puisque les archives sont disponibles. Le numéro 1 date de 1988. Les vieux documents ont été scannés.
Autre aspect très plaisant, avec la page Excel'ense, nous disposons de nombreux tutoriels décrivant l'exploitation statistique des données sous un tableur. Les exemples montrent, si besoin était, que le tableur tient très bien sa place parmi les logiciels de statistique. Nous pouvons réaliser de nombreux traitements rien qu'en utilisant les fonctions courantes.
Article : Tanagra – Revue Modulad
Référence : Rakotomalala R., "TANAGRA, une plate-forme d’expérimentation pour la fouille de données", Revue MODULAD, n°32, pp. 70-85, 2005.
Tanagra - Présentation à EGC'2005
2010-05-17 (Tag:2671668145765072463)
Au chapitre nostalgie, j'ai retrouvé le document décrivant Tanagra publié dans les actes de EGC'2005 (Paris). Il est précieux car il représente l'unique présentation du logiciel dans le cadre d'une conférence. C'est l'article que je conseille de citer lorsqu'un utilisateur souhaite faire référence à Tanagra. Il n'existe pas d'équivalent en anglais. Il faudra sûrement l'écrire un jour.Puisque l'occasion se présente, essayons un peu de situer Tanagra dans le temps. J'ai commencé à réfléchir sérieusement à un logiciel de Data Mining en janvier 2003. J'ai réalisé trois prototypes en java, c++ et delphi. Je n'étais pas très objectif néanmoins. Mon principal souci était de déterminer si l'élaboration du logiciel en delphi était pénalisant ou pas. Il est apparu au regard du cahier des charges, réaliser un logiciel à l'interface simplifiée en donnant la part belle aux calculs, que l'écrire en delphi était la solution la plus simple. Il faut dire que je programme en pascal depuis la fin des années 80.
Les idées étant singulièrement clarifiées, je me suis attelé à la programmation de Tanagra au tout début de juillet 2003. Deux mois de travail (plaisir) ininterrompu. Après, il a fallu déboguer, valider, comparer, documenter, monter le site web. En janvier 2004, le logiciel était en ligne. En janvier 2005, je le présentais à EGC suite à l'invitation du chairman de la session consacrée aux logiciels.
Il a fallu près d'un an encore pour que les tutoriels prennent vraiment de l'ampleur. Avec le recul, je me rends compte que c'est la documentation qui distingue Tanagra des autres outils libres qui, par ailleurs, possèdent d'autres atouts. A l'heure actuelle, je ne fais plus de présentation de Tanagra sans consacrer un temps important aux autres logiciels gratuits tels que R, Knime, Orange, RapidMiner et Weka.
Article : Tanagra - Egc'2005
Référence : R. Rakotomalala, "TANAGRA : un logiciel gratuit pour l'enseignement et la recherche", in 5èmes Journées d'Extraction et Gestion des Connaissances, EGC-2005, pp. 697-702, Paris, 2005.
Sipina - Présentation de l'ancienne version 2.5
2010-05-15 (Tag:6727828680654399803)
En travaillant sur la traduction du tutoriel décrivant l'implémentation des graphes d'induction à l'aide de la version 2.5 de SIPINA, je suis tombé sur un ancien document de présentation de la dite version. Le texte est assez ancien. Il est directement extrait de mon mémoire de doctorat (chapitre 11, pages 269 à 292). Il a été repris tel quel dans l'ouvrage paru en 2000 (chapitre 16, pages 391 à 414). J'imagine qu'il a été préparé en vue d'une publication dans une revue quelconque. Mais, à ma connaissance, il n'a finalement jamais été valorisé sous la forme d'un article. Ce n'est pas plus mal, nous avons l'occasion de le mettre en avant sur ce blog.Je regarde toujours avec beaucoup de nostalgie cette version 2.5 de SIPINA. Le projet a été initié par des étudiants du Master SISE (dont je faisais partie). J'ai entièrement repris le projet de l'automne 1995 jusqu'à l'été 1997, en essayant de le perfectionner au possible, en rajoutant des modules de calculs (les algorithmes d'induction d'arbres de décision tels que C4.5, CHAID; les techniques de ré-échantillonnage pour l'évaluation des résultats, bootstrap, validation croisée, etc.). Néanmoins, je n'ai jamais pu aller très loin dans le développement du logiciel. Principalement à cause d'un cahier de charges initial trop timoré qui a lourdement pesé sur sa conception; et l'utilisation de bibliothèques payantes 16 bits qui ont compromis tout passage au 32 bits.
La version recherche (ou version 3.0 et suivantes) a été conçue pour dépasser les limitations structurelles de la version 2.5. Il n'en reste pas moins que cette dernière est encore utilisée de nos jours. En effet, c'est le seul logiciel qui implémente la méthode SIPINA telle qu'elle est décrite dans littérature. Mieux même, il s'agit vraisemblablement du seul outil gratuit au monde qui propose une implémentation facilement exploitable des graphes de décision. C'est la raison pour laquelle je la mets encore en ligne sur le site web à ce jour.
Mots-clés : graphes d'induction, graphes de décision
Texte : Sipina_windows_v25.pdf
Références :
R. Rakotomalala, Graphes d’induction, Thèse de Doctorat, Université Lyon 1, 1997 (URL : https://eric.univ-lyon2.fr/ricco/publications.html).
D. Zighed, R. Rakotomalala, Graphes d’induction : Apprentissage et Data Mining, Hermès, 2000.
Traitement des classes déséquilibrées
2010-05-05 (Tag:283982405783775823)
Bien souvent, les modalités de la variable à prédire ne sont pas également représentées en apprentissage supervisé. Si l'on s'en tient aux problèmes à deux classes, les positifs, ceux que l'on cherche à identifier justement, sont rares par rapport aux négatifs : les personnes malades sont (heureusement) peu nombreux par rapport aux personnes en bonne santé ; les fraudeurs constituent une infime minorité dans la population ; etc. Dans cette configuration, en travaillant avec un échantillon représentatif et en évaluant le modèle de prédiction avec la procédure usuelle (matrice de confusion + taux d'erreur), on se rend compte que le meilleur classifieur revient à prédire systématiquement la classe majoritaire (les négatifs), ce qui nous assure le plus faible taux d'erreur.La stratégie la plus couramment admise pour surmonter cet écueil consiste à équilibrer artificiellement les données c.-à-d. mettre autant de positifs que de négatifs dans l'échantillon d'apprentissage. Sans que l'on ne sache pas très bien pourquoi, sans mettre en relation cette modification avec les caractéristiques de la technique d'apprentissage, sans en mesurer les conséquences sur le comportement du classifieur induit. Tout simplement parce que " c'est mieux ". La recette miracle en quelque sorte. En tous les cas, les ressources étant limitées, cela ne peut se faire que de deux manières : dupliquer les positifs (sur échantillonnage) ou bien n'utiliser qu'une fraction des négatifs (sous échantillonnage).
Dans ce didacticiel, nous souhaitons évaluer le comportement du sous échantillonnage lors du traitement d'une base très déséquilibrée à l'aide de la régression logistique.
Mots clés : régression logistique, classes déséquilibrées, sur et sous échantillonnage
Lien : fr_Tanagra_Imbalanced_Dataset.pdf
Données : imbalanced_dataset.xls
Références :
Wikipedia, "Régression logistique".
R. Rakotomalala, "Pratique de la régression logistique - Régression logistique binaire et polytomique".
D. Hosmer, S. Lemeshow, « Applied Logistic Regression », John Wiley &Sons, Inc, Second Edition, 2000.
Séminaire au LIESP
2010-05-01 (Tag:2195135211468350769)
Le vendredi 30 avril a été l'occasion d'un très agréable séminaire au LIESP (http://liesp.insa-lyon.fr/v2/?q=fr/acc). Le contenu est plus ou moins identique à la présentation réalisée le mois précédent à Rennes. A la différence que j'avais en face de moi des chercheurs qui travaillent dans le domaine du Data Mining.Les discussions se sont donc plutôt orientées vers l'utilisation des différents logiciels libres/gratuits en recherche. J'ai appris entres autres que, s'agissant du Data Mining, Matlab a un positionnement très proche de celui de R, avec notamment le système des plugins. J'essaierai de voir cela dans un avenir proche.
Dans la partie bilan : pour les 4 premiers mois de l'année 2010 (1er janvier au 30 avril), mes sites ont enregistré 83.219 visites, soit 693 visites par jour.
Titre : Tanagra, un logiciel gratuit pour l'enseignement et la recherche
Résumé : Tanagra est un logiciel de data mining gratuit, open source, à destination des étudiants, des enseignants et des chercheurs. Il intègre à l'heure actuelle (version 1.4.36 - Mars 2010) près de 170 techniques d'exploration des données. Elles couvrent la statistique, l'analyse de données, l'économétrie, la reconnaissance de formes. Au-delà du logiciel, le site web Tanagra est aussi le carrefour d'une documentation très importante, sous la forme d'ouvrages gratuits (free e-books) et de tutoriels en français et en anglais. La convergence de ces éléments a beaucoup contribué à la large diffusion de notre travail. En termes quantitatifs, notre site, regroupant les supports de cours, les tutoriels et le logiciel, a connu 520 visites par jour sur l'année 2009, à comparer avec les 349 visites journalières de 2008.
Dans notre exposé, nous décrivons les motivations et les contraintes qui nous ont conduit à définir un cahier de charges suffisamment précis pour l'élaboration du logiciel. Nous essayons surtout de délimiter son champ d'application et les utilisateurs visés. Les choix conditionnent la viabilité du projet dans la durée. En effet, il y a la création de la première version, toujours exaltante, puis il faut anticiper sur son évolution dans le temps. Notre propre expérience montre que les solutions organisationnelles et techniques sont très importantes dans cette perspective.
Mais Tanagra n'est pas le seul logiciel de data mining libre, loin de là. Dans une deuxième partie, nous présenterons les autres outils, très diffusés dans communauté: R, Weka, Knime, Orange, RapidMiner. Ce sont autant d'alternatives très intéressantes pour le traitement des données. Un des facteurs de succès de notre site d'ailleurs est d'avoir réalisé un effort considérable de documentation pour ces logiciels. Nous les présentons rapidement en essayant de pointer leurs spécificités respectives.
Enfin, dans une troisième et dernière partie, pour donner un tour concret à notre exposé, nous réaliserons quelques traitements types (apprentissage supervisé, induction de règles d'association) à l'aide de ces différents logiciels. En réalisant les mêmes traitements sur les mêmes données, nous sommes à même de situer ce qui rapproche ou ce qui différencie ces outils. Nous constaterons d'ailleurs que, finalement, ils sont relativement similaires. Les différences se situent essentiellement sur le mode de présentation et la terminologie utilisée selon l'origine communautaire du logiciel (statistique, informatique, reconnaissance de formes).
Mots-clés : data mining, logiciel gratuit, logiciel libre, tanagra, r, weka, knime, orange, rapidminer
Diaporama : voir diapos en version animée.
Tanagra et autres logiciels gratuits
2010-03-26 (Tag:1875280330850382083)
Un très sympathique et chaleureux séminaire au sein du Laboratoire de Mathématiques Appliquées de l'AgroCampus Ouest de Rennes (http://www.agrocampus-ouest.fr/math/) a été l'occasion de faire un bilan sur l'évolution de Tanagra ces dernières années. En termes quantitatifs, notre site, regroupant les supports de cours, les tutoriels et le logiciel, a connu 520 visites par jour sur l'année 2009, à comparer avec les 349 visites journalières de 2008. Les visiteurs sont pour moitié francophones, les accès se concentrent avant tout sur les pages consacrées à la documentation.Mais, au-delà de la simple présentation de Tanagra, j'ai surtout tenté de positionner les principaux logiciels libres largement reconnus dans notre communauté : Orange, Knime, Rapid-Miner, Weka ; mais aussi le logiciel R, plutôt d'obédience statistique, mais qui fait une percée spectaculaire auprès des " Data Miner ". Des démonstrations sur des données réalistes ont permis de montrer le mode opératoire des différents outils.
Au final, on se rend compte qu'ils répondent peu ou prou à des cahiers des charges relativement similaires. Il est illusoire de penser que tel ou tel logiciel serait systématiquement meilleur que les autres quel que soit le domaine abordé. Le plus important pour l'utilisateur est de bien cerner les spécificités de son étude (objectifs, caractéristiques des données, etc.) pour choisir en pleine conscience l'outil le mieux adapté. C'est une des raisons pour lesquelles j'essaie, et j'essaierai toujours, de comparer objectivement les logiciels lorsque que je montre la mise en œuvre des techniques exploratoires dans mes tutoriels. Après, le choix des armes appartient à l'utilisateur lorsqu'il aura à affronter ses propres données. Et c'est très bien ainsi...
Résumé du séminaire : Résumé
Slides du séminaire : Présentation
Le classifieur Bayesien Naïf revisité
2010-03-23 (Tag:8055745706887032744)
Le classifieur bayesien naïf est une méthode d'apprentissage supervisé qui repose sur une hypothèse simplificatrice forte : les descripteurs (Xj) sont deux à deux indépendants conditionnellement aux valeurs de la variable à prédire (Y) . Pourtant, malgré cela, il se révèle robuste et efficace. Ses performances sont comparables aux autres techniques d'apprentissage. Diverses raisons sont avancées dans la littérature. Dans ce document, nous mettrons en avant une explication basée sur le biais de représentation. Le modèle d'indépendance conditionnel est ni plus ni moins qu'un classifieur linéaire, au même titre que l'analyse discriminante linéaire ou la régression logistique. Seul diffère le mode d'estimation des coefficients de la fonction de classement.Dans la première partie de ce tutoriel, nous présentons tout d'abord brièvement les aspects théoriques relatifs à la méthode. Puis, nous l'implémentons à l'aide du logiciel Tanagra 1.4.36. Nous comparerons les résultats obtenus (les coefficients de l'hyperplan séparateur) avec ceux de la régression logistique, de l'analyse discriminante et d'un SVM (support vector machine) linéaire. Nous constaterons qu'ils sont étonnamment cohérents, expliquant ainsi la bonne tenue du classifieur bayesien naïf dans la grande majorité des situations.
Dans la seconde partie, nous montrons la mise en œuvre de la technique dans les plusieurs logiciels libres tels que Weka 3.6.0, R 2.9.2, Knime 2.1.1, Orange 2.0b et RapidMiner 4.6.0. Nous nous attacherons avant tout à lire correctement les résultats. Un des aspects qui dessert souvent la méthode auprès des praticiens du Data Mining.
Mots clés : classifieur bayesien naïf, séparateur linéaire, analyse discriminante, régression logistique, support vector machine
Lien : fr_Tanagra_Naive_Bayes_Classifier_Explained.pdf
Données : heart_for_naive_bayes.zip
Références :
Wikipedia, "Naive bayes classifier".
T. Mitchell, "Generative and Discriminative Classifiers: Naive Bayes and Logistic Regression", in Machine Learning, Chapter 1, 2005.
Tanagra - Version 1.4.36
2010-03-23 (Tag:5181771837268855329)
ReliefF est un composant de sélection automatique de variables pour l'apprentissage supervisé. Il sait traiter les descripteurs continus ou discrets. On peut le placer devant n'importe quelle méthode supervisée.Naive Bayes a été modifié. Il affiche maintenant un modèle de prédiction sous une forme explicite, facile à déployer. Un tutoriel accompagne cette mise à jour.
Discrétisation - Comparaison de logiciels
2010-02-03 (Tag:8866661242442302399)
La discrétisation consiste à découper une variable quantitative en intervalles. Il s'agit d'une opération de recodage. De quantitative, la variable est transformée en qualitative ordinale. Nous devons répondre à deux questions pour mener à bien l'opération : (1) comment déterminer le nombre d'intervalles à produire ; (2) comment calculer les bornes de discrétisation à partir des données. La résolution ne se fait pas forcément dans cet ordre.J'ai coutume de dire que le découpage d'expert est le meilleur possible. En effet, lui seul peut fournir une discrétisation raisonnée tenant compte des connaissances du domaine, tenant compte de tout un tas de contraintes dont on n'a pas idée si on se base uniquement sur les données, et en adéquation avec les objectifs de l'étude. Malheureusement, la démarche s'avère délicate parce que : d'une part, les connaissances ne sont pas toujours au rendez vous ou sont difficilement quantifiables ; d'autre part, elle n'est pas automatisable, le traitement d'une base comportant des centaines de variables se révèle rapidement ingérable. Souvent donc, nous sommes obligés de nous baser uniquement sur les données pour produire un découpage qui soit un tant soit peu pertinent.
Discrétisation comme prétraitement des variables en apprentissage supervisé. Tout d'abord, il faut situer le canevas dans lequel nous réalisons l'opération. Selon le cas, il est évident que la démarche et les critères utilisés ne seront pas les mêmes. Dans ce didacticiel, nous nous plaçons dans le cadre de l'apprentissage supervisé. Les variables quantitatives sont préalablement recodées avant d'être présentées à un algorithme d'apprentissage supervisé. La variable à prédire, elle, est naturellement qualitative. Lors de la discrétisation, il est par conséquent souhaitable que les groupes soient le plus purs possibles c.-à-d. les individus situés dans le même intervalle doivent appartenir majoritairement à l'une des modalités de la variable à prédire.
Dans ce didacticiel, nous comparerons le comportement des techniques supervisées et non supervisées implémentées dans les logiciels Tanagra 1.4.35, Sipina 3.3, R 2.9.2 (package dprep), Weka 3.6.0, Knime 2.1.1, Orange 2.0b et RapidMiner 4.6.0. Comme nous pouvons le constater, tout logiciel de Data Mining se doit de proposer ce type d'outils. Nous mettrons en avant le paramétrage et la lecture des résultats.
Mots clés : mdlpc, discrétisation supervisée, discrétisation non supervisée, intervalles de largeurs égales, intervalles de fréquences égales
Composants : MDLPC, Supervised Learning, Decision List
Lien : fr_Tanagra_Discretization_for_Supervised_Learning.pdf
Données : data-discretization.arff
Références :
F. Muhlenbach, R. Rakotomalala, « Discretization of Continuous Attributes », in Encyclopedia of Data Warehousing and Mining, John Wang (Ed.), pp. 397-402, 2005 (http://hal.archives-ouvertes.fr/hal-00383757/fr/).
R. Rakotomalala, « Graphes d’Induction », Thèse de Doctorat Lyon 1, 1997 ; chapitre 9, pp.209-244.
Tutoriel Tanagra, "Discrétisation contextuelle - La méthode MDLPC"
"Wrapper" pour la sélection de variables (suite)
2010-01-31 (Tag:2328986384657364965)
Ce didacticiel fait suite à celui consacré à la stratégie wrapper pour la sélection de variables en apprentissage supervisé. Nous y analysions le comportement de Sipina, puis nous avions programmé une procédure ad hoc dans R. Dans ce didacticiel, nous étudions la mise en oeuvre de la méthode dans les logiciels Knime 2.1.1, Weka 3.6.0 et RapidMiner 4.6.La démarche est la suivante : (1) utilisation du fichier d'apprentissage pour la sélection des variables les plus performantes pour le classement ; (2) création du modèle sur les descripteurs sélectionnés ; (3) évaluation des performances sur un fichier test contenant toutes les variables candidates.
Ce troisième point est très important. Nous ne pouvons pas connaître initialement les variables prédictives qui seront finalement retenues. Il ne faut pas que nous ayons à préparer manuellement le fichier test en y intégrant uniquement celles qui auront été choisies par la procédure wrapper. C'est une condition essentielle pour que la démarche soit automatisable. En effet, dans le cas contraire, chaque modification de paramétrage dans la procédure wrapper aboutissant à autre sous-ensemble de descripteurs nous obligerait à modifier manuellement le fichier test. Ce qui s'avère très rapidement fastidieux.
A la lumière de ce cahier des charges, il est apparu que seul Knime a permis de mettre en place le dispositif complet. Avec les autres logiciels, il est certes possible de sélectionner les variables pertinentes sur le fichier d'apprentissage. Je n'ai pas pu en revanche (ou je n'ai pas su) réaliser simplement le déploiement sur un fichier test comprenant la totalité des variables candidates.
La méthode d'apprentissage supervisé utilisée est le modèle d'indépendance conditionnel, le modèle bayesien naïf selon la terminologie utilisée en apprentissage automatique .
Mots clés : sélection de variables, apprentissage supervisé, classifieur bayesien naïf, wrapper
Lien : fr_Tanagra_Wrapper_Continued.pdf
Données : mushroom.wrapper.arff.zip
Références :
JMLR Special Issue on Variable and Feature Selection - 2003
R Kohavi, G. John, « The wrapper approach », 1997.
Wikipedia, "Naive bayes classifier".
Induction de règles floues avec Knime
2010-01-21 (Tag:331178814753287043)
Ce didacticiel fait suite à celui consacré à l'induction des règles prédictives. Je n'avais pas intégré Knime dans le comparatif car il proposait une technique que je ne connaissais pas bien, l'induction de règles floues, et demandait une préparation particulière de variables qui me paraissait bien étrange. Il fallait notamment que l'attribut cible soit numérique, ce qui paraît assez incongru dans le cadre de l'apprentissage supervisé. Comme il me fallait avancer, j'ai préféré reporter l'étude du logiciel Knime à plus tard (c.-à-d. maintenant) en lui dédiant spécifiquement un didacticiel.Parmi les logiciels libres (ou accessibles gratuitement) fonctionnant sous forme de diagramme de traitements, Knime est certainement l'un des plus prometteurs, un des rares à pouvoir tailler des croupières aux équivalents commerciaux. Il y a dans ce logiciel une rigueur de conception et un souci du détail qui ne laisse pas indifférent : il est par exemple possible, devant la multitude d'outils disponibles, de créer une section des méthodes favorites ; une autre palette permet également de retrouver les composants les plus fréquemment utilisés ; la documentation est accessible de manière permanente dans la partie droite de la fenêtre principale ; etc. C'est aussi un des seuls logiciels libres à faire des efforts particuliers pour ce qui est de l'accès aux bases de données et la préparation des variables. J'avoue que je prends un réel plaisir à l'utiliser et à l'étudier de manière approfondie.
Concernant l'induction de règles prédictives, Knime (version 2.1.1) implémente l'induction des règles floues. Les articles présentant la méthode sont accessibles en ligne , . Les lecteurs intéressés par les fondements théoriques de la méthode pourront s'y reporter. Pour ma part, dans ce didacticiel, je m'attacherais avant tout à décrire la mise en œuvre de la méthode en détaillant le pourquoi et comment de la préparation des variables préalable à l'induction, et le mode de lecture du modèle prédictif. Pour avoir un point de repère, nous comparerons les résultats avec ceux fournis par la méthode d'induction de règles proposée par Tanagra.
Mots clés : induction de règles prédictives, logique floue
Composants : SAMPLING, RULE INDUCTION, TEST
Lien : fr_Tanagra_Induction_Regles_Floues_Knime.pdf
Données : iris2D.txt
Références :
M.R. Berthold, « Mixed fuzzy rule formation », International Journal of Approximate Reasonning, 32, pp. 67-84, 2003.
T.R. Gabriel, M.R. Berthold, « Influence of fuzzy norms and other heuristics on mixed fuzzy rule formation », International Journal of Approximate Reasoning, 35, pp.195-202, 2004.
Tanagra - Version 1.4.35
2010-01-19 (Tag:8187163999650392277)
CTP. Modification de la méthode de détection de la bonne taille de l'arbre
dans le composant " Clustering Tree " avec post-élagage (CTP). Elle s'appuie à
la fois sur l'angle entre chaque demi-droite à chaque point de la courbe de
décroissante de l'inertie intra-classe sur l'échantillon d'expansion (growing
set) et la décroissance du même indicateur calculé sur l'échantillon d'élagage
(pruning set). Par rapport à l'implémentation précédente, il en résulte un choix
de partitionnement avec un nombre plus faible de clusters.
Regression Tree. La modification précédente est répercutée sur le composant
arbre de régression qui en est une version univariée.
C-RT Regression Tree. Un nouveau composant d'arbre de régression a été
introduit. Il implémente fidèlement la technique décrite dans l'ouvrage de
Breiman et al. (1984), notamment la partie post-élagage avec la règle de l'écart
type (1-SE Rule) (chapitre 8, en particulier p. 226 concernant la formule de la
variance du MSE).
C-RT. L'affichage de la méthode d'induction d'arbre de décision C-RT a été
complété. En s'appuyant sur la dernière colonne du tableau d'élagage, il devient
plus aisé de choisir le paramètre " x " (dans x-SE Rule) pour définir
arbitrairement la taille de l'arbre élagué.
Des tutoriels viendront décrire ces différentes modifications.
Arbres de décision interactifs avec SPAD
2010-01-17 (Tag:5575939253219063845)
Dans le domaine du Data Mining, les logiciels libres et commerciaux ne s'adressent pas au même public. Ils ne répondent pas aux mêmes besoins. Les premiers sont plutôt destinés aux étudiants et aux chercheurs. Leur but est de mettre à leur disposition un grand nombre de méthodes, à des fins pédagogiques, ou à des fins d'expérimentation. L'utilisateur doit pouvoir monter simplement des comparaisons à grande échelle, pour comprendre le comportement des méthodes, pour évaluer leurs performances, etc. Le logiciel R (http://www.r-project.org/) en est certainement le meilleur représentant. Avec le système des packages, il est extensible à l'infini. Le dispositif est maintenant bien accepté, un grand nombre de chercheurs viennent enrichir la bibliothèque de calcul au fil du temps, signe que le mécanisme a été très bien conçu.Les outils commerciaux s'adressent plutôt aux praticiens du Data Mining, y compris les chercheurs d'autres domaines. Leur objectif est de pouvoir mener à bien une étude intégrant le cycle complet de la fouille de données, partant de l'accès aux fichiers jusqu'au déploiement et la production de rapports. Dans ce cas, l'outil doit surtout leur faciliter le travail en prenant en charge, le plus simplement possible, un grand nombre de tâches répétitives et fastidieuses, comme l'accès aux données, leur préparation, la production de tableaux et graphiques pour les rapports, l'industrialisation des résultats, etc.
La frontière n'est pas aussi tranchée. Bien d'outils issus du monde universitaire tentent de franchir le Rubicon en intégrant des fonctionnalités qui intéresseraient plutôt le monde industriel (ex. déploiement des modèles avec PMML - http://www.dmg.org/). A l'inverse, des logiciels commerciaux s'approprient les formidables bibliothèques de calculs que proposent les outils libres, notamment ceux de R (ex. SAS / IML Studio, SPSS PASW ou SPAD).
Dans ce didacticiel, nous montrons la mise en œuvre des Arbres de Décision Interactifs (IDT - Interactive Decision Tree) de SPAD 7.0 sur un jeu de données constitué d'un classeur Excel décomposé en 3 feuilles : (1) on doit construire un arbre de décision à partir des données d'apprentissage ; (2) appliquer le modèle sur les données de la seconde feuille, nous adjoignons ainsi une nouvelle colonne " prédiction " aux données ; (3) vérifier la qualité de la prédiction en la confrontant à la vraie valeur de la variable cible située dans la troisième feuille du classeur.
Bien sûr, toutes ces opérations sont réalisables avec la grande majorité des logiciels libres. Un utilisateur un tant soit peu habile vous programme cela en trois coups de cuiller à pots sous R. Nous y reviendrons dans la section 4. L'intérêt ici est de montrer qu'un utilisateur novice, réfractaire à l'informatique, peut les enchaîner très facilement avec ce type d'outil, en prenant comme source de données un classeur Excel.
Mots clés : IDT, interactive decision tree, arbres de décision, induction interactive, SPAD, SIPINA, logiciel R
Lien : fr_Tanagra_Arbres_IDT_Spad.pdf
Données : pima-arbre-spad.zip
Références :
(Mise à jour) Tutoriel Tanagra, "Nouveaux arbres interactifs dans SPAD 8", Août 2014.
Logiciel SPAD, http://www.spad.eu/
R. Rakotomalala, "Arbres de décision", Revue Modulad, n°33, 2005.
Induction de Règles Prédictives
2009-11-22 (Tag:403439772876810496)
L’induction de règles tient une place privilégiée dans le Data Mining. En effet, elle fournit un modèle prédictif facilement interprétable, on sait lire sans connaissances statistiques préalables un modèle de prédiction de type « Si condition Alors Conclusion » (ex. Si Compte Client à découvert Alors Client défaillant pour remboursement des crédits ») ; les règles peuvent être facilement implémentées dans les systèmes d’information (ex. traduction d’une règle en requête SQL).Nous nous plaçons dans le cadre de l’apprentissage supervisé dans ce didacticiel. Parmi les méthodes d’induction des règles prédictives, les approches « separate-and-conquer » ont monopolisé les conférences d’apprentissage automatique dans les années 90. Curieusement, le souffle semble un peu retombé aujourd’hui. Plus ennuyeux encore, elles sont peu implémentées, voire inexistantes, dans les logiciels commerciaux. Il faut se tourner vers les logiciels libres issues de l’apprentissage automatique (la communauté « machine learning ») pour les trouver. Pourtant, elles présentent plusieurs atouts par rapport aux autres techniques.
Dans ce didacticiel, une fois n’est pas coutume, nous décrivons dans un premier temps les techniques « separate-and-conquer » pour l’induction de règles. Je trouve en effet que ces méthodes sont peu connues des praticiens du Data Mining et, de ce fait, peu utilisées. Pourtant elles sont souvent performantes. Elles constituent une alternative tout à fait valable aux arbres de décision. Nous mettrons l’accent sur les approches par spécialisation, par opposition aux approches par généralisation, plus lentes et quasi-introuvables dans les logiciels.
Dans un second temps, nous montrons la mise en œuvre des différentes variantes implémentées dans les logiciels de Data Mining. Nous utiliserons Tanagra 1.4.34, Sipina Recherche 3.3, Weka 3.6.0, R 2.9.2 avec le package RWeka, RapidMiner 4.6, et Orange 2.0b.
Mots clés : induction de règles, règles prédictives, listes de décision, base de connaissances, CN2, arbres de décision
Composants : SAMPLING, DECISION LIST, RULE INDUCTION, TEST
Lien : fr_Tanagra_Rule_Induction.pdf
Données : life_insurance.zip
Références :
J. Furnkranz, "Separate-and-conquer Rule Learning", Artificial Intelligence Review, Volume 13, Issue 1, pages 3-54, 1999.
P. Clark, T. Niblett, "The CN2 Rule Induction Algorithm", Machine Learning, 3(4):261-283, 1989.
P. Clark, R. Boswell, "Rule Induction with CN2: Some recent improvements", Machine Learning - EWSL-91, pages 151-163, Springer Verlag, 1991.
Tanagra - Version 1.4.34
2009-11-22 (Tag:5654786334398657601)
Un composant d'induction de règles prédictives (RULE INDUCTION) a été ajouté dans la section " Apprentissage Supervisé ". Son utilisation est décrite dans un didacticiel accessible en ligne.
Le composant DECISION LIST a été amélioré, nous avons modifié le test réalisé lors de la procédure de pré-élagage. La formule est décrite dans le même didacticiel que ci-dessus.
Les composants SAMPLING et STRATIFIED SAMPLING (onglet Instance Selection) ont été légèrement modifiés. Il est maintenant possible de contrôler le générateur de nombres pseudo aléatoires en fixant nous même la valeur de départ de la " graine ".
Suite à une indication de Anne Viallefont, le calcul des degrés de liberté dans les tests sur tableaux de contingence est maintenant plus générique. En effet, le calcul était erroné lorsque la base était préalablement filtrée et que certaines marges (ligne ou colonne) contenaient un effectif égal à zéro. Merci Anne pour ces indications. De manière plus générale, merci à tous ceux qui m'envoient des commentaires. Programmer a toujours été pour moi une sorte de loisir. Le vrai boulot commence lorsqu'il faut contrôler les résultats, les confronter avec les références disponibles, les croiser avec les autres logiciels de Data Mining, libres ou non, comprendre les éventuelles différences, etc. A ce stade, votre aide m'est très précieuse.
Sipina – Traitement des très grands fichiers
2009-10-21 (Tag:7061147516139790117)
Triturer les très grands fichiers est le fantasme ultime du data miner. On veut pouvoir traiter de très grandes bases dans l’espoir d’y déceler des informations cachées. Malheureusement, rares sont les logiciels libres qui peuvent les appréhender. Tout simplement parce que la quasi-totalité d’entre eux chargent les données en mémoire. Knime semble faire exception. Il sait swapper une partie des données sur le disque. Mais j’avoue ne pas savoir comment exploiter pleinement cet atout (paramétrer ou contrôler l’encombrement mémoire en fonction des données et des algorithmes utilisés par exemple).Cette rareté n’est guère étonnante. En effet, l’affaire est compliquée. Il ne s’agit pas seulement de copier des informations sur le disque, il faut pouvoir y accéder efficacement compte tenu de la méthode d’apprentissage mise en œuvre. Deux aspects s’entremêlent : (1) comment organiser les données sur le disque ; (2) est-il possible de proposer un système de cache afin d’éviter d’avoir à accéder au disque à chaque fois qu’il faut traiter un individu ou lire la valeur d’une variable.
Dans ce didacticiel, nous montrons comment exploiter une solution que j’ai naguère implémentée dans Sipina. Elle n’a jamais été valorisée ni documentée. J’avoue l’avoir totalement oubliée jusqu’à ce que je la redécouvre par hasard en préparant le tutoriel sur l’échantillonnage dans les arbres. Nous montrons qu’il est possible de traiter, en disposant de toutes les fonctionnalités interactives, un fichier comportant 41 variables et (surtout) 9.634.198 observations lorsque nous activons cette option.
Pour apprécier pleinement la solution proposée par Sipina, nous ferons le parallèle avec le comportement des logiciels Tanagra 1.4.33 et Knime 2.0.3 face à un tel fichier.
Mots clés : gros volumes, très grands fichiers, grandes bases de données, arbre de décision, échantillonnage, sipina, knime
Composants : ID3
Lien : fr_Sipina_Large_Dataset.pdf
Données : twice-kdd-cup-discretized-descriptors.zip
Références :
Tutoriel Tanagra, « Traitement de gros volumes – Comparaison de logiciels ».
Tutoriel Tanagra, « Sipina – Echantillonnage dans les arbres »
Sipina - Echantillonnage dans les arbres
2009-10-18 (Tag:4702956821695614867)
Lors de l’induction d’un arbre de décision, l’algorithme doit détecter la meilleure variable de segmentation pour chaque nœud que l’on souhaite partitionner. L’opération peut prendre du temps si le nombre d’observations est très élevé. Ceci d’autant plus que les variables candidates sont continues, il faut trouver la borne de discrétisation optimale.Le logiciel Sipina introduit une option d’échantillonnage local dans tous les algorithmes d’induction d’arbres qu’il propose. L’idée est la suivante : sur chaque sommet, plutôt que de travailler sur la totalité des observations présentes pour choisir la variable de segmentation, il réalise les opérations sur un échantillon. Bien entendu, lorsque le nombre d’observations disponibles sur le sommet est plus faible que la taille d’échantillon demandée, il n’y a plus lieu de procéder à un échantillonnage, Sipina utilise toutes les observations. Cela arrive dans les parties bases de l’arbre lorsqu’il est particulièrement profond. Nous avions évoqué cette idée dans un de nos anciens posts (Echantillonnage dans les arbres de décision), nous la mettons en œuvre dans ce didacticiel.
Nous manipulons un fichier comportant 21 descripteurs et 2.000.000 d’observations, dont une moitié est utilisée pour construire l’arbre, l’autre pour son évaluation. Nous constaterons que, dans certaines circonstances, travailler sur un échantillon dans les nœuds permet de réduire le temps de calculs (divisé par 30 !) tout en préservant les performances en classement.
Nous comparerons les temps de calcul avec ceux de Tanagra où une autre stratégie a été mise en place pour accélérer les traitements.
Mots clés : arbre de décision, échantillonnage, sipina, apprentissage, test, traitement des grandes bases de données, gros fichier
Composants : SAMPLING, ID3, TEST
Lien : fr_Sipina_Sampling.pdf
Données : wave2M.zip
Références :
J.H. Chauchat, R. Rakotomalala, « A new sampling strategy for building decision trees from large databases », Proc. of IFCS-2000, pp. 199-204, 2000.
Sipina - Traitement des données manquantes
2009-10-14 (Tag:6442841879290818448)
L’appréhension des données manquantes est un problème difficile. La gestion informatique en elle-même ne pose pas de problème, il suffit de signaler la valeur manquante par un code spécifique. En revanche, son traitement avant ou durant l’analyse des données est très compliqué.Il faut prendre en considération deux aspects : (1) la nature de la valeur manquante (complètement aléatoire, partiellement aléatoire, non aléatoire) ; (2) la technique statistique que nous mettons en œuvre par la suite, en effet, certaines méthodes de traitement des données manquantes sont plus ou moins adaptées selon les techniques statistiques que nous utilisons.
L’objectif de ce tutoriel est de montrer la mise en œuvre des techniques implémentées dans le logiciel SIPINA et d’observer les conséquences des choix sur l’induction des arbres de décision avec la méthode C4.5 (Quinlan, 1993).
Mots clés : valeur manquante, donnée manquante, missing data, sipina, C4.5
Lien : fr_Sipina_Missing_Data.pdf
Données : ronflement_missing_data.zip
Références :
P.D. Allison, « Missing Data », in Quantitative Applications in the Social Sciences Series n°136, Sage University Paper, 2002.
J. Bernier, D. Haziza, K. Nobrega, P. Whitridge, « Handling Missing Data – Case Study », Statistical Society of Canada.
Evaluation des classifieurs - Quelques courbes
2009-10-07 (Tag:6907751194906372654)
L’évaluation des classifieurs est une étape incontournable de l’apprentissage supervisé. Nous avons construit un modèle de prédiction, nous devons en mesurer les. D’un côté, nous avons la matrice de confusion et les indicateurs afférents, très populaire dans la recherche en apprentissage automatique (ah… les fameux grands tableaux avec des moyennes de taux d’erreur sur des bases de données qui n’ont rien à voir entre elles…) ; de l’autre, dans les applications, on privilégie les courbes qui semblent mystérieuses si l’on n’est pas du domaine (courbe ROC en épidémiologie, entre autres ; courbe de gain en marketing ; courbe rappel – précision en recherche d’information).Dans ce didacticiel, nous montrons dans un premier temps comment construire ces courbes en détaillant les calculs dans un tableur. Puis, dans un deuxième temps, nous utilisons les logiciels Tanagra 1.4.33 et R 2.9.2 pour les obtenir. Nous comparerons les performances de la régression logistique et des SVM (support vector machine, noyau RBF) sur notre fichier de données.
Mots-clés : courbe ROC, courbe de gain, courbe lift, courbe rappel précision, échantillon d'apprentissage, échantillon test, régression logistique, svm, noyau RBF, librairie libsvm, logiciel R, glm, package e1071Composants : DISCRETE SELECT EXAMPLES, BINARY LOGISTIC REGRESSION, SCORING, C-SVC, ROC CURVE, LIFT CURVE, PRECISION-RECALL CURVE
Lien : fr_Tanagra_Spv_Learning_Curves.pdf
Données : heart_disease_for_curves.zip
Diagnostic de la régression logistique
2009-10-03 (Tag:43625421723724139)
Ce tutoriel décrit la mise en œuvre des outils d’évaluation et de diagnostic de la régression logistique binaire, disponibles depuis la version 1.4.33 de Tanagra. Les techniques et les formules afférentes sont présentées dans le fascicule de cours que nous avons mis en ligne récemment (voir références). Il serait intéressant de le charger également afin de pouvoir s’y référer lorsque nous décrivons les résultats.Nous traitons un problème de crédit scoring. Nous cherchons à déterminer à l’aide de la régression logistique les facteurs explicatifs de l’accord ou du refus d’une demande de crédit de clients auprès d’un établissement bancaire.
Nous utiliserons Tanagra 1.4.33 dans un premier temps. Dans un deuxième temps, nous essaierons de reproduire les mêmes calculs à l’aide du Logiciel R 2.9.1 [procédure glm()].
Mots-clés : régréssion logistique, analyse des résidus, détection des points atypiques et points influents, résidus de pearson, résidus déviance, levier, distance de cook, dfbeta, dfbetas, test de Hosmer - Lemeshow, diagramme de fiabilité, reliability diagram, calibration plot, logiciel R, glm()
Composants : BINARY LOGISTIC REGRESSION, HOSMER LEMESHOW TEST, RELIABILITY DIAGRAM, LOGISTIC REGRESSION RESIDUALS
Lien : fr_Tanagra_Logistic_Regression_Diagnostics.pdf
Données : logistic_regression_diagnostics.zip
Références :
R. Rakotomalala, "Pratique de la régression logistique - Régression logistique binaire et polytomique".
D. Hosmer, S. Lemeshow, « Applied Logistic Regression », John Wiley &Sons, Inc, Second Edition, 2000.
Tanagra - Version 1.4.33
2009-10-03 (Tag:7233864721815192040)
Cette version accompagne la sortie du fascicule du cours consacré à la régression logistique (" Pratique de la Régression Logistique - Régression logistique binaire et polytomique " - Septembre 2009). Plusieurs techniques d'évaluation et de diagnostic de la régression logistique ont été développées, l'une d'entre elles (reliability diagram) peut s'appliquer à toute méthode supervisée :
1. La matrice de variance covariance des coefficients.
2. Test de Hosmer et Lemeshow
3. Diagramme de fiabilité (reliability diagram ou calibration plot en anglais)
4. Analyse des résidus, détection des points atypiques et/ou influents (résidus de pearson, résidus déviance, dfichisq, difdev, levier, distance de Cook, dfbeta, dfbetas)
Un tutoriel décrivant la mise en œuvre de ces outils sera mis en ligne très prochainement.
Etude des dépendances - Variables qualitatives
2009-09-30 (Tag:6458039922036304079)
Ce document décrit quelques mesures statistiques destinées à quantifier et tester la liaison entre 2 variables qualitatives. Elles exploitent le tableau de contingence formé à partir des variables. Le domaine étant très vaste et les mesures innombrables, nous ne pourrons certainement pas prétendre à l'exhaustivité. Nous mettrons l'accent sur l'interprétation, les formules associées et la lecture pratique des résultats.Nous nous concentrons essentiellement sur la dépendance entre variables nominales. Le traitement des variables ordinales fera l'objet d'une partie distincte (Partie IV).
Mots-clés : tableau de contingence, khi-2, mesures PRE (proportional reduction in error), odds et odds-ratio, coefficient de concordance, mesures d'association, associations ordinales
Techniques décrites : statistique du khi-2, test d'indépendance du khi-2, contributions au khi-2, t de Tschuprow, v de Cramer, lambda de Goodman et Kruskal, tau de Goodman et Kruskal, U de Theil, coefficient phi, correction de continuité, Q de Yule, kappa de Cohen, kappa de Fleiss, gamma de Goodman et Kruskal, tau-b de Kendall, tau-c de Kendall, d de Sommers
Ouvrage : Etude des dépendances - Variables qualitatives - Tableau de contingence et mesures d'association
Analyse de corrélation
2009-09-26 (Tag:2768771575869272562)
Ce document décrit les méthodes statistiques destinées à quantifier et tester la liaison entre 2 variables quantitatives : on parle d’analyse de corrélation.Il est subdivisé en 2 grandes parties. La première est consacrée à la corrélation brute : principalement le coefficient de corrélation de Pearson, mais aussi les coefficients non paramétriques de Spearman et Kendall. La seconde aborde la question des corrélations partielles et semi-partielles.
Pour chaque indicateur étudié, nous présentons la mise en place du test de significativité, et éventuellement le calcul des intervalles de confiance.
Mots-clés : corrélation brute, corrélation partielle, corrélation semi-partielle
Techniques décrites : r de Pearson, rho de Spearman, tau de Kendall, corrélation partielle d’ordre 1, corrélation partielle d’ordre p, rho de Spearman partiel, corrélation semi-partielle d’ordre 1 et d’odre p
Ouvrage : Analyse de corrélation – Etude des dépendances, Variables quantitatives
Probabilités et Statistique - Note de cours
2009-09-20 (Tag:2757994245275397437)
Ce document est un support de cours pour les enseignements des probabilités et de la statistique. Il couvre l'analyse combinatoire, le calcul des probabilités, les lois de probabilités d'usage courant et les tests d'adéquation à une loi.Il correspond approximativement aux enseignements en L2 de la filière Sciences Économiques et Gestion, Administration Économique et Sociale (AES).
Chapitres : Eléments d’analyse combinatoire, définition de la probabilité, axiome du calcul des probabilités, les schémas de tirages probabilistes, probabilité de bayes, les variables aléatoires, caractéristiques d’une variable aléatoire, les lois discrètes, les lois continues, test d’adéquation à une loi
Ouvrage : Probabilités et Statistique – Note de cours
Tests de conformité à la loi normale
2009-09-20 (Tag:3839798987903488964)
Un test d'adéquation permet de statuer sur la compatibilité d'une distribution observée avec une distribution théorique associée à une loi de probabilité. Il s'agit de modélisation. Nous résumons une information brute, une série d'observations, à l'aide d'une fonction analytique paramétrée. L'estimation des valeurs des paramètres est souvent un préalable au test de conformité. Au delà de la simplification, le test permet de valider une appréhension du processus de formation des données, il permet de savoir si notre perception du réel est compatible avec ce que nous observons.Parmi les tests d'adéquation, la conformité à la loi normale (loi gaussienne, loi de Laplace-Gauss) revêt une importance supplémentaire. En effet, l'hypothèse de normalité des distributions sous-tend souvent de nombreux tests paramétriques (ex. comparaison de moyennes, résidus de la régression, etc.).
Dans ce support, nous présenterons dans un premier chapitre les techniques descriptives, notamment le très populaire graphique Q-Q plot. Dans le second, nous détaillerons plusieurs tests statistiques reconnus et implémentés dans la plupart des logiciels de statistique. Dans le troisième, nous étudierons les tests de symétrie des distributions qui, à certains égards, peuvent être considérés comme des cas particuliers des tests de normalité. Enfin, dans un quatrième et dernier chapitre, nous décrivons les formules de Box-Cox destinées à transformer les variables afin qu’elles soient compatibles avec la distribution normale.
Mots-clés : test de conformité à la loi normale, test d’adéquation, test de symétrie, transformation de box-cox
Techniques décrites : graphique Q-Q plot, droite de henry, test de shapiro-wilk, test de lilliefors, test de anderson-darling, test de jarque-bera, test de wilcoxon, test de van der waerden
Ouvrage : Tests de normalité – Techniques empiriques et test statistiques
Pratique de la Régression Linéaire Multiple
2009-09-20 (Tag:7832077193022891385)
Le véritable travail du statisticien commence après la première mise en oeuvre de la régression linéaire multiple sur un fichier de données. Après ces calculs, qu'on lance toujours "pour voir", il faut se poser la question de la pertinence des résultats, vérifier le rôle de chaque variable, interpréter les coefficients, etc.En schématisant, la modélisation statistique passe par plusieurs étapes : proposer une solution (une configuration de l'équation de régression), estimer les paramètres, diagnostiquer, comprendre les résultats, réfléchir à une formulation concurrente.
Dans ce support, nous mettrons l'accent, sans se limiter à ces points, sur deux aspects de ce processus : le diagnostic de la régression à l'aide de l'analyse des résidus, il peut être réalisé avec des tests statistiques, mais aussi avec des outils graphiques simples ; l'amélioration du modèle à l'aide de la sélection de variables, elle permet entre autres de se dégager du piège de la colinéarité entre les variables exogènes.
Mots-clés : régression linéaire simple et multiple, étude des résidus, points aberrants et points influents, colinéarité et sélection de variables, variables exogènes qualitatives, rupture de structure
Techniques décrites : test de durbin-watson, test des séquences, qraphique qq-plot, test de symétrie des résidus, test de jarque-bera, résidu standardisé, résidu studentisé, dffits, distance de cook, dfbetas, covratio, sélection forward, backward, stepwise, codage centerd effect, codage cornered effect, test de chow
Ouvrage : Pratique de la régression linéaire multiple – Diagnostic et sélection de variables
Comparaison de populations - Tests paramétriques
2009-09-17 (Tag:3129093209844801599)
Comparaison de populations. Stricto sensu, les tests de comparaisons depopulations cherchent à déterminer si K (K ¸ 2) échantillons proviennent de la même population relativement à la variable d'intérêt. Nous sommes dans le cadre de la statistique inférentielle : à partir d'échantillons, nous tirons des conclusions sur la population. Au delà de ces aspects purement théoriques, les applications pratiques sont nombreuses.
Paramétrique. On parle de tests paramétriques lorsque l'on fait l'hypothèse que les variables qui décrivent les individus suivent une distribution paramétrée. Dans ce support, nous analyserons principalement (mais pas seulement) le cas des variables continues gaussiennes. Les paramètres sont estimés à partir des échantillons et, dans ce cas, les tests reviennent simplement à les comparer puisqu'elles dé�finissent de manière non ambiguë la distribution. Ainsi, concernant la distribution gaussienne, les tests porteront essentiellement sur la moyenne et l'écart type. L'hypothèse de normalité n'est pas aussi restrictive qu'on peut le penser, nous en discuterons de manière détaillée plus loin.
Ce fascicule de cours se veut avant tout opérationnel. Il se concentre sur les principales formules et leur mise en oeuvre pratique avec un tableur. Autant que possible nous ferons le parallèle avec les résultats fournis par les logiciels de statistique. Le bien-fondé des tests, la pertinence des hypothèses à opposer sont peu ou prou discutées. Nous invitons le lecteur désireux d'approfondir les bases de la statistique inférentielle, en particulier la théorie des tests, à consulter les ouvrages énumérés dans la bibliographie.
Mots-clés : test statistique, test paramétrique, comparaison de populations, tanagra, logiciel R
Techniques décrites : comparaison de moyennes, test de student, analyse de variance à 1 facteur, comparaison de variances, test de fisher, test de bartlett, test de cochran, test de hartley, test de levene, test de brown-forsythe, comparaison de proportions, test d'homogénéité du KHI-2 pour 2 populations, tests pour échantillons appariés, tests multivariés, T2 de hotelling, manova, lambda de wilks
Ouvrage : Comparaison de populations - Tests paramétriques
Pratique de la régression logistique
2009-09-14 (Tag:7861986696876946068)
Cet ouvrage décrit la pratique de la régression logistique. Il est pour l’instant centré sur la régression logistique binaire, il est amené à évoluer en intégrant la régression logistique polytomique dans un proche avenir.
Il aborde tous les grands thèmes du domaine : l’estimation des paramètres via la maximisation de la vraisemblance ; les intervalles de confiance et les tests de significativité ; l’interprétation des coefficients (sous la forme d’odds-ratio) ; l’évaluation de la régression ; la prédiction et les intervalles de prédiction ; le redressement sur les échantillons non représentatifs ; l’analyse des interactions ; le diagnostic de la régression via l’analyse des résidus ; etc. (15 chapitres).
L’ouvrage est très peu théorique. Il cherche à mettre en avant les aspects pratiques. Il est abondamment illustré à l’aide d’exemples traités à l’aide de logiciel libres (ou gratuits), principalement Tanagra et R. Souvent, les calculs sont également reproduits manuellement dans le tableur Excel pour que le lecteur puisse inspecter dans le détail les formules utilisées. Les données sont accessibles en ligne, tout un chacun pourra reproduire les exercices.
Mots clés : régression logistique, tanagra, R
Ouvrage : Pratique de la régression logistique – Régression logistique binaire et polytomique
Tanagra - Séminaire au L3I
2009-09-07 (Tag:6901460728304147824)
Un très sympathique séminaire au sein du laboratoire L3I (Laboratoire Informatique, Image et Interaction) de l’Université de la Rochelle a été l’occasion de faire le point sur Tanagra et de le positionner par rapport aux principaux outils libres. Un petit bilan numérique a été fait également. Sur la période 01-09-2008 au 31-08-2009 (une année), l’ensemble des sites web qui gravitent autour de Tanagra, comprenant le site du logiciel mais aussi les sites de tutoriels et de supports de cours, a enregistré 171.697 visites, soit 470 visites par jour. Une grande partie vient de France (77.117) ; puis vient le Maghreb (11.603 – Algérie, 10.855 – Maroc et 7543 – Tunisie)... (voir le pdf pour plus de précisions). Je suis très content que ce travail contribue à la diffusion de la connaissance.
Voici le résumé de l’exposé.
Titre : Tanagra - logiciels libres, spécificités et applications
Auteur : Ricco Rakotomalala, Laboratoire ERIC, Université Lyon 2
Avec internet, les logiciels libres (gratuits) connaissent un essor sans précédent. Dans le domaine du Data Mining et de l'apprentissage automatique, les outils développés par les chercheurs dans les laboratoires, uniquement connus des initiés, sont maintenant mondialement diffusés à moindre coût. Ce succès croissant introduit des contraintes. De nouvelles exigences en matière de qualité apparaissent. Il est impensable de mettre à la disposition d'autres chercheurs ou d'utilisateurs néophytes, un outil totalement abscons ou, plus grave encore, qui n'effectue pas les calculs correctement. Finalement, ces dernières années, les logiciels libres à grande diffusion intégrant tout le cycle du Data Mining (accès aux données, préparation et sélection de variables, apprentissage automatique, validation et déploiement) sont assez rares. Ces outils partagent une particularité essentielle en recherche : le code source est accessible, tout le monde a la possibilité de vérifier ce qui est réellement codé.
Dans notre exposé, nous présenterons le logiciel Tanagra que nous avons développé. Dans un premier temps, nous essaierons de mettre en avant les spécifications qui ont conduit à son élaboration, son évolution au fil du temps, et les éléments périphériques qui accompagnent sa diffusion. Dans un deuxième temps, nous le comparerons aux principaux logiciels libres, largement reconnus dans notre communauté : Orange, Knime, R, RapidMiner, Weka. Nous nous baserons principalement sur les étapes clés du Data Mining pour évaluer les solutions qui ont été mises en place par les différents outils. Des petits exemples didactiques permettront de juger de leur comportement réel. Enfin, dans un troisième temps, pour donner un tour concret à notre exposé, nous détaillerons l'utilisation de notre outil lors d'une collaboration avec un laboratoire externe, non spécialiste du Data Mining, où l'objectif initial était de classer automatiquement des planctons à partir d'images. Nous constaterons qu'au delà de la simple application des algorithmes, l'utilisation d'une plate-forme complète permet d'élargir l'horizon d'analyse et de mieux préciser les objectifs d'une étude.
Mots clés : data mining, logiciel libre, Tanagra, applications
PDF du séminaire : Tanagra
Statistiques descriptives (suite)
2009-05-29 (Tag:4525711209966362496)
La statistique descriptive vise à résumer l’information portée par un tableau de données. « Trop d’informations tue l’information » a-t-on coutume de dire. Il est illusoire d’inspecter un tableau contenant des centaines, voire des milliers, d’observations et d’en déduire des tendances.L’objectif de la statistique descriptive est de nous fournir une image simplifiée de la réalité, en mettant en exergue des caractéristiques qui ne sont pas discernables de prime abord. Elle emmène un nouvel éclairage sur les données. Elle s’appuie pour cela sur des indicateurs et des représentations graphiques qui, pour simples qu’elles soient, sont très souvent pertinentes pour une bonne compréhension de la structure des données.
Ce thème a déjà été abordé dans un de nos précédents didactciels (voir référence). Nous l'abordons de manière plus approfondie ici en le présentant selon deux axes. Tout d’abord nous ferons la distinction « techniques univariées », qui étudient les variables individuellement, et « techniques bivariées », qui étudient les relations entre 2 variables. Le second axe repose sur la distinction entre les variables catégorielles (qualitatives nominales) et les variables continues (quantitatives).
Mots clés : descriptive statistics, statistique univariée, statistique bivariée
Composants : UNIVARIATE DISCRETE STAT, CONTINGENCY CHI-SQUARE, UNIVARIATE CONTINUOUS STAT, SCATTERPLOT, LINEAR CORRELATION, GROUP CHARACTERIZATION
Lien : fr_Tanagra_Descriptive_Statistics.pdf
Données : enquete_satisfaction_femmes_1953.xls
Références :
Tutoriel Tanagra, "Statistiques descriptives"
Stratégie « wrapper » pour la sélection de variables
2009-05-15 (Tag:7640997320058715406)
La sélection de variables est un aspect essentiel de l’apprentissage supervisé. Nous devons déterminer les variables pertinentes pour la prédiction des valeurs de la variable à prédire, pour différentes raisons : un modèle plus simple sera plus facile à comprendre et à interpréter ; le déploiement sera facilité, nous aurons besoin de moins d’informations à recueillir pour la prédiction ; enfin, un modèle simple se révèle souvent plus robuste en généralisation c.-à-d. lorsqu’il est appliqué sur la population.Trois familles d’approches sont mises en avant dans la littérature. Les approches FILTRE consistent à introduire les procédures de sélection préalablement et indépendamment de l’algorithme d’apprentissage mise en oeuvre par la suite. Pour les approches INTEGREES, le processus de sélection fait partie de l’apprentissage. Les algorithmes d’induction d'arbres de décision illustrent parfaitement cette méthode. Enfin, l’approche WRAPPER cherche à optimiser un critère de performance en présentant à la méthode d’apprentissage des scénarios de solutions. Le plus souvent, il s’agit du taux d’erreur. Mais en réalité, tout critère peut convenir.
Dans ce didacticiel, nous mettrons en œuvre la méthode WRAPPER couplée avec le modèle bayesien naïf (modèle d’indépendance conditionnelle). Nous utilisons les logiciels SIPINA et R. Pour ce dernier, le code écrit est le plus générique possible afin que le lecteur puisse comprendre chaque étape du processus de sélection et adapter le programme à d’autres données, et à d’autres méthodes d’apprentissage supervisé.
La stratégie WRAPPER est a priori la meilleure puisqu’elle optimise explicitement le critère de performance. Nous vérifierions cela en comparant les résultats avec ceux fournis par l’approche FILTRE (méthode FCBF) proposée dans TANAGRA. Nous verrons que les conclusions ne sont pas aussi tranchées qu’on pourrait le croire.
Mots clés : sélection de variables, apprentissage supervisé, classifieur bayesien naïf, wrapper, fcbf, sipina, logiciel R, package RWeka,
Composants : DISCRETE SELECT EXAMPLES, FCBF FILTERING, NAIVE BAYES, TEST
Lien : fr_Tanagra_Sipina_Wrapper.pdf
Données : mushroom_wrapper.zip
Références :
JMLR Special Issue on Variable and Feature Selection - 2003
R Kohavi, G. John, « The wrapper approach », 1997.
Analyse factorielle des correspondances avec R
2009-05-09 (Tag:8277291962500681604)
Ce tutoriel reproduit sous le logiciel R, l’analyse factorielle des correspondances (AFC) décrite dans l’ouvrage de Lebart et al., pages 103 à 107. Les justifications théoriques et les formules sont disponibles dans le même ouvrage, pages 67 à 103.Ces calculs ont été reproduits dans Tanagra dans un de nos anciens didacticiels (AFC - Association médias et professions) [Note de mise à jour (01/07/2013) : un support de cours dédié à l'AFC est maintenant disponible]. Nous pouvons ainsi comparer les sorties. Si le mode de présentation est un peu différent, les résultats sont strictement les mêmes. Ils sont également identiques à ceux de notre ouvrage de référence. Heureusement.
Plusieurs packages de R peuvent mener une AFC, nous avons choisi FactorMineR pour sa simplicité et son adéquation avec les sorties usuelles des logiciels reconnus.
Mots clés : logiciel R, analyse factorielle des correspondances multiples, AFC, représentation simultanée
Composants : CA, FactoMineR
Lien : afc_avec_r.pdf
Données : afc_avec_r.zip
Références :
L. Lebart, A. Morineau, M. Piron, "Statistique Exploratoire Multidimensionnelle", Dunod, 2000 ; pages 67 à 103, partie théorique ; pages 103 à 107, pour l’exemple que nous traitons.
Tutoriel Tanagra, "Analyse Factorielle des Correspondances - Support de cours"
Tutoriel Tanagra, "AFC - Association médias et professions"
Tutoriel Tanagra, "Analyse des correspondances - Comparaison de logiciels"
Husson, Le, Josse, Mazet, « FactoMineR »
Analyse des Corresponsances Multiples avec R
2009-05-06 (Tag:3106499602588397037)
Ce tutoriel reproduit sous le logiciel R, l’analyse des correspondances multiples (ACM) décrite dans l’ouvrage de Tenenhaus, pages 266 à 276. Les justifications théoriques et les formules sont disponibles dans le même ouvrage, pages 253 à 264.Ces calculs ont été reproduits dans Tanagra dans un de nos anciens didacticiels (AFCM - Races canines). Nous pouvons ainsi comparer les sorties. Si le mode de présentation est un peu différent, les résultats sont strictement les mêmes. Ils sont également identiques à ceux de notre ouvrage de référence. Heureusement.
Plusieurs packages de R peuvent mener une ACM (ou AFCM – Analyse factorielle des correspondances multiples), nous avons choisi FactorMineR pour sa simplicité et son adéquation avec les sorties usuelles des logiciels reconnus.
Mots clés : logiciel R, analyse des correspondances multiples, ACM, analyse factorielle de correspondances multiples, AFCM, représentation pseudo-barycentrique, représentation barycentrique
Composants : MCA, FactoMineR
Lien : afcm_avec_r.pdf
Données : afcm_avec_r.zip
Références :
M. Tenenhaus, « Statistique – Méthodes pour décrire, expliquer et prévoir », Dunod, 2006 ; pages 253 à 264, partie théorique ; pages 266 à 276, pour l’exemple que nous traitons.
Tutoriel Tanagra, "AFCM - Comparaison de logiciels"
Tutoriel Tanagra, "AFCM - Races canines"
Husson, Le, Josse, Mazet, « FactoMineR »
Installation des packages sous R
2009-05-05 (Tag:5021490464253182547)
R est à la fois un langage de programmation et un logiciel statistique, c’est le point de vue de la majorité des utilisateurs et il est tout à fait justifié.Une autre manière de voir les choses serait de dire que R est un langage de programmation où l’objet de base est un vecteur. Il est ainsi particulièrement adapté au traitement statistique. Ce qui explique sa spécialisation dans ce domaine d’ailleurs, bien qu’en réalité son champ d’application soit plus large.
Cette spécialisation est d’autant plus marquée que R dispose d’une multitude de fonctions statistiques, extensibles à l’infini avec le système des packages.
L’idée est simple. Tout un chacun peut écrire une bibliothèque externe qu’il peut plugger dans R, sans avoir à modifier ou à recompiler le programme appelant. La procédure semble simple pourvu qu’on se conforme aux spécifications. Les avantages sont incommensurables. Pour le chercheur, il peut se consacrer aux méthodes qu’il développe en s’intégrant dans un environnement bien défini, en bénéficiant des fonctionnalités de gestion de données de R, et avec la possibilité d’utiliser des méthodes développées par ailleurs. Pour les praticiens, c’est l’assurance de disposer des techniques de pointe dans tous les domaines du traitement des données (statistique, analyse de données, data mining). Les mises à jour et les addenda sont quasi-journaliers.
Mots clés : logiciel R, package, arbres de décision
Composants : library, rpart
Lien : installation et gestion des packages.pdf
Références :
R Team, « The R Project for Statistical Computing ».
R. Rakotomalala, « Cours Programmation R ».
Diagnostic de la régression avec R
2009-05-05 (Tag:3661989059729020909)
Ce didacticiel illustre les concepts présentés dans la deuxième partie de mon cours d’économétrie. Il s’agit de diagnostiquer une régression linéaire multiple à l’aide des graphiques des résidus (entre autres, le graphique quantile-quantile plot, etc.), de l’analyse des points atypiques, de la détection de la colinéarité.Un processus de sélection automatique de variables est mis en place à l’aide de la procédure stepAIC (package MASS).
Les procédures et les résultats peuvent être mis en parallèle avec ceux proposés par Tanagra, présentés par ailleurs dans une série de didacticiels : Régresison – Expliquer la consommation de véhicules ; Sélection forward – Crime Dataset ; Colinéarité et régression ; Points aberrants et influents dans la régression.
Mots clés : logiciel R, régression linéaire multiple, économétrie, diagnostic, résidus, points atypiques, points aberrants, points influents, colinéarité, critère VIF, sélection de variables
Composants : lm, influence.measures, res.standard, res.student, stepAIC
Lien : regression - detection des donnees aberrantes - selection de variables.pdf
Données : automobiles_pour_regression.txt
Références :
R. Rakotomalala, "Cours Econométrie", Université Lumière Lyon 2.
R. Rakotomalala, "Pratique de la régression linéaire multiple – Diagnostic et sélection de variables", Université Lumière Lyon 2.
Analyse en Composantes Principales avec R
2009-05-04 (Tag:7519157488254652039)
Ce didacticiel reproduit un exemple traité dans l’ouvrage de Saporta (2006), à la différence que l’analyse a été menée entièrement dans R à l’aide de la procédure princomp(.) (package stats, installé et chargé automatiquement).Les mêmes calculs ont été réalisés sous Tanagra (ACP - Description de véhicules) (Note de mise à jour : d'autres outils sont disponibles - "ACP avec Tanagra - Nouveaux outils" [15/06/2012]). Nous pouvons donc comparer les résultats fournis par le livre, ceux de Tanagra et ceux rapportés dans ce document. Bonne nouvelle, ils sont strictement identiques.
L’analyse couvre les sujets suivants : construction du cercle des corrélations, projection des individus dans le plan factoriel, traitement des variables illustratives (supplémentaires) qualitatives et quantitatives, traitement des individus illustratifs (supplémentaires).
Le sujet peut être complété par la lecture du didacticiel dédié à la détection du nombre d'axes en analyse en composantes principales.Un support de cours consacré à l'ACP est aujourd'hui [29/07/2013] disponible.
Mots clés : logiciel R, analyse en composantes principales, ACP, cercle de corrélation, variables illustratives, individus illustratifs
Composants : princomp
Lien : acp_avec_r.pdf
Données : acp_avec_r.zip
Références :
G. Saporta, « Probabilités, analyse des données et statistique », Dunod, 2006 ; pages 155 à 179.
Tutoriel Tanagra, "Analyse en composantes principales - Support de cours"
Tutoriel Tanagra, "ACP - Description de véhicules"
Tutoriel Tanagra, "ACP avec R - Détection du nombre d'axes"
Tanagra - Version 1.4.31
2009-04-15 (Tag:3836030450635324252)
M. Thierry Leiber a amélioré l'add-on réalisant la connexion entre Tanagra et Open Office. Il est maintenant possible, sous Linux, d'installer la macro complémentaire sous Open Office et de lancer directement Tanagra après avoir sélectionné les données (voir le tutoriel associé). Merci beaucoup Thierry pour cette contribution qui élargit le panel des utilisateurs de Tanagra.Suite à une suggestion de M. Laurent Bougrain, la matrice de confusion est ajoutée à la sauvegarde automatique des résultats lors des expérimentations à grande échelle (voir « Tanagra en Ligne de commande »). Merci à Laurent, et à tous ceux qui par leurs commentaires constructifs m'aident à aller dans le bon sens.
Par ailleurs deux composants de régression par la méthode des Machines à Vastes Marges (Support Vector Regression) ont été ajoutés : Epsilon-SVR et Nu-SVR. Un didacticiel présente ces méthodes et compare nos résultats avec ceux du logiciel R. Tanagra, comme R avec la package « e1071 », s'appuie sur la fameuse bibliothèque LIBSVM.
Support Vector Regression
2009-04-15 (Tag:113019170777088769)
Les SVM (séparateur à vaste marge, machines à vecteurs de support, support vector machine en anglais) sont des méthodes bien connues en apprentissage supervisé. Leur utilisation est en revanche moins répandue en régression. On parle de « Support Vector Regression » (SVR).La méthode est peu diffusée auprès des statisticiens. Pourtant, elle cumule des qualités qui la positionnent favorablement par rapport aux techniques existantes. Elle se comporte admirablement bien lorsque le ratio nombre de variables sur le nombre d’observations devient très défavorable, avec des prédicteurs fortement corrélés. Encore faut-il bien entendu trouver le paramétrage adéquat, nous y reviendrons dans ce didacticiel. Autre atout, avec le principe des noyaux, il est possible de construire des modèles non linéaires sans avoir à produire explicitement de nouveaux descripteurs.
Le premier objectif de ce didacticiel est de montrer la mise en œuvre de deux nouveaux composants SVR de Tanagra 1.4.31 : espilon-SVR et nu-SVR. Ils sont issus de la bibliothèque LIBSVM que nous utilisons par ailleurs pour l’apprentissage supervisé (voir le composant C-SVC). Nous comparerons nos résultats avec ceux du logiciel R (version 2.8.0 - http://cran.r-project.org/). Nous utilisons pour ce dernier le package e1071 basée également sur la bibliothèque LIBSVM.
Le second objectif est de proposer un nouveau composant d’évaluation de la régression. Il est d’usage en apprentissage supervisé de scinder le fichier en deux parties, une pour la création du modèle, l’autre pour son évaluation, afin d’obtenir une estimation non biaisée des performances. Cette pratique est très peu répandue en régression. Pourtant, la procédure est nécessaire dès que nous sommes emmenés à comparer des prédicteurs de complexité différente. Nous constaterons ainsi dans ce didacticiel que les indicateurs usuels calculés sur les données d’apprentissage sont très trompeurs dans certaines situations.
Mots clés : support vector regression, support vector machine, régression, régression linéaire multiple, évaluation de la régression, logiciel R, package e1071
Composants : MULTIPLE LINEAR REGRESSION, EPSILON SVR, NU SVR, REGRESSION ASSESSMENT
Lien : fr_Tanagra_Support_Vector_Regression.pdf
Données : qsar.zip
Références :
C.C. Chang, C.J. Lin, "LIBSVM - A Library for Support Vector Machines".
S. Gunn, « Support Vector Machine for Classification and Regression », Technical Report of the University of Southampton, 1998.
A. Smola, B. Scholkopf, « A tutorial on Support Vector Regression », 2003.
Connexion Open Office Calc sous Linux
2009-04-15 (Tag:1304668075732738859)
L'intégration de Tanagra dans un tableur, que ce soit Excel ou Open Office Calc (OOCalc), via le système des Add-Ons, est certainement un des principaux facteurs de diffusion du logiciel. Sans connaissances particulières concernant la manipulation de fichiers, un utilisateur peut envoyer directement ses données à partir d'un environnement auquel il est familiarisé, le tableur, vers un logiciel spécialisé de Data Mining.Les macros ont été initialement développées pour l'environnement Windows. Je me suis intéressé depuis peu au fonctionnement de Tanagra sous Linux via Wine. Je me suis rendu compte que le logiciel était pleinement fonctionnel sans l'utilisateur n'ait besoin de procéder à des tripatouillages compliqués du système. Il ne restait plus qu'à établir une connexion entre le tableur phare sous Linux (OOCalc) et Tanagra.
M. Thierry Leiber a réalisé ce travail pour la version 1.4.31 de Tanagra. Il a étendu la macro complémentaire initialement destinée à la version d'Open Office sous Windows. En résumant un peu, le code consiste à tester le système en vigueur, de former la commande adéquate pour lancer Tanagra, et transférer à ce dernier les données via le presse papier. De fait, l'Add-On est maintenant opérationnel que ce soit sous Windows ou sous Linux. Il a été testé en tous les cas dans les configurations suivantes : Windows XP + Open Office 3.0.0 ; Windows Vista + Open Office 3.0.1 ; Ubuntu 8.10 + Open Office 2.4 ; Ubuntu 8.10 + Open Office 3.0.1.
Ce document reprend donc un de nos anciens tutoriels. La nouveauté ici est que nous travaillons sous Linux (distribution Ubuntu 8.10). Nous réaliserons une analyse en composantes principales pour illustrer notre propos. Mais notre principal objectif est bien de montrer le portage de la connexion sous Linux.
Mots clés : open office calc, add-on, analyse en composantes principales, ACP, cercle des corrélations, variable illustrative, linux, ubuntu 8.10 intrepid ibex
Composants : PRINCIPAL COMPONENT ANALYSIS, CORRELATION SCATTERPLOT
Lien : fr_Tanagra_OOCalc_under_Linux.pdf
Données : cereals.xls
Références :
Tutoriel Tanagra, « Connexion Open Office Calc »
Tutoriel Tanagra, « Tanagra sous Linux »
Tutoriel Tanagra, « Connexion Excel [Macro complémentaire] »
Sipina - Formats de fichiers
2009-02-16 (Tag:3543587222241231742)
L’accès aux données est la première étape du processus Data Mining. Lorsque nous souhaitons initier un traitement à l’aide d’un logiciel quelconque, la première question que nous nous posons est systématiquement « comment dois-je procéder pour importer mes données ? ». C’est donc un critère important pour juger de la qualité d’un logiciel. Nous pourrons fatalement moins consacrer de temps à l’exploration et l’interprétation lorsque la lecture et la manipulation des données deviennent des opérations difficiles et fastidieuses.Deux points de vue permettent de positionner les formats de fichier : la souplesse et la performance. On entend par souplesse la capacité à manipuler facilement le fichier, même en dehors du logiciel spécialisé. Le fichier texte est le format à privilégier dans ce contexte. Nous pouvons l’ouvrir, le modifier et l’enregistrer dans n’importe quel éditeur de texte. De plus, tout logiciel destiné à la manipulation de données (tableur, système de gestion de base de données entre autres) sait appréhender ce type de fichier. La performance revient surtout à évaluer la rapidité des accès et, dans une moindre mesure, l’occupation disque. Le critère de performance est surtout important lorsque nous avons à manipuler de très grands fichiers. En effet, Sipina réalisant les traitements en mémoire centrale, comme la majorité des logiciels de Data Mining libres d’ailleurs, il n’est pas nécessaire de répéter fréquemment les opérations de chargement et de sauvegarde.
Dans ce document, notre premier objectif est de faire le point sur les différents formats de fichier que gère Sipina. Il y a les fichiers textes au format simplifié (texte avec séparateur tabulation) ou spécialisé (ARFF de Weka) ; il y a les formats binaires que seul Sipina sait lire, mais qui sont très performants. Nous décrirons également la solution originale que nous avons mis en place pour faciliter le transfert d’Excel vers Sipina. Certaines solutions sont décrites en détail dans des didacticiels accessibles par ailleurs, nous indiquerons les pointeurs adéquats au fil du texte. L’autre objet de ce didacticiel est de comparer les performances de Sipina selon ces différents formats, lorsque l’on traite un fichier de grande taille, comportant 4.817.099 observations et 42 variables.
Enfin, nous avons construit un arbre de décision à partir de ce fichier pour évaluer un peu le comportement de Sipina face à un tel volume.
Mots clés : fichier, format, texte, csv, arff, weka, fdm, fdz, zdm, arbres de décision
Lien : fr_Sipina_File_Format.pdf
Données : weather.txt et kdd-cup-discretized-descriptors.txt.zip
Règles d'Association Prédictives
2009-02-11 (Tag:8516208370811969339)
Les algorithmes d’extraction des règles d’association ont été initialement mis au point pour découvrir des liens logiques entre des variables ayant le même statut. Les règles d’association prédictives en revanche cherchent à produire les combinaisons d’items qui caractérisent au mieux une variable qui joue un rôle à part, on cherche à prédire ses valeurs.Fondamentalement, l’algorithme est peu modifié. L’exploration est simplement restreinte aux itemsets qui comportent la variable à prédire. Le temps de calcul est d’autant réduit. Deux composants de Tanagra sont dédiés à cette tâche, il s’agit de SPV ASSOC RULE et SPV ASSOC TREE. Ils sont accessibles dans l’onglet ASSOCIATION.
Par rapport aux approches classiques, les composants de Tanagra introduisent une spécificité supplémentaire : nous avons la possibilité de préciser la classe (couple « variable à prédire = valeur ») que l’on souhaite prédire. L’intérêt est de pouvoir ainsi paramétrer finement l’algorithme de recherche, en relation directe avec les caractéristiques des données. Cela s’avère décisif par exemple lorsque les prévalences des modalités de la variable à prédire sont très différentes.
Nous avions déjà présentés le composant SPV ASSOC TREE par ailleurs. Mais c’était dans le contexte de la caractérisation multivariée de groupes d’individus. Nous l’opposions alors au composant GROUP CHARACTERIZATION. Dans ce didacticiel, nous comparerons le comportement des composants SPV ASSOC TREE et SPV ASSOC RULE sur un problème de prédiction. Nous mettrons en avant leurs points communs, les problèmes qu’ils savent traiter ; et leurs différences, SPV ASSOC RULE, en plus de proposer des mesures d’intérêt des règles originales, a la capacité de simplifier la base de règles.
Mots clés : règles d’association prédictives, mesures d'intérêt des règles, simplification des bases de règles
Composants : SPV ASSOC TREE, SPV ASSOC RULE
Lien : fr_Tanagra_Predictive_AssocRules.pdf
Données : credit_assoc.xls
Références :
R. Rakotomalala, « Règles d’association »
Utiliser et paramétrer A PRIORI MR
2009-02-06 (Tag:6799210716545225634)
L’extraction des règles d’association est une approche très populaire pour dégager les interdépendances entre les caractéristiques des individus. Elle a beaucoup été utilisée pour étudier les achats concomitants chez les consommateurs. Le résultat se présente sous la forme d’une règle logique du type « SI un individu a acheté tel ou tel produit ALORS il achètera également tel et tel produit ». Bien entendu, il est possible d’étendre le champ d’application de la méthode à d’autres domaines.Nous avons présenté les règles d’association à plusieurs reprises dans nos didacticiels. La méthode A PRIORI est certainement la plus connue. Malgré ses qualités, l’approche présente un écueil fort : le nombre de règles produites peut être très élevé. La capacité à mettre en avant les « meilleures » règles, celles qui sont porteuses d’informations « intéressantes », devient ainsi un enjeu fort.
Ces dernières années, on a vu fleurir un nombre impressionnant de publications cherchant à proposer des mesures d’intérêt des règles. Leur mise en œuvre est simple : on assigne un score (mesure d’intérêt) à chaque règle, on trie alors la base de règles de manière à ce que celles qui sont les plus informatives apparaissent en premier.
Le composant A PRIORI MR (onglet ASSOCIATION) est un outil expérimental qui propose plusieurs mesures d’évaluation des règles. Il met en avant, entres autres, le concept de « valeur-test ». C’est une mesure statistique développée par A. Morineau (1984), décrite dans un ouvrage (Lebart, Morineau et Piron, 2000), et largement utilisée dans le logiciel commercial SPAD (http://www.spad.eu/).
Mots clés : règles d’association, mesures d'intérêt des règles
Composants : A PRIORI MR
Lien : fr_Tanagra_APrioriMR_Component.pdf
Données : credit_assoc.xls
Références :
R. Rakotomalala, « Règles d’association »
Mesures d'intérêt des règles dans A PRIORI MR
2009-02-06 (Tag:9047606199815096212)
Ce document recense les mesures d’évaluation des règles d’association proposées par le composant A PRIORI MR. Elles résultent d’études relatées dans une série de publications de A. Morineau et R. Rakotomalala (essentiellement en 2006).Une mesure sert à caractériser la pertinence d’une règle. Elle permet de les classer. Elle devrait aussi permettre de discerner celles qui sont « significativement intéressantes » de celles qui ne le sont pas. Ce dernier point reste totalement prospectif. Il n’y a pas de solutions réellement satisfaisantes à ce jour.
Mots clés : règles d'association, mesures d'intérêt des règles, valeur test
Composants : A PRIORI MR
Lien : fr_Tanagra_APrioriMR_Measures.pdf
Références :
A. Morineau, R. Rakotomalala, "Crtière VT-100 de sélection des règles d'association", in Actes de EGC-2006, pp. 581-592, Lille, 2006.
Wikipedia, "Association rule learning"
Comparaison des performances sous Linux
2009-01-23 (Tag:5462277797335122284)
La courbe de gain est un outil important du ciblage marketing. On le retrouve sous des terminologies différentes selon les logiciels (gain chart, courbe lift, lift chart, courbe lift cumulative, etc.). Mais l'idée est toujours la même : nous affectons un score à des individus, nous trions la base selon un score décroissant, nous élaborons alors une graphique nuage de points avec, en abscisse, la proportion des individus dans la cible (les x premiers – en pourcentage - dans la base triée selon le score), et en ordonnée, la fraction des positifs que l'on y retrouve. Le dernier point est de coordonnée (100%, 100%) : lorsque tous les individus sont inclus dans la cible, nous sommes sûrs de retrouver tous les positifs.L'élaboration de la courbe de gains dans Tanagra est décrite par ailleurs (#1155728077892147299). Notre idée dans ce didacticiel est d'élargir la description aux autres logiciels libres (Knime, RapidMiner et Weka). La seconde originalité de cette étude est que nous réalisons toutes les opérations sous Linux (distribution Ubuntu 8.10). Nous constaterons que Tanagra, tout comme les logiciels sus-cités, fonctionnent parfaitement. Cela nous amène à la troisième originalité de ce travail, nous traitons un fichier d'une taille importante avec 2.000.000 d'observations et 41 variables. Nous pourrons évaluer la tenue de ces logiciels lorsqu'on les place dans des situations extrêmes, de surcroît sur une machine très peu performante.
Nous adopterons la même démarche pour chaque logiciel. Dans un premier temps, nous traitons un échantillon de 2.000 observations, nous pouvons ainsi paramétrer à notre aise les calculs et obtenir au moins une fois un résultat que l'on peut montrer. Dans un second temps, nous modifions la source de données pour traiter le fichier complet. Nous mesurons alors le temps d’exécution, nous mesurons également l'occupation mémoire à l'issue de tous les traitements. Nous constaterons que certains logiciels ne pourront pas mener à leur terme les calculs.
Mots clés : scoring, ciblage marketing, analyse discriminante, courbe lift, courbe de gain, knime, rapidminer, weka, orange
Composants : SAMPLING, LINEAR DISCRIMINANT ANALYSIS, SCORING, LIFT CURVE
Lien : fr_Tanagra_Gain_Chart.pdf
Données : dataset_gain_chart.zip
Références :
Wikipedia, "Analyse discriminante linéaire"
R. Rakotomalala, "Ciblage marketing"
Sipina sous Linux
2009-01-20 (Tag:3996181937435145752)
Je suis dans la période où je (re)découvre Linux. Nous avons vu récemment qu'il était possible de travailler avec Tanagra sous Linux via Wine, simplement, sans contorsions compliquées.Nous montrons dans ce document qu'il est possible de faire de même avec Sipina. Toutes les fonctionnalités du logiciel sont accessibles. On pense notamment aux outils interactifs qui permettent de guider la construction de l'arbre et d'explorer finement les sous-groupes d'observations associées aux nœuds.
Nous ne nous étendrons pas outre mesure sur ces fonctionnalités qui sont largement présentées par ailleurs dans plusieurs tutoriels accessibles sur le site web de Sipina. Notre principal objectif dans ce tutoriel est de montrer qu'il est possible d'utiliser Sipina sous Linux.
Nous utilisons la distribution française de Ubuntu 8.10. Nous avons également installé WINE, un outil extraordinaire qui permet d'exécuter un très grand nombre de logiciels initialement compilés pour Windows.
Mots clés : linux, ubuntu, wine, sipina, arbres de décision
Lien : fr_Sipina_under_Linux.pdf
Données : breast.txt
Références :
"Sipina", http://sipina.over-blog.fr/ ou https://eric.univ-lyon2.fr/ricco/sipina.html
"Ubuntu", http://www.ubuntu-fr.org/
"Wine", http://doc.ubuntu-fr.org/wine
Tanagra sous Linux
2009-01-11 (Tag:1366469368219706598)
Une question des utilisateurs qui revient souvent est : « est-ce que l'on peut utiliser Tanagra sous Linux ? ». La réponse est OUI et NON.NON, parce que Tanagra est compilé avec Delphi pour Windows. L'exécutable ne peut pas être directement lancé dans l'environnement Linux.
OUI, parce qu'il y a WINE, un outil performant qui permet d'exécuter des applications Windows sous Linux. Nous pouvons ainsi profiter de toutes les fonctionnalités de Tanagra sans avoir à se poser des questions sur les éventuels problèmes de compatibilités, etc. De fait, l'utilisation de Tanagra sous Linux est complètement transparente. On clique sur le raccourci, le programme démarre, il est directement utilisable sans que l'on ait à se poser des questions compliquées. Plusieurs utilisateurs me l'avaient déjà signalé. Je me suis dit qu'il était temps de documenter tout cela.
Dans ce didacticiel, nous montrons comment faire fonctionner Tanagra dans UBUNTU (une distribution gratuite de Linux) via l'environnement WINE que nous devrons préalablement installer.
Mots clés : linux, ubuntu, wine
Lien : fr_Tanagra_under_Linux.pdf
Références :
"Ubuntu", http://www.ubuntu-fr.org/
"Wine", http://doc.ubuntu-fr.org/wine
Coûts de mauvais classement en apprentissage supervisé
2009-01-06 (Tag:6181982300715883401)
Tout le monde s’accorde à dire que l’intégration des coûts de mauvais classement est un aspect incontournable de la pratique du Data Mining. Diagnostiquer une maladie chez un patient sain ne produit pas les mêmes conséquences que de prédire la bonne santé chez un individu malade. Dans le premier cas, le patient sera soigné à tort, ou peut être demandera-t-on des analyses supplémentaires superflues ; dans le second cas, il ne sera pas soigné, au risque de voir son état se détériorer de manière irrémédiable. Pourtant, malgré son importance, le sujet est peu abordé, tant du point de vue théorique c.-à-d. comment intégrer les coûts dans l’évaluation des modèles (facile) que dans leur construction (un peu moins facile), que du point de vue pratique c.-à-d. comment les mettre en œuvre dans les logiciels.La prise en compte des coûts lors de l’évaluation ne pose pas de problèmes particuliers. La prise en compte des coûts lors de l’élaboration du modèle de classement est moins connue. Plusieurs approches sont possibles.
Si les techniques existent, qu’en est-il de leur implémentation dans les logiciels libres ? Après investigations, on se rend compte que les logiciels qui les intègrent de manière naturelle sont très peu nombreux. Il semble que Weka soit l’un des rares à proposer des outils faciles à manipuler pour l’intégration des coûts. Ce constat nous a amené à introduire de nouveaux composants destinés à la prise en compte des coûts en apprentissage supervisé dans la version 1.4.29 de Tanagra.
Dans ce document, nous montrons la mise en œuvre de ces composants de Tanagra 1.4.29 sur un problème réel (réaliste). Nous avons également programmé ces mêmes procédures dans le logiciel R 2.8.0 (http://www.r-project.org/) pour donner une meilleure visibilité sur ce qui est implémenté. Nous comparerons nos résultats avec ceux de Weka 3.5.8. L’algorithme sous-jacent à toutes nos analyses sera un arbre de décision. Selon les logiciels, nous utiliserons C4.5, CART ou J48.
Mots clés : apprentissage supervisé, coûts de mauvais classement, arbres de décision, Weka 3.5.8, logiciel R 2.8.0, package rpart
Composants : CS-CRT, COST SENSITIVE LEARNING, COST SENSITIVE BAGGING, MULTICOST
Lien : fr_Tanagra_Cost_Sensitive_Learning.pdf
Données : dataset-dm-cup-2007.zip
Références :
J.H. Chauchat, R. Rakotomalala, M. Carloz, C. Pelletier, "Targeting Customer Groups using Gain and Cost Matrix: a Marketing Application", PKDD-2001.
J.H. Chauchat, R. Rakotomalala, "Cost sensitive C4.5"
Tutoriel Tanagra, "Apprentissage-test avec Sipina"
Règles d’association – Comparaison de logiciels
2008-11-17 (Tag:5607734124471776437)
Ce document reprend un précédent tutoriel dédié à la comparaison des implémentations libres des règles d’association. Nous avions étudié Tanagra, Orange, et Weka. Nous étendons le comparatif aux logiciels R (package arules), RapidMiner et Knime.Nos données se présentent sous la forme d’un tableau générique « attribut – valeur », avec les individus en ligne et les variables en colonne. Ce n’est pas le format usuel pour les règles d’association où l’on traite plutôt des bases transactionnelles : chaque ligne est une transaction, pour chaque transaction nous disposons de la liste des items observés.
Nous verrons dans ce didacticiel que certains logiciels savent traiter le format tableau en réalisant automatiquement en interne le recodage. Pour d’autres en revanche, il nous faudra procéder explicitement au recodage. Il importe alors de trouver les bons outils et la bonne séquence de traitements pour produire le format propice à l’extraction des règles d’association. Les manipulations ne sont pas toujours évidentes selon les logiciels.
Tous les logiciels étudiés implémentent une version plus ou moins élaborée de l’algorithme A PRIORI (Agrawal et Srikant, 1994). Pour être tout à fait précis, et afin que tout un chacun puisse reproduire exactement les opérations, nous avons mis à contribution les versions suivantes dans ce comparatif : Tanagra 1.4.28 ; R 2.7.2 (package arules 0.6-6) ; Orange 1.0b2 ; RapidMiner Community Edition ; Knime 1.3.5 et Weka 3.5.6.
Tous chargent la totalité des données et effectuent les calculs en mémoire vive. Lorsque la taille de la base augmente, le véritable goulot d’étranglement est donc la mémoire disponible sur notre machine.
Mots clés : règles d’association
Composants : A PRIORI, A PRIORI PT
Lien : fr_Tanagra_Assoc_Rules_Comparison.pdf
Données : credit-german.zip
Références :
R. Rakotomalala, « Règles d’association »
Validation croisée - Comparaison de logiciels (suite)
2008-11-06 (Tag:3934274560248037340)
Ce didacticiel reprend un de nos anciens articles consacrés à la mise en œuvre de la validation croisée pour l’évaluation des performances des arbres de décision (voir Arbres de décision avec Orange, Tanagra et Weka). Nous comparions la démarche à suivre et la lecture des résultats pour Tanagra, Orange et Weka.Dans ce document, nous étendons le descriptif aux logiciels R 2.7.2, Knime 1.3.51 et RapidMiner Community Edition.
Les objectifs et le cheminement sont les mêmes. Le lecteur peut se reporter à notre précédent didacticiel s’il souhaite avoir des précisions sur ces éléments. Nous utilisons le fichier HEART.TXT (UCI). L’objectif est de prédire l’occurrence des maladies cardio-vasculaires (COEUR). Le fichier a été nettoyé, le nombre de descripteurs a été réduit (12 variables prédictives), il en est de même pour les observations (270 individus).
Mots clés : apprentissage supervisé, arbres de décision, évaluation des classifieurs, méthode de ré échantillonnage, validation croisée, RapidMiner, Knime, logiciel R, package rpart
Lien : fr_Tanagra_Validation_Croisee_Suite.pdf
Données : heart.zip
Références :
R. Rakotomalala, "Estimation de l'erreur de prédiction - Les techniques de ré échantillonnage"
R. Rakotomalala, " Arbres de décision ", Revue Modulad, 33, 163-187, 2005 (tutoriel_arbre_revue_modulad_33.pdf)
UCI Machine Learning Repository, "Heart Disease Data set"
Classification automatique - Déploiement de modèles
2008-10-30 (Tag:7423702304836691135)
Le déploiement est une étape importante du Data Mining. Dans le cas d'une typologie, il s'agit, après la construction des classes à l'aide d'un algorithme de classification automatique, d'affecter les individus supplémentaires aux groupes.Cette phase de catégorisation vient naturellement après le processus de modélisation. La construction et l'interprétation des groupes nous permettent de dégager des caractéristiques et des comportements types. Lorsque apparaît un nouvel individu (un nouveau client pour une banque, un nouveau patient pour un centre hospitalier, etc.), le positionner par rapport aux groupes permet d'anticiper sur son attitude.
Mais le traitement des individus supplémentaires peut aussi servir à renforcer les résultats. Lorsqu'une sous population est connue pour son comportement atypique, la classer par rapport aux groupes construits sur le reste de la population renforce à la fois l'interprétation des groupes et la connaissance que l'on peut avoir des ces " niches " d'observations. On parle plus volontiers d'individus illustratifs dans ce cas.
Dans ce didacticiel, nous construisons tout d'abord les groupes à l'aide de la méthode des K-Means (méthode des centres mobiles). Puis, nous associons chaque individu supplémentaire à la classe qui lui est la plus proche au sens de la distance aux centres de classes. La méthode est viable car la technique utilisée pour classer l'individu supplémentaire est en accord avec la démarche de constitution des groupes lors de l'apprentissage. Ce n'est pas toujours bien compris. Si nous avions utilisé une classification ascendante hiérarchique avec la méthode du saut minimum, classer un nouvel individu à partir de la distance aux centres de classes n'est pas approprié. La stratégie d'affectation doit être en adéquation avec la stratégie d'agrégation.
Notre fichier est composé exclusivement de variables qualitatives. Nous devons donc passer par une phase préalable de préparation des variables (voir aussi K-Means sur variables qualitatives).
Nous utilisons Tanagra 1.4.28 et R 2.7.2 (avec le package FactoMineR pour l'analyse des correspondances multiples). Dans ce didacticiel, nos objectifs sont : (1) montrer comment réaliser ce type de tâche avec ces deux logiciels ; (2) comparer les résultats ; (3) en détaillant les commandes dans R, nous donnons une meilleure visibilité sur les calculs réalisés par Tanagra.
Mots clés : clustering, classification automatique, typologie, k-means, méthode des centres mobiles, méthode des nuées dynamiques, ACM, AFCM, analyse factorielle des correspondances multiples, interprétation des classes, tableau de contingence, déploiement de modèles, classement d’individus supplémentaires, exportation des résultats
Composants : MULTIPLE CORRESPONDENCE ANALYSIS, K-MEANS, GROUP CHARACTERIZATION, CONTINGENCY CHI-SQUARE, EXPORT DATASET
Lien : fr_Tanagra_KMeans_Deploiement.pdf
Données : banque_classif_deploiement.zip
Références :
Wikipedia (en), « K-Means algorithm ».
F. Husson, S. Lê, J. Josse, J. Mazet, « FactoMineR – A package dedicated to Factor Analysis and Data Mining with R ».
K-Means – Comparaison de logiciels
2008-10-26 (Tag:551623638217375576)
La méthode des K-Means (méthode des centres mobiles) est une technique de classification automatique (clustering en anglais). Elle vise à produire un regroupement de manière à ce que les individus du même groupe soient semblables, les individus dans des groupes différents soient dissemblables.
Nous l’avons déjà décrite (faire recherche sur le mot clé k-means ou voir la section classification-clustering) par ailleurs. Notre idée dans ce didacticiel est de montrer sa mise en oeuvre dans différents logiciels libres de Data Mining. Nous souhaitons utiliser la démarche suivante :
- Importer les données ;
- Réaliser quelques statistiques descriptives sur les variables actives ;
- Centrer et réduire les variables ;
- Réaliser la classification automatique via les K-Means sur les variables transformées, en décidant nous même du nombre de classes ;
- Visualiser les données avec la nouvelle colonne représentant la classe d’appartenance des individus ;
- Illustrer les classes à l’aide des variables actives, via des statistiques descriptives comparatives et des graphiques judicieusement choisis ;
- Croiser la partition obtenue avec une variable catégorielle illustrative ;
- Exporter les données, avec la colonne additionnelle, dans un fichier.
Ces étapes sont usuelles lors de la construction d’une typologie. L’intérêt de ce didacticiel est de montrer qu’elles sont pour la plupart, sous des formes parfois diverses certes, réalisables avec les logiciels libres de Data Mining. Il faut simplement trouver les bons composants et le bon enchaînement.
Nous étudierons les logiciels suivants : Tanagra 1.4.28 ; R 2.7.2 (sans package additionnel spécifique) ; Knime 1.3.5 ; Orange 1.0b2 et RapidMiner Community Edition.
Nous utilisons la méthode des centres mobiles dans ce tutoriel. Il est possible de suivre la même démarche globale en lui substituant n’importer quelle autre technique de classification automatique (la classification ascendante hiérarchique, les cartes de Kohonen, etc.).
Bien évidemment, je ne peux prétendre maîtriser complètement les différents logiciels. Il se peut que des fonctionnalités m’échappent pour certains d’entre eux. Il faut surtout voir les grandes lignes et le parallèle entre les outils, les experts pourront compléter les opérations à leur guise.
Mots clés : clustering, classification automatique, typologie, k-means, méthode des centres mobiles, méthode des nuées dynamiques, ACP, interprétation des classes
Composants : PRINCIPAL COMPONENT ANALYSIS, K-MEANS, GROUP CHARACTERIZATION, EXPORT DATASET
Lien : fr_Tanagra_et_les_autres_KMeans.pdf
Données : cars_dataset.zip
Références :
Wikipedia (en), « K-Means algorithm ».
Traitement de gros volumes – CAH Mixte
2008-10-14 (Tag:8644381424523352618)
La CAH (classification ascendante hiérarchique) est une technique de classification automatique (clustering en anglais). Elle vise à produire un regroupement des individus de manière à ce que les individus du même groupe soient semblables, des individus dans des groupes différents soient dissemblables.Le succès de la CAH repose sur sa capacité à produire des partitions emboîtées. Au lieu de fournir une solution clé en main, irréversible, elle donne la possibilité de choisir, parmi les regroupements proposés, celui qui correspond au mieux aux contraintes de l’étude et aux objectifs de l’analyste. Cet avantage s’accompagne d’une représentation graphique, le dendrogramme. Il nous suggère, dans le continuum des solutions envisageables, celles qui semblent les plus pertinentes.
Son principal défaut est le temps de calcul. Il devient vite rédhibitoire dès que le nombre d’observations est élevé. Pour dépasser cet écueil, on procède alors à la CAH Mixte. Elle consiste à faire précéder la CAH proprement dite par une phase de pré-regroupement, en utilisant un algorithme des nuées dynamiques par exemple, la CAH prend alors comme point de départ ces pré-classes. De fait, avec cette stratégie, il devient possible de traiter de très grands fichiers tout en bénéficiant des avantages de la CAH.
Cette approche a déjà été largement abordée dans un de nos anciens didacticiels (voir CAH Mixte – Le fichier IRIS de Fisher). La méthode est par ailleurs longuement décrite dans l’ouvrage de Lebart et al. (2000). Conformément à ce qui est préconisé par les auteurs, nous réalisons la classification sur les axes factoriels de l’ACP (analyse en composantes principales). L’idée est de « lisser » les informations exploitées en évacuant les fluctuations aléatoires.
L’enjeu dans ce didacticiel est de mettre en œuvre cette stratégie sur un fichier de taille relativement considérable, avec 500.000 observations et 68 variables. Nous utiliserons Tanagra 1.4.27 et R 2.7.2. Nous nous en tenons à ces deux logiciels. En effet, il n’est pas possible d’implémenter la CAH Mixte avec les autres logiciels libres (Weka, Orange, Knime, Rapidminer). Et lancer directement la CAH standard sur un tel fichier n’est pas raisonnable.
Mots clés : clustering, classification automatique, typologie, CAH, k-means, nuées dynamiques, ACP, classification sur facteurs
Composants : PRINCIPAL COMPONENT ANALYSIS, K-MEANS, HAC, GROUP CHARACTERIZATION, EXPORT DATASET
Lien : fr_Tanagra_CAH_Mixte_Gros_Volumes.pdf
Données : sample-census.zip
Références :
L. Lebart, A. Morineau, M. Piron, « Statistique Exploratoire Multidimensionnelle », Dunod, 2000 ; chapitre 2, sections 2.3 et 2.4.
Régression logistique - Comparaison de logiciels
2008-10-07 (Tag:3486592938939508852)
La régression logistique est une technique prédictive, très populaire dans la communauté statistique. Je ne sais pas si elle est très utilisée parce que très enseignée, ou très enseignée parce que largement utilisée. En tous les cas, on ne peut pas passer à côté si on s’intéresse un tant soit peu au Scoring c.-à-d. aux configurations où l’on souhaite prédire ou expliquer les valeurs d’une variable discrète (nominale ou ordinale) à partir d’une série de descripteurs (de type quelconque).Les raisons de cet engouement sont nombreuses. La régression logistique s’intègre dans un cadre théorique parfaitement identifié, celui de la régression linéaire généralisée. C’est une technique semi paramétrique. Son champ d’application est large. Par rapport aux techniques issues de l’apprentissage automatique, elle intègre les outils de la statistique inférentielle. Enfin, autre atout fort, la lecture des coefficients sous forme de surcroît de risque (les fameux « odds ratio ») donne aux utilisateurs un outil de choix pour comprendre l’essence de la relation entre les descripteurs et la variable à prédire.
La régression logistique est implémentée dans tous les logiciels de statistique commerciaux. Elle est plus rare en revanche dans les logiciels libres. En partie parce que la méthode est peu connue des informaticiens, ceux qui sont les plus enclins à programmer des outils. La situation change quand même un peu maintenant. Avec le label « data mining », il y a un certain brassage des cultures. On peut parler de « faire une régression » sans que certaines personnes ne s’imaginent que vous êtes en train de retomber en enfance.
Dans ce didacticiel, nous comparons la mise en œuvre de la régression logistique à l’aide de quelques logiciels libres : Tanagra 1.4.27, bien sûr, puisque je travaille dessus ; R 2.7.2 (procédure GLM), qui est incontournable dès que l’on souhaite utiliser des techniques d’obédience statistique ; Orange 1.0b2, qui l’intègre dans sa panoplie ; Weka 3.5.6, qui l’aborde exclusivement sous l’angle de l’optimisation, en faisant l’impasse sur la partie inférentielle ; et enfin, toujours Weka mais via le package RWeka 0.3-13 pour le logiciel R.
Au delà de la comparaison, ce didacticiel est aussi l’occasion de montrer la démarche à suivre pour réaliser la succession d’opérations suivantes sur ces différents logiciels : importer un fichier au format ARFF ; fractionner les données en apprentissage et test ; lancer la modélisation sur la fraction apprentissage ; évaluer les performances sur la partie test ; procéder à une sélection de variables en accord avec la régression logistique (et non pas basé sur des critères qui n’ont aucun rapport avec l’approche) ; évaluer de nouveau les performances du modèle simplifié.
Mots clés : régression logistique, scoring, apprentissage supervisé
Composants : BINARY LOGISTIC REGRESSION, SUPERVISED LEARNING, TEST, DISCRETE SELECT EXAMPLES
Lien : fr_Tanagra_Perfs_Reg_Logistique.pdf
Données : wave_2_classes_with_irrelevant_attributes.zip
Références :
Wikipédia (fr), « Régression logistique »
SVM - Comparaison de logiciels
2008-10-03 (Tag:8701286616146824782)
Les machines à vecteurs de support (ou séparateur à vaste marge) sont des techniques d’apprentissage supervisé qui s’appuient sur deux idées fortes : (1) le principe de la maximisation de la marge ; (2) lorsque les données ne sont pas linéairement séparables, il est possible, par le principe des noyaux, de se projeter dans un espace de plus grande dimension pour trouver la solution adéquate, sans avoir à former explicitement ce nouvel espace de représentation.Nous nous plaçons dans un cadre particulièrement favorable aux SVM dans ce didacticiel. Nous souhaitons prédire la famille d’appartenance de séquences de protéines à partir de la présence - absence de suites de 4 acides aminées (4-grams). Nous traitons un problème à 2 classes, nous disposons de 135 observations et 31809 descripteurs. Notre objectif est de comparer le comportement de quelques implémentations libres des SVM. Ce document vient en complément d’autres comparaisons que nous avons réalisés dans des contextes différents.
Ce comparatif est intéressant à plus d’un titre. Tout d’abord, nous aurons la possibilité d’évaluer les différentes implémentations des SVM, tant en temps de calcul qu’en qualité de prédiction. L’optimisation reposant sur des heuristiques, il est normal que les temps de calcul soient différents, mais il se peut également que les performances en classement qui en résultent ne soient pas identiques. Pouvoir les situer est une démarche importante. Dans les publications utilisant les SVM, on devrait non seulement dire « nous avons utilisé les SVM, avec tel noyau », mais aussi préciser « quelle implémentation des SVM », tant parfois les résultats peuvent diverger d’un logiciel à l’autre.
Autre point important. A y regarder de plus près, nous sommes également confrontés à un problème de volumétrie ici. Même si le nombre d’observations est faible, le nombre de variables, lui, est élevé. Or, les logiciels évalués chargent la totalité des données en mémoire vive. De nouveau la mémoire disponible devient un goulot d’étranglement.
Les logiciels évalués dans ce didacticiel sont : ORANGE, RAPIDMINER, TANAGRA et WEKA.
Mots clés : svm, support vector machine, séparateur à vaste marge, machine à vecteurs de support
Composants : C-SVC, SVM, SUPERVISED LEARNING, CROSS-VALIDATION
Lien : fr_Tanagra_Perfs_Comp_SVM.pdf
Données : wide_protein_classification.zipRéférences :
Ricco Rakotomalala, "Support Vector Machine - Diapos", mai 2016.
Wikipédia (en), « Support vector machine »
Traitement de gros volumes – Comparaison de logiciels
2008-09-21 (Tag:7311410094755552097)
La gestion de la volumétrie est une des pierres angulaires du Data Mining. Toute présentation du domaine passe par le sempiternel « depuis quelques années, les entreprises amassent une quantité considérable de données, l’enjeu n’est plus comment les stocker mais plutôt comment les exploiter pour en tirer de l’information », etc., etc. Ok, ok, n’en jetez plus, on est d’accord.Si le traitement des grandes bases est un enjeu important, on est curieux de savoir comment se comportent les logiciels libres (gratuits) dans ce contexte. Ils sont nombreux dans le Data Mining. J’essaie de suivre un peu leur évolution. La capacité à analyser des grands fichiers est un critère que je regarde souvent pour situer mes propres implémentations. La plupart chargent l’ensemble de données en mémoire centrale. De fait, la différenciation en termes de performances repose essentiellement sur la technologie utilisée (compilé ou pseudo-compilé) et la programmation. Le goulot d’étranglement est la mémoire disponible.
Dans ce didacticiel, nous comparons les performances de plusieurs implémentations de l’algorithme C4.5 (Quinlan, 1993) lors du traitement d’un fichier comportant 500.000 observations et 22 variables. Un fichier somme toute assez raisonnable.
Les logiciels mis en compétition sont les suivants : KNIME, ORANGE, R (package RPART), RAPIDMINER (anciennement YALE), SIPINA, TANAGRA et WEKA.
Ce document vient un complément d’un ancien didacticiel où nous montrions les performances de ID3 de Tanagra sur un fichier encore plus volumineux. Nous retiendrons 2 critères pour comparer les logiciels : le temps de traitement et surtout l’occupation mémoire. Ils sont essentiels dans notre contexte.
On retiendra entre autres que tous les logiciels ont pu mener à bien les calculs dans cette expérimentation. Ce qui confirme, si besoin était, l’excellente tenue des logiciels libres en matière de performances.
Mots clés : c4.5, arbres de décision, grandes bases de données, comparaison de logiciels, knime, orange, r, rapidminer, sipina, tanagra, weka
Composants : SUPERVISED LEARNING, C4.5
Lien : fr_Tanagra_Perfs_Comp_Decision_Tree.pdf
Données : wave500k.zip
Références :
R. Quinlan, « C4.5 : Programs for Machine Learning », Morgan Kaufman, 1993.
Tanagra : Spécifications, Développement, Promotion
2008-09-19 (Tag:3503728989058152104)
Un séminaire au sein de l'UMR Sensométrie et Chimiométrie (ENITIAA/INRA) à Nantes en avril 2008 a été l'occasion de faire un peu le bilan du projet Tanagra, 5 ans presque après son lancement.L'objectif était de tracer les grandes lignes du projet en mettant en avant les différentes réflexions que nous avons eu à mener, les pistes qui ont permis d'élaborer un cahier des charges raisonnable.
Il fallait notamment : essayer de cerner les utilisateurs types ; définir les spécifications fonctionnelles, en nous situant par rapport aux outils que nous avions programmés auparavant et les logiciels existants ; définir les spécifications techniques, de manière entre autres à ce que la mise à jour ne devienne pas un parcours du combattant ; choisir le mode de documentation du logiciel, aspect crucial dès lors que l'on souhaite le diffuser à grande échelle, j'ai beaucoup pêché sur le sujet par le passé ; et enfin, poser la question de la promotion du logiciel auprès des utilisateurs. En effet, il s'agit d'un outil totalement libre, c'est entendu. Mais si je suis le seul à l'utiliser, l'intérêt est plutôt limité. Je pense que la documentation joue un rôle très important dans ce domaine.
C'est donc le support visuel de l'exposé qui est mis en ligne ici. Quelques transparents ont été réactualisés pour refléter les chiffres de la version 1.4.27 (fin août 2008).
Lien : R. Rakotomalala, "Tanagra : Spécifications, Développement et Promotion", Séminaire USC, ENITIAA/INRA, Nantes, Avril 2008.
La méthode CART dans Tanagra et R (package rpart)
2008-09-17 (Tag:2752440325288987770)
CART (Breiman et al, 1984) est une méthode très populaire d’induction d’arbres de décision, peut-être la plus répandue, tout du moins au sein de la communauté francophone du Data Mining. A juste titre. CART intègre tous les bons ingrédients d’un apprentissage maîtrisé : arbitrage biais – variance via avec le post-élagage, le mécanisme de coût complexité permet de « lisser » l’exploration de l’espace des solutions, intégration de la préférence à la simplicité avec la règle de l’écart type, préférence que le praticien peut modifier en modulant les paramètres en fonction des objectifs de l’étude et des caractéristiques des données, etc.La Société Salford Systems détient les droits d’utilisation du nom CART. De fait, même si la méthode est implantée dans de nombreux logiciels commerciaux, elle n’est jamais désignée nommément. Que cela ne nous induise pas en erreur, une lecture rapide de la documentation ne laisse généralement aucun doute quant à l’origine de la technique.
La situation est un peu différente en ce qui concerne les logiciels libres. Ils sont nettement plus rares à proposer CART, une grande majorité d’entre eux lui préférant ID3 ou C4.5, nettement plus faciles à programmer au demeurant.
Dans ce didacticiel, nous comparons deux implémentations libres de CART : le composant C-RT de Tanagra et le package RPART du Logiciel R. A la lecture de la documentation, ils s’appuient tous les deux sur les mêmes schémas génériques (Breiman et al, 1984 ; chapitres 3, 10 et 11). La principale différence apparaît lors du post-élagage. Tanagra ne propose que le post élagage basé sur un échantillon spécifique dit « échantillon d’élagage » (section 11.4). RPART lui s’appuie plus volontiers sur la validation croisée (section 11.5), bien qu’il soit possible d’utiliser également un échantillon d’élagage, au prix de manipulations (un peu beaucoup) compliquées il est vrai.
Pour mener la comparaison, nous utilisons les données artificielles WAVEFORM de Breiman (section 2.6.2). La variable à prédire (CLASS) comporte 3 modalités, les 21 variables prédictives (V1 à V21) sont toutes continues. Nous essayons de reproduire l’expérimentation décrite dans l’ouvrage de référence (pages 49 et 50), à savoir utiliser 300 individus en apprentissage et 5000 en test.
Mots clés : arbres de décision, méthode cart, apprentissage supervisé, comparaison de logiciels, logiciel R, package rpart
Composants : DISCRETE SELECT EXAMPLES, C-RT, SUPERVISED LEARNING, TEST
Lien : fr_Tanagra_R_CART_algorithm.pdf
Données : wave5300.xls
Références :
Breiman, J. Friedman, R. Olsen, C. Stone, Classification and Regression Trees, Chapman & Hall, 1984.
"The R project for Statistical Computing" - http://www.r-project.org/
La méthode SIPINA
2008-09-15 (Tag:3758345177656647993)
SIPINA est un logiciel. Mais c'est aussi une méthode d'apprentissage. Elle généralise les arbres en introduisant une opération supplémentaire, la fusion, lors de l'induction du modèle de prédiction. On parle de " Graphes d'Induction ".
L'idée de fusion des sommets existe déjà dans des méthodes telles que CART ou CHAID. Mais dans ce cas, il s'agit de procéder au regroupement des feuilles issues du même nœud père lors d'une segmentation. Pour une variable explicative discrète comportant K modalités, CART effectue des regroupements de manière à proposer 2 super modalités, l'arbre est binaire ; CHAID effectue un regroupement sélectif en comparant les profils des distributions, il y a bien regroupement mais l'arbre n'est pas forcément binaire. SIPINA généralise cette idée en permettant le regroupement de 2 feuilles quelconques de la structure. La fusion peut donc s'appliquer à deux feuilles géographiquement éloignées dans le graphe.
Schématiquement, à chaque étape du processus de construction du graphe, la méthode évalue et met en compétition la segmentation d'un nœud et la fusion de deux nœuds. Elle choisit l'opération qui améliore la mesure d'évaluation globale de la partition. Cela est possible car le critère pénalise les nœuds à faibles effectifs. Dans certaines situations, il peut être avantageux de fusionner des sommets avant de segmenter à nouveau. L'objectif est d'explorer plus finement des sous-groupes d'individus, sans tomber dans un des inconvénients récurrents des arbres de décision, la tendance au sur-apprentissage consécutive à l'éparpillement excessif des observations.
La méthode SIPINA n'est disponible que dans la version 2.5 du logiciel (SIPINA version 2.5). Ce dernier concentre bien des défauts. Mais c'est néanmoins le seul logiciel à proposer la méthode SIPINA telle qu'elle est décrite dans la littérature (voir Références). C'est la raison pour laquelle je le mets encore en ligne d'ailleurs. Sinon, si l'on veut utiliser d'autres algorithmes d'induction d'arbres (C4.5, CHAID, etc.), il est préférable de se tourner vers la " Version Recherche " , nettement plus performante et fiable.
Dans ce didacticiel, nous montrons la mise en œuvre de la méthode SIPINA dans le logiciel éponyme, version 2.5. Le problème traité est l'explication du faible poids de certains bébés à la naissance à partir des caractéristiques de la mère. L'interprétation des résultats est anecdotique dans notre contexte. On cherche surtout (1) à montrer la prise en main de cette version du logiciel qui est très peu documentée, (2) à mettre en avant les avantages de la méthode lorsque l'on traite des fichiers comportant peu d'observations.
Mots clés : arbres de décision, graphes d'induction
Lien : fr_sipina_method.pdf
Données : low_birth_weight_v4.xls
Références
Zighed, J.P. Auray, G. Duru, SIPINA : Méthode et logiciel, Lacassagne, 1992.
R. Rakotomalala, Graphes d’induction, Thèse de Doctorat, Université Lyon 1, 1997 (URL : https://eric.univ-lyon2.fr/ricco/publications.html).
D. Zighed, R. Rakotomalala, Graphes d’induction : Apprentissage et Data Mining, Hermès, 2000.
Comparaison des dispersions pour K échantillons indépendants
2008-08-30 (Tag:2401591064295260975)
Les tests de comparaison de variances sont souvent présentés comme des préalables aux tests de comparaisons de moyennes, pour s’assurer de l’hypothèse d’homoscédasticité. Mais ce n’est pas leur seule finalité. Comparer les dispersions peut être une fin en soi.Les tests paramétriques reposent principalement sur la normalité des données. Nous mettons en avant le test de Levene dans ce didacticiel. D’autres tests existent, nous les signalerons dans le texte.
Lorsque l’hypothèse de normalité est battue en brèche, lorsque les effectifs sont faibles, lorsque la variable est plus ordinale que continue, on a intérêt à passer aux tests non paramétriques. On parle alors de comparaison d’échelles ou de dispersions. En effet les procédures ne reposent plus sur les variances estimées. Nous utiliserons dans ce didacticiel les techniques les plus connues tels que le test de Ansari-Bradley, le test de Mood ou le test de Klotz. Ils ont un champ d’application plus large puisque non paramétriques. Ils présentent en revanche un inconvénient fort, ils sont inapplicables dès que les caractéristiques de tendance centrale conditionnelles (on dira la médiane pour simplifier) sont différentes.
Nous montrons la mise en œuvre de ces différents tests dans TANAGRA. Nous inspecterons et confronterons les résultats. Nous essayerons d’apporter des solutions lorsque les conditions d’utilisation des tests ne sont pas respectées.
Les données décrivent les performances de dispositifs de chauffage écologique. La variable d’intérêt est la température à l’intérieur d’une cabane au petit matin de l’automne, au fin fond de la forêt, lorsque le loup n’est pas rentré dans sa tanière encore. Nous disposons de n = 45 observations. Un premier groupe de n1 = 15 cabanes sert de témoin. Aucun système n’a été mis en place. Deux autres groupes (n2 = 15 et n3 = 15) sont constitués : l’un bénéficie d’un système basé sur un réchauffement naturel de l’air, l’autre s’appuie sur le réchauffement de l’eau. On cherche à comparer la disparité des températures d’un groupe à l’autre.
Les aspects théoriques relatifs à ce didacticiel sont décrits dans des supports de cours accessibles en ligne (voir références). D'autres tutoriels sont consacrés à la comparaison de variances (voir Comparaison de populations - Tests paramétriques univariés ; Analyse de variance et comparaison de variances ; etc.)
Mots clés : tests paramétriques, tests non paramétriques, échantillons indépendants, test de comparaison de variances, test de comparaison de dispersions ou d’échelles, test de Levene, test de Bartlett, test de Brown-Forsythe, test de Mood, test de Klotz, test de Ansari-Bradley
Composants : LEVENE’S TEST, ANSARI-BRADLEY SCALE TEST, MOOD SCALE TEST, KLOTZ SCALE TEST
Lien : fr_Tanagra_Nonparametric_Test_for_Scale_Differences.pdf
Données : tests_for_scale_differences.xls
Références :
R. Rakotomalala, « Comparaison de populations. Tests non paramétriques », Université Lyon 2.
R. Rakotomalala, « Comparaison de populations. Tests paramétriques », Université Lyon 2.
Tests de comparaison pour 2 échantillons appariés
2008-08-29 (Tag:3813321274685214669)
L’appariement est une procédure qui vise à réduire l’effet des fluctuations d’échantillonnage c.-à-d. la variabilité due aux observations. Nous pouvons l’associer à différentes configurations.Le schéma des « mesures répétés » est le premier qui vient à l’esprit. Il s’agit de mesurer la même grandeur chez un même individu, avant et après intervention d’une action dont on veut justement évaluer les conséquences. Par exemple, on mesure la fièvre chez un malade, on lui donne un médicament, après un certain laps de temps, on lui prend de nouveau sa température : les deux mesures sont confrontées.
L’appariement peut être aussi le fruit de la constitution des données en blocs. Si l’on souhaite comparer l’efficacité de 2 méthodes d’enseignement, les mesures répétées sont inappropriées. Dans les paires d’observations, que l’on appelle « blocs », nous associerons alors des élèves identiques par rapport aux caractéristiques de l’étude. Par exemple, on met dans chaque paire des élèves qui, par le passé, ont obtenu des résultats identiques aux examens.
Enfin, l’appariement peut être tout simplement inhérent à la situation que l’on cherche à analyser. Par exemple, on cherche à comparer le temps passé devant la télévision par l’homme et la femme à l’intérieur d’un couple. Les blocs correspondent naturellement aux ménages. Les hommes et les femmes ne doivent pas être considérés comme des observations indépendantes.
Les tests de comparaisons spécifiques à ce type de configuration présentent une caractéristique particulière : l’appréciation des différences est réalisée prioritairement à l’intérieur des blocs. Dans ce didacticiel, nous présentons deux techniques non paramétriques, le test des signes et le test des rangs signés de Wilcoxon, et une technique paramétrique, le test de Student pour échantillons appariés.
Les données proviennent du site de cours en ligne du Pr Richard Lowry du « Vassar College ». Nous traitons l’exemple utilisé pour illustrer le test des rangs signes de Wilcoxon. On a posé deux questions, QA et QB, à des étudiants, du type « quelle est la probabilité que… ». On cherche à savoir si les valeurs de QA sont stochastiquement différentes de celles de QB. Le principe, les formules et les calculs spécifiques à ces données sont détaillés sur le site web. Nous pouvons suivre à la trace les résultats fournis par TANAGRA.
Les aspects théoriques relatifs à ce didacticiel sont décrits dans des supports de cours accessibles en ligne (voir références). D'autres tutoriels abordent également le sujet de la comparaison sur échantillons apapriés (voir Tests paramétriques univariés, Tests non paramétriques, etc.)
Mots clés : tests non paramétriques, échantillons appariés, test des signes, test des rangs signés de Wilcoxon, test de Student pour échantillons appariés, test de normalité
Composants : SIGN TEST, WILCOXON SIGNED RANK TEST, PAIRED T-TEST, FORMULA, NORMALITY TEST
Lien : fr_Tanagra_Nonparametric_Test_for_Two_Related_Samples.pdf
Données : comparison_2_related_samples.xls
Références :
R. Rakotomalala, « Comparaison de populations. Tests non paramétriques », Université Lyon 2.
R. Rakotomalala, « Comparaison de populations. Tests paramétriques », Université Lyon 2.
R. Lowry, « Concepts and Applications of Inferential Statistics », SubChapter 12a. The Wilcoxon Signed-Rank Test.
Test de Kruskal-Wallis et comparaisons multiples
2008-08-28 (Tag:5696251320721414829)
Les tests de comparaison de populations visent à déterminer si (K >= 2) échantillons proviennent de la même population au regard d’une variable d’intérêt (X). En d’autres termes, nous souhaitons vérifier que la distribution de la variable est la même dans chaque groupe. On utilise également l’appellation « tests d’homogénéité » dans la littérature.Les tests non paramétriques lorsque l’on ne fait pas d’hypothèse sur la distribution de X, on parle aussi de tests « distribution free ».
Dans ce didacticiel, nous nous intéressons plus particulièrement à la configuration où la variable d’intérêt prend stochastiquement des valeurs plus élevées (ou plus faibles, ou simplement différentes) dans une des sous populations. On suppose que la différenciation se fait sur un décalage entre les caractéristiques de tendance centrale des distributions conditionnelles. On parle de modèle de localisation. Le test de Kruskal-Wallis est certainement celui qui vient immédiatement à l’esprit pour traiter ce type de problèmes. Nous verrons dans ce didacticiel que d’autres tests existent. Nous comparerons les résultats obtenus. Nous complèterons l’étude en procédant à des comparaisons multiples, on souhaite détecter les groupes qui diffèrent significativement les uns des autres.
Les données proviennent du site de cours en ligne du Pr Richard Lowry du « Vassar College ». Nous traitons l’exemple utilisé pour illustrer le test de Kruskal-Wallis. On a demandé à n = 21 personnes d’évaluer 3 types de vins (A, B et C) : n1 = 8 ont noté le premier type de vin 1, n2 = 7 pour le second et, n3 = 6 pour le troisième. On souhaite savoir si les notes attribuées sont significativement différentes d’un groupe à l’autre.
Il y a une grosse feinte dans l’expérimentation. En réalité, le vin est exactement le même quel que soit le groupe. C’est l’entretien d’évaluation, débouchant sur l’attribution de la note, qui a été mené de différentes manières. Il est enthousiaste pour le groupe A, un peu moins dans le groupe B, il est neutre dans le groupe C.
La variable d’intérêt est RATING. Elle va de 1 à 10, meilleure sera l’appréciation, plus élevée sera la note. Un complément intéressant de ce tutoriel serait d’étudier le comportement des méthodes paramétriques (ANOVA à 1 Facteur et WELCH ANOVA) sur ces mêmes données.
Les aspects théoriques relatifs à ce didacticiel sont décrits dans un support de cours accessible en ligne (voir références).
Mots clés : tests non paramétriques, test de Kruskal-Wallis, test de Van der Waerden, test de Fisher-Yates-Terry-Hoeffding, test des médianes, modèle de localisation
Composants : KRUSKAL-WALLIS 1-WAY ANOVA, MEDIAN TEST, VAN DER WAERDEN 1-WAY ANOVA, FYTH 1-WAY ANOVA
Lien : fr_Tanagra_Nonparametric_Test_KW_and_related.pdf
Données : wine_evaluation_nonparametric.xls
Références :
R. Rakotomalala, « Comparaison de populations. Tests non paramétriques », Université Lyon 2.
R. Lowry, « Concepts and Applications of Inferential Statistics », SubChapter 14a. The Kruskal-Wallis Test for 3 or More Independent Samples.
Tests non paramétriques de comparaison de 2 populations. Modèle de localisation.
2008-08-27 (Tag:5105547367008318425)
Les tests de comparaison de populations visent à déterminer si (K >= 2) échantillons proviennent de la même population au regard d’une variable d’intérêt (X). En d’autres termes, nous souhaitons vérifier que la distribution de la variable est la même dans chaque groupe. On utilise également l’appellation « tests d’homogénéité » dans la littérature.Les tests non paramétriques lorsque l’on ne fait pas d’hypothèse sur la distribution de X, on parle aussi de tests « distribution free ».
De manière générique, le test de Kolmogorov-Smirnov consiste à comparer les fonctions de répartition empiriques (CDF : cumulative distribution function, en anglais). Dans ce cas, on cherche toute forme de différenciation entre les distributions.
On peut approfondir l’analyse en qualifiant la forme de la différenciation. Une approche très usitée consiste à déterminer si les valeurs de la variable d’intérêt sont stochastiquement plus élevés (plus faibles, ou tout simplement différents) dans un des sous échantillons. Le test de Wilcoxon-Mann-Whitney est certainement la technique la plus populaire, nous verrons dans ce didacticiel que d’autres tests non paramétriques peuvent être utilisés.
Les données proviennent du site de cours en ligne de l’Université Penn State de Pennsylvanie « STAT 500 – Applied Statistics ». Nous nous intéressons à la leçon n°10 qui traite de la comparaison de moyennes. Il s’agit d’évaluer les performances de 2 machines, une ancienne et une nouvelle, lors de l’empaquetage de cartons. La variable d’intérêt est la durée de l’opération.
Les données semblent compatibles avec une distribution normale, les tests paramétriques sont à privilégier dans ce cas. Le site d’ailleurs détaille les résultats du test de Student de comparaison de moyenne. La statistique du test est t = -3.40, l’écart est très significatif avec une probabilité critique (p-value) p = 0.0032 pour un test bilatéral.
Un aspect intéressant de ce tutoriel sera d’étudier le comportement les tests non paramétriques sur ces données, et de confronter les résultats avec celui du test de Student.
Les aspects théoriques relatifs à ce didacticiel sont décrits dans un support de cours accessible en ligne (voir références).
Mots clés : tests non paramétriques, test de Kolmogorov-Smirnov, test de Wilcoxon-Mann-Whitney, test de Van der Waerden, test de Fisher-Yates-Terry-Hoeffding, test de la médiane, modèle de localisation
Composants : FYTH 1-WAY ANOVA, K-S 2-SAMPLE TEST, MANN-WHITNEY COMPARISON, MEDIAN TEST, VAN DER WAERDEN 1-WAY ANOVA
Lien : fr_Tanagra_Nonparametric_Test_MW_and_related.pdf
Données : machine_packs_cartons.xls
Références :
R. Rakotomalala, « Comparaison de populations. Tests non paramétriques », Université Lyon 2.
Wikipedia, « Non-parametric statistics ».
Comparaison de populations – Tests non paramétriques
2008-08-23 (Tag:3156361979323650957)
Les tests de comparaison de populations visent à déterminer si K (K >= 2) échantillons proviennent de la même population au regard d’une variable d’intérêt (X). En d’autres termes, nous souhaitons vérifier que la distribution de la variable est la même dans chaque groupe. On utilise également l’appellation « tests d’homogénéité » dans la littérature.Les tests non paramétriques présentent la particularité de ne pas faire d’hypothèses sur la distribution de X. On parle de tests « distribution free ». Leur champ d’application est donc théoriquement plus étendu que celui de leurs homologues paramétriques.
Ce document n’est pas à proprement parler un tutoriel. Il s’agit plutôt d’un fascicule de cours. Nous l’intégrons à ce site néanmoins car il intègre un grand nombre de sorties de Tanagra décortiquées en détail et mises en relation directe avec les formules sous-jacentes. Les productions de Tanagra sont également comparées avec celles des autres logiciels, libres (R) ou commerciaux (SAS).
Plusieurs didacticiels sur ce site traitent les thèmes abordés dans ce document (par ex. Analyse de variance de Friedman, Tests non paramétriques, etc.). Il serait intéressant de comparer les résultats produits par ces tests avec ceux des tests paramétriques équivalents.
Mots clés : tests non paramétriques, test de Kolmogorov-Smirnov, test de Kuiper, test de Cramer-von Mises, test de Wilcoxon-Mann-Whitney, test de Van der Waerden, test de Fisher-Yates-Terry-Hoeffding, test de la médiane, test de Kruskal-Wallis, modèle de localisation, test de Mood, test de Klotz, test de Ansari-Bradley, modèle d’échelle, test des signes, test de rangs signés de Wilcoxon, anova de Friedman, test Q de Cochran
Composants : ANSARI-BRADLEY SCALE TEST, CONCHRAN’S Q-TEST, FRIEDMAN’S ANOVA BY RANKS, FYTH 1-WAY ANOVA, KLOTZ SCALE TEST, KRUSKAL-WALLIS 1-WAY ANOVA, K-S 2-SAMPLE TEST, MANN-WHITNEY COMPARISON, MEDIAN TEST, MOOD SCALE TEST, SIGN TEST, VAN DER WAERDEN 1-WAY ANOVA, WILCOXON SIGNED RANKS TEST
Lien : Comparaison de populations - Tests non paramétriques
Données : dataset_support_tests_non_parametriques.xls
Références :
R. Rakotomalala, « Comparaison de populations. Tests non paramétriques », Université Lyon 2.
Wikipedia, « Non-parametric statistics ».
Comparaison de populations - Tests paramétriques multivariés
2008-07-22 (Tag:757612481517861877)
Les tests de comparaison de populations visent à déterminer si K (K >= 2) échantillons proviennent de la même population au regard d’une groupe de variables d’intérêt (X1,…,Xp). En d’autres termes, nous souhaitons vérifier que la distribution de la variable est la même dans chaque groupe. On utilise également l’appellation « tests d’homogénéité » dans la littérature.On parle de tests paramétriques lorsque l’on fait l’hypothèse que X suit une distribution paramétrée. Dès lors comparer les distributions empiriques conditionnelles revient à comparer les paramètres : la moyenne et la variance lorsque l’on fait l’hypothèse de normalité en analyse univariée ; le vecteur moyenne et la matrice de variance covariance lorsque l’on considère que le groupe de variables est distribuée selon une loi normale multidimensionnelle en analyse multivariée.
Enfin, dans ce didacticiel, nous traitons les tests multivariés c.-à-d. nous étudions simultanément plusieurs variables d’intérêt.
Ce type de test peut servir à comparer effectivement des processus (ex. est-ce que deux machines produisent des boulons de même diamètre et qualité), mais il permet également d’éprouver la liaison qui peut exister entre une variable catégorielle et une variable quantitative (ex. est ce que les femmes conduisent en moyenne moins vite que les hommes, provoquent moins d’accidents et consomment moins ?).
Les aspects théoriques relatifs à ce didacticiel sont décrits dans un support de cours accessible en ligne (Voir référence, Partie III). Les tests d’écrits dans ce didacticiel s’appliquent aux échantillons indépendants. Les procédures pour échantillons appariés feront l’objet d’autres didacticiels.
Mots clés : T2 de Hotelling, Lambda de Wilks, Box’s M test, test de Bartlett multivarié, vecteur des moyennes, barycentre, matrice de variance covariance, MANOVA
Composants : UNIVARIATE CONTINUOUS STAT, HOTELLING’S T2, HOTELLING’S T2 HETEROSCEDASTIC, BOX’S M TEST, ONE-WAY MANOVA
Lien : fr_Tanagra_Multivariate_Parametric_Tests.pdf
Données : credit_approval.xls
Références :
R. Rakotomalala, « Comparaison de populations. Tests paramétriques », Université Lyon 2.
S. Rathburn, A. Wiesner, "STAT 505: Applied Multivariate Statistical Analysis", The Pennsylvania State University.
Comparaison de populations - Tests paramétriques univariés
2008-07-22 (Tag:8892704970465034859)
Les tests de comparaison de populations visent à déterminer si K (K >= 2) échantillons proviennent de la même population au regard d’une variable d’intérêt (X). En d’autres termes, nous souhaitons vérifier que la distribution de la variable est la même dans chaque groupe. On utilise également l’appellation « tests d’homogénéité » dans la littérature.On parle de tests paramétriques lorsque l’on fait l’hypothèse que la variable X suit une distribution paramétrée. Dès lors comparer les distributions empiriques conditionnelles revient à comparer les paramètres, soit la moyenne et la variance lorsque l’on fait l’hypothèse de normalité de X.
Enfin, dans ce didacticiel, nous traitons les tests univariés c.-à-d. nous étudions une seule variable d’intérêt. Lorsque nous traitons simultanément plusieurs variables, on parle de tests multivariés. Ce qui fera l’objet d’un autre didacticiel prochainement.
Ce type de test peut servir à comparer effectivement des processus (ex. est-ce que deux machines produisent des boulons de même diamètre), mais il permet également d’éprouver la liaison qui peut exister entre une variable catégorielle et une variable quantitative (ex. est ce que les femmes conduisent en moyenne moins vite que les hommes sur telle portion de route).
Les aspects théoriques relatifs à ce didacticiel sont décrits dans un support de cours accessible en ligne (Voir référence, Parties I et II). Nous utiliserons les mêmes données et nous suivrons exactement la même trame pour que le lecteur puisse suivre le détail des formules mises en œuvre.
Mots clés : comparaison de moyennes, test de Student, comparaison de variances, test de Fisher, test de Bartlett, test de Levene, test de Brown-Forsythe, échantillons indépendants et échantillons appariés, ANOVA, ANOVA de Welch, blocs aléatoires complets, mesures répétées
Composants : MORE UNIVARIATE CONT STAT, NORMALITY TEST, T-TEST, T-TEST UNEQUAL VARIANCE, ONE-WAY ANOVA, WELCH ANOVA, FISHER’S TEST, BARTLETT’S TEST, LEVENE’S TEST, BROWN-FORSYTHE TEST, PAIRED T-TEST, PAIRED V-TEST, ANOVA RANDOMIZED BLOCKS
Lien : fr_Tanagra_Univariate_Parametric_Tests.pdf
Données : credit_approval.xls
Références :
R. Rakotomalala, « Comparaison de populations. Tests paramétriques », Université Lyon 2.
NIST/SEMATECH e-Handbook of Statistical Methods, http://www.itl.nist.gov/div898/handbook/ (Chapter 7, Product and Process Comparisons)
Les cartes de Kohonen
2008-07-21 (Tag:8033506913656933266)
Les cartes de Kohonen sont des réseaux de neurones artificiels orientés, constitués de 2 couches. Dans la couche d’entrée, les neurones correspondent aux variables décrivant les observations. La couche de sortie, elle, est le plus souvent organisée sous forme de grille (de carte) de neurones à 2 dimensions. Chaque neurone représente un groupe d’observations similaires.Le réseau de Kohonen est donc une technique de classification automatique (clustering, apprentissage non supervisé). L’objectif est de produire un regroupement de manière à ce que les individus situés dans la même case soient semblables, les individus situés dans des cases différentes soient différents. En y regardant de plus près, on se rend compte d’ailleurs que l’algorithme d’apprentissage est une version sophistiquée de la méthode des K-Means (on parle de « nuées dynamiques » en français, bien que cette dernière intègre elle aussi d’autres types d’améliorations par rapport aux K-Means de Forgy [1965]).
Les cartes de Kohonen constituent également une technique de visualisation. En effet, les neurones de la couche de sortie sont organisés de manière à ce que deux cellules adjacentes dans la grille correspondent à des groupes d’observations proches dans l’espace de représentation initial. On parle de cartes auto organisatrices (SOM : Self Organisation Map). De ce point de vue, le réseau de Kohonen se positionne par rapport aux techniques factorielles de réduction de dimensionnalité. A la différence que la projection est non linéaire.
Dans ce didacticiel, nous montrons comment mettre en œuvre l’algorithme de Kohonen dans Tanagra. Nous visualiserons graphiquement les résultats. L’idée est de vérifier cette fameuse proximité entre les cellules de la grille dans l’espace de représentation. Puis, nous comparons les groupes obtenus avec ceux de la méthode des K-Means, très largement répandue au sein de la communauté de l’apprentissage automatique. Enfin, nous montrons comment nous pouvons affiner les résultats en lançant une classification ascendante hiérarchique (CAH) à partir des cellules de la carte. Cette stratégie est une approche alternative de la classification mixte (K-MEANS + CAH ; Lebart et al., 2000). Elle est particulièrement recommandée pour les fichiers comportant un grand nombre d’observations.
Mots clés : cartes de Kohonen, self organization map, SOM, classification automatique, clustering, réduction de dimensionnalité, k-means, nuées dynamiques, cah, classification ascendante hiérarchique, classification mixte
Composants : UNIVARIATE CONTINUOUS STAT, UNIVARIATE OUTLIER DETECTION, KOHONEN-SOM, PRINCIPAL COMPONENT ANALYSIS, SCATTERPLOT, K-MEANS, CONTINGENCY CHI-SQUARE, HAC
Lien : fr_Tanagra_Kohonen_SOM.pdf
Données : waveform_unsupervised.xls
Références :
Tutoriel Tanagra, "Les cartes auto-organisatrices de Kohonen - Diapos", juillet 2016.
Wikipedia, « Self organizing map », http://en.wikipedia.org/wiki/Self-organizing_map
Corrélation semi-partielle
2008-06-17 (Tag:44417195214184159)
La régression linéaire multiple vise à expliquer les valeurs d’une variable dépendante (Y) à l’aide d’une série de variables indépendantes ou explicatives (Z1, …, Zp). La corrélation semi-partielle quantifie le pouvoir explicatif additionnel d’une variable supplémentaire (X), une fois que nous lui avons retranché les informations déjà portées par les variables (Z1,…,Zp). Une manière simple de la calculer est de réaliser les 2 régressions, avec et sans la présence de X, l’écart entre les deux coefficients de détermination des régressions correspond au carré de la corrélation semi-partielle.Une autre manière de la produire est de calculer les résidus de la régression de X sur (Z1, …, Zp). Ils correspondent à la fraction de X non expliquée par les variables indépendantes. La corrélation semi-partielle est obtenue en calculant le coefficient de corrélation de Pearson entre Y et la variable résiduelle. La nature asymétrique du processus apparaît clairement, l’appellation « corrélation semi-partielle » est pertinente de ce point de vue. On peut faire le parallèle avec la corrélation partielle qui, elle, est symétrique. En effet la corrélation est calculée sur les résidus de X/Z1,…,Zp et Y/Z1,…, Zp dans ce cas.
Dans ce didacticiel, nous montrons les différentes manières de produire la corrélation semi-partielle. Nous comparons les résultats avec le composant dédié de TANAGRA (SEMI-PARTIAL CORRELATION).
Les aspects théoriques en relation avec ce didacticiel sont disponibles dans un support de cours accessible en ligne (voir références, chapitre 5). Nous reprenons d’ailleurs l’exemple illustratif qui y est développé.
Nous cherchons à expliquer la consommation des véhicules à partir de la puissance, la cylindrée et le poids. L’objectif est de déterminer l’apport d’information de "puissance" par rapport aux autres variables explicatives.
Mots clés : corrélation, corrélation de Pearson, corrélation semi-partielle, régression linéaire multiple
Composants : LINEAR CORRELATION, MULTIPLE LINEAR REGRESSION, SEMI-PARTIAL CORRELATION
Lien : fr_Tanagra_Semi_Partial_Correlation.pdf
Données : cars_semi_partial_correlation.xls
Références :
R. Rakotomalala, « Analyse de corrélation – Etudes des dépendances, variables quantitatives », Chapitre 5, Analyse_de_Correlation.pdf
R. Rakotomalala, « Cours économétrie - Supports de cours L3 IDS », Université Lyon 2
M. Brannick, « Partial and Semipartial Correlation », University of South Florida
Corrélation partielle
2008-06-17 (Tag:4696024516808826764)
Le coefficient de corrélation est une mesure statistique destinée à quantifier l’intensité d’un lien (linéaire) entre 2 variables. Il est possible de mettre en place un test de significativité qui cherche à établir l’existence de la relation dans la population.Le coefficient de corrélation est un instrument très populaire. Mais comme tout outil numérique, il a ses faiblesses. La plus criante étant certainement la corrélation factice : 2 variables semblent fortement liées, on se rend compte après coup que la liaison repose sur l’intervention d’une troisième variable. Par exemple, la corrélation entre la longueur des jambes et la longueur des avant-bras est très forte. Elle repose en réalité sur la taille des personnes : les grands ont tendance à avoir des jambes et des avant-bras longs, inversement chez les petits.
La corrélation partielle corrige cet inconvénient. Elle mesure la liaison en annulant l’effet de la troisième variable, dite variable de contrôle. Dans notre exemple, il s’agit de mesurer, à taille de personne égale, la relation entre les longueurs des jambes et des bras. Nous pouvons faire intervenir plusieurs variables de contrôle.
Dans ce didacticiel, nous montrons comment mettre en œuvre le composant PARTIAL CORRELATION dans Tanagra. Nous reprenons un exemple décrit sur un excellent site de cours en ligne (voir références). Outre une présentation théorique de la technique, le détail des calculs est disponible. Nous pouvons retracer les étapes de construction de la mesure, le test de significativité et l’élaboration des intervalles de confiance. Nous pouvons aussi nous comparer avec les résultats établis à l’aide d’autres logiciels de statistique.
Les données proviennent d’un test d’intelligence (QI) basé sur la méthode WAIS (Wechsler Adult Intelligence Scale). Nous disposons de 37 observations mesurées sur 4 dimensions : « Information », le degré de connaissance associée à la culture ; « Similarities », la capacité d’abstraction verbale ; « Arithmetic », le calcul mental ; « Picture.Completion », la capacité à percevoir les détails visuel. Nous cherchons à caractériser la liaison entre INFORMATION et SIMILARITIES, les variables de contrôle seront ARITHMETIC et PICTURE.COMPLETION.
Mots clés : corrélation, corrélation de Pearson, corrélation de rangs, rho de Spearman, corrélation partielle
Composants : LINEAR CORRELATION, SPEARMAN’S RHO, PARTIAL CORRELATION
Lien : fr_Tanagra_Partial_Correlation.pdf
Données : wechsler_adult_intelligence_scale.xls
Références :
R. Rakotomalala, « Analyse de corrélation – Etudes des dépendances, variables quantitatives », Analyse_de_Correlation.pdf
S. Rathbun, A. Wiesner, « STAT 505 – Applied Multivariate Statistical Analysis », The Pennsylvania State University, Lesson 7 : Partial Correlations
Régression PLS – Comparaison de logiciels
2008-05-25 (Tag:1033476965183689903)
Se comparer aux autres est toujours une bonne manière de faire avancer un logiciel.Pour valider les implémentations. C’est un point essentiel. Bien que l’on s’appuie sur les mêmes références bibliographiques, que l’on met en place les mêmes algorithmes, les choix de programmation ne sont pas anodins (la gestion des conditions de convergence par exemple). Une manière simple de valider l’implémentation est, outre la documentation des algorithmes utilisés et la publication du code, de voir ce qui se passe avec les autres outils.
Pour améliorer la présentation de résultats. Il y a certains standards à respecter dans la production des rapports, consensus initié par les ouvrages de référence et/ou le(s) logiciel(s) leader(s) dans le domaine. Les utilisateurs ont besoin de repères.
Notre implémentation de la Régression PLS repose essentiellement sur l’ouvrage de M. Tenenhaus (1998) qui, lui même, fait beaucoup référence au logiciel SIMCA-P. Profitant de l’accès à une version gratuite sur le site de l’éditeur (version 11 - limitée dans le temps), nous avons voulu comparer nos résultats sur un jeu de données. Nous avons étendu cette comparaison à d’autres logiciels (SAS avec la PROC PLS, SPAD avec le composant PLS, le logiciel R avec le package PLS).
Cette étude nous a emmené à introduire un nouveau composant dans Tanagra 1.4.24 (PLSR). Il intègre dans un cadre unique les composants PLS FACTORIAL, qui produit les scores factoriels, et PLS REGRESSION, qui effectue les prédictions. De plus, le mode de présentation des résultats, les noms des tableaux entre autres, est aligné sur les références anglo-saxonnes. Pour cela, nous nous sommes beaucoup appuyés sur les documents disponibles sur le site web de SIMCA-P (manuel de référence et tutoriel), et sur la description de D. Garson qui, inlassablement, produit toujours des documents d’une qualité extraordinaire.
Enfin, ce didacticiel permet d’approfondir la lecture et l’interprétation des résultats de la régression PLS. Le précédent était peut être un peu trop laconique. On se rend compte, dans ce nouveau document, de la richesse de l'approche qui constitue aussi une méthode factorielle : les observations sont projetés dans un nouvel espace qui permet de mieux expliciter les relations entre les variables, de mieux situer les proximités entre les individus.
Mots clés : régression pls, comparaison de logiciels
Composants : PLSR, VIEW DATASET, CORRELATION SCATTERPLOT, SCATTERPLOT WITH LABEL
Lien : fr_Tanagra_PLSR_Software_Comparison.pdf
Données : cars_pls_regression.xls
Références :
M. Tenenhaus, « La régression PLS – Théorie et pratique », Technip, 1998.
D. Garson, « Partial Least Squares Regression », from Statnotes: Topics in Multivariate Analysis. Retrieved 05/18/2008.
UMETRICS. SIMCA-P for Multivariate Data Analysis.
Détection (univariée) des points aberrants
2008-05-24 (Tag:5601183425082123409)
Dans le processus Data Mining, la détection et le traitement des points aberrants sont incontournables lors de la préparation des données, ou même après coup, pour analyser et valider les résultats.On parle de point aberrant (point atypique) lorsque qu’un individu prend une valeur exceptionnelle sur une variable (ex. un client d’une banque aurait 158 ans) ou sur des combinaisons de variables (ex. un athlète de 12 ans aurait effectué le 100 m en 10 secondes). Ces points sont problématiques car ils peuvent biaiser les résultats, notamment pour les méthodes basées sur des distances entre individus, ou plus dramatiquement encore, des distances par rapport à des barycentres. Il importe donc d’identifier ces individus et de les considérer attentivement.
Dans ce didacticiel, nous présentons le composant UNIVARIATE OUTLIER DETECTION destiné à détecter les points atypiques sur chacune des variables, prises individuellement.
Les techniques intégrées dans ce composant sont largement inspirées du texte sur le site de NIST. Nous essayerons de les combiner au mieux avec les statistiques descriptives dans ce document. On se rendra vite compte que des stratégies simples, notamment les approches graphiques, sont au moins aussi intéressantes finalement. Les techniques numériques ne sont réellement décisives que dans le cadre du traitement automatisé de fichiers comportant de très nombreuses colonnes. Dans ce cas, leurs indications nous permettent de nous orienter rapidement vers les variables à problèmes.
Enfin, notre composant choisit d’exclure les observations atypiques. C’est une solution possible mais ce n’est certainement pas la panacée. Il y a d’autres stratégies : la transformation des données, en rendant symétrique la distribution, on atténue l’écartement des queues de distribution ; une transformation plus radicale encore, le passage au rangs ; l’utilisation de techniques appropriées, peu sensibles aux points aberrants (ex. dans le data mining, plutôt qu’une analyse discriminante, on préfèrera les arbres de décision s’il y a profusion de points atypiques)...
Mots clés : point aberrant, point atypique
Composants : MORE UNIVARIATE CONT STAT, SCATTERPLOT WITH LABEL, UNIVARIATE OUTLIER DETECTION, UNIVARIATE CONT STAT
Lien : fr_Tanagra_Outliers_Detection.pdf
Données : body_mass_index.xls
Référence :
NIST/SEMATECH, « e-Handbook of Statistical Methods », Section 7.1.6, « What are outliers in the data ? »
R. High, "Dealing with 'Outliers': How to Maintain Your Data's Integrity"
Analyse Discriminante PLS – Etude comparative
2008-05-14 (Tag:6780785170361002898)
La régression PLS est une technique de régression qui vise à prédire les valeurs prises par un groupe de variables Y (variables à prédire, variables cibles, variables expliquées) à partir d’une série de variables X (variables prédictives, les descripteurs, variables explicatives). Définie à l’origine pour le traitement des variables cibles continues, la Régression PLS peut être transposée à la prédiction d’une variable qualitative, de différentes manières, on parle « d’analyse discriminante PLS ». Elle fait alors preuve des qualités qu’on lui connaît habituellement, essentiellement la capacité à traiter un espace de représentation à très forte dimensionnalité, avec un grand nombre de descripteurs bruités et/ou redondants.Ce document fait suite à un précédent didacticiel où nous présentions différentes méthodes supervisées basées sur la Régression PLS. L’objectif est de montrer le comportement de l’une d’entre elles, PLS-LDA, dans un contexte où le nombre de descripteurs est élevé par rapport au nombre d’observations. Le ratio reste « raisonnable » (278 variables prédictives pour 232 observations en apprentissage). Nous pouvons néanmoins voir se dessiner dans cette expérimentation les principaux traits du traitement de ce type de données où, finalement, la maîtrise de la variance du classifieur est l’enjeu majeur. Pour confirmer cette idée, nous opposerons PLS-LDA à des méthodes éprouvées telles que les SVM (Support Vector Machine, Librairie LIBSVM, Fan et al., 2005), les Random Forest (Breiman, 2001), ou… l’analyse discriminante linéaire (Fisher, 1936 - combinée avec une sélection de variables judicieuse, cette dernière se révèle être une compétitrice redoutable dans notre étude).
Nous reproduisons dans ce didacticiel le schéma de comparaison de classifieurs déjà mis en avant dans un de nos didacticiels. Nous forçons un peu le trait en intégrant un plus grand nombre de descripteurs. Les méthodes réputées stables devraient plus se démarquer. Nous intégrons de plus de nouvelles méthodes dans le comparatif, notamment les méthodes dérivées de la Régression PLS, peu connues en apprentissage automatique.
Mots clés : régression pls, analyse discriminante linéaire, apprentissage supervisé, support vector machine, SVM, random forest, forêts aléatoires, méthode des plus proches voisins, nearest neighbor
Composants : K-NN, PLS-LDA, BAGGING, RND TREE, C-SVC, TEST, DISCRETE SELECT EXAMPLES, REMOVE CONSTANT
Lien : fr_Tanagra_PLS_DA_Comparaison.pdf
Données : arrhytmia.bdm
Références :
S. Chevallier, D. Bertrand, A. Kohler, P. Courcoux, « Application of PLS-DA in multivariate image analysis », in J. Chemometrics, 20 : 221-229, 2006.
M. Tenenhaus, « La régression PLS – Théorie et Pratique », Technip, 1998.
Garson, « Partial Least Squares Regression (PLS) », http://www2.chass.ncsu.edu/garson/PA765/pls.htm
Analyse Discriminante PLS
2008-05-08 (Tag:8652167614404831451)
La régression PLS est une technique de régression qui vise à prédire les valeurs prises par un groupe de variables Y à partir d’une série de variables X. La régression PLS a été définie à l’origine pour les problèmes de prédictions sur des variables cibles quantitatives. Il aurait été dommage de ne pas exploiter ses qualités, notamment sa capacité à appréhender des dimensionnalités très élevées, en apprentissage supervisé où, rappelons le, la variable cible est catégorielle.Dans ce didacticiel, nous présentons plusieurs variantes de la régression PLS dédiées à la prédiction d’une variable catégorielle. Elles sont regroupées sous l’appellation générique de « Analyse Discriminante PLS ». Elles reposent sur le même principe : dans un premier temps, nous codons la variable à prédire catégorielle à l’aide d’une série d’indicatrices correspondant à ses modalités (codage disjonctif complet) ; dans un second temps, nous présentons le tableau de données, Y composé des indicatrices, X des descripteurs, à l’algorithme PLS. Les variantes diffèrent (1) par le type de codage et la valeur des codes utilisés lors de la constitution du tableau Y ; (2) par l’exploitation des résultats de la régression PLS lors de la phase de classement.
Ce didacticiel vise avant tout à présenter les techniques et à donner les repères de lecture des résultats. Nous utiliserons donc un jeu de données très simple pour faciliter la lecture. Dans un prochain document, nous utiliserons des données autrement plus difficiles à appréhender, avec une dimensionnalité élevée au regard du nombre d’observations. Nous constaterons alors l’excellent comportement de l’Analyse Discriminante PLS qui soutient la comparaison face à des méthodes fortement régularisées telles que les SVM (Support Vector Machine).
Mots clés : régression pls, analyse discriminante, apprentissage supervisé
Composants : C-PLS, PLS-DA, PLS-LDA
Lien : fr_Tanagra_PLS_DA.pdf
Données : breast-cancer-pls-da.xls
Références :
S. Chevallier, D. Bertrand, A. Kohler, P. Courcoux, « Application of PLS-DA in multivariate image analysis », in J. Chemometrics, 20 : 221-229, 2006.
M. Tenenhaus, « La régression PLS – Théorie et Pratique », Technip, 1998.
Garson, « Partial Least Squares Regression (PLS) », http://www2.chass.ncsu.edu/garson/PA765/pls.htm
Programmer un composant dans TANAGRA
2008-04-21 (Tag:4656190260109387859)
L’intérêt de l’ « open source » est de pouvoir intervenir dans le logiciel pour ajouter de nouvelles fonctionnalités.Dans le cas de Tanagra, il s’agit de rajouter une nouvelle méthode de Data Mining c.-à-d. rajouter un nouveau composant dans le logiciel. Il peut profiter des calculs réalisés en amont, il peut aussi proposer des résultats réutilisables en aval. Bref, son insertion parmi les outils déjà disponibles devrait lui permettre de tirer parti au maximum de l’environnement de travail.
Dans ce didacticiel, nous détaillons les étapes pour créer un composant de calcul de la moyenne sur les variables sélectionnées. L’objectif est modeste. Mais en détaillant l’exemple, nous accédons aux principales informations qui permettront à tout programmeur de démarrer dans l’implémentation de nouvelles méthodes de traitement de données dans Tanagra.
La totalité du projet, incluant l’unité du nouveau composant et la version compilée du prototype est accessible en ligne. Le fichier de données ayant servi aux tests est intégré dans l’archive.
Lien : fr_Ajouter_Composant_Dans_Tanagra.pdf
Fichiers du projet : exemple_ajouter_composant_dans_tanagra.zip
Compiler le projet Tanagra
2008-04-19 (Tag:3077906623140444585)
Ce document décrit la compilation du projet TANAGRA avec la version "Edition Personnelle" de Delphi 6.0 (version gratuite).Les étapes sont détaillées :
1. Chargement et installation du compilateur et des patches
2. Chargement et installation des bibliothèques externes (LMD TOOLS SE et TEE CHART)
3. Préparation du répertoire de compilation
4. Organisation du code source sur le disque dur
5. Chargement du projet dans DELPHI
6. Configuration du répertoire de sortie (.exe et .dcu)
7. Compilation
Tanagra est développé avec Delphi. Pourquoi ? C’est une question qui revient souvent.
Pour pleins de raisons, la principale étant simplement les affinités personnelles. Cela fait près de 20 ans que je programme en Pascal (procédural, puis objet). DELPHI me permet de développer des applications d’excellent niveau. Je ne vois pas d’intérêt à changer pour suivre telle ou telle mode. Et puis, du coup, c’est un des très rares projets de Data Mining « open source » développé en DELPHI (le seul à ma connaissance). La grande majorité des autres projets sont développés en JAVA, qui est très bien aussi, je n’en doute pas.
Il est possible de le faire passer sur les versions plus récentes du compilateur. Un internaute m’a envoyé une version du code que l’on peut compiler avec DELPHI 7.0. Il a également substitué la bibliothèque libre (open source) JEDI à LMD TOOLS SE en reprenant la grande majorité des boîtes de dialogue. Cela concourt à une meilleure évolutivité du projet. Ce code source pour DELPHI 7.0 est accessible sur simple demande. Pour ma part, je ne l’ai pas adopté, car pour des raisons qui m’échappent totalement, JEDI pose problème à mon compilateur. Elle m’obligeait à réinstaller complètement la bibliothèque à chaque démarrage de DELPHI. Ce n’était pas tenable.
Lien : fr_Guide_Compilation_Tanagra.pdf
Interpréter la « valeur test »
2008-04-18 (Tag:3904758917416510797)
La « valeur test » est un indicateur qui permet de hiérarchiser les variables lors de la caractérisation univariée des groupes, décrites par la modalité d’une variable (ex. qu’est ce qui caractérise les personnes soufrant de telle maladie), ou issue du calcul (un groupe défini par une classification automatique par exemple).Grosso modo, il s’agit ni plus ni moins que d’une statistique de test de comparaison de paramètres calculés dans le sous échantillon associé au groupe et dans la totalité de l’échantillon : test de comparaison de moyennes lorsque la variable est quantitative, test de comparaison de proportions lorsque la variable est catégorielle. A la différence que les données ne sont pas indépendantes, le sous échantillon constitue une fraction de l’échantillon initial.
Dans ce didacticiel, nous mettons en avant l’indicateur « valeur test » pour la caractérisation de personnes souffrant d’une maladie cardiovasculaire. Nous détaillons les calculs, suites aux demandes répétées d’utilisateurs. La mesure est peu connue, elle pourtant très pratique. Notre texte repose principalement sur descriptif, accompagné de justifications théoriques, proposé dans l’ouvrage de Lebart et al. (2000).
Mots clés : valeur test, caractérisation de classes, clustering, analyse factorielle
Composants : Group characterization
Lien : fr_Tanagra_Comprendre_La_Valeur_Test.pdf
Données : heart_disease_male.xls
Référence :
Alain MORINEAU, "Note sur la Caractérisation Statistique d'une Classe et les Valeurs-tests", Bulletin Technique du Centre de Statistique et d'Informatique Appliquées, Vol 2, no 1-2, p 20-27, 1984 (http://www.deenov.com/analyse-de-donnees/documents/article-valeur-test.aspx).
L. Lebart, A. Morineau, M. Piron, « Statistique exploratoire multidimensionnelle », Dunod, 2000 ; pages 181 à 184.
Régression logistique ordinale
2008-04-11 (Tag:2057708304713774650)
La régression logistique est une technique très populaire pour analyser les dépendances entre une variable à expliquer (dépendante, endogène) binaire et une ou plusieurs variables explicatives (indépendantes, exogènes) quantitatives et qualitatives ordinales ou nominales.La généralisation à une variable dépendante qualitative nominale est relativement simple. On parle dans ce cas de régression logistique multinomiale.
La situation est un peu plus complexe lorsqu’il s’agit de modéliser une liaison impliquant une variable dépendante ordinale. Pléthores d’interprétations sont possibles, allant de l’impasse sur le caractère ordinal afin de revenir simplement au modèle multinomial, à l’assimilation de la variable à prédire à une variable quantitative, dans ce cas la régression linéaire multiple devrait suffire. Entre ces deux cas extrêmes existent différentes approches. Dans ce didacticiel, nous étudierons essentiellement les LOGITS adjacents et les LOGITS cumulatifs. On parle alors de régression logistique polytomique à variable dépendante ordinale.
Pour étudier ces techniques, qui ne sont pas à ce jour programmées dans Tanagra (jusqu'à la version 1.4.22 en tous les cas), nous utilisons le logiciel R, accessible librement en ligne. Il s’agit d’un logiciel de statistique disposant d’un interpréteur de commande et d’un vrai langage de programmation. Il est particulièrement performant grâce au système des packages, des modules externes compilés, qui permettent de compléter sa bibliothèque de fonctions statistiques. Dans notre étude, nous utiliserons en priorité le package VGAM, il élargit de manière significative les dispositions de R en matière de régression généralisée.
Mots clés : régression logistique polytomique, régression logistique ordinale, logiciel R
Composants : -
Lien : didacticiel_Reg_Logistique_Polytomique_Ordinale.pdf
Données : hypertension.txt
Références :
R. Rakotomalala, « Régression logistique polytomique »
A. Slavkovic, « Multinomial Logistic Regression Models – Adjacent-Category Logits - The proportional odds cumulative logit model», in « STAT 504 – Analysis of Discrete Data », Pensylvania State University, 2007.
Régression logistique binaire
2008-04-11 (Tag:5738566435942851270)
La régression logistique est une technique supervisée. Elle vise à expliquer et prédire l’appartenance à une classe (groupe) prédéfinie à partir d’une série de descripteurs. Le plus souvent nous traitons une variable à prédire binaire. La régression logistique est une technique semi-paramétrique dans le sens où les hypothèses sont émises sur les rapports de distributions conditionnelles. Elle a donc un champ d’application théorique plus large que l’analyse discriminante par exemple. Elle est adaptée entre autres aux cas où les descripteurs sont des mélanges de variables quantitatives et des indicatrices 0/1. La régression logistique se démarque également par la richesse des interprétations des coefficients que l’on peut mettre en avant à la lecture des résultats, pour peu que l’on code de manière appropriée les variables.
Ce didacticiel montre la mise en œuvre de la régression logistique, la lecture des résultats et l’évaluation des performances en prédiction. Tout comme le didacticiel sur l’analyse discriminante (la structure de présentation est exactement la même), il est réalisé sous la forme d’une démonstration animée.
Mots clés : régression logistique, validation croisée, évaluation de l’erreur
Composants : Binary logistic regression, Cross-validation
Lien : Vidéo
Données : prematures.xls
Références :
R. Rakotomalala, « Régression logistique »
Analyse discriminante linéaire
2008-04-11 (Tag:3853379008755237118)
L’analyse discriminante linéaire (ADL) est une technique supervisée. Elle vise à expliquer et prédire l’appartenance d’un individu à une classe (groupe) prédéfinie à partir d’une série de descripteurs.
L’analyse discriminante est une technique paramétrique. Elle repose sur l’hypothèse de distribution conditionnelle gaussienne des variables c.à-d. on considère que les nuages de points associés à chaque groupe sont distribués selon une loi normale multidimensionnelle. L’analyse discriminante linéaire introduit une hypothèse supplémentaire, les nuages conditionnels doivent avoir une forme identique. On peut penser que ces hypothèses sont très restrictives, empêchant toute utilisation pratique. On se rend compte que la méthode est relativement robuste. On comprend mieux pourquoi lorsque l’on considère le problème sous un angle géométrique, l’analyse discriminante linéaire cherche avant tout à tracer une droite de séparation entre les groupes. Les hypothèses vont surtout influer sur le positionnement de la droite dans l’espace de représentation.
Avec ce didacticiel, nous dérogeons à notre schéma habituel. Plutôt que de produire un texte rédigé avec des copies d’écran (format PDF), nous montrons directement la mise en œuvre de l’analyse sous forme de démonstration animée. L’appréhension du document est un peu différente. Je pense que cette approche est complémentaire avec les PDF. Le didacticiel montre comment introduire l’analyse discriminante, comment sélectionner manuellement les bonnes variables (avec une méthode très basique), et par la suite, comment évaluer les performances en prédiction à l’aide de la validation croisée.
Mots clés : analyse discriminante linéaire, analyse discriminante prédictive, validation croisée, évaluation de l’erreur
Composants : Linear Discriminant Analysis, Cross-validation
Lien : Vidéo
Données : prematures.xls
Références :
R. Rakotomalala, "Cours Analyse discriminante"
Analyse de variance de Friedman
2008-04-08 (Tag:4442938246432410956)
L’analyse de variance de Friedman (Friedman’s two-way ANOVA by ranks) est un test de comparaison de populations sur échantillons appariés.Dans notre exemple, il s’agit d’apprécier les performances de conférenciers selon 3 types de supports. Chaque individu a été noté dans les 3 circonstances. On veut savoir si le support a une influence sur la qualité de la présentation.
Les échantillons ne sont pas indépendants. Nous devons en tenir compte en éliminant les disparités dues aux conférenciers. Nous avons une analyse de variance à 2 facteurs : le premier est le « type de support », le second est le « conférencier ». Si nous omettons ce second facteur c.-à-d. si nous considérons que les échantillons sont indépendants, l’ANOVA classique peut aboutir à des conclusions différentes. C’est le cas sur nos données.
Mots clés : comparaison de populations, échantillons appariés, analyse de variance, ANOVA
Composants : Friedman’s ANOVA by Rank, One-way ANOVA, Kruskal-Wallis 1-way ANOVA
Lien : fr_Tanagra_Friedman_Anova.pdf
Données : howell_book_friedman_anova_dataset.zip
Références :
R. Ramousse, M. Le Berre, L. Le Guelte, « Introduction aux Statistiques », Section 4.3, « K échantillons – Cas de k échantillons appariés »
Wikipedia, « Friedman test »
Tests d’adéquation à la loi normale
2008-04-06 (Tag:2937759817751563430)
Un test d’adéquation permet de statuer sur la compatibilité d’une distribution observée avec une distribution théorique associée à une loi de probabilité. Il s’agit de modélisation. Nous résumons une information brute, les données observées, à l’aide d’une fonction analytique paramétrée. L’estimation des valeurs des paramètres est souvent un préalable au test.Parmi les tests d’adéquation, la conformité à la loi normale (loi de Laplace Gauss, loi gaussienne) tient une place importante. En effet, l’hypothèse de normalité sous-tend souvent de nombreux tests paramétriques. En toute rigueur, s’assurer de la compatibilité des données avec la loi normale devrait être un préalable obligatoire. Dans la pratique, fort heureusement, ce n’est pas vrai. Grâce à la notion de robustesse, les procédures statistiques restent valables même si l’on s’écarte plus ou moins des hypothèses initiales.
Dans ce didacticiel, nous montrons comment mettre en œuvre les tests de conformité à la loi normale dans Tanagra. Plusieurs procédures sont disponibles. Nous utilisons des données artificielles pour mieux situer les résultats.
Mots clés : test d’adéquation à la loi normale, conformité à la loi normale, test de Shapiro-Wilk, test de Lilliefors, test d’Anderson-Darling, test de d’Agostino
Composants : More Univariate cont stat, Normality Test
Lien : fr_Tanagra_Normality_Test.pdf
Données : normality_test_simulation.xls
Référence : R. Rakotomalala, « Tests de normalité – Techniques empiriques et tests statistiques », Université Lumière Lyon 2.
Comparaison de moyennes
2008-04-06 (Tag:3596555303336186739)
Le test de comparaison de moyennes est un classique de la statistique paramétrique.Etant entendu que les distributions sont gaussiennes, si on conclut que les moyennes sont significativement différentes, on peut en déduire que les populations parentes ne sont pas les mêmes.
La statistique du test suit une loi de Student. Les degrés de libertés dépendent de l’hypothèse d’égalité des variances dans les sous populations.
Dans ce didacticiel, nous comparons la moyenne de la consommation de véhicules selon qu’elles proviennent des USA ou du Japon. Nous rapprochons nos résultats avec ceux du logiciel du NIST qui est une référence pour les calculs scientifiques.
Mots clés : comparaison de populations, test de comparaison de moyenne, loi de Student
Composants : T-Test, T-Test Unequal Variance
Lien : fr_Tanagra_Two_Sample_T_Test_For_Equal_Means.pdf
Données : auto83b.xls
Référence : NIST/SEMATECH, « e-Handbook of Statistical Methods », Section 7.3.1 « Do two processes have the same mean ? ».
MANOVA
2008-04-05 (Tag:8229451075566127870)
L’analyse de variance multivariée consiste à comparer les barycentres, des moyennes calculées sur plusieurs variables, de K populations. C’est une généralisation multidimensionnelle de l’analyse de variance.Le plus important à retenir est qu’elle ne peut pas se décomposer en plusieurs tests unidimensionnels, pour la simple raison que les variables ne sont pas indépendantes.
Dans ce didacticiel, nous montrons la mise en œuvre du test MANOVA sur un petit fichier à deux variables tiré du livre de Tomassone et al. (1988). Les résultats montrent que, effectivement, le test MANOVA et les séquences de tests ANOVA sur chaque dimension peuvent produire des résultats contradictoires.
Notons, cela est dans le support en référence, que le test MANOVA peut être utilisé en analyse discriminante prédictive pour évaluer la séparabilité des groupes, et pour sélectionner les variables pertinentes.
Mots clés : comparaison de populations, analyse de variance multivariée
Composants : One-way ANOVA, One-Way MANOVA
Lien : fr_Tanagra_Manova.pdf
Données : tomassone_p_29.xls
Références :
F. Carpentier, « Introduction à l'Analyse de Variance Multivariée (MANOVA) » (avec illustrations sous R et STATISTICA), Université de Brest.
R. Palm, « L’analyse de le variance multivariée et l’analyse canonique discriminante : principes et applications ».
R. Rakotomalala, « Analyse linéaire discriminante ».
Analyse de variance et comparaison de variances
2008-04-05 (Tag:4466877440855993007)
L’analyse de variance (ANOVA) est, comme son nom ne l’indique pas du tout, un test statistique qui vise à comparer la moyenne d’une variable dans K sous populations. Il s’agit de la généralisation du test de comparaison de 2 moyennes. Il est paramétrique, il repose de plus sur l’hypothèse d’égalité de variance.Dans ce didacticiel, nous montrons comment mettre en œuvre l’analyse de variance dans Tanagra. Nous montrons aussi comment procéder au test de comparaisons de variances, qui devrait être un préalable systématique à l’ANOVA. Dans la pratique, ce type de test est souvent superflu, l’ANOVA est plutôt robuste, et nous pouvons en améliorer le comportement en équilibrant les sous échantillons. Enfin, les tests de comparaisons de variance eux même sont paramétriques, et certains ne sont absolument pas robustes.
Le fichier GEAR a été récupéré sur le site (NIST/SEMATECH e-Handbook of Statistical Methods). La description sur le site n’est pas très explicite quant à la nature exacte de ces données. De notre point de vue nous considérons qu’il s’agit d’évaluer des engrenages produits par 10 machines outils différentes : nous disposons donc d’un prélèvement de 10 lots de 10 unités (100 observations). Plusieurs questions peuvent être posées : (1) est-ce que le diamètre moyen des engrenages est le même d’une machine à l’autre, (2) la variabilité du diamètre est-elle la même dans chaque lot ?
L’intérêt de ce fichier est que NIST propose ses propres résultats qui font référence au sein de notre communauté.
Mots clés : comparaison de populations, analyse de variance, test de comparaison de variances, test de bartlett, test de levene, test de brown-forsythe
Composants : One-way ANOVA, Bartlett’s test, Levene’s test, Brown-Forsythe test
Lien : fr_Tanagra_Anova_and_Tests_for_Equality_of_Variances.pdf
Données : gear_data_from_nist.xls
Référence : NIST/SEMATECH, « e-Handbook of Statistical Methods », Chapitre 7 « Product and Process Comparisons ».
Tests non paramétriques
2008-04-05 (Tag:4660348476119634876)
Les tests non paramétriques font partie de la statistique inférentielle. Ils ont pour particularité de ne pas effectuer d’hypothèses sur la distribution des données, ils n’ont pas besoin, de ce fait, d’estimer les paramètres de la population.Ces tests répondent néanmoins aux problèmes classiques de tests d’hypothèses : comparaisons de populations sur échantillons indépendants, comparaison de population sur échantillons appariés, test de significativité de l’association etc. Notre implémentation repose en grande partie sur l’excellent ouvrage de Siegel et Castellan (1988).
Notons que si les tests paramétriques sont notoirement plus puissants lorsque les hypothèses de distributions sont validées, les tests non paramétriques ne sont pas pour autant mauvais dans ce cas. Nous pouvons donc les mettre en œuvre dans un contexte plus étendu. Certains, comme le test de Kuskal-Wallis, se comportent quasiment aussi bien que leur homologue paramétrique quand bien même les données seraient compatibles avec l’hypothèse de distribution des données.
Notre fichier décrit 300 ménages à l’aide de 5 variables (salaire de l’homme, salaire de la femme, revenu du ménage, type d’habitation et le fait de disposer d’un jardin ou pas). En vérité, les problèmes mis en avant dans ce didacticiel sont pour la plupart plus ou moins saugrenus, l’essentiel est de montrer la mise en œuvre des techniques sur un jeu de données. Pour la lecture et l’interprétation qualitative des résultats, nous conseillons le site web exceptionnel indiqué en référence. Il propose de plus des macros et des classeurs dédiés aux tests non paramétriques sous un tableur.
Mots clés : statistiques non paramétriques, comparaison de populations, analyse de variance, mesures d’association, test de wald et wolfowitz, test de mann et whitney, test de kruskal et wallis, corrélation, rho de spearman, tau de kendall, test des signes, test de rangs signés de wilcoxon
Composants : Mann-Whitney Comaprison, Wald-Wolfowitz Runs Test, Kruskal-Wallis 1-way ANOVA, One-way ANOVA, Spearman’s rho, Kendall’s tau, Sign Tes, Wilconxon Ranks Test, Paired T-Test
Lien : fr_Tanagra_Nonparametric_Statistics.pdf
Données : nonpametric_statistics_dataset.xls
Références :
S. Siegel, J. Castellan, « Nonparametric Statistics for the Behavioral Sciences », McGraw-Hill, 1988.
Ricco Rakotomalala, "Comparaison de populations - Tests non paramétriques".
H. Delboy, « Tests non paramétriques sous Microsoft Excel ».
Mesures d’association – Variables ordinales
2008-04-05 (Tag:1486040790174818832)
La manipulation d’une variable ordinale n’est pas facile. D’un côté, il s’agit bien d’une variable qualitative, le nombre de valeurs qu’elle peut prendre est réduit. Mais à la différence des variables nominales, les modalités sont ordonnées. De l’autre, nous ne pouvons pas l’assimiler à une variable quantitative, l’amplitude des écarts n’est pas quantifiable. Il faudra tenir compte de ces contradictions lors du choix des outils destinés à extraire de l’information à partir de ces données.Dans ce didacticiel, nous étudions la mise en œuvre de quelques mesures de dépendances entre 2 variables ordinales (Y et X) dans Tanagra. Ce document constitue le contrepoint d’un précédent didacticiel traitant des variables nominales. Le point de départ est toujours le tableau de contingence croisant les deux variables à analyser. Nous en extrayons les informations nécessaires à la construction des indicateurs. L’essence des mesures est en revanche complètement différente. Elles s’appuient sur la notion de comparaison par paires.
Nous définirons la variable Y comme la variable dépendante (expliquée) et X la variable indépendante (explicative). C’est important pour la lecture et l’interprétation des résultats, mais sans aucune incidence sur les calculs lorsque les mesures sont symétriques c.-à-d. lorsqu’elles fournissent la même valeur quand bien même le tableau de contingence serait transposé. Seul le d de Sommers, qui est une mesure asymétrique, tiendra compte explicitement du rôle des variables.
Dans la pratique, les mesures d’association pour variables sont toujours calculées à partir des effectifs du tableau de contingence. Dans ce cas, il n’est plus question d’intervertir les lignes (ou les colonnes) du tableau. Leur ordonnancement est déterminé par les modalités des variables.
Mots clés : association entre variables ordinales, tableau de contingence, gamma de goodman et kruskal, tau-c de kendall, d de sommers
Composants : Goodman Kruskal Gamma, Kendall Tau-c, Sommers d, Linear Correlation
Lien : fr_Tanagra_Measures_of_Association_Ordinal_Variables.pdf
Données : blood_pressure_ordinal_association.xls
Référence : R. Rakotomalala, « Etude des dépendances, Variables qualitatives – Tableau de contingence et mesures d’association », Université Lumière Lyon 2.
Mesures d’association – Variables nominales
2008-04-04 (Tag:1540723273305546743)
Pour quantifier le lien existant entre deux variables continues, nous utilisons généralement le coefficient de corrélation. Cet indicateur est très largement répandu, ses défauts et ses qualités sont largement connus.Lorsque nous voulons traiter deux variables catégorielles (variables nominales), les indicateurs sont moins répandus. Le point de départ est le tableau croisant les deux variables, le tableau de contingence, il recense les effectifs pour chaque combinaison de valeurs des variables.
A partir de ce tableau, plusieurs indicateurs peuvent être calculés. Ils permettent de caractériser, de différentes manières, les liens -- les associations -- existant entre les deux variables. Nous verrons dans ce didacticiel comment calculer ces différents indicateurs avec TANAGRA.
Les variables étant nominales, nous pouvons intervertir les lignes (les colonnes) du tableau sans modifier la valeur des indicateurs que nous présentons. En revanche, selon que la mesure est symétrique ou asymétrique, la transposition du tableau a une incidence sur le résultat.
Dans une première partie, nous présentons le test d’indépendance basé sur la statistique du KHI-2. Il permet de vérifier la significativité du lien, il est assez répandu. Le KHI-2 est plus riche qu’il n’y paraît, nous montrons comment le décomposer pour identifier les principales associations dans le tableau de contingence.
Dans la seconde partie, nous nous intéressons aux mesures asymétriques. Les variables ne jouent plus le même rôle dans ce cas, nous nous servons des valeurs prises par la première variable (en colonne par exemple) pour expliquer ou prédire les valeurs prises par la seconde variable (en ligne). L’idée est de mettre en avant la causalité.
Enfin, dans la troisième et dernière partie, nous présentons les mesures partielles. L’idée est de caractériser le lien entre deux variables Y et X en contrôlant les valeurs prises par une tierce variable Z c.-à-d. caractériser le lien entre Y et X conditionnellement aux valeurs prises par Z.
Mots clés : association entre variables nominales, tableau de contingence, test d’indépendance du khi-2, contributions au khi-2, t de tschuprow, v de cramer, association asymétrique, mesures pre (proportional reduction in error), tau de goodman et kruskal, u de theil, association partielle, u de theil partiel
Composants : Contingency Chi-Square, Goodman-Kruskal Tau, Theil U, Partial Theil U, Discrete select examples
Lien : fr_Tanagra_Measures_of_Association_Nominal_Variables.pdf
Données : fuel_consumption.xls
Référence : R. Rakotomalala, « Etude des dépendances, Variables qualitatives – Tableau de contingence et mesures d’association », Université Lumière Lyon 2.
Coefficient de corrélation linéaire
2008-04-04 (Tag:627582996664617298)
Calculer un indicateur et trier selon cet indicateur fait partie des tâches récurrentes de la fouille de données. Dans ce didacticiel, nous montrons comment mettre en place rapidement le calcul du coefficient de corrélation linéaire (1) d’une variable de référence avec une liste de variables, dans le cadre de la sélection de variables explicatives d’une régression par exemple ; (2) croisé entre plusieurs variables, cela peut être utilisé pour détecter les colinéarités entre variables explicatives d’une régression.Dans une deuxième partie, nous abordons le calcul de la corrélation partielle sur un grand nombre de variables. Pour rappel, la corrélation partielle Y,X/Z correspond au lien entre Y et X en contrôlant l’effet de Z c.-à-d. à valeur de Z constant, nous mesurons la liaison entre Y et X. Z joue le rôle de variable de contrôle, il peut y en avoir plusieurs.
La stratégie mise en avant dans Tanagra est de produire les résidus des régressions Y/Z et X/Z, puis de calculer la corrélation brute sur ces résidus. Cela nous permet de mieux organiser le diagramme de traitements. Un petit bémol cependant, une attention particulière doit être portée aux degrés de libertés du test de significativité dès lors que l’on fait intervenir une ou plusieurs variables de contrôle dans le calcul de la corrélation.
Mots clés : corrélation linéaire, corrélation partielle
Composants : Linear correlation, Residual scores
Lien : fr_Tanagra_Linear_Correlation.pdf
Données : cars_acceleration.xls
Références :
D. Garson, « Correlation », in Statnotes : Topics in Multivariate Analysis.
D. Garson, « Partial correlation », in Statnotes : Topics in Multivariate Analysis.
Régression PLS – Sélection du nombre d’axes
2008-04-04 (Tag:756344325800812232)
La sélection du nombre d’axes est un problème difficile dans la régression PLS. Ne disposant pas des outils de la statistique inférentielle, nous devons nous tourner vers les techniques de ré échantillonnage. Tanagra utilise la validation croisée pour optimiser les critères de prédiction.Nous avons donc introduit deux approches pour la détection de la solution optimale : la première est toujours fondée sur le Q2 conformément (strictement) au descriptif dans l’ouvrage de Tenenhaus (1998) ; la seconde est une variante qui teste si la réduction du PRESS (l’erreur quadratique en validation croisée pour chaque variable TARGET) est supérieure ou non à un seuil choisi par l’utilisateur. Le seuil de 20% permet de définir un comportement raisonnable sur les données que nous avons pu étudier. Tout cela est à améliorer bien sûr, l’accès au code source vous permettra d’apporter les améliorations souhaitées.
La procédure est intégrée dans le composant PLS SELECTION de Tanagra. Il a la particularité de ne pouvoir se brancher que sur les composants PLS dans le diagramme de traitements.
Mots clés : régression pls, analyse factorielle
Composants : PLS Factorial, PLS Selection
Lien : fr_Tanagra_PLS_Selecting_Factors.pdf
Données : protein.txt
Référence :
M. Tenenhaus, « La régression PLS – Théorie et pratique », Technip, 1998 ; page 83.
Tanagra : un logiciel open source
2008-04-03 (Tag:3530228608809260364)
Ce document correspond à la première présentation du logiciel Tanagra en janvier 2004, à l’occasion d’un séminaire au sein du laboratoire ERIC.L’idée est de décrire les enjeux et les contraintes qui pèsent sur les spécifications et la réalisation de Tanagra. Nous essayons de cerner les utilisateurs que l’on vise, les traitements types dans lesquels le logiciel peut être mis en avant, etc.
Un aspect très important est abordé lors de cet exposé : la nécessité pour les chercheurs de rendre accessibles les codes sources des prototypes servant aux publications. En effet, les développements théoriques sont souvent accompagnés d’expérimentations. Il est très important que les chercheurs puissent les reproduire, les modifier pour évaluer l’impact de tel ou tel paramétrage, les comparer avec d'autres implémentations d’un même algorithme, voire de les vérifier. Cela n’est possible que si le logiciel est en « open source ». D’une certaine manière, la publication du code sert aussi à valider les articles scientifiques.
Lien : slides_tanagra.pdf
Régression PLS
2008-04-02 (Tag:7482993680140840605)
La régression PLS peut être vue comme une alternative à la régression linéaire multiple. A la différence qu’elle est mieux régularisée, de ce fait elle sait gérer le problème de la colinéarité.La régression PLS peut être vue également comme une technique factorielle alternative à l’analyse canonique (qui elle même est une généralisation de l’analyse en composantes principales). A la différence qu’elle est asymétrique, on essaie bien d’expliquer les valeurs prises par un groupe de variables expliquées Y, à partir des valeurs d’un groupe de variables explicatives X.
La régression PLS est une technique performante. On peut exécuter sur de grands ensembles de données, particulièrement lorsque le nombre de variables est très élevé.
On pourrait énumérer ses qualités pendant longtemps encore. Entre autres, elle propose un dispositif efficace pour traiter les données manquantes. Cette fonctionnalité n’est cependant pas intégrée dans Tanagra (qui ne gère pas du tout les données manquantes, ça doit être fait en amont).
Ce didacticiel décrit, très succinctement, la mise en œuvre du composant PLS Regression. L’accent est mis sur les différents tableaux de résultats produits par le logiciel. L’ouvrage de Tenenhaus (1998) nous a servi de référence.
Mots clés : régression pls, analyse factorielle, régression linéaire multiple
Composants : PLS Regression
Lien : fr_Tanagra_PLS.pdf
Données : orange.bdm
Références :
M. Tenenhaus, « La régression PLS – Théorie et pratique », Technip, 1998.
S. Vancolen, « La régression PLS », Université de Neuchâtel.
H. Abdi, "Partial Least Square Regression".
Règles d’association - Orange, Tanagra et Weka
2008-04-02 (Tag:8049682819781708614)
Ce didacticiel décrit l’instanciation et le paramétrage des règles d’association dans les 3 logiciels.Ils s’accordent sur un point : ils prennent en entrée des données tabulaires « individus x variables » et procèdent en interne à un codage disjonctif complet. Chaque couple « attribut = valeur » devient un item candidat à la génération des règles.
Mots clés : règles d’association
Composants : A priori
Lien : fr_Tanagra_TOW_Association_Rule.pdf
Données : vote.txt
Références :
Voir « Les règles d’association – A priori »
Règles d’association avec Apriori PT
2008-04-02 (Tag:2745121124617634952)
La construction de règles d’association pose de problèmes de performances, tant en occupation mémoire qu’en temps de traitement. L’implémentation actuelle dans TANAGRA est relativement rapide, en revanche, elle est très gourmande en mémoire, au point de la saturer très rapidement dès que l’on a à produire un grand nombre de règles. De plus, l’affichage des règles en HTML est tributaire du composant d’affichage, un peu limité, au point que le temps consacré à l’affichage est parfois aussi important que le temps consacré à l’élaboration des règles.Il fallait donc se tourner vers un module très performant de construction des règles et proposer une nouvelle fenêtre d’affichage peu sensible au nombre de règles, fussent-elles de plusieurs centaines de milliers.
Sur la création des règles, j’ai découvert les travaux de Christian BORGELT. Il propose une implémentation réellement impressionnante. Traduire le code en DELPHI m’exposait aux risques de mauvaises interprétations de son travail, et donc d’introduction d’erreurs ; le passage par des DLL est également séduisant mais m’oblige à faire un travail de traduction des structures en C vers DELPHI, toujours hasardeux, pour la définition des unités d’import. J’ai donc décidé d’inaugurer une nouvelle approche avec cette nouvelle version, l’appel à un programme externe avec passage de fichiers temporaires. La rapidité de l’ensemble dépend en grande partie du temps consacré à l’écriture et à la lecture des fichiers temporaires. Force est de constater que le travail de Borgelt est réellement impressionnant. Au final, cette approche semble viable, du moins tant qu’il n’est pas nécessaire de produire des données qui seront par la suite utilisées dans le diagramme. Nous en montrons un exemple dans ce didacticiel.
L’autre point important était de créer une fenêtre de visualisation des règles qui ne s’effondre pas dès que leur nombre excède la centaine de milliers de règles, et qui par ailleurs, comporte des fonctionnalités de tri selon différents critères. Nous avons donc élaboré un outil simple qui permet de récupérer les sorties de Borgelt et d’afficher simplement les règles dans une fenêtre conviviale.
Après les commentaires des utilisateurs, je me suis rendu compte que l’implémentation distribuée par Borgelt, intégrée dans Tanagra, ne génère des règles qu’avec un seul item dans le conséquent. La limitation est inhérente au code source, on ne peut pas la dépasser en modifiant simplement les paramétrages.
Quoiqu’il en soit, dès que la base est d’une taille relativement importante, c’est bien ce composant qu’il faut utiliser en priorité.
Mots clés : règles d’association, traitement de grandes bases
Composants : A priori PT
Lien : fr_Tanagra_A_Priori_Prefix_Tree.pdf
Données : assoc_census.zip
Références :
C. Borgelt, "A priori - Association Rule Induction / Frequent Item Set Mining"
Voir « Les règles d’association – A priori »
Règles d’association « supervisées »
2008-04-02 (Tag:5285836493000762331)
Dans de très nombreuses analyses, il est souvent nécessaire de caractériser un groupe d’individus. Dans le cadre de la classification automatique par exemple, après avoir la constitution des classes, nous devons les interpréter. Il s’agit d’identifier les caractéristiques communes aux observations situées dans le même groupe. Et c’est là que les difficultés commencent…Le composant GROUP CHARACTERIZATION joue ce rôle en calculant des statistiques descriptives comparatives entre le groupe qui nous intéresse et les autres groupes ou la totalité de l’échantillon. Bien que très instructif, cet outil est limité par le fait qu’il effectue essentiellement des comparaisons univariées, variable par variable, il ne permet pas de tenir compte des interactions entre les variables.
La seconde piste la plus souvent évoquée dans la littérature est l’analyse factorielle. Elle permet de « visualiser » les groupes dans les plans factoriels. La démarche est bien multivariée. En revanche, on se heurte à un second écueil, il faut maintenant interpréter les facteurs.
Dans ce didacticiel, nous montrons l’utilisation du composant SPV ASSOC TREE. Il permet de réaliser des caractérisations multivariées, mettant en oeuvre la conjonction de plusieurs variables. La méthode, très simple, s’appuie essentiellement sur le mécanisme des règles d’association dans lequel nous fixons la modalité que nous voulons voir dans le conséquent des règles.
Dans notre exemple, les classes sont définies a priori, elles sont désignées par une variable supplémentaire dans notre base. Elles auraient pu également, comme nous le signalons plus haut, être le produit d’un clustering en amont.
Mots clés : règles d’association, caractérisation des groupes, clustering, classification automatique
Composants : Group Characterization, Spv Assoc Tree
Lien : fr_Tanagra_Spv_Assoc_Tree.pdf
Données : vote.txt
Références :
Voir « Les règles d’association – A priori »
A PRIORI sur les bases transactionnelles
2008-04-02 (Tag:5807359709180363287)
Si les règles d’association peuvent être construites à partir d’un fichier « attribut-valeur » que l’on a recodé en interne, il arrive aussi que le fichier soit binaire par nature. C'est le cas des bases transactionnelles. Dans ce contexte, le recodage n’est absolument pas nécessaire, il faut traiter le fichier tel quel en se focalisant sur la présence des items dans les transactions.TANAGRA ne gère que les fichiers tabulaires, pour spécifier la présence ou absence d’un item par chaque transaction, on utilisera la valeur 0 (absence) et 1 (présence). Lors de l’importation, ces données étant numériques, il les importe comme une variable continue.
TANAGRA peut donc construire des règles d’association sur des variables continues, sachant qu’il interprète la valeur 0 comme une absence d’un item dans la transaction, et toute autre valeur (on s’attend à ce que ce soit 1 si le fichier est correctement construit) comme une présence.
Mots clés : règles d’association, algorithme a priori
Composants : A priori
Lien : Binary_A_Priori.pdf
Données : transactions.bdm
Références :
Voir « Les règles d’association – Algorithme A priori »
Règles d’association – Algorithme A PRIORI
2008-04-02 (Tag:6475028708751649323)
L’extraction des règles d’association est une technique de data mining relativement récente (Agrawal et Srikant, 1994). Elle a été définie initialement pour trouver des co-occurrences dans les bases transactionnelles, notamment pour analyser les fameux « tickets de caisse » des grandes surfaces. On s’est rendu compte très rapidement que la démarche pouvait être étendue à l’analyse des tableaux statistiques « individus x variables ».Si le principe de l’algorithme est assez simple, il en est tout autre en ce qui concerne son implémentation. Les principaux enjeux sont la gestion de la volumétrie : les bases à traiter sont en général très importantes ; et, a posteriori, le nombre de règles produites est très élevé, il devient vital de pouvoir les filtrer/trier avec des critères répondant directement aux besoins de l’utilisateurs.
Très rares sont les logiciels de Data Mining libres capables d’appréhender des grandes bases de données. Tanagra ne déroge pas à la règle. Les données sont chargées en mémoire, les structures intermédiaires pour l’extraction des itemsets et la production des règles sont également en mémoire. La machine est vite débordée, surtout si on paramètre mal la méthode.
Néanmoins, sur des bases relativement raisonnables, et avec un paramétrage adéquat, on peut très bien générer les règles d’association avec Tanagra. Dans un cadre pédagogique, il donne toute satisfaction.
Ce didacticiel décrit la mise en œuvre de l’algorithme sur une base « individus x variables ». Il montre l’influence du paramétrage sur le nombre de règles produites.
Mots clés : règles d’association, algorithme a priori
Composants : A priori
Lien : a_priori.pdf
Données : banque.bdm
Références :
R. Rakotomalala, « Les règles d’association ».
P.N. Tan, M. Steinbach, V. Kumar, « Introduction to Data Mining », Addison Wesley, 2006 ; chapitre 6, « Association analysis : Basic Concepts and Algorithms ».
Réseaux de neurones avec SIPINA, TANAGRA et WEKA
2008-04-02 (Tag:3401200820531381751)
Les réseaux de neurones sont des techniques d’apprentissage directement inspirés de l’observation du fonctionnement du cerveau humain. Au final, il s’agit de modélisation. On essaie de calculer les paramètres d’un modèle à partir d’un ensemble de données.Dans le cas de l’apprentissage supervisé, le perceptron multi-couches est certainement la technique la plus répandue. Il est très performant, pour peu qu’il soit bien paramétré. En revanche, il présente l’inconvénient d’être un modèle « boîte noire » c.-à-d. on ne perçoit pas, en tous les cas pas directement, le rôle des descripteurs dans la prédiction.
Dans ce didacticiel, nous montrons la mise en œuvre d’un perceptron dans 3 logiciels. Une fraction des données est réservée au calcul des coefficients, les poids synaptiques, une autre est utilisée pour en évaluer les performances. TANAGRA et WEKA fonctionnent de la même manière, l’apprentissage est lancé, l’utilisateur attend la fin des calculs. Le paramétrage est primordial dans ce cas, il faut définir une règle d’arrêt raisonnable.
Le déroulement de l’apprentissage, l’évolution de l’erreur de prédiction, est visible dans SIPINA. L’utilisateur a la possibilité d’interrompre les calculs. Lorsque par exemple il se rend compte que la courbe de l’erreur stagne sur un palier, et qu’il n’est plus nécessaire de poursuivre les itérations. C’est un plus considérable.
Nous utilisons le fichier IONOSPHERE.ARFF (source UCI IRVINE – format de données WEKA). Les données ont été d’emblée centrées et réduites pour nous affranchir des différences entre les techniques de pré-traitement mis en oeuvre par les logiciels. Le fichier comporte 351 observations, 33 descripteurs continus ; l’attribut classe est binaire.
Dans TANAGRA, nous en profitons pour comparer les performances du perceptron avec d’autres techniques (analyse discriminante linéaire, svm et régression logistique).
Mots clés : apprentissage supervisé, réseaux de neurones, perceptron multi couches, subdivision apprentissage test
Composants : Sampling, Supervised learning, Log-Reg TRIRLS, Linear Discriminant Analysis, C-SVC, Test
Lien : fr_Tanagra_TSW_MLP.pdf
Données : ionosphere.arff
Références :
R. Rakotomalala, « Réseaux de neurones artificiels – Perceptron simple et multi-couches ».
F. Denis, R. Gilleron, « Apprentissage à partir d’exemples – Notes de cours », chapitre 3, « Les réseaux de neurones »
Wikipédia, « Réseaux de neurones »
Apprentissage-test avec ORANGE, TANAGRA et WEKA
2008-04-02 (Tag:1778420535090799620)
Très souvent, pour résoudre un problème d’apprentissage supervisé, nous sommes emmenés à choisir entre plusieurs algorithmes d’apprentissage. Parmi les critères d’évaluation figurent la précision des méthodes sur un échantillon test. Pour une expérimentation rigoureuse, il est fortement conseillé d’utiliser les mêmes échantillons d’apprentissage et de test, ainsi les méthodes seront directement comparables deux à deux, il est même possible de caractériser leur manière de classer, cela peut être intéressant lorsque les coûts de mauvais classement ne sont pas symétriques.Dans ce didacticiel, nous montrons le détail des opérations sur les logiciels ORANGE, WEKA et TANAGRA. Nous verrons qu’ils procèdent avec une philosophie très différente, notamment dans la préparation des fichiers, mais au final nous obtenons des résultats similaires.
Nous avons choisi de mettre en compétition trois méthodes d’apprentissage pour illustrer notre propos : un SVM linéaire (Support Vector Machine), la régression logistique et un arbre de décision.
Nous utilisons le fichier BREAST (UCI IRVINE). Il comporte un attribut classe binaire (tumeur bénigne ou maligne), 9 descripteurs, tous continus, et 699 exemples.
Nous avons sélectionné 499 observations pour l’apprentissage, 200 pour le test. Nous utilisons la même subdivision pour nos trois logiciels, les résultats sont ainsi comparables d'un logiciel à l'autre.
Mots clés : apprentissage supervisé, arbres de décision, svm, régression logistique, évaluation des classifieurs, subdivision apprentissage test, Weka, Orange, comparaison de classifieurs
Composants : Select examples, Supervised learning, Binary logistic regression, C-RT, C-SVC, Test
Lien : fr_Tanagra_TOW_Predefined_Test_Set.pdf
Données : breast_tow.zip
Références :
R. Rakotomalala, « Méthodes de ré échantillonnage pour l’évaluation des performances ».
Arbres de décision avec ORANGE, TANAGRA et WEKA
2008-04-02 (Tag:4780054141764607419)
La très grande majorité des logiciels de data mining libre intègrent au moins un algorithme d’induction des arbres de décision. Pour la simple raison que c’est une technique très populaire et, somme toute, elle est relativement facile à programmer. On aurait tort de s’en priver.S’agissant de l’induction d’un arbre de décision, quel que soit le logiciel utilisé, nous devons impérativement passer par les étapes suivantes :
+ Importer les données dans le logiciel ;
+ Définir le problème à résoudre, c.-à-d. choisir la variable à prédire (l’attribut « classe ») et les descripteurs ;
+ Sélectionner la méthode d’induction d’arbres de décision, selon les logiciels et selon les implémentations, les résultats peuvent être différents ;
+ Lancer l’apprentissage et visualiser l’arbre ;
+ Utiliser la validation croisée pour évaluer la qualité du modèle induit.
Dans ce didacticiel, nous montrons que malgré les différences, la trame reste la même. Cela confirme l’idée qu’un bon data miner ne doit pas être dépendant de l’outil. Le plus important est de se fixer une démarche générique. La mise en œuvre d’un traitement ou d’une séquence de traitements doit obéir à des codes que l’on retrouve dans tout logiciel. Si on ne les retrouve pas, c’est le logiciel qu’il faut remettre en cause, pas l’utilisateur.
Mots clés : apprentissage supervisé, arbres de décision, évaluation des classifieurs, méthode de ré échantillonnage, validation croisée, Weka, Orange
Composants : Supervised learning, C-RT, Cross validation
Lien : fr_Tanagra_TOW_Decision_Tree.pdf
Données : heart.txt
Références :
R. Rakotomalala, " Arbres de décision ", Revue Modulad, 33, 163-187, 2005 (tutoriel_arbre_revue_modulad_33.pdf)
Courbe ROC avec ORANGE, TANAGRA et WEKA
2008-04-02 (Tag:3015418667763160745)
TANAGRA, ORANGE et WEKA sont trois logiciels de data mining gratuits. S’ils poursuivent le même objectif, permettre aux utilisateurs de définir une succession de traitements sur les données, ils présentent néanmoins des différences. C’est tout à fait normal. Leurs auteurs n’ont pas la même culture informatique, cela se traduit par des choix technologiques différents ; ils n’ont pas la même culture de la fouille de données, ce qui se traduit par un vocabulaire et par un mode de présentation des résultats parfois différents.Au-delà de leurs propres spécificités, ces outils permettent de définir les mêmes analyses et par conséquent produisent les mêmes résultats. La comparaison sera d’autant plus aisée qu’ils adoptent le même mode de représentation graphique des séquences d’opérations, à l’aide d’un graphe pour ORANGE et WEKA, à l’aide d’un arbre pour TANAGRA : chaque sommet représente un traitement, le lien entre chaque sommet représente le flux de données.
Dans ce didacticiel, nous montrons la construction de la courbe ROC à partir d’une régression logistique. Quel que soit le logiciel utilisé, nous devons impérativement passer par les étapes suivantes :
+ Importer les données dans le logiciel ;
+ Calculer les statistiques descriptives pour se donner une idée de la nature des données ;
+ Définir le problème à résoudre, c.-à-d. choisir la variable à prédire (l’attribut « classe ») et les descripteurs ;
+ Définir la modalité « positive » de la variable à prédire ;
+ Subdiviser le fichier en données d’apprentissage (70% par exemple), servant à construire le modèle de prédiction, et en données test (30 %), pour construire la courbe ROC ;
+ Choisir l’algorithme d’apprentissage, nous voulons mettre en œuvre la régression logistique, selon la méthode réellement implémentée dans le logiciel, c’est le principal point de différenciation, nous pouvons obtenir des résultats légèrement différents ;
+ Lancer l’apprentissage et visualiser les résultats ;
+ Elaborer la courbe ROC sur les données en test afin d’évaluer les performances en classement.
La progression peut ne pas être la même pour chaque logiciel. Néanmoins, à un moment ou un autre, il faudra passer par chacune des étapes ci-dessus, de manière explicite ou non, pour arriver à nos fins.
On retrouve dans un autre didacticiel l’utilisation de la courbe ROC lorsque l’on souhaite comparer les performances de classifieurs.
Mots clés : apprentissage supervisé, courbe roc, évaluation des classifieurs, Weka, Orange, subdivision apprentissage test
Composants : More Univariate cont stat, Sampling, Supervised learning, Log-Reg TRIRLS, Scoring, Roc curve
Lien : fr_Tanagra_Orange_Weka_Roc_curve.pdf
Données : ds1_10.zip
Références :
R. Rakotomalala – « Courbe ROC »
T. Fawcet – « ROC Graphs : Notes and Practical Considerations of Researchers »
Logiciels gratuits pour l’enseignement (déc.2005)
2008-04-02 (Tag:1428737419597411647)
Il y a pléthore de logiciels plus ou moins gratuits de Data Mining disponibles sur le web, de qualité assez inégale. On peut légitimement se poser la question de l’opportunité de leur utilisation dans l’enseignement supérieur. Quels sont leurs avantages et leurs inconvénients pour les cours et travaux dirigés ? Pénalise-t-on les étudiants qui, par la suite, iront dans le monde professionnel et seront confrontés à des logiciels commerciaux qu’ils n’auront jamais vus à l’université ?Pour répondre à ces interrogations, nous essayons de définir un cahier des charges des logiciels à utiliser pour l’enseignement de la fouille de données, nous en dégageons alors une série de critères que nous mettrons à contribution pour évaluer 5 logiciels totalement gratuits référencés sur le portail KDNUGGETS (ALPHA MINER, YALE, WEKA, ORANGE, TANAGRA). Nous nous pencherons plus particulièrement sur les 3 derniers et, pour donner un tour concret à l’exposé, nous accorderons une large place à l’étude de leurs fonctionnalités respectives à partir d’études de cas sur des fichiers de données.
Ce site reprend une présentation que j’ai réalisée il y a quelques années (décembre 2005). La grande majorité des commentaires émis restent d’actualité encore. J’ai noté néanmoins que dans la période récente, tant WEKA que ORANGE ont grandement amélioré leurs capacités de traitements.
Mots clés : logiciel libre de data mining, logiciel open source
Référence : R. Rakotomalala, « Les logiciels gratuits de data mining pour l’enseignement », Séminaire du Laboratoire ERIC, décembre 2005.
Arbres de régression
2008-04-02 (Tag:7418056214765640354)
La régression consiste à produire un modèle qui permet de prédire ou d’expliquer les valeurs d’une variable à prédire continue (endogène) à partir des valeurs d’une série de variables prédictives (exogènes), continues ou discrètes. La régression linéaire multiple est certainement l’approche la plus connue, mais d’autres méthodes, moins connues en économétrie mais plus populaire dans la communauté de l’apprentissage automatique, permettent de remplir cette tâche.Dans ce didacticiel nous présentons la méthode de régression par arbres de TANAGRA. La méthode implémentée est directement inspirée de CART (Breiman et al., 1984), dans sa partie régression (chapitre 8). L’arbre est élaboré en deux temps : une première phase d’expansion, pour construire l’arbre maximal ; une seconde phase de post élagage, destiné à réduire la taille de l’arbre, sans en diminuer la précision lorsqu’on la déploiera sur la population. Notre implémentation diffère légèrement dans la détection de l’arbre final. La préférence à la simplicité s’appuie sur une analyse de la courbe de la somme des carrés des résidus.
Petite particularité de ce didacticiel, nous traitons directement un fichier de données au format Weka (arff).
Mots clés : arbres de régression, arbres de décision, CART, post élagage
Composants : Regression tree
Lien : fr_Tanagra_Regression_Tree.pdf
Données : housign.arff
Référence : L. Breiman, J. Friedman, R. Olsen, C. Stone, « Classification and Regression Trees », Wadsworth International, 1984.
Points aberrants et influents dans la régression
2008-04-02 (Tag:8808838819036241580)
La validation est une étape clé de la modélisation. S’agissant de la régression linéaire multiple, parmi les multiples évaluations à mettre en place figure l’analyse des résidus, plus particulièrement la détection des points aberrants et influents.La distinction entre points aberrants et points influents n’est pas toujours comprise. Pour simplifier, nous dirons que les points aberrants correspondent à des observations hors normes, c.-à-d. ne correspondant pas à la population étudiée. Il peut s’agir d’un comportement très particulier, par exemple un senior qui se présente à l’épreuve du bac. Ces points peuvent fausser les résultats de la régression.
Les points influents correspondent aux observations qui pèsent significativement, voire exagérément, sur les calculs. Ils déterminent, dans une proportion à évaluer, les résultats de la régression. Il convient de les considérer avec précaution au moins pour interpréter correctement les coefficients obtenus. Dans certains cas, on peut considérer qu’une observation pèse trop sur la régression au point d’altérer les paramètres estimés.
Concernant la détection des points aberrants et influents dans la régression, il existe un très grand nombre de documents en ligne, de qualité assez inégale malheureusement. Nous avons donc complètement documenté les indicateurs implémentés dans Tanagra (voir références). Il est important de bien comprendre le sens à donner à ces indicateurs, et ils sont nombreux, pour interpréter correctement les résultats.
Enfin, pour éviter les confusions autour des définitions des indicateurs (la définition des résidus standardisés, studentisés, internes ou externes, est par exemple assez fluctuante d’un logiciel à l’autre), nous cadrons nos calculs par rapport à deux logiciels reconnus dans le monde scientifique, SAS et le logiciel gratuit R. Nous procèderons de la manière suivante : dans un premier temps, nous affichons les données et les résultats issus de la documentation de SAS, ils nous serviront de référence ; puis nous décrivons la procédure sous TANAGRA ; enfin, nous décrirons la démarche à suivre sous R.
Les données sont issues de la documentation de SAS, disponible en ligne. L’objectif est d’expliquer la population US (USPopulation) à partir de l’année (Year) et du carré de l’année (YearSq). Nous mettrons essentiellement l’accent sur la mise en œuvre des calculs et la comparaison de résultats dans ce didacticiel.
Mots clés : régression linéaire multiple, points influents, points aberrants, points atypiques, résidus standardisés, résidus studentisés, leverage, dffits, distance de cook, covratio, dfbetas, logiciel R
Composants : Multiple linear regression, Outlier detection, DfBetas
Lien : fr_Tanagra_Outlier_Influential_Points_for_Regression.pdf
Données : USPopulation.xls
Références :
R. Rakotomalala, « Pratique de la régression linéaire multiple – Diagnostic et sélection de variables », Université Lumière Lyon 2.
SAS STAT User’s Guide, « The REG Procedure – Predicted and Residual Values »
Colinéarité et régression
2008-04-02 (Tag:8635158511130061319)
Un des plus gros écueils de la régression est la colinéarité c.-à-d. les variables exogènes sont excessivement corrélées. Les coefficients deviennent incohérents, en contradiction avec les connaissances du domaine. Des variables, a priori très importantes, paraissent non significatives, elles sont par conséquent éliminées à tort.Il importe de déterminer s’il y a colinéarité dans la régression que nous menons. Cela se manifeste de différentes manières. Les résultats sont très instables, une petite modification des observations entraîne une forte modification des paramètres estimés. Les signes et les valeurs des paramètres sont incohérents, par rapport aux autres variables et par rapport aux connaissances du domaine. Enfin, des variables paraissent non pertinentes à cause d’une variance mal estimée. Le test de nullité des coefficients, le t de Student, renvoie des valeurs faussées. Généralement, pour détecter la colinéarité, nous nous appuyons sur des calculs simples tels que la comparaison du signe de la corrélation brute « endogène-exogène » avec le signe du coefficient dans la régression ; la comparaison du carré de la même corrélation avec le coefficient de détermination de la régression.
Par la suite, il faut proposer des solutions pour obtenir des solutions consistantes. Dans ce didacticiel, nous étudierons trois approches destinées à surmonter la colinéarité : la sélection de variables, la régression sur les composantes orthogonales, la régression PLS.
Dans le cas de la régression PLS, nous montrons comment introduire les composants qui permettent de sélectionner le bon nombre d’axes et de calculer les intervalles de confiance des coefficients. Deux problèmes difficiles, sur lesquels nous n’avons pas de solutions immédiates. Les outils proposés dans Tanagra sont basés sur des techniques de ré échantillonnage.
Mots clés : régression linéaire multiple, économétrie, colinéairité, sélection de variables, analyse en composantes principales, régression pls1
Composants : Multiple linear regression, Linear Correlation, Forward Entry Regression, Principal Component Analysis, PLS Regression, PLS Selection, PLS Conf. Interval
Lien : fr_Tanagra_Regression_Colinearity.pdf
Données : car_consumption_colinearity_regression.xls
Références :
R. Rakotomalala, « Pratique de la régression linéaire multiple – Diagnostic et sélection de variables », Université Lumière Lyon 2.
S. Vancolen, « La régression PLS », Groupe de Statistique, Université de Neuchâtel.
Rotation VARIMAX en ACP
2008-04-01 (Tag:7474978045493252431)
L’ACP (analyse en composante principale) est, entre autres, une technique descriptive qui vise à projeter un nuage de points dans un espace à plus faible dimension tout en préservant la proximité des individus.Un aspect essentiel de la méthode est l’interprétation des résultats. Pourquoi la proximité entre tel ou tel groupe d’individus dans les plans factoriels ?
Pour ce faire, nous devons interpréter les nouvelles variables, les facteurs (axes factoriels), produites par l’ACP. Il s’agit de combinaisons linéaires des variables initiales. Chaque variable apporte une certaine contribution dans l’élaboration des facteurs. Plus elle est élevée, plus elle sera déterminante dans l’interprétation.
Le cercle de corrélations est un outil privilégié pour identifier le rôle des variables dans l’élaboration des axes. C’est à ce stade souvent qu’apparaissent les principales déceptions. En effet, il n’est pas rare que les variables soient plus ou moins fortement liées avec 2 ou 3 facteurs, empêchant une association tranchée « axe-facteur » propice à l’interprétation.
Pour dépasser cet écueil, il existe des techniques de rotation d’axes. Nous avons implémenté les méthodes VARIMAX et QUARTIMAX dans Tanagra. L’idée est simple : on choisit les x premiers axes à modifier, on les fait tourner de manière à ce que les corrélations entre les variables et les axes soient le plus tranchés possibles c.-à-d. proche de +/-1 ou proche de 0. Deux contraintes fortes doivent guider les calculs : (1) l’orthogonalité des axes est conservée avec ces techniques (il existe par ailleurs des techniques qui n’intègrent pas cette contrainte) ; (2) le pourcentage d’inertie porté par les x à axes à pivoter doit être préservé.
Mots clés : analyse en composantes principales, rotation VARIMAX, rotation QUARTIMAX
Composants : Principal Component Analysis, Factor Rotation
Lien : fr_Tanagra_Pca_Varimax.pdf
Données : crime_dataset_from_DASL.xls
Arbres de classification
2008-04-01 (Tag:121189301696325130)
La classification consiste à construire des groupes homogènes d’observations, des classes, du point de vue d’une série de descripteurs de telle sorte que les observations dans les mêmes classes soient le plus similaires possible, et que les observations dans des classes différentes soient le plus dissemblables possible.Une fois les groupes construits, il nous faut d’une part pouvoir les interpréter c.-à-d. savoir sur quelles caractéristiques les individus d’un même groupe ont été placés ensemble, qu’est-ce que différencient les groupes ; d’autre part, disposer d’une procédure d’affectation qui nous permettra de classer rapidement un nouvel individu dans un des groupes.
Les arbres de classification permettent de répondre très simplement à ces deux exigences. Le modèle de classement est représenté par un arbre de décision, chaque groupe est décrit par une règle logique, l’algorithme détecte automatiquement les variables pertinentes dans leur élaboration, l’interprétation est immédiate. L’affectation à un groupe peut être réalisée simplement en appliquant le système logique sur les descripteurs de l’observation à classer.
Cette technique est peu connue, les principales références sont à ce jour les articles de Chavent (1998) et Blockeel (1998).
Nous travaillerons sur le fichier ZOO (UCI). Il s’agit de regrouper des animaux selon leurs caractéristiques. Ils sont par ailleurs classés en 7 familles par des spécialistes. Nous vérifierons si notre classification concorde peu ou prou avec cette typologie proposée par les biologistes. Nous vérifierons également si notre classification, qui intègre quand même une contrainte forte, la construction d’un arbre logique pour représenter les classes, concorde avec les résultats produits par les méthodes classiques telles que les K-MEANS.
Mots clés : classification automatique, clustering, arbres de classification, interprétation des classes, clustering tree
Composants : Multiple Correspodance Analysis, CTP, Contingency Chi-Square, K-Means
Lien : fr_Tanagra_Clustering_Tree.pdf
Données : zoo.xls
Références :
R. Rakotomalala, « Arbres de classification ».
M. Chavent (1998), « A monothetic clustering method », Pattern Recognition Letters, 19, 989—996.
H. Blockeel, L. De Raedt, J. Ramon (1998), « Top-Down Induction of Clustering Trees », ICML, 55—63.
Statistiques descriptives comparatives
2008-03-31 (Tag:2234661018108356302)
Le travail du statisticien consiste souvent à calculer des statistiques descriptives comparatives à partir de tris à plat ou tris croisés (à plusieurs niveaux). L’intérêt de ces approches assez frustes est que la lecture de ces résultats ne nécessite pas de compétences particulières. Elles permettent de comparer et de caractériser les spécificités d’une sous-population à partir d’une série de descripteurs.Dans ce didacticiel, nous montrons l’utilisation de deux composants qui permettent de mettre en œuvre facilement ces opérations de comparaison entre sous-populations.
Pour marquer les différences sur les descripteurs, nous utilisons l’indicateur « valeur test ». Il s’agit de la statistique du test de comparaison de moyennes (variables quantitatives) ou de proportions (variables qualitatives). Il confronte la moyenne (proportion) calculée dans l’échantillon global et dans le sous-échantillon correspondant au groupe.
Bien sûr, il ne s’agit pas d’un test au sens rigoureux du terme, les échantillons ne sont pas indépendants. Il faut surtout le prendre comme une référence qui permet de positionner les différentes variables. En effet, étant souvent exprimés dans des unités différentes, elles ne sont pas directement comparables.
Mots clés : comparaison de populations, tri à plat, tri croisé
Composants : Group characterization, Group Exploration
Lien : fr_Tanagra_Group_Exploration.pdf
Données : autos.xls
Référence : Lebart, Morineau, Piron « Statistique exploratoire multidimensionnelle », Dunod, 2000 ; pages 181 à 184.
Travailler sur les corrélations partielles
2008-03-31 (Tag:8884665222233018283)
Le coefficient de corrélation linéaire mesure l'intensité de la liaison entre deux variables quantitatives. Il est utilisé dans de nombreuses situations, entre autres dans l'analyse en composantes principales (ACP) pour résumer les principales informations portées par un fichier de données.
Pour pratique qu'il soit, le coefficient de corrélation peut être trompeur. L'extrapolation de la corrélation à la causalité doit être faite avec précaution. Notamment parce qu'il peut y avoir une ou plusieurs variables supplémentaires, connues ou inconnues, qui influent sur les variations des variables étudiées, laissant à penser qu'il existe un lien entre ces variables. Ces tierces variables, on parle de facteurs confondants en médecine, sont la cause de bien des problèmes dans les études réelles. Elles induisent des conclusions totalement faussées. Bien souvent, nous devons nous en remettre à l'expertise du domaine pour les circonscrire. Il importe alors de les traiter convenablement.
Dans ce tutoriel, nous montrons le fonctionnement du composant RESIDUAL SCORES de TANAGRA. Son rôle est d'enlever dans les variables cibles la variabilité causée par une série de variables annexes, qui ne semblent pas directement impliquées dans l'étude, mais qui en réalité pèsent significativement sur les résultats. Cela permet de mettre en oeuvre des études « toutes choses égales par ailleurs » où l'on ramène l'ensemble des variables à un référentiel commun.
Nous travaillons sur un fichier qui recense les dimensions de différentes parties du corps (circonférence des chevilles, du coude, du genou, de la taille, des hanches, etc.). L'objectif est de vérifier s'il existe un lien entre les dimensions de ces différentes parties du corps. Trois variables supplémentaires sont disponibles : le poids, la taille et le sexe des individus étudiés. A priori, ces variables n'ont pas de rôle direct à jouer dans notre étude. Nous verrons qu'en réalité, elles tiennent une place centrale.
Mots clés : corrélation partielle, analyse en composantes principales
Composants : Principal Component Analysis, Scatterplot, 0_1_Binarize, Residual Scores, VARHCA
Lien : fr_Tanagra_PartialCorrelation.pdf
Données : body.xls
Références :
D. Garson, « Partial Correlation »
Wikipedia, « Partial Correlation »
Classification de variables
2008-03-31 (Tag:559832578114158606)
Dans la majorité des ouvrages, la classification de variables est décrite très sommairement. Les auteurs se contentent le plus souvent de la présenter comme un cas particulier de la typologie où le coefficient de corrélation r est utilisé pour mesurer la proximité entre les variables, (1- r) étant alors un indice de dissimilarité naturel.Pourtant, la classification de variables peut être très utile dans la recherche des structures sous-jacentes dans les données. Elle permet de repérer les groupes de variables redondantes, emmenant le même type d’information ; de distinguer les groupes de variables orthogonales, rapportant des informations complémentaires. Nous disposons ainsi de précieuses indications sur l’architecture des données.
Cette méthode peut également être mise en œuvre dans une stratégie de réduction/sélection des variables. Pour chaque groupe de variables, une variable « moyenne » unique pourra être produite et utilisée dans les analyses ultérieures, en tant que variable prédictive présentée aux méthodes supervisées par exemple, réduisant considérablement la dimensionnalité.
Avec la version 1.4.16, nous introduisons dans TANAGRA plusieurs techniques de classification de variables inspirées par la lecture de l’ouvrage de Nakache et Confais (2005). Nous nous sommes plus particulièrement penchés sur les techniques de classification autour de composantes latentes basées sur les travaux de Vigneau et Qannari (2003), à l’origine notamment de la fameuse procédure VARCLUS (Variable Clustering) implémentée dans le logiciel SAS.
Dans ce didacticiel, nous présentons 3 méthodes de classification de variables, toutes basées sur le principe du regroupement autour des variables latentes. La première VARHCA est algorithme ascendant hiérarchique. Elle est intéressante dans la mesure où nous disposons d’un dendrogramme qui permet de visualiser l’évolution de l’agrégation, et par là de détecter ce qui serait le bon nombre de groupes. La seconde VARKMEANS est une méthode de réallocation. Avec les avantages et inconvénients qui s’y rattachent. La troisième VARCLUS est une méthode descendante, particulière adaptée lorsque le nombre de variables à traiter est important.
Une large partie du tutoriel est consacrée à la l’interprétation. Les outils sont nombreux, il importe de bien comprendre les informations que nous procurent les tableaux de résultats.
Mots clés : classification automatique de variables, variable clustering, composantes latentes
Composants : VARHCA, VARKMeans, VARCLUS
Lien : fr_Tanagra_VarClus.pdf
Données : crime_dataset_from_DASL.xls
Références :
E. Vigneau et E. Qannari, « Clustering of variables around latent components », Simulation and Computation, 32(4), 1131-1150, 2003.
J.P. Nakache et J. Confais, « Approche Pragmatique de la Classification », TECHNIP, 2005, chapitre 9, pages 219 à 239.
SAS OnlineDoc – Version 8, « The VARCLUS Procedure ».
K-Means sur variables qualitatives
2008-03-31 (Tag:2222972961104163317)
L’algorithme des K-Means est une méthode de classification automatique (clustering), on l’appelle également K-Moyennes ou encore Nuées dynamiques (bien que cette dénomination constitue en réalité une généralisation).L’idée est très simple. On choisit K individus au hasard, qui constituent les noyaux initiaux. On fait passer toutes les observations. On affecte chaque observation au noyau qui lui est le plus proche. Les noyaux sont alors remis à jour. Puis on réitère le passage de tous les individus jusqu’à ce que la solution soit stable.
Sa simplicité fait la popularité de cette approche. Autre avantage notable, il n’est pas nécessaire de calculer au préalable les distances deux à deux entre tous les individus, opération très gourmande en temps et en espace mémoire dans certains algorithmes de clustering.
La méthode des K-Means présente néanmoins des inconvénients. On citera notamment l’obligation de fixer au préalable le nombre de groupes, sans qu’aucune indication ne soit fournie. La CAH – classification ascendante hiérarchique - par exemple ne donne pas non plus le bon nombre de groupes, en revanche avec le dendrogramme, nous disposons des indications sur le partitionnement adéquat. On citera aussi la forte dépendance de la méthode au choix des noyaux initiaux. La méthode peut converger vers un optimum local. C’est pour cette raison que l’on propose dans Tanagra (et dans tous les autres logiciels) de réitérer plusieurs fois le processus complet en changeant les conditions initiales.
Dans ce didacticiel, nous abordons un problème supplémentaire. Les descripteurs sont catégoriels. Nous ne pouvons pas directement lancer les K-Means surtout avec la distance euclidienne usuelle. On propose de travailler en 2 étapes : (1) réaliser une analyse en composante multiple ; (2) lancer les K-Means sur les x premiers axes factoriels. L'étape (1) de construction de variables nous permet d'utiliser par la suite l'algorithme standard des K-Means basé sur la distance euclidienne.
Pour interpréter les groupes, nous utiliserons dans un premier temps les statistiques descriptives comparatives. Malgré (ou grâce à) sa simplicité, elle est foncièrement univariée, cette approche est très populaire. Elle permet de détecter rapidement les principales variables qui différencient fortement les groupes.
Dans un second temps, nous comparons les groupes obtenus avec une variable supplémentaire, qui constituerait les classes « naturelles » des observations. On parle dans ce cas de validation externe. Cette démarche est très utilisée dans la recherche, lorsque l’on veut montrer l’efficacité d’une méthode de classification.
Mots clés : classification automatique, clustering, k-means, k-moyennes, nuées dynamiques, analyse factorielle de correspondances mutliples, validation externe, interprétation des classes
Composants : Multiple Correspondance Analysis, K-Means, Group characterization, Cross Tabulation
Lien : dr_clustering_validation_externe.pdf
Données : dr_vote.bdm
Références :
Wikipédia, « K-means algorithm ».
G. Bisson, « Evaluation & Catégorisation ».
Régression logistique multinomiale
2008-03-30 (Tag:6964224595357467225)
La régression logistique est très répandue pour les problèmes de prédiction ou d’explication d’une variable dépendante binaire (malade oui/non, défaillance oui/non, client potentiel oui/non, etc.) à partir d’une série de variables explicatives continues, binaires ou binarisées (dummy variables). On parle dans de cas de régression logistique binaire.Lorsque la variable dépendante possède plusieurs catégories non ordonnées (K > 2), on parle de régression logistique multinomiale (on parle aussi de Régression logistique polytomique à variable dépendante nominale). Elle est peu (ou moins) connue, pourtant cette configuration est finalement assez courante. De plus, elle est directement traitée par les autres méthodes d’apprentissage telles que l’analyse discriminante prédictive, les arbres de décision, etc.
Grosso modo, la régression logistique multinomiale consiste à désigner une catégorie de référence, la dernière (Kème) par exemple pour fixer les idées, et à exprimer chaque logit (ou log-odds) des (K-1) modalités par rapport à cette référence à l’aide d’une combinaison linéaire des variables prédictives.
Dans ce didacticiel, nous montrons la mise en œuvre de la régression logistique multinomiale dans TANAGRA. Nous voulons expliquer, pour une série de produits de même catégorie, la marque (3 marques possibles) choisie par 735 consommateurs à partir de leur age et de leur sexe. Ces données ont déjà été traitées par ailleurs à l’aide du logiciel R. Les données et les résultats associés sont disponibles en ligne.
Mots clés : régression logistique multinomiale
Composants : Supervised Learning, Multinomial Logistic Regression
Lien : fr_Tanagra_Multinomial_Logistic_Regression.pdf
Données : brand_multinomial_logit_dataset.xls
Référence : A. Slavkovic, « Multinomial Logistic Regression Models – Baseline-Category Logit Model », in « STAT 504 – Analysis of Discrete Data », Pensylvania State University, 2007.
Stepdisc – Analyse discriminante
2008-03-30 (Tag:5881511846028223115)
La sélection de variables est un processus très important en apprentissage supervisé. Nous disposons d’une série de variables candidates, nous cherchons les variables les plus pertinentes pour expliquer et prédire les valeurs prises par la variable à prédire. Les objectifs sont bien souvent multiples : nous réduisons le nombre de variables à recueillir pour le déploiement du système ; nous améliorons notre connaissance du phénomène de causalité entre les descripteurs et la variable à prédire, ce qui est fondamental si nous voulons interpréter les résultats pour en assurer la reproductibilité ; enfin, mais pas toujours, nous améliorons la qualité de la prédiction, le ratio nombre d’observations / dimension de représentation étant plus favorable.Dans ce tutoriel, nous présentons la méthode STEPDISC (Stepwise Discriminant Analysis). Elle repose le critère du LAMBDA de WILKS. Géométriquement, il s’agit de trouver le sous-espace de représentation qui permet un écartement maximal entre les barycentres des nuages de points conditionnels c.-à-d. les nuages de points associés à chaque valeur de la variable à prédire. Elle est donc particulièrement bien adaptée à l’analyse discriminante linéaire qui utilise également le même critère, d’où son appellation. Elles sont systématiquement associées dans les logiciels.
TANAGRA implémente deux stratégies. L’approche FORWARD consiste à partir de l’ensemble vide, choisir la variable induisant la meilleure amélioration du LAMBDA, et la sélectionner si amélioration est statistiquement significative ; nous procédons itérativement en ajoutant unes à unes les variables jusqu’à ce que l’adjonction d’une variable n’apporte plus d’amélioration. A l’inverse, l’approche BACKWARD, part de l’ensemble des variables candidates, recherche la variable dont le retrait entraînerait la dégradation la plus faible du LAMBDA, et la retire effectivement si cette dégradation n’est pas statistiquement significative.
Dans notre exemple, nous partons de 60 descripteurs candidats pour arriver à un modèle à 7 variables, tout en conservant le même niveau de performances. Autre résultat important, les procédures FORWARD et BACKWARD peuvent aboutir à des sous-ensembles différents. La stratégie d’exploration n’étant pas la même, il ne faut pas s’en émouvoir. Ces techniques fournissent avant tout des scénarios de résultats. Charge à nous, en accord avec les connaissances du domaine, de déterminer la solution la plus adaptée.
Mots clés : stepdisc, sélection de variables, analyse discriminante prédictive
Composants : Supervised Learning, Linear discriminant analysis, Bootstrap, Stepdisc
Lien : fr_Tanagra_Stepdisc.pdf
Données : sonar_for_stepdisc.xls
Référence : SAS/STAT User’s Guide, « The STEPDISC Procedure »
Random Forests
2008-03-30 (Tag:2209219714804575594)
RANDOM FOREST (forêts d'arbres) est une technique d’apprentissage supervisé qui combine une technique d’agrégation, le BAGGING, et une technique particulière d’induction d’arbres de décision.Lors de la construction de l’arbre, pour initier la segmentation d’un nœud, la méthode effectue dans un premier temps une sélection aléatoire parmi les variables candidates ; sélection à partir de laquelle, dans un deuxième temps, elle cherche la variable de segmentation. La taille de la sélection est un paramètre de l’algorithme. Si elle n’est pas spécifiée, on propose généralement la formule « partie entière de log2 (J)+1 », où J est le nombre total de variables.
L’idée est assez simple, et déjà présente dans les premiers articles de BREIMAN (1996) sur le BAGGING : en exacerbant la variabilité de la technique d’apprentissage, nous augmentons l’efficacité de la technique d’agrégation.
L’implémentation dans Tanagra est un peu particulière. Plutôt que de fournir un composant dédié, une méthode de construction d’arbre « aléatoire » est proposée. La méthode Random Forest revient à l’utiliser conjointement avec le composant BAGGING. L’utilisateur bénéficie ainsi d’une meilleure souplesse d’utilisation, il pourra aussi introduire ses propres variantes, BOOSTING + RANDOM TREE par exemple, etc.
Dans ce didactciel, nous comparons les performances de C4.5 (Quinlan, 1993), élaborant un arbre unique, avec random forest. Cette dernière améliore sensiblement la qualité de la prédiction. Le taux d’erreur est mesuré en validation croisée.
Mots clés : random forest, agrégation de classifieurs, arbres de décision, validation croisée
Composants : Bagging, Rnd Tree, Supervised Learning, Cross-validation, C4.5
Lien : fr_Tanagra_Random_Forest.pdf
Données : dr_heart.bdm
Référence : L. Breiman, A. Cutler, « Random Forests ».
Listes de décision (vs. arbres de décision)
2008-03-30 (Tag:5138805891597926265)
Les listes de décision (decision list en anglais) font partie des méthodes d’apprentissage supervisé très en vogue au début des années 90. La méthode est très proche de l’induction par arbres, elle produit des règles de production triées et mutuellement exclusives du type « Si condition_1 Alors conclusion_1 Sinon Si condition_2 Alors conclusion_2 Sinon Si… ».Si le biais de représentation est très proche des arbres de décision, les DL construisent des hyper-rectangles les plus homogènes possibles du point de vue de la variable à prédire, le biais de préférence est différent, elles procèdent par « Separate-and-conquer » et non par « Divide-and-conquer », elles disposent donc un degré de liberté supplémentaire pour mettre en avant les solutions les plus spécialisées. Cette liberté a un prix, cette méthode est souvent sujette au sur apprentissage à force de vouloir détecter à tout prix les sous populations les plus intéressantes, son paramétrage est alors primordial pour éviter qu’elle ne produise des règles couvrant trop peu d’individus et de ce fait non significatives.
La méthode que nous avons implémentée dans TANAGRA est très largement inspirée de CN2 (Clark & Niblett, ML-1989). Nous avons pris quelques libertés : (1) en simplifiant l’exploration de l’espace des hypothèses, nous utilisons un « hill-climbing » simple plutôt qu’un « best-first search », nettement plus coûteux en CPU mais pas vraiment plus efficace ; (2) en introduisant un paramètre supplémentaire, le support de la règle, pour éviter que des règles sur-spécialisées et non-significatives apparaissent.
Dans ce didacticiel, nous comparons les performances de CN2 avec CART. Notons que CN2 ne sait pas manipuler directement les attributs continus, nous devons les discrétiser au préalable, nous utilisons la méthode MDLPC (Fayyad et Irani, 1993) pour cela. Les taux d’erreur sont mesurés par bootstrap. On constate que les méthodes se valent. Ce qui n’est pas étonnant, les biais de représentation sont (quasiment) identiques.
Mots clés : CN2, decision list, listes de décision, arbres de décision, CART, discrétisation
Composants : Supervised Learning, MDLPC, Decision List, C-RT, Bootstrap
Lien : fr_Tanagra_DL.pdf
Données : dr_heart.bdm
Référence : P. Clark, « CN2 – Rule induction from examples ».
Support vector machine (SVM) multi-classes
2008-03-28 (Tag:229470752671847420)
Les machines à vecteurs de support (ou machine à vaste marge) ont été définies à l’origine pour les problèmes à 2 classes c.-à-d. les cas où la variable à prédire prend 2 modalités (les positifs contre les négatifs). Notre composant SVM ne traite que ce type de problème d’ailleurs.Pour passer à des problèmes multi-classes, il faut proposer de nouvelles solutions. TANAGRA fait appel au module externe LIBSVM (libre et open source) dans ce cas. J’y vois essentiellement 2 avantages : on dispose d’une solution directe, déjà débuguée, leur bibliothèque est largement diffusée ; LIBSVM, avec un algorithme ad hoc, propose un niveau de performances (rapidité) que je n’ai jamais pu approcher avec mes propres implémentations (dérivées de l’algorithme de Platt, 1998).
Notre tutoriel traite d’un problème à deux classes. Mais le composant C-SVC que nous présentons peut directement traiter un problème multi-classes, sans qu’aucune préparation des données ne soit nécessaire.
Dans notre exemple, on ne peut que s’extasier devant les performances de l’implémentation, quelques secondes suffisent pour produire un classifieur sur un jeu de données comptant une centaine d’observations et plusieurs milliers de variables. Ce problème de classement de protéines est par ailleurs traité dans un autre didacticiel où nous utilisons une approche différente, basée sur une construction de variables à l’aide de l’algorithme NIPALS.
Mots clés : SVM, support vector machine, machine à vaste marge, SVM multi-classes, classement de protéines
Composants : Supervised Learning, C-SVC, Bootstrap
Lien : fr_Tanagra_CSVC_LIBSVM.pdf
Données : Tanagra_Nipals.zip
Référence : C.C. Chang, C.J. Jin, « LIBSVM – A library for Support Vector Machine »
Support vector machine (SVM)
2008-03-28 (Tag:3617728109216246824)
Les machines à vecteurs de support (ou machine à vaste marge) sont des techniques d’apprentissage supervisé qui reposent sur deux idées fortes : (1) il repose sur le principe de la maximisation de la marge ; (2) lorsque les données ne sont pas linéairement séparables, il est possible, par le principe des noyaux, de se projeter dans un espace de plus grande dimension pour trouver la solution adéquate, sans avoir à former explicitement ce nouvel espace de représentation (Wikipedia, voir références).Dans ce tutoriel, nous montrons la mise en œuvre des SVM de TANAGRA. Notre implémentation reprend l’algorithme de Platt (1998 - Algorithme SMO), directement inspiré du code source en Java de Weka, un logiciel très populaire dans la communauté « apprentissage automatique ». Nous montrons que dans un problème avec un ratio nombre d’individus/nombre de variables défavorable, les SVM résistent mieux à la dimensionnalité que l’analyse discriminante. Nous verrons également qu’en passant à un noyau polynomial de degré 2, les performances sont encore améliorées.
Sur notre fichier, nous réduisons significativement le taux d’erreur, il passe de 25% (analyse discriminante) à 15% (SVM – Noyau polynomial). Le SVM linéaire propose un taux de 20%. Ce n’est qu’un exemple illustratif bien entendu, ça n’a pas valeur de preuve. Quoiqu'il en soit, il est avéré que les SVM, surtout linéaires, résistent fort bien à la fameuse « malédiction de la dimensionnalité ». Contrairement à l’analyse discriminante qui peut s’effondrer dramatiquement dans ce contexte.
Les taux d’erreur sont mesurés par bootstrap.
Mots clés : SVM, support vector machine, machine à vaste marge, analyse discriminante linéaire, fonction noyau
Composants : Supervised Learning, SVM, Linear discriminant analysis, Bootstrap
Lien : fr_Tanagra_SVM.pdf
Données : sonar.xls
Références:
Wikipédia (FR) – « Machine à vecteurs de support »
Wikipedia (US) – « Support vector machine »
Weka – « Weka 3: Data Mining Software in Java »
Construction de variables avec NIPALS
2008-03-27 (Tag:528660689028187847)
Nous avons déjà parlé par ailleurs de la régularisation en apprentissage supervisé. L’idée est de réduire la dimensionnalité tout en préservant l’information utile dans les données. L’apprentissage supervisé subséquent ne peut qu’en bénéficier.Nous voulons mettre en œuvre la méthode des plus proches voisins (K-PPV) dans un problème de prédiction où nous disposons d’une centaine d’observations, et… plusieurs milliers de descripteurs. Avant même de lancer les calculs, nous savons que ça ne donnera rien de bon, surtout pour cette méthode. Les estimations locales des probabilités, dans le voisinage des points à classer, sont très mauvaises. Les performances en classement seront désastreuses.
Nous voulons réduire la dimensionnalité, en utilisant l'analyse en composantes principales par exemple. L’ACP permet de projeter les individus dans un sous-espace, tout en préservant les proximités entre eux. Si l’idée est bonne, elle est impraticable. En effet, calculer une matrice de variance covariance de taille 6740 x 6740 n’est déjà pas très malin (au mieux, on utilise 173 Mo de mémoire vive en double précision). Tenter de la diagonaliser relève d’un optimisme forcené.
La méthode NIPALS paraît tout indiquée dans ce contexte. Elle permet de retrouver les axes factoriels de l’ACP, avec une précision moindre certes, sans avoir à former explicitement la matrice de variance covariance. L’avantage est double : moindre occupation mémoire et temps de calculs autrement plus accessibles. L’inconvénient, infime au regard des avantages, est que nous devons fixer à l’avance le nombre de facteurs à retenir.
Dans ce didacticiel, nous montrons comment élaborer les facteurs avec la méthode NIPALS, puis les présenter aux K-PPV. Le gain de temps est énorme. Il s’accompagne de surcroît d’une amélioration des performances en prédiction. L’amélioration du rapport entre le nombre d’observations et le nombre de variables est primordiale dans ce contexte.
Le taux d’erreur est mesuré par bootstrap.
Mots clés : NIPALS, analyse en composantes principales, ACP, méthode des plus proches voisins, K-PPV, K-NN, méthodes de ré échantillonnage, bootstrap
Composants : Supervised Learning, NIPALS, K-NN, Bootstrap
Lien : fr_Tanagra_NIPALS.pdf
Données : Tanagra_Nipals.zip
Références :
M. Tenenhaus, « La régression PLS – Théorie et pratique », Technip, 1998 ; Chapitre 6, « L’algorithme NIPALS », pages 61 à 73.
R. Rakotomalala, « Autres méthodes supervisées extrapolées du schéma bayesien – La méthode des plus proches voisins »
Tanagra en ligne de commande
2008-03-27 (Tag:6204543915807310690)
L’expérimentation est indissociable du data Mining. Une grande partie de notre travail est de déterminer les paramètres adaptés, tester des configurations différentes, comparer des performances d’algorithmes sur les mêmes données, reproduire des traitements sur des fichiers de données similaires.A l’évidence, la définition de traitements sous forme de diagramme, appelé pompeusement « programmation visuelle », n’est absolument pas adaptée dans ce contexte. Il faudrait disposer d’un langage de programmation avec tous les attributs associés : boucles, branchement conditionnel, etc.
Avant d’en arriver à ce stade, nous pouvons quand même tirer parti de certaines fonctionnalités de Tanagra pour monter des expérimentations. En effet, il est possible de lancer directement le logiciel en ligne de commande. Il nous suffit donc de définir un diagramme type, enregistré au format TDM (qui est un fichier texte rappelons-le, aisément manipulable en dehors du logiciel), et de le transmettre à Tanagra.
On peut même aller plus loin en définissant des traitements par lots dans un fichier .BAT (pour le DOS). Différentes sessions de Tanagra sont lancés, les résultats sont sauvegardés régulièrement. C’est la démarche que nous proposons dans ce didacticiel. Nous étudions les performances comparées du modèle bayesien naïf, avec et sans sélection de variables, sur des fichiers de structure similaire.
Enfin, nous ne l’abordons pas dans ce tutoriel, mais si nous souhaitons véritablement monter des expérimentations à grande échelle. La solution passe par l’écriture d’un programme simple qui génère automatiquement les fichiers TDM avec les configurations souhaités, et qui les transmet à Tanagra. Les résultats sont collectés au fur et à mesure. Le nombre de variantes que l’on peut tester ainsi devient très important.
Mots clés : traitements automatisés, expérimentation
Composants : Supervised Learning, Naive bayes, Cross validation, FCBF filtering
Lien : dr_utiliser_tanagra_en_mode_batch.pdf
Données : tanagra_batch_execution.zip
Echantillonnage dans les arbres de décision
2008-03-27 (Tag:7529287133375514529)
Stratégie d'échantillonnage pour les arbres de décision. Dans tous les algorithmes d'induction d'arbres, SIPINA introduit une option d'échantillonnage. L'idée est la suivante : plutôt que de travailler sur l'ensemble des individus disponibles sur chaque noeud pour choisir la variable de segmentation, nous proposons d'extraire un sous-échantillon et de calculer sur ces observations les indicateurs appropriés (gain d'entropie, statistique du khi-2, indice de Gini, etc.).L'expérimentation montre que l'ordonnancement des variables de segmentation sur chaque noeud reste le même, et de fait, les caractéristiques des arbres produits, notamment les performances en prédiction, sont préservées.
L'intérêt de cette approche est le gain de temps lors de la construction de l'arbre. Il peut être déterminant sur les grandes bases, surtout lorsqu'elles comportent un nombre important de variables continues, nécessitant la répétition du tri des données lors de la discrétisation.
L'échantillonnage sur un noeud est toujours sans remise. Il peut être représentatif (aléatoire simple), équilibré (le même nombre d'observations pour chaque modalité de la variable à prédire), ou stratifié (respectant les proportions de la totalité des observations sur le noeud).
Changement de stratégie dans Tanagra. Notons que par la suite, dans TANAGRA, nous avons adopté une autre stratégie. Toutes les variables continues sont triées une fois pour toutes avant l'induction. Un tableau d'index permet de conserver l'ordre des observations. Lors du traitement d'un noeud, nous y puisons les individus présents. La phase de tri n'est donc plus nécessaire puisque les observations sont déjà ordonnées. Le prix de cette approche est la nécessité de conserver en mémoire le tableau d'index, à savoir 4 octets par observation et par variable. Pourquoi ce revirement ? La raison est simplement pragmatique. En 1998, on disait d'une machine qu'elle était performante lorsqu'elle disposait de 256 Mo de RAM. En 2004, et plus récemment encore, un ordinateur avec 2Go de RAM est tout à fait courant.
Mots clés : arbres de décision, échantillonnage, optimisation des calculs, traitement des grandes bases de données
Référence : J.H. Chauchat, R. Rakotomalala, « A new sampling strategy for building decision trees from large databases », Proc. of IFCS-2000, pp. 199-204, 2000.
Analyse discriminante sur axes principaux
2008-03-26 (Tag:3784657387112559165)
L’analyse discriminante linéaire possède des qualités évidentes, maintes fois décrites dans de nombreuses publications. Elle souffre toutefois d’une faiblesse criante, elle nécessite l’inversion de la matrice de variance covariance intra-classes. Lorsque la matrice est singulière, le logiciel plante, au moins on sait à quoi s’en tenir. La situation est plus complexe lorsqu’elle est quasi singulière, la technique est très instable et propose des solutions erratiques. Cette situation arrive fréquemment lorsque le nombre de variables se rapproche dangereusement du nombre d’observations, ou lorsque certains prédicteurs sont fortement corrélés.La régularisation permet de contrôler cette instabilité. Dans leur ouvrage, Lebart et al. (2000) présentent plusieurs techniques. Nous retenons l’analyse discriminante sur axes principaux dans ce didacticiel.
La démarche est la suivante : nous réalisons une analyse en composantes principales sur les variables initiales, nous éliminons les axes correspondant à des valeurs propres nulles ou proches de 0, puis nous réalisons une analyse discriminante sur les facteurs qui ont été retenus.
L’idée sous jacente est de procéder à un lissage où l’on essaie d’épurer les données pour ne retenir que l’information « utile ». Les perturbations annexes, correspondant aux fluctuations d’échantillonnage, traduites par les derniers axes à très faible variance, sont éliminées.
Dans notre exemple, la solution semble idyllique. Cela n’est pas étonnant, nous avons utilisé le fichier « ondes » de Breiman et al. (1984) qui sont en réalité des données synthétiques. La solution est particulièrement adaptée.
Dans la pratique, si cette technique de régularisation permet de stabiliser l’apprentissage, éliminant le problème d’inversion de matrice hasardeuse, elle ne constitue pas pour autant la solution miracle. En effet, les axes principaux de l’ACP sont construits sans tenir compte de l’étiquette des observations. Il y a des cas où cela peut être totalement inapproprié.
Mots clés : régularisation, analyse discriminante linéaire, analyse discriminante prédictive, analyse en composantes principales, ACP
Composants : Supervised Learning, Linear discriminant analysis, Principal Component Analysis, Scatterplot, Train-test
Lien : dr_utiliser_axes_factoriels_descripteurs.pdf
Données : dr_waveform.bdm
Références :
L. Lebart, A. Morineau, M. Piron, « Statistique exploratoire multidimensionnelle », Dunod, 2000 ; pages 269 à 275.
Wikipédia , « Analyse discriminante linéaire »
Validation croisée, bootstrap, leave one out
2008-03-26 (Tag:413655480062008015)
L’évaluation des classifieurs est une question récurrente en apprentissage supervisé. Parmi les différents indicateurs existants, la performance en prédiction calculée à l’aide du taux d’erreur (ou son complémentaire à 1, le taux de bon classement) est un critère privilégié. Du moins dans les publications scientifiques car, dans les études réelles, d’autres considérations sont au moins aussi importantes : l’évaluation des performances en intégrant les coûts de mauvaise affectation, l’interprétation des résultats, les possibilités de mise en production, etc.Le taux d’erreur théorique est défini comme la probabilité de mal classer un individu dans la population. Bien entendu, il est impossible de le calculer directement, essentiellement parce qu’il n’est pas possible d’accéder à toute la population. Nous devons produire une estimation. Qui dit estimation dit utilisation d’un échantillon, un estimateur de bonne qualité doit être le moins biaisé possible (en moyenne, on tombe sur la bonne valeur du taux d’erreur théorique), et le plus précis possible (la variabilité autour de la vraie valeur est petite).
Dans la pratique, on recommande de subdiviser l’échantillon en 2 parties : la première, dite échantillon d’apprentissage pour créer le classifieur ; la seconde, dite échantillon test, pour calculer la proportion des erreurs en classement (voir Comparaison de classifieurs). L’erreur ainsi mesurée est non biaisée.Lorsque la base initiale de petite taille, cette démarche n’est plus adaptée. Il faut réserver toutes les données disponibles pour la construction du modèle. Comment alors évaluer les performances du classifieur ainsi produit ?
Les techniques de ré échantillonnage permettent de répondre à cette question. Nous étudierons plus particulièrement la validation croisée, le leave one out, et le bootstrap. Il s’agit de répéter plusieurs fois, sous des configurations pré définies, le schéma apprentissage test. Attention, il s’agit bien d’une estimation de l’erreur du modèle construit sur l’ensemble des données. Les modèles intermédiaires, élaborés lors des apprentissages répétés, servent uniquement à l’évaluation de l’erreur. Ils ne sont pas accessibles à l’utilisateur, ils n’ont pas d’utilité intrinsèque.
Ce didacticiel vise à compléter le cours décrivant les techniques de ré échantillonnage accessible en ligne (voir Référence). L’idée est la suivante : sur des données synthétiques, nous comparons l'erreur évaluée à l'aide des techniques de ré échantillonnage avec le cas, hypothétique, où nous disposons d’un échantillon test de taille virtuellement infinie. Nous pourrons ainsi situer le comportement et la précision des différentes techniques.
Nous utiliserons l’analyse discriminante linéaire (LDA) et les arbres de décision (C4.5) pour illustrer notre propos.
Mots clés : méthodes de ré échantillonnage, évaluation de l’erreur, validation croisée, bootstrap, leave one out, analyse discriminante linéaire
Composants : Supervised Learning, Cross-validation, Bootstrap, Test, Leave-one-out, Linear discriminant analysis, C4.5
Lien : fr_Tanagra_Resampling_Error_Estimation.pdf
Données : wave_ab_err_rate.zip
Référence : R. Rakotomalala, "Estimation de l'erreur de prédiction - Les techniques de ré échantillonnage"
Comparaison de classifieurs – Validation croisée
2008-03-26 (Tag:4829780958622760253)
Comparer les performances en prédiction est souvent mis en avant pour sélectionner le modèle le plus intéressant en apprentissage supervisé. Pour cela, il nous faut donc produire une mesure du taux d’erreur fiable, non biaisée.Dans la majorité des cas, on subdivise l’échantillon en 2 parties : la première, dite échantillon d’apprentissage pour créer le classifieur ; la seconde, dite échantillon test, pour calculer la proportion des erreurs en classement (voir Comparaison de classifieurs)
Lorsque la base initiale est de petite taille, cette démarche n’est plus adaptée. Il faut réserver toutes les données disponibles pour la construction du modèle. Comment alors évaluer les performances du classifieur ainsi produit ?
Les méthodes de ré échantillonnage apportent une réponse à ce problème. Par une série d’apprentissages-tests répétés sur des fractions de l’échantillon global, elles produisent une estimation de l’erreur en classement du modèle construit sur la totalité des données. Il faut bien entendu que cette estimation soit le moins biaisé possible, et avec une variance faible.
Dans ce didacticiel, nous montrons comment comparer les performances de deux algorithmes d’apprentissage supervisé (K-NN et ID3) à l’aide de l’erreur calculée en validation croisée.
Mots clés : validation croisée, méthodes de ré échantillonnage, comparaison de classifieurs, méthode des plus proches voisins, k-ppv, k-nn, arbres de décision, id3
Composants : Supervised Learning, K-NN, Cross-validation
Lien : dr_comparer_spv_learning.pdf
Données : dr_heart.bdm
Référence : R. Rakotomalala, "Estimation de l'erreur de prédiction - Les techniques de ré échantillonnage"
Courbe ROC pour la comparaison de classifieurs
2008-03-25 (Tag:6192617438132599184)
Une courbe ROC permet de comparer des algorithmes d’apprentissage supervisé indépendamment (1) de la distribution des modalités de la variable à prédire dans le fichier test, (2) des coûts de mauvaises affectations.La courbe ROC est avant tout définie pour les problèmes à deux classes (les positifs et les négatifs), elle indique la capacité du classifieur à placer les positifs devant les négatifs. Elle met en relation dans un graphique les taux de faux positifs (en abscisse) et les taux de vrais positifs (en ordonnée).
Sa construction s’appuie donc sur les probabilités d’être positif fournies par les classifieurs. Il n’est pas nécessaire que ce soit réellement une probabilité, une valeur quelconque dite « score » permettant d’ordonner les individus suffit amplement.
Il est possible de dériver un indicateur synthétique à partir de la courbe ROC, il s’agit de l’AUC (Area Under Curve – Aire Sous la Courbe), elle indique la probabilité d’un individu positif d’être classé devant un individu négatif. Il existe une valeur seuil, si l’on classe les individus au hasard, l’AUC sera égal à 0.5.
Dans ce didacticiel, nous construisons les courbes ROC de deux méthodes d’apprentissage que nous voulons comparer sur un problème de détection de maladies cardio-vasculaires : l’analyse discriminante linéaire (LDA) et les machines à vecteur de supports (SVM).
Dans la version actuelle (1.4.21 et + récente), le graphique de la courbe est directement construite dans TANAGRA, il n’est plus nécessaire de passer par un tableur.
Mots clés : courbe roc, auc, comparaison de classifieurs, analyse discriminante, svm, support vector machine, scoring
Composants : Sampling, 0_1_Binarize, Supervised Learning, Scoring, Roc curve, SVM, Linear discriminant analysis
Lien : fr_Tanagra_Roc_Curve.pdf
Données : dr_heart.bdm
Références :
R. Rakotomalala – « Courbe ROC »
T. Fawcet – « ROC Graphs : Notes and Practical Considerations of Researchers »
Statistiques descriptives avec SIPINA
2008-03-25 (Tag:292954754601636702)
SIPINA propose des fonctionnalités de statistiques descriptives. Peu de personnes le savent. En soi l'information n'est pas éblouissante, il existe un grand nombre de logiciels libres capables de produire les indicateurs de la description statistique.L'affaire devient plus intéressante lorsque l'on couple ces outils avec l'induction d'un arbre de décision. La richesse de la phase exploratoire est décuplée. En effet, chaque nœud d'un arbre correspond à une sous population décrite par une règle. Ce groupe a été constitué de manière à ce que seule une des modalités de la variable à prédire soit représentée. C'est l'objectif de l'apprentissage. Mais qu'en est-il des autres variables ?
L'arbre a une qualité rare, elle met en avant les meilleures variables dans l'induction. Mais elle a le défaut de ses qualités, elle ne donne pas directement d'informations sur les variables qui ont été écartées, encore moins sur les relations entre ces variables. La possibilité de calculer simplement des statistiques descriptives sur les sous populations permet à l'utilisateur d'étudier finement les spécificités de ces groupes, et par là même de mieux caractériser la règle produite par l'induction. C'est ce que nous essayions de mettre en valeur dans ce didacticiel.
Nous utilisons les données HEART_DISEASE_MALE.XLS . Il s'agit de prédire l'occurrence d'un maladie cardiaque (DISEASE) à partir des caractéristiques des individus (AGE, SUCRE dans le sang, etc.). Les données, 209 observations, sont restreintes aux individus de sexe masculin
Mots clés : statistiques descriptives, arbres de décision, exploration interactive
Lien : fr_sipina_descriptive_statistics.pdf
Données : heart_disease_male.xls
Scoring avec la régression logistique
2008-03-21 (Tag:8521832563952133771)
Un autre exemple de ciblage marketing, l’objectif toujours est d’associer un score à chaque individu permettant de les trier selon leur appétence à un produit.Par rapport au didacticiel précédent, nous avons deux particularités : on utilise la régression logistique binaire, une méthode très populaire dans le scoring ; le ratio nombre de variables sur nombre d’individus est très élevé, nous imposant une sélection de variables sévère.
L’échantillon est subdivisé en 2 parties, nous construisons le modèle sur la partie apprentissage, nous l’évaluons sur la partie test. Nous utilisons la courbe lift pour comparer les approches. Plus précisément, nous comptabilisons le nombre de positifs que nous arrivons à détecter dans une cible de 300 individus.
Deux conclusions s’imposent dans cet exemple. (1) La sélection de variables diminue considérablement le nombre de descripteurs sans dégrader la qualité du scoring. (2) Selon que l’on adopte une recherche forward ou backward, nous n’obtenons, ni le même nombre de variables, ni les mêmes variables. Mais la qualité du ciblage est quasi identique.
Ce dernier résultat laisse souvent perplexe les praticiens : quel modèle choisir au final ? On pourrait déjà adopter la solution comportant le plus petit nombre de variables. Ca a le mérite de trancher. Mais, à mon sens, il faut surtout voir ces approches comme des outils fournissant des scénarios. Charge à nous, avec une expertise autre que purement statistique (banquier, médecin, etc.), de choisir par la suite la solution la plus appropriée, en adéquation avec les connaissances et les contraintes du domaine.
Mots clés : scoring, ciblage marketing, régression logistique
Composants : Supervised learning, Binary logistic regression, Select examples, Scoring, Lift curve, Forward-logit, Backward-logit
Lien : fr_Tanagra_Variable_Selection_Binary_Logistic_Regression.pdf
Données : dataset_scoring_bank.xls
Références :
R. Rakotomalala – « Ciblage marketing – Construire la courbe Lift »
R. Rakotomalala – « Régression logistique »
Ciblage marketing (scoring) – Coil challenge
2008-03-20 (Tag:1155728077892147299)
Le ciblage en Data Mining consiste à constituer des groupes d’individus dans lequel nous maximisons le nombre d’éléments « positifs ». L’exemple le plus souvent cité est l’entreprise qui veut faire la promotion d’un produit en envoyant un courrier à ses clients. Les « positifs » sont les personnes qui vont répondre positivement à l’offre. La cible constitue les prospects, les individus contactés. Pour des questions de coûts, il n’est pas possible de solliciter tous les clients. Il faut que dans la cible souhaitée, limitée par un budget souvent, la proportion de personnes positives soit le plus élevé possible.Parfois, la démarche est inversée : l’entreprise fixe un objectif en parts de marchés, nombre de clients positifs à retrouver, on s’appuiera sur le scoring pour déterminer la cible de plus petite taille possible afin d’obtenir ce résultat.
Au final, nous sommes bien dans un problématique d’apprentissage supervisé à 2 classes : on veut différencier les positifs des négatifs. A la différence qu’il ne s’agit pas prédire absolument l’étiquette des individus, mais plutôt de leur attribuer un score (de positivité) qui permet de trier la base selon l’appétence du client au produit proposé. La matrice de confusion et le taux d’erreur n’ont plus de sens dans ce contexte. On préfèrera un outil spécifique, la COURBE LIFT (GAIN CHART), pour définir la part de marché obtenue à budget fixé, ou inversement, déterminer le budget nécessaire pour obtenir une part de marché fixée.
Ce didacticiel montre la mise en œuvre du scoring dans Tanagra à l’aide de l’analyse discriminante. Les données proviennent d’une compétition qui a été organisée en 2000 (CoIL Challenge 2000) : il s’agissait de repérer parmi les clients d’une compagnie d’assurance, ceux qui vont prendre une police d’assurance pour leur caravane.
Les résultats du concours ont montré que les méthodes avec un biais de représentation linéaire (type analyse discriminante, régression logistique ou modèle d’indépendance conditionnelle [Naive Bayes]) se comportent très bien dans le scoring. C’est par ailleurs ce que constatent tous les jours les chargés d’études qui travaillent dans le domaine. Les méthodes plus complexes sont rarement meilleures. De plus, elles pâtissent d’un défaut rédhibitoire, il est difficile de discerner le rôle des variables dans la détection des positifs.
Enfin, par rapport au descriptif proposé dans le didacticiel, Tanagra (version 1.4.21 et +) affiche directement maintenant la courbe lift dans un onglet supplémentaire de la fenêtre d'affichage.
Mots clés : scoring, ciblage marketing, analyse discriminante, courbe lift, gain chart
Composants : Supervised learning, Linear discriminant analysis, Select examples, Scoring, Lift curve
Lien : fr_Tanagra_Scoring.pdf
Données : tcidata.zip
Référence : R. Rakotomalala – « Ciblage marketing – Construire la courbe Lift »
Déploiement de modèles avec Tanagra
2008-03-20 (Tag:123762518799927571)
Le déploiement des modèles est une activité clé du Data Mining. Dans le cas de l’apprentissage supervisé, il s’agit de classer de nouveaux individus à partir des valeurs connues des variables prédictives introduites dans le modèle. Dans le cas de l’analyse factorielle, il s’agit de fournir les coordonnées factorielles d’un individu à partir de la description dans l’espace initial. Dans le cas de la classification automatique (clustering), il s’agit de définir le groupe d’appartenance d’un individu supplémentaire, etc.Sipina s’appuie sur un dispositif relativement simple pour cette tâche. On peut appliquer un arbre de décision sur un nouveau fichier. Comme les données ne subissent pas de transformations intermédiaires avant l’apprentissage supervisé, la correspondance entre les variables du fichier de données servant à élaborer le modèle et les variables disponibles pour le déploiement est relativement aisée.
Dans le cas de Tanagra, la situation est autrement plus complexe pour deux raisons : c’est un logiciel généraliste, intégrant des techniques de nature différentes ; le concept de la chaîne de traitements implique une succession de transformations. Prenons un exemple d’apprentissage supervisé pour fixer les idées. Les descripteurs sont initialement composés de variables quantitatives et qualitatives. Nous discrétisons tout d’abord les variables quantitatives. Puis, nous intégrons les variables discrétisées et les variables déjà qualitatives dans une analyse en composantes multiples. Les axes factoriels deviennent alors les entrées de l’analyse discriminante.
Lorsque nous voulons déployer le modèle sur un nouveau fichier de données, seules les variables originelles sont décrites. Il nous faudrait donc reproduire la séquence des opérations en effectuant le déploiement à partir de tous les opérateurs intermédiaires c.-à-d. appliquer la discrétisation sur les variables quantitatives en utilisant les paramètres calculés en apprentissage, calculer les coordonnées factorielles, effectuer la prédiction de l’analyse discriminante enfin. Cela peut être très rapidement inextricable...
Tanagra réalise bien toutes ces opérations lors du déploiement d’une chaîne de traitements complexe. Mais pour éviter de tomber dans un dispositif qui ressemblerait rapidement à une usine à gaz, le fichier doit être préparé d’une manière particulière, afin que les opérations intermédiaires soient correctement réalisées.
Ce didacticiel montre comment doit être organisé le fichier de données pour que le déploiement soit réalisé efficacement. Nous illustrons notre propos avec un exemple assez simple. Mais la démarche peut être généralisée à des chaînes de traitements complexes.
Mots clés : déploiement de modèles, arbres de décision, CART, exportation des données
Composants : Supervised learning, C-RT, Select examples, View dataset, Export dataset
Lien : fr_Tanagra_Deployment.pdf
Données : tanagra_deployment_files.zip
Sélection de variables – Bayesien naïf
2008-03-20 (Tag:7962008072003053436)
La sélection de variables est une étape primordiale du Data Mining. Dans le cadre de l’apprentissage supervisé, parmi les objectifs de la fouille de données figure, en très bonne place, la recherche des causalités entre les variables prédictives et la variable à prédire. Plus le nombre de variables retenu est faible, meilleure sera la lisibilité du modèle prédictif. De plus, il est avéré qu’un modèle simple sera plus robuste lorsqu’il sera déployé dans la population.Ce didacticiel décrit la mise en œuvre du composant MIFS (Battiti, 1994) dans l’apprentissage du modèle d’indépendance conditionnelle (Bayesien Naïf). Il est intéressant à double titre car cette phase de sélection est précédée d’un recodage où les descripteurs continus sont préalablement discrétisées avec la méthode MDLPC.
L’efficacité de la sélection est évaluée en comparant les performances en validation croisée du modèle avec et sans sélection de variables. Nous traitons le fameux fichier des IRIS de Fisher (1936).
Mots clés : sélection de variables, discrétisation, modèle d’indépendance conditionnelle
Composants : Supervised learning, Naive Bayes, MDLPC, MIFS filtering, Cross validation
Lien : Feature_Selection_For_Naive_Bayes.pdf
Données : iris.bdm
Référence : R. Battiti, « Using the mutual information for selecting in supervised neural net learning », IEEE Transactions on Neural Networks, 5, pp.537-550, 1994.
Traitement des grands fichiers
2008-03-20 (Tag:1362181543924691821)
Une des principales nouveautés de ces dernières années est l’évolution quasi-exponentielle du volume des fichiers que nous sommes emmenés à traiter. Il y a une dizaine d’années encore, un tableau de 5000 observations avec 22 variables, les fameuses « ondes de Breiman », faisait figure de « gros fichier » au sein de la communauté de l’apprentissage automatique. Aujourd’hui, les tailles de fichiers connaissent une inflation galopante avec une augmentation importante du nombre d’observations (les bases marketing) et/ou du nombre de descripteurs (en bio-informatique, en réalité tous les domaines où les descripteurs sont générés automatiquement).La capacité à traiter les gros ensembles de données est un critère important de différenciation entre les logiciels de recherche et les logiciels commerciaux. Très souvent les outils commerciaux disposent de systèmes de gestion de données très performants, limitant la quantité de données chargée en mémoire à chaque étape du traitement. Les outils de recherche en revanche conservent toutes les données en mémoire, en les codant au mieux de manière à ce que l’occupation de la RAM ne soit pas prohibitive. Dès lors, les limites du logiciel sont déterminées par les capacités de la machine utilisée.
TANAGRA se situe précisément dans la seconde catégorie. Il charge toutes les données en mémoire, sous une forme encodée. Il est intéressant d’analyser les temps de traitements sur un fichier de taille (relativement) respectable. Nous décrivons cela dans ce didacticiel en mettant en exergue l’importation des données et l’induction d’un arbre de décision avec la méthode ID3.
Mots clés : temps de traitement, capacité de traitement, grandes bases de données, arbres de décision
Composants : Supervised learning, ID3
Lien : fr_Tanagra_Big_Dataset.pdf
Données : covtype.zip
Sauver et charger des parties du diagramme
2008-03-20 (Tag:4523544240631350666)
Bien souvent, nous utilisons les mêmes séquences de traitements lorsque nous traitons, avec des objectifs identiques, des bases de données présentant des caractéristiques similaires.
Prenons le cas de l’apprentissage supervisé, il s’agit de définir la variable à prédire et les variables prédictives, mettre en place la méthode d’apprentissage, et valider la chaîne à l’aide d’une technique de ré échantillonnage. L’analyse peut être complétée par une étape de sélection de variables. Il s’agit bien là d’une démarche type qui peut être transposée dans tout problème d’apprentissage supervisé. Il serait intéressant de pouvoir créer, une fois pour toutes, ce « super composant » constitué d’un enchaînement standardisé. L’objectif est de pouvoir le reproduire facilement lors de l’exploration d’autres fichiers.
Il est possible de sauvegarder dans un fichier externe une fraction du diagramme dans TANAGRA. On pourra le charger dans un autre contexte pour définir les mêmes traitements types. On peut le voir comme un module de programme partageable. Il faut bien entendu que les configurations soient compatibles.
Dans ce didacticiel, nous traitons un problème de prédiction où tous les descripteurs sont discrets. Nous utilisons le modèle d’indépendance conditionnelle. Nous voulons comparer les performances du classifieur, avec et sans FCBF (Yu et Liu, 2003), une méthode de sélection de variables. Les manipulations sont décomposées en 3 phases : (1) création du diagramme type sur un des fichiers de données ; (2) sauvegarde de la fraction du diagramme que l’on veut partager ; (3) importation de la fraction dans un autre diagramme, traitant un autre fichier de données.
Cette fonctionnalité peut être vue comme une généralisation du copier coller. A la différence que nous pouvons travailler sur plusieurs diagrammes différents. Elle ouvre des perspectives intéressantes. On pourrait demander à des experts de définir des séquences de traitements types qui seront distribuées aux utilisateurs.
Mots clés : sauvegarde du diagramme, copier coller, comparaison de classifieurs, apprentissage supervisé, validation croisée, modèle d’indépendance conditionnelle, sélection de variables, FCBF
Composants : Supervised learning, Naive Bayes, Cross validation
Lien : fr_Tanagra_Diagram_Save_Subdiagram.pdf
Données : congressvote_zoo.zip
Voir aussi : Copier coller dans le diagramme
Copier coller dans le diagramme
2008-03-20 (Tag:3515989782790300799)
A mesure que les calculs deviennent complexes, la taille d’un diagramme enfle rapidement, d’autant plus que certaines séquences d’opérations sont répétitives. Il est important dans ce contexte de disposer d’outils simples pour dupliquer des branches entières du diagramme, un copier coller de composants en quelque sorte.
Dans ce didacticiel, nous voulons comparer 5 méthodes d’apprentissage en validation croisée sur un fichier de données. La construction et le paramétrage de la première branche du diagramme sont réalisés manuellement. Par la suite, pour chaque méthode, les séquences d’opérations sont les mêmes. Pouvoir dupliquer la chaîne de composants simplement est un avantage appréciable.
Dans une deuxième étape, nous avons voulu introduire une construction de variables adéquate pour bonifier l’apprentissage. Nous effectuons une analyse en composantes principales sur les descripteurs. L’apprentissage supervisé est ensuite réalisé sur les axes factoriels les plus significatifs. L’idée est de « lisser » les données de manière à ne conserver que l’information utile pour la modélisation. Dans le contexte de ce fichier, avec un rapport nombre de variables – nombre d’individus élevés, cette préparation est vraisemblablement avantageuse. Nous voulons justement le vérifier en répétant les comparaisons ci-dessus. Dans ce cas, c’est toute une branche du diagramme qu’il faut dupliquer, il est évident que le copier coller est indispensable, ré-insérer manuellement la série de composants est non seulement fastidieuse mais expose le praticien à de multiples erreurs de manipulations.
Mots clés : copier coller, comparaison de classifieurs, apprentissage supervisé, validation croisée, régression logistique, régression pls, svm, analyse discriminante linéaire, k-nn, analyse en composantes principales, régularisation
Composants : Supervised learning, Binary logistic regression, C-PLS, C-SVC, Linear discriminant analysis, K-NN, Principal Component Analysis
Lien : fr_Tanagra_Diagram_New_Features.pdf
Données : sonar.xls
Voir aussi : Comparaison de classifieurs
Importer un fichier Weka dans Tanagra
2008-03-20 (Tag:7052415468970909662)
WEKA est un logiciel de Data Mining libre très populaire dans la communauté « Machine Learning ». Il possède un format de fichier propriétaire (*.ARFF), qui est un format texte, avec des spécifications ad hoc pour documenter les variables. Importer un fichier ARFF ne pose donc pas de problèmes particuliers, dès lors que l’on sait appréhender un fichier texte.
Dans ce didacticiel, nous montrons comment charger un fichier ARFF dans TANAGRA. Lorsque le fichier comporte des données manquantes, une substitution très sommaire est mise en place : la moyenne est utilisée pour les variables continues, une nouvelle modalité est créée pour les variables discrètes.
Les traitements peuvent commencer normalement, un diagramme est automatiquement créé. Si nous décidons de le sauvegarder au format TDM, la référence du fichier est enregistrée. Au prochain chargement du diagramme, l’importation du fichier ARFF est réalisée automatiquement sans manipulations spécifiques.
Mots clés : WEKA, format de fichier ARFF, importation de données
Composants : Dataset
Lien : fr_Tanagra_Handle_WEKA_File.pdf
Données : sick.arff
Voir aussi : Importer un fichier Weka dans Sipina
Codage disjonctif complet
2008-03-20 (Tag:104283591613088241)
Ce didacticiel est le pendant de celui traitant de la discrétisation des variables continues. Il s’agit de transformer une variable catégorielle (qualitative) en variables numériques (indicatrices).Lorsque les variables prédictives (variables indépendantes, exogènes, etc.) sont catégorielles, les méthodes d’apprentissage supervisé telles que la régression logistique et l’analyse discriminante ne peuvent pas être mises en oeuvre directement. Il est nécessaire de recoder les variables.
La technique la plus connue est certainement le codage disjonctif complet ou codage 0/1. Chaque modalité de la variable originelle devient une variable binaire qui prend la valeur 1 lorsque la modalité est présente pour un individu, 0 sinon. Puisque la somme de ces nouvelles variables est systématiquement égal à 1, il est d’usage d’omettre la dernière modalité qui peut être déduite des autres c.-à-d. si toutes les variables binaires prennent la valeur 0, on en déduit que l’individu porte la dernière valeur, elle devient la modalité de référence.
Attention, si la variable à recoder est ordinale, ce dispositif peut être utilisé toujours, mais dans ce cas nous perdons de l’information : la méthode d’apprentissage ne tient plus compte du caractère ordinal des modalités. Un codage 0/1 emboîté est plus indiqué si l’on veut la préserver.
Dans ce didacticiel, nous montrons comment utiliser le composant 0_1_ BINARIZE pour transformer une variable catégorielle en une série de variables binaires que nous introduisons dans une régression logistique.
Autre particularité de ce document, nous montrons comment, directement dans TANAGRA, subdiviser de manière aléatoire l’ensemble de données en 2 fractions : la première, l’échantillon d’apprentissage, sert à la construction du modèle ; la seconde, l’échantillon test, sert à son évaluation.
Mots clés : codage disjonctif complet, codage binaire 0/1, régression logistique, échantillon d’apprentissage, échantillon test
Composants : Sampling, 0_1_Binarize, Supervised Learning, Binary Logistic Regression, Test
Lien : fr_Tanagra_Dummy_Coding_for_Logistic_Regression.pdf
Données : categorical_heart.xls
Discrétisation contextuelle – La méthode MDLPC
2008-03-19 (Tag:52019321530466153)
La préparation des variables est une étape clé du Data Mining. De la qualité du travail réalisé durant cette phase dépend le succès de la modélisation entreprise par la suite.
La construction de variables nous sert avant tout à mettre en évidence les informations pertinentes dans les données. Mais dans certaines situations, le recodage est une nécessité. Lorsque, par exemple, la technique de fouille subséquente ne sait pas appréhender tel ou tel type de données, nous devons modifier la nature de la variable, en la passant d’un type quantitatif vers un type qualitatif, ou inversement, l’important étant de produire un codage efficace où les pertes d’informations, voire les injections de nouvelles informations, parfois intempestives, sont contrôlées.
Composants : MDLPC, Supervised Learning, Naive bayes, Cross-validation
Lien : SupervisedDiscretisation.pdf
Données : breast.bdm
Références :
U. Fayyad et K. Irani, « Multi-interval discretization of continuous-valued attributes for classification learning », in Proc. of IJCAI, pp.1022-1027, 1993.
R. Rakotomalala, « Graphes d’Induction », Thèse de Doctorat Lyon 1, 1997 ; chapitre 9, pp.209-244.
Connexion Open Office Calc
2008-03-19 (Tag:6024625723889334439)
De la même manière qu’il est possible de transférer directement des données d’EXCEL vers TANAGRA via une macro complémentaire (voir Connexion Excel – Tanagra), nous avons mis au point un add-on (ou add-in) pour le tableur Calc d’Open Office (Open Office Calc).
La procédure est la même. Lors de l’installation de TANAGRA, l’add-in est automatiquement installé sur le disque dur. Il nous reste à la brancher dans Open Office Calc en suivant une procédure précise.
Ce didacticiel décrit la démarche à suivre pour installer correctement l’add-in dans Open Office Calc. Deux documents sont disponibles : (1) un pdf classique déroulant les étapes avec des copies d’écran ; (2) une démonstration animée au format flash (en anglais mais les menus sont tous en français).
Mots clés : importation des données, tableur, open office calc, add-in, add-on, création d’un diagramme de traitement
Composants : View Dataset
Lien pdf : fr_Tanagra_OOoCalc_Addon.pdf
Lien démo animée : from_OOoCalc_To_Tanagra.htm
Données : breast.ods
Importer un fichier Weka dans Sipina
2008-03-19 (Tag:488322573618026560)
WEKA est un logiciel de Data Mining libre très populaire dans la communauté « Machine Learning ». Il intègre un grand nombre de méthodes, articulées essentiellement autour des approches supervisées et non supervisées.
WEKA possède un format de fichier propriétaire (*.ARFF), qui est un format texte, avec des spécifications ad hoc pour documenter les variables. Importer un fichier ARFF ne pose donc pas de problèmes particuliers, dès lors que l’on sait appréhender un fichier texte.
Dans ce didacticiel, nous montrons comment charger un fichier ARFF dans SIPINA. L’importation est directe, il s’agit simplement de connaître la bonne procédure. Nous profitons de cet exemple pour montrer comment subdiviser aléatoirement un ensemble de données pour : construire l’arbre sur l’échantillon d’apprentissage, l’évaluer sur l’échantillon test. Nous utilisons la méthode C4.5 (Quinlan, 1993).
Mots clés : WEKA, format de fichier ARFF, arbres de décision, C4.5, subdivision apprentissage et test, évaluation des classifieurs
Lien : fr_sipina_weka_file_format.pdf
Données : ionosphere.arff
Description de l’interface SIPINA
2008-03-18 (Tag:5820319485750320581)
Un texte, un peu ancien et assez succinct, qui décrit les principales fonctionnalités de SIPINA : chargement de données, avec le format propriétaire binaire (*.fdm) ; choix de la méthode d'apprentissage ; définition de la variable à prédire et des variables prédictives ; sélection des individus en apprentissage et en test ; création et lecture d'un arbre de décision.Le principal intérêt de ce document est qu'il essaie de recenser les éléments d'interface du logiciel : barre d'outils, explorateur de projets, barre d'état, etc.
Mots-clés : interface SIPINA, arbres de décision
Lien : french_introduction_sipina_research.pdf
Déploiement d'un arbre de décision avec SIPINA
2008-03-17 (Tag:2081002236066069496)
Déploiement de modèles. Le déploiement des modèles est une activité clé du Data Mining. Dans le cas de l’apprentissage supervisé, il s’agit de classer de nouveaux individus à partir des valeurs connues des variables prédictives introduites dans le modèle. SIPINA peut directement appliquer un arbre de décision sur un nouveau fichier non étiqueté. Petite contrainte néanmoins, le processus de déploiement doit être consécutif à l’apprentissage. Il n’est pas possible de distribuer un modèle pour l’appliquer sur de nouveaux individus en dehors de l’environnement SIPINA.Evaluation des performances. Prédire sur des nouveaux individus, c’est bien. Mais il faut pouvoir annoncer à l’avance les performances à venir. En effet, une affectation erronée produit des conséquences négatives (ex. diagnostiquer l’absence d’une maladie chez une personne souffrante fera qu’elle ne sera pas soignée). Pouvoir évaluer la fiabilité d’un modèle prédictif est primordiale pour la décision de sa mise en production (ou non). Nous utiliserons la méthode bootstrap dans ce didacticiel. Le but est de fournir une mesure crédible de la performance de l’arbre construit sur la totalité des données disponibles.
Ce tutoriel montre comment, avec SIPINA, construire un arbre de décision, l’appliquer sur un fichier de données non étiqueté. Par la suite, les performances en prédiction sont estimées par bootstrap. Le même schéma sera appliqué dans un second temps en utilisant l’analyse discriminante.
Mots clés : déploiement de modèles, arbres de décision, évaluation des classifieurs, bootstrap, méthodes de ré échantillonnage, analyse discriminante
Lien : fr_sipina_deployment.pdf
Données : wine_deployment.xls
Comparaison de classifieurs
2008-03-09 (Tag:8239961562268097449)
Pour évaluer un algorithme d'apprentissage supervisé, on conseille souvent de subdiviser les données en deux sous-ensembles disjoints : l'ensemble d'apprentissage (learning set) qui sert à élaborer le modèle de prédiction ; l'ensemble test (test set) qui sert à en mesurer les performances. TANAGRA dispose d'outils permettant de construire automatiquement ces sous-ensembles à partir d'un échantillonnage. Mais, dans certains cas, l'utilisateur peut vouloir procéder lui-même à cette subdivision afin d'utiliser les mêmes ensembles d'apprentissage et de test pour comparer les algorithmes d'apprentissage.Dans ce didacticiel, nous utiliserons un fichier de données dans lequel nous avons introduit une colonne supplémentaire permettant de désigner les individus à utiliser pour l'apprentissage et ceux à utiliser lors de l'évaluation. Nous montrerons alors quels composants utiliser pour désigner les observations qui vont servir à construire les modèles de prédiction, nous utiliserons un autre composant pour comparer leurs performances sur l'ensemble test.
Mots clés : apprentissage supervisé, comparaison de classifieurs, schéma apprentissage test, taux d'erreur, matrice de confusion, analyse discriminante linéaire, support vector machine, algorithme des plus proches voisins
Composants : Select examples, Supervised learning, Linear discriminant analysis, SVM, K-NN
Lien : fr_Tanagra_Compare_Algorithms_On_Predefined_Test_Set.pdf
Données : sonar_with_test_set.xls
Références :
R. Rakotomalala, " Apprentissage supervisé "
R. Rakotomalala, " Estimation de l'erreur de prédiction - Les techniques de ré échantillonnage "
Classification automatique - Algorithme EM
2008-03-09 (Tag:4041160085304623410)
Les modèles de mélanges traduisent une fonction de densité régissant la distribution de données à l'aide d'une combinaison linéaire de fonctions de densité élémentaires. L'approche la plus connue est le modèle de mélange gaussien où les densités élémentaires sont des lois normales multidimensionnelles.Cette technique peut être utilisée pour décrire la distribution des données en classification automatique. Chaque classe (groupe, cluster, etc.) est décrite par une loi de distribution normale, paramétrée par son centre de gravité et sa matrice de variance covariance. Pour estimer les paramètres des distributions élémentaires, l'algorithme EM (Expectation-Maximization) est certainement le plus connu. L'objectif est de maximiser la logvraisemblance de l'échantillon de données compte tenu d'un nombre de cluster défini au préalable.
Dans ce didacticiel, nous montrons l'intérêt de cette approche sur des données artificielles. Malgré la difficulté du problème proposé, l'algorithme EM trouve parfaitement la solution adéquate. Nous donnons des indications également pour détecter au mieux, de manière raisonnée en tous les cas, le bon nombre de groupes, un problème récurrent de la classification automatique.
Malgré sa puissance, cette technique est peu diffusée, peu utilisée, peu enseignée, peut être parce qu'elle est rarement implémentée dans les logiciels de Data Mining.
Mots clés : classification automatique, algorithme EM, modèle de mélange gaussien, maximisation de la vraisemblance, choix du nombre de classes
Composants : EM-Clustering, K-Means, EM-Selection, scatterplot
Lien : fr_Tanagra_EM_Clustering.pdf
Données : two_gaussians.xls
Références :
Wikipédia (fr) -- Algorithme espérance-maximisation
Wikipédia (en) -- Expectation-maximization algorithm
La complémentarité CAH et ACP
2008-03-09 (Tag:6984350710753659934)
L'appréhension d'un problème de fouille de données est rarement monolithique. Certes, nous identifions rapidement si nous devons mettre en œuvre des techniques descriptives, des techniques de classification ou des techniques de prédiction pour répondre au cahier de charges d'une étude. Il n'en reste pas moins que dans la grande majorité des cas, nous devons faire coopérer ces approches pour obtenir des résultats performants et interprétables.Dans ce didacticiel, nous cherchons à regrouper des véhicules à partir de leurs caractéristiques (poids, consommation, etc.). La combinaison d'une technique de visualisation, l'analyse en composantes principale, avec une technique de typologie, la classification ascendante hiérarchique, amplifie la portée des résultats. Il faut dire que l'exemple s'y prête bien. L'interprétation des groupes produits par la classification automatique est un problème crucial, souvent malaisé. Bénéficier des lumières d'une technique de visualisation nous permet de mieux délimiter ce que nous produisons.
L'exemple nous montre qu'il faut se méfier des résultats automatisés, basés uniquement par des procédures numériques. L'interprétation des résultats, l'expertise que nous pouvons apporter par ailleurs, nous permet de guider les résultats vers des solutions plus en harmonie avec les connaissances du domaine.
Mots clés : CAH, classification automatique, ACP, analyse factorielle, techniques de visualisation
Composants : HAC, Group characterization, Principal component analysis, correlation scatterplot, scatterplot
Lien : fr_Tanagra_hac_pca.pdf
Données : cars.xls
Références :
M. Gettler-Summa, C. Pardoux, " La classification automatique " -- Classification.pdf
A. Baccini, P. Besse, " Data Mining I - Exploration Statistique " -- Explo_stat.pdf
Analyse discriminante descriptive - Vins de Bordeaux
2008-03-09 (Tag:2675486121474857533)
L'analyse discriminante est une technique statistique qui cherche à décrire, expliquer et prédire l'appartenance à des groupes prédéfinis (classes, modalités de la variable à prédire, ...) d'un ensemble d'observations (individus, exemples, ...) à partir d'une série de variables prédictives (descripteurs, variables exogènes, ...).On distingue généralement deux approches, qui peuvent se rejoindre : l'analyse discriminante descriptive, que nous étudions dans ce didacticiel, et l'analyse discriminante prédictive que nous étudierons dans d'autres circonstances.
L'analyse factorielle discriminante, ou analyse discriminante descriptive, vise à produire un nouveau système de représentation, des variables latentes formées à partir de combinaisons linéaires des variables prédictives, qui permettent de discerner le plus possible les groupes d'individus. En ce sens, elle se rapproche de l'analyse factorielle car elle permet de proposer une représentation graphique dans un espace réduit, plus particulièrement de l'analyse en composantes principales calculée sur les centres de gravité conditionnels des nuages de points avec une métrique particulière. On parle également d'analyse canonique discriminante, notamment dans les logiciels anglo-saxons.
Ce didacticiel, nous cherchons à décrire la qualité des vins du beaujolais à partir de variables météorologiques. TANAGRA indique à la sortie les axes factoriels significatifs, les corrélations totales, intra et inter groupes, qui permettent de les interpréter. Cet exemple est tiré de l'ouvrage de M. Tenenhaus (1996).
Mots clés : analyse factorielle discriminante, analyse discriminante descriptive
Composants : Canonical discriminant analysis, Scatterplot
Lien : fr_Tanagra_Canonical_Discriminant_Analysis.pdf
Données : wine_quality.xls
Références :
M. Tenenhaus, " Méthodes statistiques en gestion ", Dunod, 1996 ; page 244.
Wikipédia -- Analyse discriminante
Sélection forward - Crime dataset
2008-03-09 (Tag:7550321006701097757)
La sélection de variables est une opération primordiale dans la régression linéaire multiple. Il s'agit tout d'abord d'écarter les variables non pertinentes dans le processus d'explication de la variable endogène. Mais il s'agit également de traiter le cas des variables redondantes, emmenant le même type d'information, fortement corrélées au point d'empêcher le calcul correct des coefficients et de leurs caractéristiques (écart type notamment). C'est le problème de la colinéarité des exogènes.Ce didacticiel montre la mise en œuvre d'une technique simple de sélection de variables. La sélection est séquentielle, en ajoutant au fur et à mesure une explication additionnelle significative au regard des variables déjà introduites : on parle de sélection forward. Ce processus peut s'interpréter de différentes manières. Une lecture en termes de corrélation partielle est peut être la plus séduisante : à chaque étape on cherche la variable exogène la plus corrélée avec l'endogène après soustraction de l'information emmenée par les variables sélectionnées à l'étape précédente.
Dans ce didacticiel, nous voulons expliquer la criminalité dans 47 états des USA en 1960 à partir des indicateurs socio-économiques (taux de chômage, revenu moyen, etc.).
Mots clés : régression linéaire multiple, économétrie, sélection de variables, sélection forward, stepwise, colinéarité, corrélation partielle
Composants : View Dataset, Multiple linear regression,
Lien : fr_Tanagra_Forward_Selection_Regression.pdf
Données : crime_dataset_from_DASL.xls
Références :
Cours économétrie L3 IDS Lyon 2-- Cours Econométrie
Pratique de la régression -- La régression dans la_pratique
Régression - Expliquer la consommation des véhicules
2008-03-09 (Tag:8498260728034790274)
La régression linéaire multiple est une technique statistique qui vise à modéliser la relation entre une variable dépendante quantitative (endogène) avec une ou plusieurs variables indépendantes quantitatives (exogènes, elles peuvent être qualitatives mais doivent être recodées). C'est une technique très populaire. Son domaine d'application est très large. Une des applications privilégiées est la modélisation des phénomènes économiques. Elle rentre dans un cadre plus large qu'est l'économétrie dans ce cas.La régression peut être à vocation prédictive, c.-à-d. à partir de la connaissance des valeurs prises par les exogènes, on essaie de prédire les valeurs prises par l'endogène. Elle peut être à vocation explicative c.-à-d. essayer de délimiter le rôle des variables exogènes dans l'explication de l'endogène. Dans tous les cas, l'étude et l'interprétation des résultats tiennent une place prépondérante dans l'analyse.
Dans ce didacticiel, nous voulons expliquer la consommation des véhicules automobiles à partir de leurs caractéristiques (poids, puissance, etc.).
Mots clés : régression linéaire multiple, économétrie, variable endogène, variables exogènes
Composants : View Dataset, Multiple linear regression
Lien : Regression.pdf
Données : autompg.bdm
Références :
Wikipédia -- Régression linéaire multiple
Cours économétrie L3 IDS Lyon 2-- Cours Econométrie
CAH Mixte - Le fichier Iris de Fisher
2008-03-09 (Tag:8436901916753805071)
La CAH (classification ascendante hiérarchique) est une technique de classification automatique. Elle vise à produire un regroupement des individus de manière à ce que les individus dans un même groupes soient similaires, les individus dans des groupes différents soient dissemblables.La CAH a de particulier qu'elle propose une série de partitionnement emboîtés, avec une représentation graphique, le dendrogramme, qui donne des indications sur les solutions alternatives à évaluer. La détermination du bon nombre de groupes est un problème récurent en typologie, le nombre de solutions à étudier est ainsi réduit.
La CAH pose problème dès que la taille de la base augmente. L'obligation de calculer les distances entre les individus deux à deux est très vite rédhibitoire. Dans un contexte où les bases contiennent plusieurs milliers d'individus, il est inepte de vouloir construire le dendrogramme en partant directement des observations. Même si le calcul était possible, la lecture des parties basses de l'arbre est impossible, et de toute manière inutile.
LA CAH - MIXTE permet de dépasser élégamment cet écueil en effectuant un pré regroupement des individus, assez fruste, avec une méthode de réallocation par exemple, de manière à ce que ce premier partitionnement soit le point de départ de la création du dendrogramme.
Le premier regroupement en un nombre assez important de classes (une vingtaine) a peu d'intérêt en tant que tel. Sa lecture et son interprétation n'ont pas de sens. En revanche, elle permet de réduire considérablement les calculs lorsque l'on met en œuvre par la suite une construction de l'arbre selon la méthode de Ward. Il n'est pas nécessaire de recalculer les distances entre les couples d'individus, le calcul de proche en proche des centres de gravité des groupes suffit.
Ce didacticiel décrit le traitement du fameux fichier IRIS (Fisher, 1936). On cherche à produire un regroupement en 3 classes des iris à partir de leur morphologie. On confrontera par la suite les classes obtenues avec l'espèce, connue, de la fleur. On parle dans ce cas de validation externe. On connaît une classe d'appartenance a priori. On regarde si les classes produites " en aveugle ", sur la base uniquement des descripteurs, sont concordantes.
Mots clés : classification, typologie, CAH, nuées dynamiques, K-Means, validation externe
Composants : HAC , K-Means, Group characterization
Lien : HAC_IRIS.pdf
Données : iris_hac.bdm
Référence : L. Lebart, A. Morineau, M. Piron, " Statistique exploratoire multidimensionnelle ", Dunod, 2000 ; pages 177 à 184.
CART - Détermination de la taille de l'arbre
2008-03-09 (Tag:5675555174534297193)
Déterminer la bonne taille de l'arbre est une opération cruciale dans la construction d'un arbre de décision à partir de données. Elle détermine ses performances lors de son déploiement dans la population1. Il y a deux extrêmes à éviter : l'arbre sous dimensionné, trop réduit, captant mal les informations utiles dans le fichier d'apprentissage ; l'arbre sur dimensionné, de taille exagérée, captant les spécificités du fichier d'apprentissage, spécificités qui ne sont pas transposables dans la population. Dans les deux cas, nous avons un modèle de prédiction peu performant.La popularité de la méthode CART repose en grande partie sur sa capacité à proposer une démarche efficace de détermination de la bonne (je n'ose dire " optimale ") taille de l'arbre. Ce didacticiel montre comment se manifeste cette stratégie, quelles en sont les conséquences sur (1) la complexité de l'arbre (nombre de feuilles c.-à-d. nombre de règles) ; et (2) ses performances en prédiction (évaluation sur un fichier test n'ayant pas participé à l'élaboration du modèle).
Quelques pistes sont alors proposées pour fixer de manière raisonnée les paramètres de l'algorithme d'apprentissage, plus particulièrement la règle de l'écart type qui permet de réduire considérablement la taille de l'arbre sans dégrader les performances.
L'exemple traité consiste à prédire le niveau de revenu annuel des individus (supérieur à 50000 $ ou non) à partir de caractéristiques signalétiques (niveau d'étude, type d'emploi, etc.).
Mots clés : arbres de décision, CART, apprentissage et évaluation des classifieurs, principe de parcimonie, règle de l'écart type (1-SE Rule)
Composants : Discrete select examples, Supervised Learning, C-RT, Test
Lien : fr_Tanagra_Tree_Post_Pruning.pdf
Données : adult_cart_decision_trees.zip
Références :
L. Breiman, J. Friedman, R. Olshen, C. Stone, " Classification and Regression Trees ", California : Wadsworth International, 1984.
R. Rakotomalala, " Arbres de décision ", Revue Modulad, 33, 163-187, 2005 (tutoriel_arbre_revue_modulad_33.pdf)
Arbres de décision - ID3 sur Breast Cancer
2008-03-09 (Tag:1481484948951667828)
Les arbres de décision font partie des techniques les plus populaires du data mining. Dans ce didacticiel, nous montrons comment (1) implémenter la méthode ID3 sur un problème de prédiction de type de cellules (cancéreuse ou non) à partir de leurs caractéristiques (forme, taille, etc.) ; (2) lire les résultats produits par TANAGRA (matrice de confusion, lecture de l'arbre, déduction des règles).Plusieurs techniques sont disponibles dans TANAGRA, entre autres ID3 (Quinlan, 1979 ; Quinlan, 1986), C4.5 (Quinlan, 1993) et CART (Breiman et al., 1984). L'induction est totalement automatisée. Nous pouvons modifier les paramètres avant les calculs. En revanche, il n'est pas possible de manipuler interactivement l'arbre. Si on désire pouvoir intervenir dans la construction de l'arbre, choix des variables de segmentation, élagage manuel, mieux vaut se tourner vers le logiciel SIPINA. Les didacticiels sont disponibles dans la catégorie associée.
Mots clés : arbres de décision, ID3, apprentissage supervisé
Composants : Supervised Learning, ID3
Lien : DecisionTree.pdf
Données : breast.bdm
Références :
R. Quinlan, " Induction of Decision Trees ", Machine Learning, 1, 81-106, 1986.
R. Rakotomalala, " Arbres de décision ", Revue Modulad, 33, 163-187, 2005 (tutoriel_arbre_revue_modulad_33.pdf)
AFCM - Races canines
2008-03-09 (Tag:5646902309870877638)
Analyse factorielle des correspondances multiples (AFCM ou plus simplement ACM) est une technique factorielle, descriptive, qui vise à projeter un tableau de données individus - variables, variables exclusivement catégorielles, dans un espace réduit, respectant au mieux les proximités entre les individus.Il s'agit donc du pendant de l'analyse en composantes principales pour les variables catégorielles. Mais, contrairement à l'ACP, l'interprétation des axes factoriels à l'aide des pourcentages d'inerties, nettement plus répartis sur les axes successifs, est peu intéressante. On se concentrera avant tout sur les contributions pour leur interprétation, et les cosinus carrés pour évaluer la représentation des modalités sur les axes.
L'AFCM peut être aussi vue comme une technique de transformation de variables. Elle permet de passer d'un espace discret, décrit par les variables originales, en un espace continu, décrit par les axes factoriels. Sans perte d'informations si l'on choisit de conserver tous les axes. Avec une perte d'information contrôlée lorsque l'on ne conserve que les premiers axes. En effet, les derniers facteurs traduisent essentiellement les fluctuations aléatoires dues à l'échantillonnage, on lisse ainsi les données en nous concentrant sur les informations essentielles.
Ce didacticiel retrace un exemple tiré de l'ouvrage de M. Tenenhaus (1996) qui traite de la description de races canines à partir de caractéristiques physiques et psychiques. L'intérêt est de pouvoir comparer les résultats qu'il décrit avec les sorties que propose TANAGRA.
Mots clés : analyse factorielle des correspondances multiples, plan factoriel, contributions, cosinus carrés
Composants : Multiple correspondance analysis, View Dataset, Scatterplot with labels, View multiple scatterplot
Lien : fr_Tanagra_Acm.pdf
Données : races_canines_acm.xls
Référence : M. Tenenhaus, " Méthodes statistiques en gestion ", Dunod, 1996 ; pages 212 à 222.
AFC - Association médias et professions
2008-03-09 (Tag:2811478296671754924)
L'analyse factorielle des correspondances (AFC) est une technique factorielle adaptée au traitement des grands tableaux de contingence, tableaux de comptage croisant deux variables qualitatives.Elle permet de décomposer les principales associations (attractions - répulsions) entre les caractéristiques (les modalités) des variables du tableau de contingence.
Ce didacticiel décrit l'étude de l'association entre la profession des personnes et les médias qu'ils privilégient. Il reprend un exemple tiré de l'ouvrage de Lebart et al. (2000). L'intérêt est de faire le parallèle entre les résultats retracés dans l'ouvrage et les sorties que propose TANAGRA.
Mots clés : analyse factorielle des correspondances, tableau de contingence, khi-2, chi-2, plan factoriel, contributions, cosinus carrés
Composants : Correspondence analysis
Lien : fr_Tanagra_Afc.pdf
Données : media_prof_afc.xls
Référence : L. Lebart, A. Morineau, M. Piron, " Statistique exploratoire multidimensionnelle ", Dunod, 2000 ; pages 77 à 107.
ACP - Description de véhicules
2008-03-09 (Tag:1222307279606281988)
L'analyse en composantes principales est une technique factorielle très populaire. On peut la voir de différentes manières.Elle permet de visualiser un ensemble de données comportant plusieurs variables dans un espace de dimension réduite, dans le plan le plus souvent, en respectant plus ou moins les proximités entre les individus. Profitant d'une meilleure visualisation, le praticien du data mining peut détecter les groupes d'observations correspondant à des caractéristiques similaires.
L'ACP permet aussi de résumer les informations que porte les variables en les décomposant en des dimensions orthogonales, les composantes principales.
L'ACP constitue également une technique de régularisation, en proposant des variables synthétiques qui portent les informations " utiles " pour les techniques de fouilles de données qui viennent en aval.
La liste est longue...
Ce didacticiel montre la mise en œuvre de l'ACP dans un cadre descriptif. Il reprend un exemple décrit dans l'ouvrage de G.Saporta (Dunod, 2006). L'intérêt est de pouvoir faire le parallèle entre les sorties décrites dans l'ouvrage et les outils que propose TANAGRA pour évaluer et interpréter les résultats.
L'exemple traité concerne la description d'un ensemble de véhicules à l'aide de leurs caractéristiques (cylindrée, puissance, poids, etc.).
(Note de mise à jour : d'autres outils sont disponibles - "ACP avec Tanagra - Nouveaux outils" [15/06/2012])
Mots clés : analyse en composantes principales, analyse factorielle, méthodes de description, plan factoriel, cercle des corrélations
Composants : Principal Component Analysis, View Dataset, Scatterplot with labels, Correlation scatterplot, View multiple scatterplot
Lien : fr_Tanagra_Acp.pdf
Données : autos_acp.xls
Référence : G. Saporta, " Probabilités, Analyse de données et Statistique ", Dunod, 2006 ; pages 177 à 181.
Statistiques descriptives
2008-03-09 (Tag:2959042991421539078)
Réaliser des statistiques descriptives reste une opération incontournable du data mining. Résumer simplement les caractéristiques des données permet d'effectuer un diagnostic rapide des principales scories (valeur unique dans une colonne, distribution très déséquilibrée, etc.) qui pourraient limiter la portée des techniques de fouille de données mises en œuvre par la suite.
Ce didacticiel montre comment mettre en œuvre les techniques de description simple des données, différentes selon que les variables sont discrètes (qualitatives) ou continues (quantitatives).
Mots clés : statistique descriptive
Composants : View dataset, Univariate continuous stat, Univariate discrete stat, Group characterization
Lien : Basics.pdf
Données : breast.txt
Arbres interactifs - Sipina et Orange
2008-03-09 (Tag:12387467499700736)
Sipina et Orange sont parmi les très rares logiciels libres à intégrer des fonctionnalités interactives dans la construction d'un arbre de décision. Pourtant, cette particularité, c.-à-d. la possibilité pour un expert de guider la construction du modèle en accord avec les connaissances du modèle, constitue un des atouts majeurs de cette technique par rapport aux autres méthodes de data mining.Ce tutoriel compare les potentialités des logiciels Sipina et Orange dans une session d'élaboration interactive d'un arbre de décision. Les points suivants sont abordés : (1) importation d'un fichier texte ; (2) partitionnement d'un fichier en ensemble d'apprentissage et ensemble test, en utilisant une variable supplémentaire qui désigne le rôle des individus ; (3) induction et évaluation des performances d'un arbre ; (4) élagage manuel de l'arbre ; (5) choix de la variable de segmentation sur un nœud.
Le fichier IRIS est utilisé. Pas vraiment original à vrai dire, mais au moins on devine à l'avance la teneur des résultats que l'on devrait obtenir.
Mots clés : arbre de décision, analyse interactive, apprentissage et évaluation des classifieurs, fichier texte
Lien : fr_Tanagra_Interactive_Tree_Builder.pdf
Données : iris_tree.txt
Apprentissage - test avec Sipina
2008-03-09 (Tag:7276721755316627792)
Ce didacticiel montre comment exploiter un fichier scindé en deux parties : la première est dédiée à l'apprentissage de l'arbre de décision (échantillon d'apprentissage), la seconde est dédiée à son évaluation (échantillon test).Dans cet exemple, une variable indicatrice supplémentaire est intégrée au données, elle désigne le rôle que joue chaque individu dans la modélisation (apprentissage ou test). SIPINA s'appuie sur cette variable pour subdiviser le fichier. De manière plus générale, il est possible d'effectuer directement un partitionnement aléatoire des individus dans le logiciel lui même, la procédure est beaucoup plus simple.
La subdivision préalable, telle qu'elle est mise en oeuvre dans ce didacticiel, se justifie surtout lorsque nous voulons comparer les résultats produits par différents logiciels (ex. arbres de décision sous SIPINA vs. la procédure rpart du package du même nom de R, etc.). Ainsi, nous maîtrisons totalement le mode de subdivision des données, avec des résultats directement comparables d'un outil à l'autre : ils ont travaillé sur les mêmes individus en apprentissage et calculer les performances sur les mêmes individus en test.
Ce didacticiel présente un second thème : il montre comment mettre en oeuvre les coûts de mauvais classement dans une variante de C4.5. L'arbre de décision est ainsi optimisé pour non plus minimiser le taux d'erreur, mais un indicateur tenant compte de la nature non-symétrique des coûts telle que la F-Measure.
L'exemple traité concerne la détection automatique de spams à partir de caractéristiques extraites de courriers eléctroniques.
Mots-clés : arbres de décision, évaluation des classifieurs, C4.5, coûts de mauvais classement non-symétriques, F-Measure, détection de spams
Lien : fr_sipina_cost_sensitive.pdf
Données : spam.xls
Références : resampling_evaluation.pdf
Analyse interactive avec Sipina
2008-03-08 (Tag:1343165218752576673)
Le succès des arbres de décision repose en grande partie sur les fonctionnalités interactives des logiciels qui les implémentent. L'expert (lebanquier, le médecin, etc.) peut intervenir pour guider l'exploration vers les solutions qui sont en accord avec les connaissances du domaine. On imagine très mal un logiciel commercial d'induction d'arbres ne proposant pas ces fonctionnalités : exploration locale des sommets, choix des variables de segmentation, élagage manuel, ...
Du côté des logiciels gratuits, l'offre est nettement moindre. Certes, de nombreux logiciels proposent des algorithmes d'induction d'arbres, mais ils les présentent comme des techniques purement automatisées, au même titre que les autres méthodes de fouilles de données où le rôle de l'utilisateur se réduit à cliquer au bon endroit pour lancer les traitements et attendre les résultats pour les interpréter (quand c'est possible).
SIPINA est un des rares logiciels entièrement gratuits à offrir des ressources permettant à l'utilisateur d'approfondir son analyse durant la construction même de l'arbre. Elles sont peu connues du grand public car mal documentées. Je suis un peu fautif dans cette histoire. Dans la frénésie de la programmation, je n'avais pas eu (pris !) le temps de les documenter. Je passe mon temps à essayer de les recenser maintenant, j'en découvre encore maintenant, plusieurs années après l'arrêt du développement.
Dans ce didacticiel, les potentialités interactives de SIPINA pour comprendre, interpréter et manipuler l'arbre de décision pendant la phase d'exploration sont mises en avant.
Mots clés : arbres de décision, analyse interactive
Lien : fr_sipina_interactive.pdf
Données : blood_pressure_levels.xls
Connexion Excel - Sipina
2008-03-08 (Tag:4359719060084432026)
L'importation des données est un écueil important pour les logiciels libres de Data Mining. La grande majorité des utilisateurs travaillent avec un tableur, Excel principalement, en la couplant avec un logiciel spécialisé de Data Mining (voir à ce sujet l'enquête KDD). Dès lors, une question récurrente des utilisateurs est "comment faire pour importer mes données dans Sipina ?"Il est possible d'importer différents types de formats avec Sipina. Pour ce qui est des classeurs Excel, un dispositif particulier a été mis en place.
Une macro complémentaire est copiée automatiquement sur la machine lors de l'installation de la version recherche de SIPINA. Il faut l'intégrer dans Excel. La macro ajoute un nouveau menu dans le tableur. Après avoir sélectionné la plage de données, l'utilisateur n'a plus qu'à l'activer, s'en suivent les opérations suivantes : (1) SIPINA est automatiquement démarré ; (2) les données sont transférées via le presse-papier ; (3) SIPINA considère que la première ligne de la plage de cellules correspond aux noms de variables ; (4) les colonnes avec des valeurs numériques sont des variables quantitatives ; (5) les colonnes avec des valeurs alphanumériques sont des variables catégorielles.
Contrairement aux autres didacticiels, la séquence des manipulations sont décrites dans une vidéo. Cela relativise un peu le fait que le descriptif qui l'accompagne soit en anglais.
Note (07/08/2014) : les didactciels montrent la procédure pour les anciennes versions d'Office (jusqu'à Office 2003). Pour les versions plus récentes (Excel 2007 et Excel 2010), un nouveau descriptif à été mis en ligne.
Mots clés : arbres de décision, importation des données, fichier excel
Installation : sipina_xla_installation.htm
Utilisation : sipina_xla_processing.htm
Importation fichier texte
2008-03-08 (Tag:336744028614044577)
TANAGRA importe des fichiers textes avec séparateur tabulation. La première ligne correspond aux noms de variables. Ce didactciel montre comment : (1) préparer ce type de fichier, en partant d'un tableur par exemple ; (2) importer ces données en créant un nouveau diagramme dans TANAGRA. Attention, le point décimal des variables quantitatives dépend de la configuration de votre système.
L'utilisation des fichiers texte est à privilégier lors du traitement de "gros" volumes de données c.-à-d. de l'ordre de plusieurs centaines de milliers d'observations. Pour des fichiers de taille modérée (plusieurs dizaines de milliers d'individus, un fichier qui tient dans un tableur), mieux vaut utiliser le format Excel.
Mots clés : importation des données, fichier texte, création d'un diagramme de traitementsComposants : Dataset
Lien : ImportDataset.pdf
Données : weather.xls
Importation fichier XLS (Excel) [Mode natif]
2008-03-08 (Tag:6347476321911674155)
TANAGRA peut importer en mode natif -- c.-à-d. sans qu'il ne soit nécessaire que le tableur soit présent sur votre ordinateur -- les fichiers EXCEL (.xls), version 1997 à 2003 (sûr, pour Excel 2007 ça demande confirmation). Quelques petites restrictions sur la configuration du fichier : (1) les données doivent être situés dans la première feuille de calcul du classeur ; (2) Il ne doit pas y avoir de colonnes vides à gauche des données, ni de lignes vides au dessus des données, en d'autres termes les données doivent être calées sur la première ligne et la première colonne ; (3) TANAGRA considère que la première ligne contient les noms des variables.Dans ce didacticiel, nous montrons comment créer un nouveau diagramme en important un classeur EXCEL.
Mots clés : importation des données, fichier excel, création d'un diagramme de traitements
Composants : Group characterization
Lien : fr_Tanagra_Handle_Spreadsheet_File.pdf
Données : adult_dataset.zip
Importation fichier XLS (Excel) [Macro complémentaire]
2008-03-08 (Tag:947476440747517227)
TANAGRA peut importer des fichiers EXCEL, de n'importe quelle version (Excel 5.0 et + récentes, gérant les macro complémentaires VBA), à travers une macro complémentaire (TANAGRA.XLA) qui effectue automatiquement la jonction entre le tableur et le logiciel. Cette approche est une alternative aux technologies (XLMINER ou XLSTAT par exemple) où les techniques statistiques apparaissent comme des menus supplémentaires dans EXCEL.Concrètement, il s'agit d'installer la macro complémentaire sur le tableur, une fois pour toutes, de charger le classeur Excel contenant les données, de sélectionner la plage de cellules et d'activer le nouveau menu TANAGRA qui apparaît dans la barre de menu. TANAGRA est automatiquement démarré, un nouveau diagramme est créé, et les données sont chargées.
Ce didacticiel montre comment installer la macro complémentaire livrée et copiée automatiquement sur la machine lors du setup. Un scénario d'utilisation est par la suite développé.
Note (27/08/2010) : les didactciels montrent la procédure pour les anciennes versions d'Office (jusqu'à Office 2003). Pour les versions plus récentes (Excel 2007 et Excel 2010), un nouveau descriptif à été mis en ligne.
Mots clés : importation des données, fichier excel, création d'un diagramme de traitements, macro complémentaire excel, add-in, add-on
Composants : Univariate Discrete stat
Lien : fr_Tanagra_Excel_AddIn.pdf
Données : add_in_dataset.zip